










前言:
Linux熟练掌握的必备
本部分参考这个:
https://blog.csdn.net/qq_23853743/article/details/84037598
进阶部分参考这个:
https://blog.csdn.net/u014427391/article/details/102785219
常用命令的解释:
https://blog.csdn.net/qq_40334837/article/details/83819735
基础命令
ls
-l
-a
-h
-R
pwd
无
mkdir
cd
这个不用多说
touch
- -a 改变档案的读取时间记录
- -m 改变档案的修改时间记录。
- -c 假如目的档案不存在,不会建立新的档案。与 --no-create 的效果一样。
- -f 不使用,是为了与其他 unix 系统的相容性而保留。
- -r 使用参考档的时间记录,与 --file 的效果一样。
- -d 设定时间与日期,可以使用各种不同的格式。
- -t 设定档案的时间记录,格式与 date 指令相同。
- –no-create 不会建立新档案。
- –help 列出指令格式。
- –version 列出版本讯息。
cp
- -a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
- -d:复制时保留链接。这里所说的链接相当于Windows系统中的快捷方式。
- -f:覆盖已经存在的目标文件而不给出提示。
- -i:与-f选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答"y"时目标文件将被覆盖。
- -p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
- -r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
- -l:不复制文件,只是生成链接文件。
mv
- -b: 当目标文件或目录存在时,在执行覆盖前,会为其创建一个备份。
- -i: 如果指定移动的源目录或文件与目标的目录或文件同名,则会先询问是否覆盖旧文件,输入 y 表示直接覆盖,输入 n 表示取消该操作。
- -f: 如果指定移动的源目录或文件与目标的目录或文件同名,不会询问,直接覆盖旧文件。
- -n: 不要覆盖任何已存在的文件或目录。
- -u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。
rmdir
rmdir移除空目录
无
rm
- -i 删除前逐一询问确认。
- -f 即使原档案属性设为唯读,亦直接删除,无需逐一确认。
- -r 将目录及以下之档案亦逐一删除。
cat
> 重定向
more & less
功能相同
less更牛批
head & tail
显示头尾的n行
-n
用户 & 组管理命令:
groupadd
-g
useradd
创建一个用户user1,同时在/etc/passwd文件和/etc/shadow文件增加一行,并自动为用户创建相应的主目录:/home/user1
-u
-g
-G
-d
userdel
-r
groupdel
当某个组是某现有用户的主要组时,则不能被删除
passwd
普通用户只可以修改自己的口令
-l
-u
-d
usermod
UID号修改为601、主要组修改为501
-u
-g
id
显示用户的UID、GID及所属的组信息
文件属性操作
chown
change own
改变文件的属主
-R
chgrp
改变文件的属组
-R
chmod
以二进制编码的形式进行权限赋值
ln
建立硬链接 & 软连接
-s

查找命令:
which & whereis
无参数
find
参考博客:
https://blog.csdn.net/lilygg/article/details/84076757
find 目录 参数 参数值
-name "name" 查找name文件
-user "user" 查找属于某用户的文件
-group "group" 查找属于某用户组的文件
-maxdepth 1 查看多深的文件,不能超过所限制的目录下的内容
-mindepth 2 查看不小于多深的文件,不低于所限制内容
# 这个要放到参数的最前头
-size 20K 按文件大小查找20K 的文件
-size -20K 查找不大于20K的文件
-size +20K 查找大于 20K的文件
# 这种+-在后头的参数中也有用到
-type 查找指定类型的文件
#主要的文件类型:
f #file 普通文件
d #dir 目录
b #block 块设备
s #socket 套接字
c #char 字符设备
l #link 链接
p #pipe 管道
-cmin 5 查看距现在5分钟时修改
-cmin -5 查看五分钟内修改的文件
-cmin +5 五分钟之前修改的文件
-ctime 5 五内的时间点修改过的文件
-ctime +5 五天前修改或的文件
-ctime -5 小于五天修改过的文件
-perm 按权限查找
-perm 555 查找权限为555的文件
-perm -444 查找所有人 所有组 其他人 有读权限的文件
-perm /444 查找所有人 或所有组 或其他人 至少有一个有读权限的文件
常用实例:
找到temp目录下7天之内以log结尾的文件, 并删除
find ./temp/ -type f -name "*log" -ctime -5 -print

而删除文件使用的是xargs
xargs用来给命令传递参数, 通常可以用在管道中
xargs详细命令:
https://www.linuxprobe.com/linux-xargs-usage.html
find ./temp/ -type f -name "*log" -ctime -5 -print | xargs -n 1 rm
也可以使用grep配合正则表达式执行
find . -type f | grep ".*log" | xargs rm -r
文件操作:
grep:
-v
常用参数:
-E :开启扩展(Extend)的正则表达式。
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号
-w :被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只显示被模式匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
更多参数:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或–silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
grep & 正则
grep支持正则表达式, 直接使用即可, 如下例子
查找当前目录中的文件
find . -type f | grep ".*log"
但是为了支持完整的正则, 或不同版本的正则, 需要加参数, help如下
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated fixed strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
可以看到3种正则, -E -G -P
功能最全的是-P, 能够支持零宽断言等高级功能
使用过程中遇到的问题:
-
零宽断言的
(?>=exp)不能使用不定长度, 即以下语句是不被允许的url="https://www.cnblogs.com/yangyongzhi/archive/2012/11/05/2755421.html" file=`echo ${url} | grep -P -oe "(?<=/)[^/]+$"` echo ${url} | grep -P -oe "(?<=//[a-z]+/).+(?=${file})"
wc
常用参数
-l -c -w
sort
将指定文件以行为单位按字典序正序/逆序输出
即将每行都视为一个字符串, 以 字典序排序后输出
-r
diff
比较文件test与mytest是否相同,将****不同****之处输出到屏幕上。
cut
详细参考:
https://blog.csdn.net/yangshangwei/article/details/52563123
rz & sz
rz & sz 利用ZModem协议与Linux服务器上传/下载文件
rz & sz的使用条件
- linux系统
- root权限
- lrzsz安装包
这个命令就没啥好讲的了
du
查看文件大小
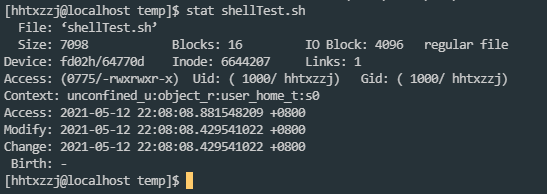
stat
stat 以文字的格式来显示 inode 的内容
而inode是储存文件元信息的区域, 通常被翻译为“索引节点”
每一个文件都有inode, 其中包含的了与文件相关的信息(有点类似于文件控制块所包含的信息)
压缩 & 打包命令:
tar
tar是 Linux 中最常用的 备份工具,此命令可以 把一系列文件 打包到 一个大文件中,也可以把一个 打包的大文件恢复成一系列文件tar的命令格式如下:
# 打包文件
tar -cvf 打包文件.tar 被打包的文件/路径...
# 解包文件
tar -xvf 打包文件.tar
tar选项说明
| 选项 | 含义 |
|---|---|
| c | 建立新的压缩文件 |
| x | 从压缩的文件中提取文件(解压缩) |
| v | 列出归档解档的详细过程,显示进度 |
| f | 指定档案文件名称,f 后面一定是 .tar 文件,所以必须放选项最后, 且这个玩意为必选 |
常用参数:
必要参数有如下:
-A 新增压缩文件到已存在的压缩
-c 建立新的压缩文件
-d 记录文件的差别
-r 添加文件到已经压缩的文件
-u 添加改变了和现有的文件到已经存在的压缩文件
-x 从压缩的文件中提取文件
-t 显示压缩文件的内容
-z 支持``gzip``解压文件
-j 支持``bzip2``解压文件
-Z 支持compress解压文件
-v 显示操作过程
-l 文件系统边界设置
-k 保留原有文件不覆盖
-m 保留文件不被覆盖
-W 确认压缩文件的正确性
-C 解压到指定目录
gzip
tar与gzip命令结合可以使用实现文件 打包和压缩tar只负责打包文件,但不压缩- 用
gzip压缩tar打包后的文件,其扩展名一般用xxx.tar.gz
包括Github上的release版都是tar.gz格式
在
Linux中,最常见的压缩文件格式就是xxx.tar.gz
- 在
tar命令中有一个选项 -z 可以调用gzip,从而可以方便的实现压缩和解压缩的功能 - 命令格式如下:
# 压缩文件
tar -zcvf 打包文件.tar.gz 被压缩的文件/路径...
# 解压缩文件
tar -zxvf 打包文件.tar.gz
# 解压缩到指定路径
tar -zxvf 打包文件.tar.gz -C 目标路径
| 选项 | 含义 |
|---|---|
| -C | 解压缩到指定目录,注意:要解压缩的目录必须存在 |
当解压目录不存在时:

查看压缩文档内容
打包解包压缩解压上头的就是
-
查看压缩文件内容:
tar -tzvf tar/tartest.tar.gz
bzip2
此为另一种常用的压缩格式
tar与bzip2命令结合可以使用实现文件 打包和压缩(用法和gzip一样)tar只负责打包文件,但不压缩,- 用
bzip2压缩tar打包后的文件,其扩展名一般用xxx.tar.bz2
- 在
tar命令中有一个选项 -j 可以调用bzip2,从而可以方便的实现压缩和解压缩的功能 - 命令格式如下:
就是将上头的-z换成-j即可
# 压缩文件
tar -jcvf 打包文件.tar.bz2 被压缩的文件/路径...
