






SAM 2 是 Meta 的Segment Anything Model (SAM) 的第二代产品,官网地址
官方操作教程写得很清楚了,这里主要介绍一下如何通过YOLO来快速实现分割。
1、安装
安装非常简单,要安装SAM 2,请使用以下命令。首次使用时,所有SAM 2 型号都会自动下载。
pip install ultralytics2、预训练权重下载
官网下载,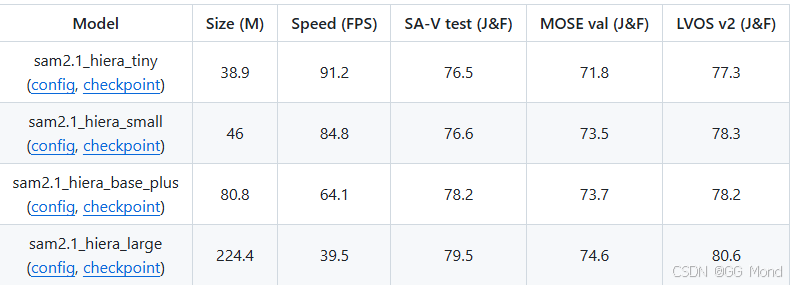
3、SAM 2 预测示例
from ultralytics import SAM
# Load a model
model = SAM("sam2.1_b.pt")
# Display model information (optional)
model.info()
# Run inference with bboxes prompt
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200])
# Run inference with single point
results = model(points=[900, 370], labels=[1])
# Run inference with multiple points
results = model(points=[[400, 370], [900, 370]], labels=[1, 1])
# Run inference with multiple points prompt per object
results = model(points=[[[400, 370], [900, 370]]], labels=[[1, 1]])
# Run inference with negative points prompt
results = model(points=[[[400, 370], [900, 370]]], labels=[[1, 0]])4、Surprise


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









