









第一、把图片的三个通道矩阵转化为一个特征向量。这个特征向量的长度为长宽3.

二、一般X代表的是所有输入的一个矩阵,每一列就是一个特征向量,即一张图片。Y代表的是所有的输出。一个行向量。而W则是一个参数矩阵,W中的每一个元素都和X1 X2 X…中的每一个元素相乘得到一个最终值。

x和y的上标代表的是第i个样布的输入和输出
损失函数和代价函数用下图所示的公式:

如上图所示,我们最终的目的是要找到让J 最小的w和b,即图中的最低点,采用的方法就是梯度衰减法,不断的让J沿着有关w的下降最快的方向行走。学习率就是每次走的步长。梯度衰减的公式如下,其中约定dw表示dJ/dW

通过反向传播来优化参数就是一个链式法则偏导过程,求出J对于各个输入量参数的关系,然后找到偏导(下降最快的地方),然后开始迭代,更新参数,让J 变的更小

在神经网络里,一个特征向量x1对应一个参数向量w??每一个神经元对应每一个输入也有一个W??
目前理解为w的长度应等于特征向量的长度
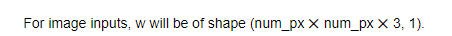
一个简单的神经网络的梯度下降算法如下,这张图包含了dw和db的推导

最后,关于用numpy写一个简单的反向传播识别猫的神经网络做一个总结,总的步骤分为以下4步:

算法描述如下
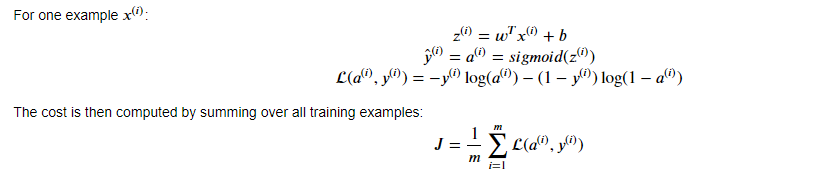
算法部分搭建步骤如下

正向反向传播的步骤及相关公式如下:

梯度衰减,优化的步骤如下:

预测函数的步骤如下:
















 4024
4024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