# 解压缩文件
tar -jxvf 打包文件.tar.bz2
网卡配置:
ifconfig
设置网卡参数:
ifconfig eth0 10.22.1.103 netmask 255.255.255.0
禁用 & 激活某块网卡:
ifconfig eth0 down
ifconfig eth0 up
软件安装
rpm
查询系统中安装的软件包
rpm -qa

查询软件包中文件清单
rpm -ql php

卸载指定的软件包
rpm -e php

安装软件包
rpm -ivh php-4.3.9-3.1-i386.rpm

-h通常都表示人性化
强制安装软件包
rpm -ivh --force php-4.3.9-3.1-i386.rpm
如果要安装的软件的版本****比较低或该软件包在系统中已存在****,系统会给出提示并拒绝安装,此时可以加上参数—force来进行强制安装
忽略依赖关系安装:
rpm -ivh --nodeps php-4.3.9-3.1-i386.rpm
在安装或卸载软件时经常会遇到提示“该软件包与某某软件包存在依赖关系”,只有加上参数****–nodeps****忽略掉依赖关系才能进行安装或卸载
yum & apt-get
这两个用的都比较多, 暂时不复习了
源码编译安装:
./configure
make
make install
make clean与make distclean
系统监控 & 管理
ps
常用命令
命令参数:
a 显示所有进程
-a 显示同一终端下的所有程序
-A 显示所有进程
c 显示进程的真实名称
-N 反向选择
-e 显示所有进程, 等于-A
e 显示环境变量
f 显示程序间的关系
-H 显示树状结构
r 显示当前终端的进程
T 显示当前终端的所有程序
u 指定用户的所有进程
-au 显示较详细的资讯
-aux 显示所有包含其他使用者的进程
-C<命令> 列出指定命令的状况
--lines<行数> 每页显示的行数
--width<字符数> 每页显示的字符数
--help 显示帮助信息
--version 显示版本显示
这里的三种前缀: 不带-, 带-, 带--, 是因为, ps支持三种风格的参数:
- UNIX 风格,选项可以组合在一起,并且选项前必须有“-”连字符
- BSD 风格,选项可以组合在一起,但是选项前不能有“-”连字符
- GNU 风格的长选项,选项前有两个“-”连字符
表项详解:
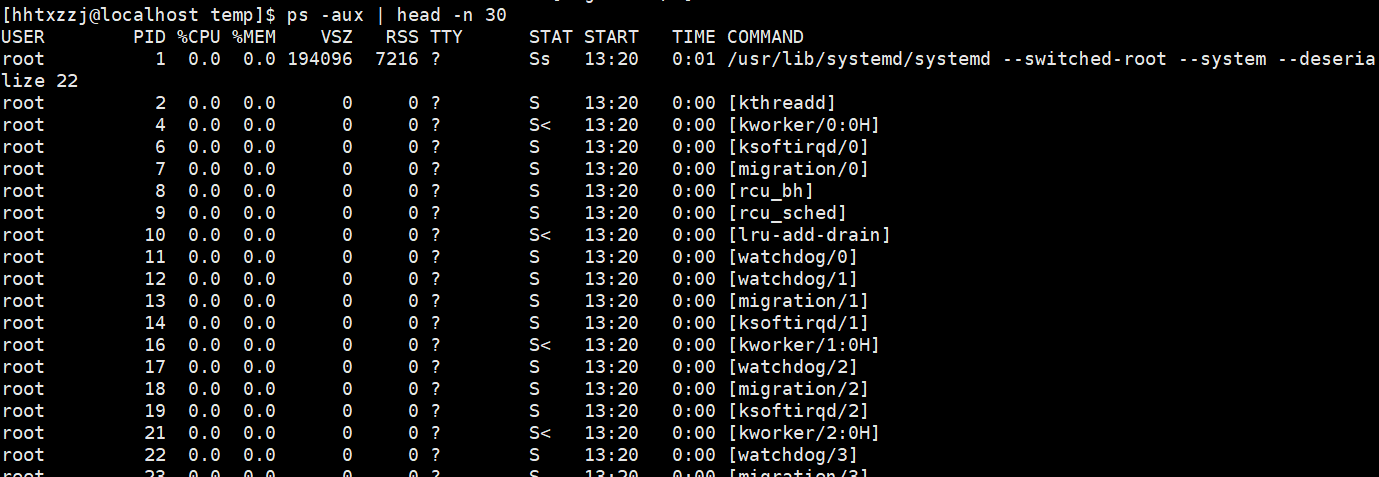
- USER: 进程拥有者
- PID: pid
- %CPU: 占用的 CPU 使用率
- %MEM: 占用的内存使用率
- VSZ: 占用的虚拟内存大小
- RSS: 占用的内存大小
- TTY: 终端的次要装置号码 (minor device number of tty)
- STAT: 该进程的状态:
- D: 无法中断的休眠状态 (通常 IO 的进程)
- R: 正在执行中
- S: 静止状态
- T: 暂停执行
- Z: 不存在但暂时无法消除
- W: 没有足够的内存分页可分配
- <: 高优先序的进程
- N: 低优先序的进程
- L: 有内存分页分配并锁在内存内 (实时系统或捱A I/O)
- START: 进程开始时间
- TIME: 执行的时间
- COMMAND:所执行的指令
几个常用的组合
常用的使用方式:
https://linux.cn/article-4743-1.html
# 显示所有进程信息, 包括命令行
ps -e
ps -ef
ps -eF
ps -ely
# 显示进程树
ps -ejH
ps axjf
# 获取线程信息
ps -eLf
ps axms
# 查看指定用户的进程信息
ps -U root -u root u
# 将目前属于您自己这次登入的 PID 与相关信息列示出来
ps -l
这里的-l相当于显示更多信息
top & htop
这个不同多说
但是参数很多, 有空可以看一下
- d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
- q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
- c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称
- S : 累积模式,会将己完成或消失的子行程 ( dead child process ) 的 CPU time 累积起来
- s : 安全模式,将交谈式指令取消, 避免潜在的危机
- i : 不显示任何闲置 (idle) 或无用 (zombie) 的行程
- n : 更新的次数,完成后将会退出 top
- b : 批次档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到档案内
表项详解:
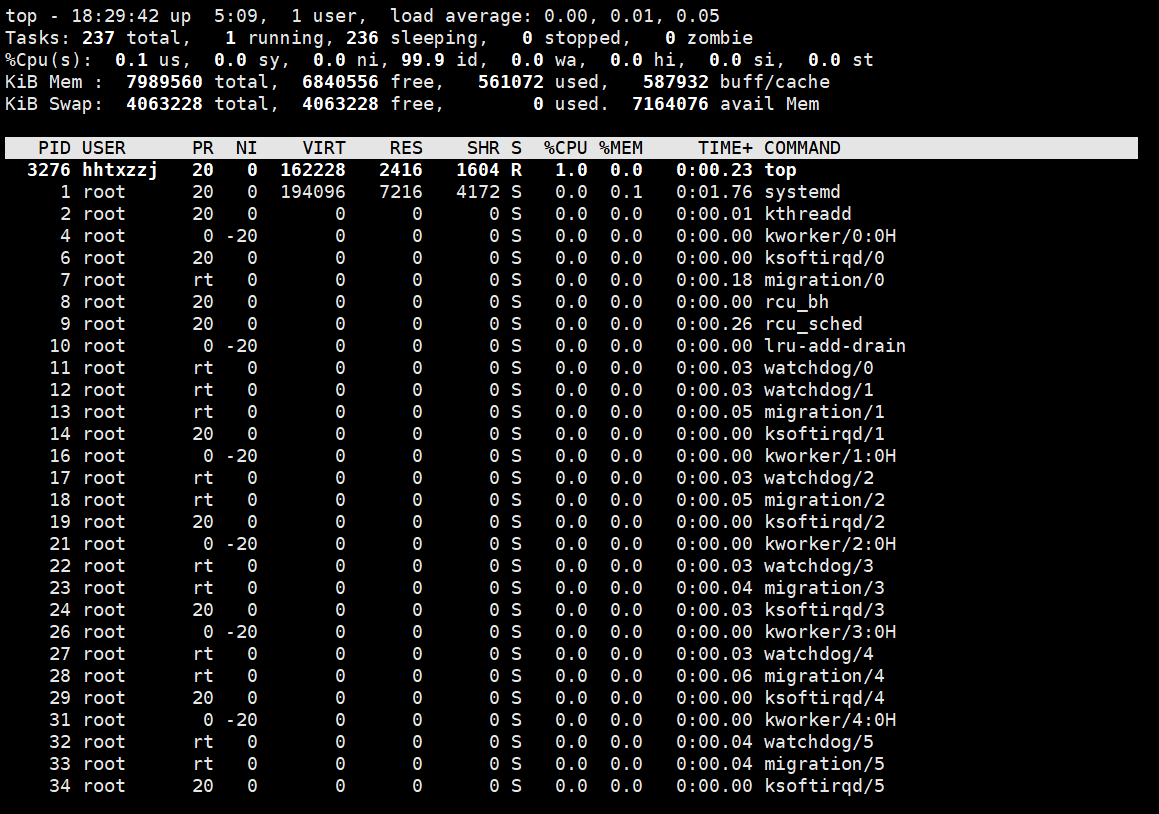
头部部分(系统概述):
这里的不同显示行都可以使用相应的按键(交互式)切换显示模式
-
第一行: 系统运行时间和平均负载
- 当前时间
- 系统已运行的时间
- 当前登录用户的数量
- 相应最近5、10和15分钟内的平均负载
l键切换模式
-
第二行: 任务或者进程的总结
- 全部进程的数量
- 除此之外,还有正在运行、睡眠、停止、僵尸进程的数量(僵尸是一种进程的状态)
-
第三行: CPU状态
- us, user: 运行(未调整优先级的) 用户进程的CPU时间
- sy,system: 运行内核进程的CPU时间
- ni,niced:运行已调整优先级的用户进程的CPU时间
- wa,IO wait: 用于等待IO完成的CPU时间
- hi:处理硬件中断的CPU时间
- si: 处理软件中断的CPU时间
- st:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)
t键切换模式
-
第四行: 内存使用
- 物理内存: 全部可用内存、已使用内存、空闲内存、缓冲内存
- 交换内存: 全部、已使用、空闲和缓冲交换空间
m键切换模式
进程信息部分:
PID
进程ID,进程的唯一标识符
USER
进程所有者的实际用户名。
PR
进程的调度优先级。这个字段的一些值是’rt’。这意味这这些进程运行在实时态。
NI
进程的nice值(优先级)。越小的值意味着越高的优先级。
VIRT
进程使用的虚拟内存。
RES
驻留内存大小。驻留内存是任务使用的非交换物理内存大小。
SHR
SHR是进程使用的共享内存。
S
这个是进程的状态。它有以下不同的值:
- D – 不可中断的睡眠态。
- R – 运行态
- S – 睡眠态
- T – 被跟踪或已停止
- Z – 僵尸态
%CPU
自从上一次更新时到现在任务所使用的CPU时间百分比。
%MEM
进程使用的可用物理内存百分比。
TIME+
任务启动后到现在所使用的全部CPU时间,精确到百分之一秒。
COMMAND
运行进程所使用的命令。
还有许多在默认情况下不会显示的输出,它们可以显示进程的页错误、有效组和组ID和其他更多的信息。
常用实例:
显示进程信息
# top
显示完整命令
# top -c
以批处理模式显示程序信息
# top -b
以累积模式显示程序信息
# top -S
设置信息更新次数
top -n 2
//表示更新两次后终止更新显示
设置信息更新时间
# top -d 3
//表示更新周期为3秒
显示指定的进程信息
# top -p 139
//显示进程号为139的进程信息,CPU、内存占用率等
显示更新十次后退出
top -n 10
安全模式, 使用者将不能利用交谈式指令来对行程下命令
top -s
交互命令:
‘h’: 帮助
回车或空格: 手动刷新显示
‘A’: 切换交替显示模式
按了A 接着按a可以切换4种显示模式
- Def (默认字段组)
- Job (任务字段组)
- Mem (内存字段组)
- Usr (用户字段组)
‘B’: 触发粗体显示
‘d’ 或‘s’: 设置显示的刷新间隔
‘l’、‘t’、‘m’: 切换负载、任务、内存信息的显示
‘f’: 字段管理
‘R’: 反向排序
‘c’: 触发命令
‘i’: 空闲任务
‘V’: 树视图
‘Z’: 改变配色
‘z’: 切换彩色显示
‘x’ 或者 ‘y’ 切换高亮显示
‘u’: 特定用户的进程
‘n’ 或 ‘#’: 任务的数量
‘k’: 结束任务
‘r’: 重新设置优先级
kill
参考:
https://www.runoob.com/linux/linux-comm-kill.html
-9
kill命令可以发送各种signal给进程, 默认发送9(SIGTERM) , termination终止进程
kill支持以下信号:
[hhtxzzj@localhost shellTest]$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
各种信号有不同的作用
参考博客:
https://www.cnblogs.com/frisk/p/11602973.html
SIGHUP 1 /* Hangup (POSIX). */ 终止进程 终端线路挂断
SIGINT 2 /* Interrupt (ANSI). */ 终止进程 中断进程 Ctrl+C
SIGQUIT 3 /* Quit (POSIX). */ 建立CORE文件终止进程,并且生成core文件 Ctrl+\
SIGILL 4 /* Illegal instruction (ANSI). */ 建立CORE文件,非法指令
SIGTRAP 5 /* Trace trap (POSIX). */ 建立CORE文件,跟踪自陷
SIGABRT 6 /* Abort (ANSI). */
SIGIOT 6 /* IOT trap (4.2 BSD). */ 建立CORE文件,执行I/O自陷
SIGBUS 7 /* BUS error (4.2 BSD). */ 建立CORE文件,总线错误
SIGFPE 8 /* Floating-point exception (ANSI). */ 建立CORE文件,浮点异常
SIGKILL 9 /* Kill, unblockable (POSIX). */ 终止进程 杀死进程
SIGUSR1 10 /* User-defined signal 1 (POSIX). */ 终止进程 用户定义信号1
SIGSEGV 11 /* Segmentation violation (ANSI). */ 建立CORE文件,段非法错误
SIGUSR2 12 /* User-defined signal 2 (POSIX). */ 终止进程 用户定义信号2
SIGPIPE 13 /* Broken pipe (POSIX). */ 终止进程 向一个没有读进程的管道写数据
SIGALARM 14 /* Alarm clock (POSIX). */ 终止进程 计时器到时
SIGTERM 15 /* Termination (ANSI). */ 终止进程 软件终止信号
SIGSTKFLT 16 /* Stack fault. */
SIGCLD SIGCHLD /* Same as SIGCHLD (System V). */
SIGCHLD 17 /* Child status has changed (POSIX). */ 忽略信号 当子进程停止或退出时通知父进程
SIGCONT 18 /* Continue (POSIX). */ 忽略信号 继续执行一个停止的进程
SIGSTOP 19 /* Stop, unblockable (POSIX). */ 停止进程 非终端来的停止信号
SIGTSTP 20 /* Keyboard stop (POSIX). */ 停止进程 终端来的停止信号 Ctrl+Z
SIGTTIN 21 /* Background read from tty (POSIX). */ 停止进程 后台进程读终端
SIGTTOU 22 /* Background write to tty (POSIX). */ 停止进程 后台进程写终端
SIGURG 23 /* Urgent condition on socket (4.2 BSD). */ 忽略信号 I/O紧急信号
SIGXCPU 24 /* CPU limit exceeded (4.2 BSD). */ 终止进程 CPU时限超时
SIGXFSZ 25 /* File size limit exceeded (4.2 BSD). */ 终止进程 文件长度过长
SIGVTALRM 26 /* Virtual alarm clock (4.2 BSD). */ 终止进程 虚拟计时器到时
SIGPROF 27 /* Profiling alarm clock (4.2 BSD). */ 终止进程 统计分布图用计时器到时
SIGWINCH 28 /* Window size change (4.3 BSD, Sun). */ 忽略信号 窗口大小发生变化
SIGPOLL SIGIO /* Pollable event occurred (System V). */
SIGIO 29 /* I/O now possible (4.2 BSD). */ 忽略信号 描述符上可以进行I/O
SIGPWR 30 /* Power failure restart (System V). */
SIGSYS 31 /* Bad system call. */
SIGUNUSED 31
free
free 命令能够显示系统中物理上的空闲和已用内存,还有交换内存,同时,也能显示被内核使用的缓冲和缓存
常用参数:
- -b:以Byte为单位显示内存使用情况
- -k:以KB为单位显示内存使用情况
- -m:以MB为单位显示内存使用情况
- -h: 依然是人性化显示信息
- -o:不显示缓冲区调节列
- -s<间隔秒数>:持续观察内存使用状况
- -t:显示内存总和列
- -V:显示版本信息

几个表项的意义都很明了
ulimit
用于显示系统资源限制的信息
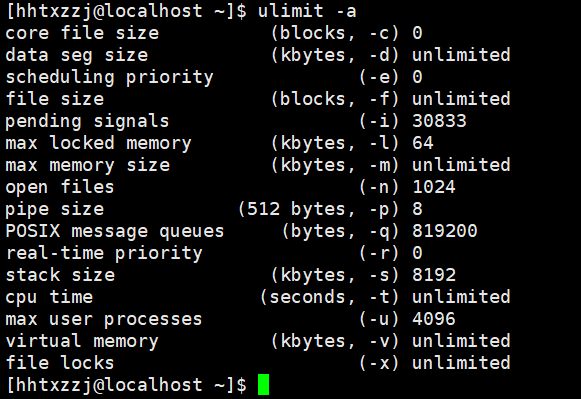
这里主要关注两个信息:
- open files:– 用户可以打开文件的最大数目
- max user processes – 用户可以开启进程/线程的最大数目
其中每个参数在图中都有提示使用哪个参数进行设置
如open files使用-n来临时设置
curl
-A/--user-agent <string> 设置用户代理发送给服务器
-b/--cookie <name=string/file> cookie字符串或文件读取位置
-c/--cookie-jar <file> 操作结束后把cookie写入到这个文件中
-C/--continue-at <offset> 断点续转
-D/--dump-header <file> 把header信息写入到该文件中
-e/--referer 来源网址
-f/--fail 连接失败时不显示http错误
-o/--output 把输出写到该文件中
-O/--remote-name 把输出写到该文件中,保留远程文件的文件名
-r/--range <range> 检索来自HTTP/1.1或FTP服务器字节范围
-s/--silent 静音模式。不输出任何东西
-T/--upload-file <file> 上传文件
-u/--user <user[:password]> 设置服务器的用户和密码
-w/--write-out [format] 什么输出完成后
-x/--proxy <host[:port]> 在给定的端口上使用HTTP代理
常用方法:
==这里为了页面精简, 删了输出部分, 详细的直接看参考博客:
https://www.jb51.net/article/118402.htm
1. 获取页面内容
当我们不加任何选项使用 curl 时,默认会发送 GET 请求来获取链接内容到标准输出。
curl http:``//www``.codebelief.com
2. 显示 HTTP 头
如果我们只想要显示 HTTP 头,而不显示文件内容,可以使用 -I 选项:
curl -I http:``//www``.codebelief.com
也可以同时显示 HTTP 头和文件内容,使用 -i 选项:
curl -i http:``//www``.codebelief.com
3. 将链接保存到文件
我们可以使用 > 符号将输出重定向到本地文件中。
curl http:``//www``.codebelief.com > index.html
也可以通过 curl 自带的 -o/-O 选项将内容保存到文件中。
-o(小写的 o):结果会被保存到命令行中提供的文件名-O(大写的 O):URL 中的文件名会被用作保存输出的文件名
curl -o index.html http:``//www``.codebelief.com ``curl -O http:``//www``.codebelief.com``/page/2/
**注意:**使用 -O 选项时,必须确保链接末尾包含文件名,否则 curl 无法正确保存文件。如果遇到链接中无文件名的情况,应该使
用 -o选项手动指定文件名,或使用重定向符号。
4. 同时下载多个文件
我们可以使用 -o 或 -O 选项来同时指定多个链接,按照以下格式编写命令:
curl -O http:``//www``.codebelief.com``/page/2/` `-O http:``//www``.codebelief.com``/page/3/
或者:
curl -o page1.html http:``//www``.codebelief.com``/page/1/` `-o page2.html http:``//www``.codebelief.com``/page/2/
5. 使用 -L 跟随链接重定向
如果直接使用 curl 打开某些被重定向后的链接,这种情况下就无法获取我们想要的网页内容。例如:
curl http:``//codebelief``.com
而当我们通过浏览器打开该链接时,会自动跳转到 http://www.codebelief.com。此时我们想要 curl 做的,就是像浏览器一样跟随链接的跳转,获取最终的网页内容。我们可以在命令中添加 -L 选项来跟随链接重定向:
curl -L http:``//codebelief``.com
这样我们就能获取到经过重定向后的网页内容了。
6. 使用 -A 自定义 User-Agent
我们可以使用 -A 来自定义用户代理,例如下面的命令将伪装成安卓火狐浏览器对网页进行请求:
curl -A ``"Mozilla/5.0 (Android; Mobile; rv:35.0) Gecko/35.0 Firefox/35.0"` `http:``//www``.baidu.com
下面我们会使用 -H 来实现同样的目的。
7. 使用 -H 自定义 header
当我们需要传递特定的 header 的时候,可以仿照以下命令来写:
curl -H ``"Referer: www.example.com"` `-H ``"User-Agent: Custom-User-Agent"` `http:``//www``.baidu.com
可以看到,当我们使用 -H 来自定义 User-Agent 时,需要使用 “User-Agent: xxx” 的格式。
我们能够直接在 header 中传递 Cookie,格式与上面的例子一样:
curl -H ``"Cookie: JSESSIONID=D0112A5063D938586B659EF8F939BE24"` `http:``//www``.example.com
另一种方式会在下面介绍。
8. 使用 -c 保存 Cookie
当我们使用 cURL 访问页面的时候,默认是不会保存 Cookie 的。有些情况下我们希望保存 Cookie 以便下次访问时使用。例如登陆了某个网站,我们希望再次访问该网站时保持登陆的状态,这时就可以现将登陆时的 Cookie 保存起来,下次访问时再读取。
-c 后面跟上要保存的文件名。
curl -c ``"cookie-example"` `http:``//www``.example.com
9. 使用 -b 读取 Cookie
前面讲到了使用 -H来发送 Cookie 的方法,这种方式是直接将 Cookie 字符串写在命令中。如果使用 -b 来自定义 Cookie,命令如下:
curl -b ``"JSESSIONID=D0112A5063D938586B659EF8F939BE24"` `http:``//www``.example.com
如果要从文件中读取 Cookie,-H 就无能为力了,此时可以使用 -b 来达到这一目的:
curl -b ``"cookie-example"` `http:``//www``.example.com
即 -b后面既可以是 Cookie 字符串,也可以是保存了 Cookie 的文件名。
10. 使用 -d 发送 POST 请求
我们以登陆网页为例来进行说明使用 cURL 发送 POST 请求的方法。假设有一个登录页面 www.example.com/login,只需要提交用户名和密码便可登录。我们可以使用 cURL 来完成这一 POST 请求,-d 用于指定发送的数据,-X 用于指定发送数据的方式:
curl -d ``"userName=tom&passwd=123456"` `-X POST http:``//www``.example.com``/login
在使用 -d 的情况下,如果省略 -X,则默认为 POST 方式:
curl -d ``"userName=tom&passwd=123456"` `http:``//www``.example.com``/login
强制使用 GET 方式
发送数据时,不仅可以使用 POST 方式,也可以使用 GET 方式,例如:
curl -d ``"somedata"` `-X GET http:``//www``.example.com``/api
或者使用 -G 选项:
curl -d ``"somedata"` `-G http:``//www``.example.com``/api
从文件中读取 data
curl -d ``"@data.txt"` `http:``//www``.example.com``/login
带 Cookie 登录
当然,如果我们再次访问该网站,仍然会变成未登录的状态。我们可以用之前提到的方法保存 Cookie,在每次访问网站时都带上该 Cookie 以保持登录状态。
curl -c ``"cookie-login"` `-d ``"userName=tom&passwd=123456"` `http:``//www``.example.com``/login
再次访问该网站时,使用以下命令:
curl -b ``"cookie-login"` `http:``//www``.example.com``/login
这样,就能保持访问的是登录后的页面了。
smartctl
第三方软件, 可能不会问到
env
看当前用户的环境信息
lsof
lists openfiles
在Linux中, 所有的一切都是文件, 包括Socket等, 所以lsof的功能非常强大, 甚至可以替代 netstat & ps
东西非常多, 有详细需要直接看教程
参考资料:
https://www.jianshu.com/p/a3aa6b01b2e1
- 默认 : 没有选项,lsof列出活跃进程的所有打开文件
- 组合 : 可以将选项组合到一起,如-abc,但要当心哪些选项需要参数
- -a : 结果进行“与”运算(而不是“或”)
- -l : 在输出显示用户ID而不是用户名
- -h : 获得帮助
- -t : 仅获取进程ID
- -U : 获取UNIX套接口地址
- -F : 格式化输出结果,用于其它命令。可以通过多种方式格式化,如-F pcfn(用于进程id、命令名、文件描述符、文件名,并以空终止)
获取网络信息
正如我所说的,我主要将lsof用于获取关于系统怎么和网络交互的信息。这里提供了关于此信息的一些主题:
使用-i显示所有连接
有些人喜欢用netstat来获取网络连接,但是我更喜欢使用lsof来进行此项工作。结果以对我来说很直观的方式呈现,我仅仅只需改变我的语法,就可以通过同样的命令来获取更多信息。
语法: lsof -i[46] [protocol][@hostname|hostaddr][:service|port]
1. # lsof -i
3. COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
4. dhcpcd 6061 root 4u IPv4 4510 UDP *:bootpc
5. sshd 7703 root 3u IPv6 6499 TCP *:ssh (LISTEN)
6. sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
使用-i 6仅获取IPv6流量
1. # lsof -i 6
仅显示TCP连接(同理可获得UDP连接)
你也可以通过在-i后提供对应的协议来仅仅显示TCP或者UDP连接信息。
1. # lsof -iTCP
3. COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
4. sshd 7703 root 3u IPv6 6499 TCP *:ssh (LISTEN)
5. sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
使用-i:port来显示与指定端口相关的网络信息(查看端口占用)
或者,你也可以通过端口搜索,这对于要找出什么阻止了另外一个应用绑定到指定端口实在是太棒了。
1. # lsof -i :22
3. COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
4. sshd 7703 root 3u IPv6 6499 TCP *:ssh (LISTEN)
5. sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
使用@host来显示指定到指定主机的连接
这对于你在检查是否开放连接到网络中或互联网上某个指定主机的连接时十分有用。
1. # lsof -i@172.16.12.5
3. sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->172.16.12.5:49901 (ESTABLISHED)
使用@host:port显示基于主机与端口的连接
你也可以组合主机与端口的显示信息。
1. # lsof -i@172.16.12.5:22
3. sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->172.16.12.5:49901 (ESTABLISHED)
找出监听端口
找出正等候连接的端口。
1. # lsof -i -sTCP:LISTEN
你也可以grep “LISTEN”来完成该任务。
1. # lsof -i | grep -i LISTEN
3. iTunes 400 daniel 16u IPv4 0x4575228 0t0 TCP *:daap (LISTEN)
找出已建立的连接
你也可以显示任何已经连接的连接。
1. # lsof -i -sTCP:ESTABLISHED
你也可以通过grep搜索“ESTABLISHED”来完成该任务。
1. # lsof -i | grep -i ESTABLISHED
3. firefox-b 169 daniel 49u IPv4 0t0 TCP 1.2.3.3:1863->1.2.3.4:http (ESTABLISHED)
用户信息
你也可以获取各种用户的信息,以及它们在系统上正干着的事情,包括它们的网络活动、对文件的操作等。
使用-u显示指定用户打开了什么
1. # lsof -u daniel
3. -- snipped --
4. Dock 155 daniel txt REG 14,2 2798436 823208 /usr/lib/libicucore.A.dylib
5. Dock 155 daniel txt REG 14,2 1580212 823126 /usr/lib/libobjc.A.dylib
6. Dock 155 daniel txt REG 14,2 2934184 823498 /usr/lib/libstdc++.6.0.4.dylib
7. Dock 155 daniel txt REG 14,2 132008 823505 /usr/lib/libgcc_s.1.dylib
8. Dock 155 daniel txt REG 14,2 212160 823214 /usr/lib/libauto.dylib
9. -- snipped --
使用-u user来显示除指定用户以外的其它所有用户所做的事情
1. # lsof -u ^daniel
3. -- snipped --
4. Dock 155 jim txt REG 14,2 2798436 823208 /usr/lib/libicucore.A.dylib
5. Dock 155 jim txt REG 14,2 1580212 823126 /usr/lib/libobjc.A.dylib
6. Dock 155 jim txt REG 14,2 2934184 823498 /usr/lib/libstdc++.6.0.4.dylib
7. Dock 155 jim txt REG 14,2 132008 823505 /usr/lib/libgcc_s.1.dylib
8. Dock 155 jim txt REG 14,2 212160 823214 /usr/lib/libauto.dylib
9. -- snipped --
杀死指定用户所做的一切事情
可以消灭指定用户运行的所有东西,这真不错。
1. # kill -9 `lsof -t -u daniel`
命令和进程
可以查看指定程序或进程由什么启动,这通常会很有用,而你可以使用lsof通过名称或进程ID过滤来完成这个任务。下面列出了一些选项:
使用-c查看指定的命令正在使用的文件和网络连接
1. # lsof -c syslog-ng
3. COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
4. syslog-ng 7547 root cwd DIR 3,3 4096 2 /
5. syslog-ng 7547 root rtd DIR 3,3 4096 2 /
6. syslog-ng 7547 root txt REG 3,3 113524 1064970 /usr/sbin/syslog-ng
7. -- snipped --
使用-p查看指定进程ID已打开的内容
1. # lsof -p 10075
3. -- snipped --
4. sshd 10068 root mem REG 3,3 34808 850407 /lib/libnss_files-2.4.so
5. sshd 10068 root mem REG 3,3 34924 850409 /lib/libnss_nis-2.4.so
6. sshd 10068 root mem REG 3,3 26596 850405 /lib/libnss_compat-2.4.so
7. sshd 10068 root mem REG 3,3 200152 509940 /usr/lib/libssl.so.0.9.7
8. sshd 10068 root mem REG 3,3 46216 510014 /usr/lib/liblber-2.3
9. sshd 10068 root mem REG 3,3 59868 850413 /lib/libresolv-2.4.so
10. sshd 10068 root mem REG 3,3 1197180 850396 /lib/libc-2.4.so
11. sshd 10068 root mem REG 3,3 22168 850398 /lib/libcrypt-2.4.so
12. sshd 10068 root mem REG 3,3 72784 850404 /lib/libnsl-2.4.so
13. sshd 10068 root mem REG 3,3 70632 850417 /lib/libz.so.1.2.3
14. sshd 10068 root mem REG 3,3 9992 850416 /lib/libutil-2.4.so
15. -- snipped --
-t选项只返回PID
1. # lsof -t -c Mail
3. 350
文件和目录
通过查看指定文件或目录,你可以看到系统上所有正与其交互的资源——包括用户、进程等。
显示与指定目录交互的所有一切
1. # lsof /var/log/messages/
3. COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
4. syslog-ng 7547 root 4w REG 3,3 217309 834024 /var/log/messages
显示与指定文件交互的所有一切
1. # lsof /home/daniel/firewall_whitelist.txt
高级用法
与tcpdump类似,当你开始组合查询时,它就显示了它强大的功能。
显示daniel连接到1.1.1.1所做的一切
1. # lsof -u daniel -i @1.1.1.1
3. bkdr 1893 daniel 3u IPv6 3456 TCP 10.10.1.10:1234->1.1.1.1:31337 (ESTABLISHED)
同时使用-t和-c选项以给进程发送 HUP 信号
1. # kill -HUP `lsof -t -c sshd`
lsof +L1显示所有打开的链接数小于1的文件
这通常(当不总是)表示某个攻击者正尝试通过删除文件入口来隐藏文件内容。
1. # lsof +L1
3. (hopefully nothing)
显示某个端口范围的打开的连接
1. # lsof -i @fw.google.com:2150=2180
ip
ip 命令与 ifconfig 命令类似,但比 ifconfig 命令更加强大,主要功能是用于显示或设置网络设备
ip 命令是 Linux 加强版的的网络配置工具,用于代替 ifconfig 命令
ip [ OPTIONS ] OBJECT { COMMAND | help }
- link:网络设备
- address:设备上的协议(IP或IPv6)地址
- addrlabel:协议地址选择的标签配置
- route:路由表条目
- rule:路由策略数据库中的规则
常用实例:
这里直接参考教程:
https://linux.cn/article-3144-1.html
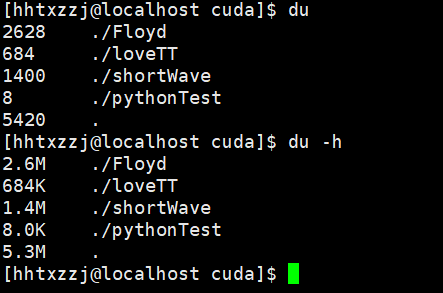
du
disk usage 用于显示目录或文件的大小
du [-abcDhHklmsSx][-L <符号连接>][-X <文件>][--block-size][--exclude=<目录或文件>][--max-depth=<目录层数>][--help][--version][目录或文件]
常用参数:
-a #显示目录中文件的大小 单位 KB 。
-b #显示目录中文件的大小,以字节byte为单位。
-c #显示目录中文件的大小,同时也显示总和;单位KB。
-k 、 -m 、#显示目录中文件的大小,-k 单位KB,-m 单位MB.
-s #仅显示目录的总值,单位KB。
更多参数:
- -a或-all 显示目录中个别文件的大小。
- -b或-bytes 显示目录或文件大小时,以byte为单位。
- -c或–total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
- -D或–dereference-args 显示指定符号连接的源文件大小。
- -h或–human-readable 以K,M,G为单位,提高信息的可读性。
- -H或–si 与-h参数相同,但是K,M,G是以1000为换算单位。
- -k或–kilobytes 以1024 bytes为单位。
- -l或–count-links 重复计算硬件连接的文件。
- -L<符号连接>或–dereference<符号连接> 显示选项中所指定符号连接的源文件大小。
- -m或–megabytes 以1MB为单位。
- -s或–summarize 仅显示总计。
- -S或–separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
- -x或–one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
- -X<文件>或–exclude-from=<文件> 在<文件>指定目录或文件。
- –exclude=<目录或文件> 略过指定的目录或文件。
- –max-depth=<目录层数> 超过指定层数的目录后,予以忽略。
- –help 显示帮助。
- –version 显示版本信息。
dig
不是自带命令, 可能不会考
iptables
启动指令:service iptables start
重启指令:service iptables restart
关闭指令:service iptables stop
过于复杂, 先放着
sestatus
sestatus命令将显示SELinux启用状态。还显示有关SELinux的其他信息
感觉用处不是很大, 先放着
history
“history”命令就是历史记录。它显示了在终端中所执行过的所有命令的历史
常用操作:
history # 显示终端执行过的命令
history 10 # 显示最近10条终端执行过的命令
Ctrl+r # 搜索已经执行过的命令,它可以你写命令时自动补全
-c 将目前shell中的所有history命令消除
-a 将目前新增的命令写入histfiles, 默认写入~/.bash_history
-r 将histfiles内容读入到目前shell的history记忆中
-w 将目前history记忆的内容写入到histfiles
df
命令用于显示磁盘分区上的可使用的磁盘空间
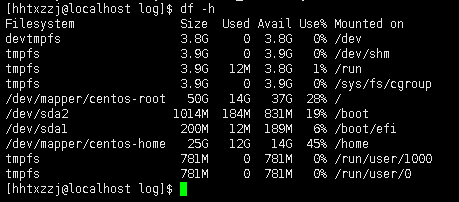
默认单位是kb, 可使用-h人性化显示
常用参数:
- df -a 查看全部的文件系统
- df -h查看磁盘使用情况
- df -i 查看inode使用情况
更多:
-a或–all:包含全部的文件系统;
–block-size=<区块大小>:以指定的区块大小来显示区块数目;
-h或–human-readable:以可读性较高的方式来显示信息;
-H或–si:与-h参数相同,但在计算时是以1000 Bytes为换算单位而非1024 Bytes;
-i或–inodes:显示inode的信息;
-k或–kilobytes:指定区块大小为1024字节;
-l或–local:仅显示本地端的文件系统;
-m或–megabytes:指定区块大小为1048576字节;
–no-sync:在取得磁盘使用信息前,不要执行sync指令,此为预设值;
-P或–portability:使用POSIX的输出格式;
–sync:在取得磁盘使用信息前,先执行sync指令;
-t<文件系统类型>或–type=<文件系统类型>:仅显示指定文件系统类型的磁盘信息;
-T或–print-type:显示文件系统的类型;
-x<文件系统类型>或–exclude-type=<文件系统类型>:不要显示指定文件系统类型的磁盘信息;
–help:显示帮助;
–version:显示版本信息。
netstat
-a或--all: 显示所有连线中的Socket;
-A<网络类型>或--<网络类型>: 列出该网络类型连线中的相关地址;
-c或--continuous: 持续列出网络状态;
-C或--cache: 显示路由器配置的快取信息;
-e或--extend: 显示网络其他相关信息;
-F或--fib: 显示FIB;
-g或--groups: 显示多重广播功能群组组员名单;
-h或--help: 在线帮助;
-i或--interfaces: 显示网络界面信息表单;
-l或--listening: 显示监控中的服务器的Socket;
-M或--masquerade: 显示伪装的网络连线;
-n或--numeric: 直接使用ip地址,而不通过DNS(能加快速度)
-N或--netlink或--symbolic 显示网络硬件外围设备的符号连接名称;
-o或--timers: 显示计时器;
-p或--programs: 显示正在使用Socket的程序识别码和程序名称;
-r或--route: 显示Routing Table;
-s或--statistice: 显示网络工作信息统计表;
-t或--tcp: 显示TCP传输协议的连线状况;
-u或--udp: 显示UDP传输协议的连线状况;
-v或--verbose: 显示指令执行过程;
-V或--version: 显示版本信息;
-w或--raw: 显示RAW传输协议的连线状况;
-x或--unix: 此参数的效果和指定"-A unix"参数相同;
--ip或--inet: 此参数的效果和指定"-A inet"参数相同。
常用实例:
列出端口:
netstat -a # 列出所有端口
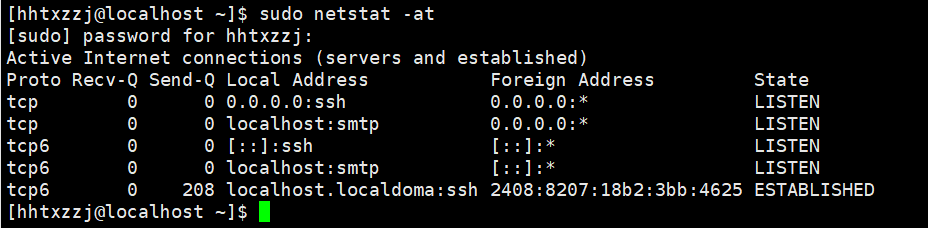
netstat -at # 列出所有TCP端口
netstat -au # 列出所有UDP端口
netstat -ax # 列出所有unix端口
netstat -atnlp # 直接使用ip地址列出所有处理监听状态的TCP端口,且加上程序名
显示每个协议的统计信息
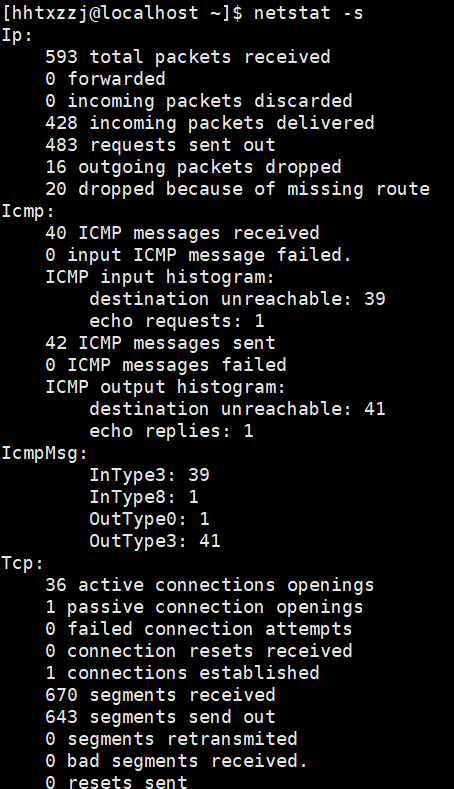
netstat -s # 显示所有端口的统计信息
netstat -st # 显示所有TCP的统计信息
netstat -su # 显示所有UDP的统计信息
显示核心路由信息
netstat -r # 显示所有端口的统计信息
netstat -rn # 显示所有TCP的统计信息

-
Destination:目标网络或者主机。
-
Gateway:网关地址,如果没有设置则为*。
-
Genmask:目标网络掩码;如果默认路由则用"0.0.0.0"。
-
Flags标志说明:
U Up表示此路由当前为启动状态 H Host,表示此网关为一主机 G Gateway,表示此网关为一路由器 R Reinstate Route,使用动态路由重新初始化的路由 D Dynamically,此路由是动态性地写入 M Modified,此路由是由路由守护程序或导向器动态修改 ! 表示此路由当前为关闭状态 -
Iface:对于这个路由,数据包将要发送到那个接口(网卡)
输出信息解释:
TCP & UDP与unix不同
-
Proto:协议名(tcp协议还是udp协议)
-
recv-Q:网络接收队列
-
send-Q:网路发送队列
-
Local Address 监听地址
如果是0.0.0.0打头, 则监听的是所有地址
-
Foreign Address 与本机端口通信的外部socket
显示规则与Local Address相同
-
State 链路状态
总共有12种, 前11种对应TCP握手挥手的几个状态:
- LISTEN :首先服务端需要打开一个socket进行监听,状态为LISTEN./*The socket is listening for incoming connections. 侦听来自远方TCP端口的连接请求 /
- *SYN_SENT:客户端通过应用程序调用connect进行activeopen.于是客户端tcp发送一个SYN以请求建立一个连接.之后状态SYN_SENT。/*The socket is actively attempting to establish aconnection. 在发送连接请求后等待匹配的连接请求 /
- SYN_RECV:服务端应发出ACK确认客户端的 SYN,同时自己向客户端发送一个SYN.之后状态置为SYN_RECV/ A connection request has been received from the network. 在收到和发送一个连接请求后等待对连接请求的确认 /
- ESTABLISHED:代表一个打开的连接,双方可以进行或已经在数据交互了。/ The socket has an established connection. 代表一个打开的连接,数据可以传送给用户 /
- FIN_WAIT1:主动关闭(activeclose)端应用程序调用close,于是其TCP发出FIN请求主动关闭连接,之后进入FIN_WAIT1状态./ The socket is closed, and the connection is shutting down. 等待远程TCP的连接中断请求,或先前的连接中断请求的确认 /
- CLOSE_WAIT:被动关闭(passiveclose)端TCP接到FIN后,就发出ACK以回应FIN请求(它的接收也作为文件结束符传递给上层应用程序),并进入CLOSE_WAIT./ The remote end has shut down, waiting for the socketto close. 等待从本地用户发来的连接中断请求 /
- FIN_WAIT2:主动关闭端接到ACK后,就进入了FIN-WAIT-2./ Connection is closed, and the socket is waiting for a shutdownfrom the remote end. 从远程TCP等待连接中断请求 /
- LAST_ACK:被动关闭端一段时间后,接收到文件结束符的应用程 序将调用CLOSE关闭连接。这导致它的TCP也发送一个 FIN,等待对方的ACK.就进入了LAST-ACK./ The remote end has shut down, and the socket is closed. Waiting foracknowledgement. 等待原来发向远程TCP的连接中断请求的确认 /
- TIME_WAIT:在主动关闭端接收到FIN后,TCP 就发送ACK包,并进入TIME-WAIT状态。/ Thesocket is waiting after close to handle packets still in the network.等待足够的时间以确保远程TCP接收到连接中断请求的确认*/*
- CLOSING:比较少见./ Bothsockets are shut down but we still don’t have all our datasent. 等待远程TCP对连接中断的确认 /
- *CLOSED:被动关闭端在接受到ACK包后,就进入了closed的状态。连接结束./*The socket is not being used. 没有任何连接状态 /
- UNKNOWN:未知的Socket状态。/ Thestate of the socket is unknown. */
crontab
这个直接看之前的实操
uname
unix name
用于显示电脑以及操作系统的相关信息
常用参数:
-a或--all 显示全部的信息。
-m或--machine 显示电脑类型。
-n或--nodename 显示在网络上的主机名称。
-r或--release 显示操作系统的发行编号。
-s或--sysname 显示操作系统名称。
-v 显示操作系统的版本。
--help 显示帮助。
--version 显示版本信息。
uptime
uptime 命令告诉你系统启动up了(运行了)多长时间
几个参数
-p, --pretty 人性化显示
-h, --help 显示帮助
-s, --since system up since
-V, --version output version information and exit
mount
mount命令是经常会使用到的命令,它用于挂载Linux系统外的文件
语法:
mount [-hV]
mount -a [-fFnrsvw] [-t vfstype]
mount [-fnrsvw] [-o options [,...]] device | dir
mount [-fnrsvw] [-t vfstype] [-o options] device dir
参数:
-V:显示程序版本
-h:显示辅助讯息
-v:显示较讯息,通常和 -f 用来除错。
-a:将 /etc/fstab 中定义的所有档案系统挂上。
-F:这个命令通常和 -a 一起使用,它会为每一个 mount 的动作产生一个行程负责执行。在系统需要挂上大量 NFS 档案系统时可以加快挂上的动作。
-f:通常用在除错的用途。它会使 mount 并不执行实际挂上的动作,而是模拟整个挂上的过程。通常会和 -v 一起使用。
-n:一般而言,mount 在挂上后会在 /etc/mtab 中写入一笔资料。但在系统中没有可写入档案系统存在的情况下可以用这个选项取消这个动作。
-s-r:等于 -o ro
-w:等于 -o rw
-L:将含有特定标签的硬盘分割挂上。
-U:将档案分割序号为 的档案系统挂下。-L 和 -U 必须在/proc/partition 这种档案存在时才有意义。
-t:指定档案系统的型态,通常不必指定。mount 会自动选择正确的型态。
-o async:打开非同步模式,所有的档案读写动作都会用非同步模式执行。
-o sync:在同步模式下执行。
-o atime、-o noatime:当 atime 打开时,系统会在每次读取档案时更新档案的『上一次调用时间』。当我们使用 flash 档案系统时可能会选项把这个选项关闭以减少写入的次数。
-o auto、-o noauto:打开/关闭自动挂上模式。
-o defaults:使用预设的选项 rw, suid, dev, exec, auto, nouser, and async.
-o dev、-o nodev-o exec、-o noexec允许执行档被执行。
-o suid、-o nosuid:
允许执行档在 root 权限下执行。
-o user、-o nouser:使用者可以执行 mount/umount 的动作。
-o remount:将一个已经挂下的档案系统重新用不同的方式挂上。例如原先是唯读的系统,现在用可读写的模式重新挂上。
-o ro:用唯读模式挂上。
-o rw:用可读写模式挂上。
-o loop=:使用 loop 模式用来将一个档案当成硬盘分割挂上系统。
umount
语法:
umount [-ahnrvV][-t <文件系统类型>][文件系统]
参数:
-a 卸除/etc/mtab中记录的所有文件系统。
-h 显示帮助。
-n 卸除时不要将信息存入/etc/mtab文件中。
-r 若无法成功卸除,则尝试以只读的方式重新挂入文件系统。
-t<文件系统类型> 仅卸除选项中所指定的文件系统。
-v 执行时显示详细的信息。
-V 显示版本信息。
[文件系统] 除了直接指定文件系统外,也可以用设备名称或挂入点来表示文件系统。
nice & renice
nice命令以更改过的优先序来执行程序,如果未指定程序,则会印出目前的排程优先序,内定的 adjustment 为 10,范围为 -20(最高优先序)到 19(最低优先序)
renice命令用于重新指定一个或多个行程(Process)的优先序(一个或多个将根据参数而定)
“nice”是指“niceness”,即友善度、谦让度。用于进程中,表示进程的优先级,也即进程的友善度。niceness值为负时,表示高优先级,能提前执行和获得更多的资源,对应低友善度;反之,则表示低优先级,高友善度
语法
nice [-n adjustment] [-adjustment] [--adjustment=adjustment] [--help] [--version] [command [arg...]]
参数说明:
- -n adjustment, -adjustment, --adjustment=adjustment 皆为将该原有优先序的增加 adjustment
- –help 显示求助讯息
- –version 显示版本资讯
语法
renice priority [[-p] pid ...] [[-g] pgrp ...] [[-u] user ...]
参数说明:
- -p pid 重新指定行程的 id 为 pid 的行程的优先序
- -g pgrp 重新指定行程群组(process group)的 id 为 pgrp 的行程 (一个或多个) 的优先序
- -u user 重新指定行程拥有者为 user 的行程的优先序
其他命令:
echo:
-n 不输出末尾的换行符
-e 启用反斜杠转义的解释
-E 禁用反斜杠转义的解释(默认)
seq
用于生成一个序列, 常用在shell中
语法结构:
seq [选项]... 尾数
seq [选项]... 首数 尾数
seq [选项]... 首数 增量 尾数
常用参数:
-f, --format=格式 使用printf 样式的浮点格式
-s, --separator=字符串 使用指定字符串分隔数字(默认使用:\n)
-w, --equal-width 在列前添加0 使得宽度相同【自动补位】
--help 显示此帮助信息并退出
--version 显示版本信息并退出
例子:
[hhtxzzj@localhost ~]$ seq -s "#" 1 5
1#2#3#4#5
[hhtxzzj@localhost ~]$ seq 1 5
1
2
3
4
5
xargs
参考博客:
https://www.runoob.com/linux/linux-comm-xargs.html
expr
参考博客:
https://www.cnblogs.com/chengjian-physique/p/8878341.html
expr为shell中很重要的命令
expr命令可以实现数值运算、数值或字符串比较、字符串匹配、字符串提取、字符串长度计算等功能。它还具有几个特殊功能,判断变量或参数是否为整数、是否为空、是否为0等
bc:
内置计算器, 常用与shell编程
几个常用的参数:
-h, --help
Print the usage and exit.
-i, --interactive
# 强制进入交互模式
-l, --mathlib
# 定义(启用)标准数学库, 用于进行高精度计算等操作
-w, --warn
# 对POSIX bc 的扩展给出警告
-s, --standard
# 准确的处理POSIX bc 语言
-q, --quiet
# 不要打印欢迎语句
-v, --version
Print the version number and copyright and quit.
4个内置变量, 计算时常会用到
| 变量名 | 作 用 |
|---|---|
| scale | 指定精度,也即小数点后的位数;默认为 0,也即不使用小数部分。 |
| ibase | 指定输入的数字的进制,默认为十进制。 |
| obase | 指定输出的数字的进制,默认为十进制。 |
| last 或者 . | 表示最近打印的数字 |
注意:obase 要尽量放在 ibase 前面,因为 ibase 设置后,后面的数字都是以 ibase 的进制来换算的
几个内置函数, 也经常用到
使用这些函数需要加-l参数
| 函数名 | 作用 |
|---|---|
| s(x) | 计算 x 的正弦值,x 是弧度值。 |
| c(x) | 计算 x 的余弦值,x 是弧度值。 |
| a(x) | 计算 x 的反正切值,返回弧度值。 |
| l(x) | 计算 x 的自然对数。 |
| e(x) | 求 e 的 x 次方。 |
| j(n, x) | 贝塞尔函数,计算从 n 到 x 的阶数。 |
awk
参考博客:
https://www.runoob.com/linux/linux-comm-awk.html
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具
命名取自三位创始人名字的首字母
wget
参考博客
https://www.cnblogs.com/ftl1012/p/9265699.html
非交互式的网络文件下载工具
语法结构:
wget [选项]... [URL]...
#如:
wget -O wordpress.zip http://www.minjieren.com/download.aspx?id=1080
常用参数:
开始:
-V, --version 显示 Wget 的版本信息并退出。
-h, --help 打印此帮助。
-b, --background 启动后转入后台。
-e, --execute=COMMAND 运行一个‘.wgetrc’风格的命令。
登入并输入文件:
-o, --output-file=FILE 将信息写入 FILE。
-a, --append-output=FILE 将信息添加至 FILE。
-d, --debug 打印大量调试信息。
-q, --quiet 安静模式(无信息输出)。
-v, --verbose 详尽的输出(此为默认值)。
-nv, --no-verbose 关闭详尽输出,但不进入安静模式。
-i, --input-file=FILE 下载本地或外部 FILE 中的 URLs。
-F, --force-html 把输入文件当成 HTML 文件。
-B, --base=URL 解析与 URL 相关的
HTML 输入文件(由 -i -F 选项指定)。
下载:
-t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。
--retry-connrefused 即使拒绝连接也是重试。
-O, --output-document=FILE 将文档写入 FILE。
-nc, --no-clobber 不要重复下载已存在的文件。
-c, --continue 继续下载部分下载的文件。
--progress=TYPE 选择进度条类型。
-N, --timestamping 只获取比本地文件新的文件。
-S, --server-response 打印服务器响应。
--spider 不下载任何文件。
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。
--dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。
--connect-timeout=SECS 设置连接超时为 SECS 秒。
--read-timeout=SECS 设置读取超时为 SECS 秒。
-w, --wait=SECONDS 等待间隔为 SECONDS 秒。
--waitretry=SECONDS 在取回文件的重试期间等待 1..SECONDS 秒。
--random-wait 取回时等待 0...2*WAIT 秒。
--no-proxy 关闭代理。
-Q, --quota=NUMBER 设置取回配额为 NUMBER 字节。
--bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)。
--limit-rate=RATE 限制下载速率为 RATE。
--no-dns-cache 关闭 DNS 查寻缓存。
--restrict-file-names=OS 限定文件名中的字符为 OS 允许的字符。
--ignore-case 匹配文件/目录时忽略大小写。
-4, --inet4-only 仅连接至 IPv4 地址。
-6, --inet6-only 仅连接至 IPv6 地址。
--prefer-family=FAMILY 首先连接至指定协议的地址
FAMILY 为 IPv6,IPv4 或是 none。
--user=USER 将 ftp 和 http 的用户名均设置为 USER。
--password=PASS 将 ftp 和 http 的密码均设置为 PASS。
--ask-password 提示输入密码。
--no-iri 关闭 IRI 支持。
--local-encoding=ENC IRI 使用 ENC 作为本地编码。
--remote-encoding=ENC 使用 ENC 作为默认远程编码。
目录:
-nd, --no-directories 不创建目录。
-x, --force-directories 强制创建目录。
-nH, --no-host-directories 不要创建主目录。
--protocol-directories 在目录中使用协议名称。
-P, --directory-prefix=PREFIX 以 PREFIX/... 保存文件
--cut-dirs=NUMBER 忽略 NUMBER 个远程目录路径。
HTTP 选项:
--http-user=USER 设置 http 用户名为 USER。
--http-password=PASS 设置 http 密码为 PASS。
--no-cache 不在服务器上缓存数据。
--default-page=NAME 改变默认页
(默认页通常是“index.html”)。
-E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档。
--ignore-length 忽略头部的‘Content-Length’区域。
--header=STRING 在头部插入 STRING。
--max-redirect 每页所允许的最大重定向。
--proxy-user=USER 使用 USER 作为代理用户名。
--proxy-password=PASS 使用 PASS 作为代理密码。
--referer=URL 在 HTTP 请求头包含‘Referer: URL’。
--save-headers 将 HTTP 头保存至文件。
-U, --user-agent=AGENT 标识为 AGENT 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive(永久连接)。
--no-cookies 不使用 cookies。
--load-cookies=FILE 会话开始前从 FILE 中载入 cookies。
--save-cookies=FILE 会话结束后保存 cookies 至 FILE。
--keep-session-cookies 载入并保存会话(非永久) cookies。
--post-data=STRING 使用 POST 方式;把 STRING 作为数据发送。
--post-file=FILE 使用 POST 方式;发送 FILE 内容。
--content-disposition 当选中本地文件名时
允许 Content-Disposition 头部(尚在实验)。
--auth-no-challenge send Basic HTTP authentication information
without first waiting for the server's
challenge.
HTTPS (SSL/TLS) 选项:
--secure-protocol=PR 选择安全协议,可以是 auto、SSLv2、
SSLv3 或是 TLSv1 中的一个。
--no-check-certificate 不要验证服务器的证书。
--certificate=FILE 客户端证书文件。
--certificate-type=TYPE 客户端证书类型, PEM 或 DER。
--private-key=FILE 私钥文件。
--private-key-type=TYPE 私钥文件类型, PEM 或 DER。
--ca-certificate=FILE 带有一组 CA 认证的文件。
--ca-directory=DIR 保存 CA 认证的哈希列表的目录。
--random-file=FILE 带有生成 SSL PRNG 的随机数据的文件。
--egd-file=FILE 用于命名带有随机数据的 EGD 套接字的文件。
FTP 选项:
--ftp-user=USER 设置 ftp 用户名为 USER。
--ftp-password=PASS 设置 ftp 密码为 PASS。
--no-remove-listing 不要删除‘.listing’文件。
--no-glob 不在 FTP 文件名中使用通配符展开。
--no-passive-ftp 禁用“passive”传输模式。
--retr-symlinks 递归目录时,获取链接的文件(而非目录)。
递归下载:
-r, --recursive 指定递归下载。
-l, --level=NUMBER 最大递归深度( inf 或 0 代表无限制,即全部下载)。
--delete-after 下载完成后删除本地文件。
-k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件。
-K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
-m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
-p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
--strict-comments 开启 HTML 注释的精确处理(SGML)。
递归接受/拒绝:
-A, --accept=LIST 逗号分隔的可接受的扩展名列表。
-R, --reject=LIST 逗号分隔的要拒绝的扩展名列表。
-D, --domains=LIST 逗号分隔的可接受的域列表。
--exclude-domains=LIST 逗号分隔的要拒绝的域列表。
--follow-ftp 跟踪 HTML 文档中的 FTP 链接。
--follow-tags=LIST 逗号分隔的跟踪的 HTML 标识列表。
--ignore-tags=LIST 逗号分隔的忽略的 HTML 标识列表。
-H, --span-hosts 递归时转向外部主机。
-L, --relative 只跟踪有关系的链接。
-I, --include-directories=LIST 允许目录的列表。
-X, --exclude-directories=LIST 排除目录的列表。
-np, --no-parent 不追溯至父目录。
sed
参考博客:
https://www.runoob.com/linux/linux-comm-sed.html
sed是一种流编辑器,它是文本处理中非常好的工具,能够完美的配合正则表达式使用,功能非常强大
处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件,可以将数据行进行替换、删除、新增、选取等特定工作,简化对文件的反复操作,编写转换程序等
语法结构:
# sed的命令格式:
sed [options] 'command' file(s);
# sed的脚本格式:
sed [options] -f scriptfile file(s);
常用参数:
-e :直接在命令行模式上进行sed动作编辑,此为默认选项;
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
-i :直接修改文件内容;
-n :只打印模式匹配的行;
-r :支持扩展表达式;
-h或--help:显示帮助;
-V或--version:显示版本信息。
动作说明:
a\ 在当前行下面插入文本;
i\ 在当前行上面插入文本;
c\ 把选定的行改为新的文本;
d 删除,删除选择的行;
D 删除模板块的第一行;
s 替换指定字符;
h 拷贝模板块的内容到内存中的缓冲区;
H 追加模板块的内容到内存中的缓冲区;
g 获得内存缓冲区的内容,并替代当前模板块中的文本;
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面;
l 列表不能打印字符的清单;
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令;
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码;
p 打印模板块的行。 P(大写) 打印模板块的第一行;
q 退出Sed;
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾;
r file 从file中读行;
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
w file 写并追加模板块到file末尾;
W file 写并追加模板块的第一行到file末尾;
! 表示后面的命令对所有没有被选定的行发生作用;
= 打印当前行号;
# 把注释扩展到下一个换行符以前;
替换标记:
g 表示行内全面替换;
p 表示打印行;
w 表示把行写入一个文件;
x 表示互换模板块中的文本和缓冲区中的文本;
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式);
\1 子串匹配标记;
& 已匹配字符串标记;
正则:
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行;
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行;
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d;
* 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行;
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed;
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行;
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers;
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**;
\< 匹配单词的开始,如:/\
\> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行;
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行;
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行;
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行;
sed能实现的功能非常多, 有需要的时候再来看吧
功能参考博客:
https://www.cnblogs.com/ztteng/articles/3112599.html
字符串替换:
sed -i 's/Search_String/Replacement_String/g' Input_File
实践出来几个问题:
- sed的
tr
参考博客:
https://www.runoob.com/linux/linux-comm-tr.html
tr 命令用于转换或删除文件中的字符
tr 指令从标准输入设备读取数据,经过字符串转译后,将结果输出到标准输出设备
sort
参考博客:
https://www.runoob.com/linux/linux-comm-sort.html
语法结构:
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
常用参数
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- –help 显示帮助。
- –version 显示版本信息。
join
参考博客:
https://www.runoob.com/linux/linux-comm-join.html
join命令用于将两个文件中,指定栏位内容相同的行连接起来。
找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。
先具体了解一下join的作用:
$ cat testfile_1 #testfile_1文件中的内容
Hello 95 #例如,本例中第一列为姓名,第二列为数额
Linux 85
test 30
$ cat testfile_2 #testfile_2文件中的内容
Hello 2005 #例如,本例中第一列为姓名,第二列为年份
Linux 2009
test 2006
$ join testfile_1 testfile_2 #连接testfile_1、testfile_2中的内容
Hello 95 2005 #连接后显示的内容
Linux 85 2009
test 30 2006
如果两个文件的顺序互换, 则会输出结果也将互换
$ join testfile_2 testfile_1 #改变文件顺序连接两个文件
Hello 2005 95 #连接后显示的内容
Linux 2009 85
test 2006 30
cut
参考博客:
https://www.runoob.com/linux/linux-comm-cut.html
cut命令用于显示每行从开头算起 num1 到 num2 的文字
能够很方便的指定分隔符对字符串进行分割
语法结构:
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
参数:
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示第几个分割块, index>=1
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
注意:
- cut会处理文件的每一行
- 如果不指定File参数, 则默认从标准输入读取
- 必须指定-b、-c 或 -f 之一
栗子:
cat /etc/passwd | cut -d":" -f1,5
指定分隔符为:, 并显示第一行和第五行
chattr
chattr常用与以超越用户权限的方式改变文件属性
语法结构:
chattr [ -RVf ] [ -v version ] [ mode ] files...
常用参数:
-A:即Atime,告诉系统不要修改对这个文件的最后访问时间。
-S:即Sync,一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘。
-a:即Append Only,系统只允许在这个文件之后追加数据,不允许任何进程覆盖或截断这个文件。如果目录具有这个属性,系统将只允许在这个目录下建立和修改文件,而不允许删除任何文件。
-b:不更新文件或目录的最后存取时间。
-c:将文件或目录压缩后存放。
-d:当dump程序执行时,该文件或目录不会被dump备份。
-D:检查压缩文件中的错误。
-i:即Immutable,系统不允许对这个文件进行任何的修改。如果目录具有这个属性,那么任何的进
程只能修改目录之下的文件,不允许建立和删除文件。
-s:彻底删除文件,不可恢复,因为是从磁盘上删除,然后用0填充文件所在区域。
-u:当一个应用程序请求删除这个文件,系统会保留其数据块以便以后能够恢复删除这个文件,用来防止意外删除文件或目录。
-t:文件系统支持尾部合并(tail-merging)。
-X:可以直接访问压缩文件的内容。
lsattr:
参考博客:
https://www.runoob.com/linux/linux-comm-lsattr.html
用chattr执行改变文件或目录的属性,需要用lsattr指令查询其属性。
语法结构:
lsattr [-adlRvV][文件或目录...]
参数:
-a 显示所有文件和目录,包括以"."为名称开头字符的额外内建,现行目录"."与上层目录".."。
-d 显示,目录名称,而非其内容。
-l 此参数目前没有任何作用。
-R 递归处理,将指定目录下的所有文件及子目录一并处理。
-v 显示文件或目录版本。
-V 显示版本信息。
fdisk
参考博客:
https://www.runoob.com/linux/linux-comm-fdisk.html
Linux fdisk是一个创建和维护分区表的程序,它兼容DOS类型的分区表、BSD或者SUN类型的磁盘列表。
语法结构:
fdisk [必要参数][选择参数]
必要参数:
- -l 列出素所有分区表
- -u 与"-l"搭配使用,显示分区数目
选择参数:
- -s<分区编号> 指定分区
- -v 版本信息
菜单操作说明
- m :显示菜单和帮助信息
- a :活动分区标记/引导分区
- d :删除分区
- l :显示分区类型
- n :新建分区
- p :显示分区信息
- q :退出不保存
- t :设置分区号
- v :进行分区检查
- w :保存修改
- x :扩展应用,高级功能
mkfs
mkfs(make file system)命令用于在特定的分区上建立 linux 文件系统
语法结构:
mkfs [-V] [-t fstype] [fs-options] filesys [blocks]
参数 :
- device : 预备检查的硬盘分区,例如:/dev/sda1
- -V : 详细显示模式
- -t : 给定档案系统的型式,Linux 的预设值为 ext2
- -c : 在制做档案系统前,检查该partition 是否有坏轨
- -l bad_blocks_file : 将有坏轨的block资料加到 bad_blocks_file 里面
- block : 给定 block 的大小
dd
参考博客:
https://www.cnblogs.com/ginvip/p/6370836.html
convert an copy , 简称cc, 但是cc通常指代C Compiler, 所以就改为了dd
用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换
参数:
if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >
of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。
cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。
count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
conv=conversion:用指定的参数转换文件:
ascii:转换ebcdic为ascii
ebcdic:转换ascii为ebcdic
ibm:转换ascii为alternate ebcdic
block:把每一行转换为长度为cbs,不足部分用空格填充
unblock:使每一行的长度都为cbs,不足部分用空格填充
lcase:把大写字符转换为小写字符
ucase:把小写字符转换为大写字符
swab:交换输入的每对字节
noerror:出错时不停止
notrunc:不截短输出文件
sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
例子:
dd if=/dev/zero of=minifs bs=1024 count=1024
fg & bg
参考博客:
https://www.cnblogs.com/pengdonglin137/p/3416779.html
bg
将一个在后台暂停的命令,变成继续执行
fg
将后台中的命令调至前台继续运行
语法格式:
fg %工作号
bg %工作号
其中工作号就是jobs 中显示出的任务ID
jobs
参考博客;
https://www.cnblogs.com/pengdonglin137/p/3416779.html
jobs用于显示放到后台执行的进程
常用参数:
无参数: 显示 【任务ID】 状态status 程序名
-l 显示后台进程的信息,显示格式 [Job ID] [+-] PID CMD (当前任务用+表示,其他非当前为-)
-p 只显示PID
-r 只显示运行重的进程,任务的状态可为running、Terminated、stopped、done等

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









