






kmalloc
cat /proc/slabinfo
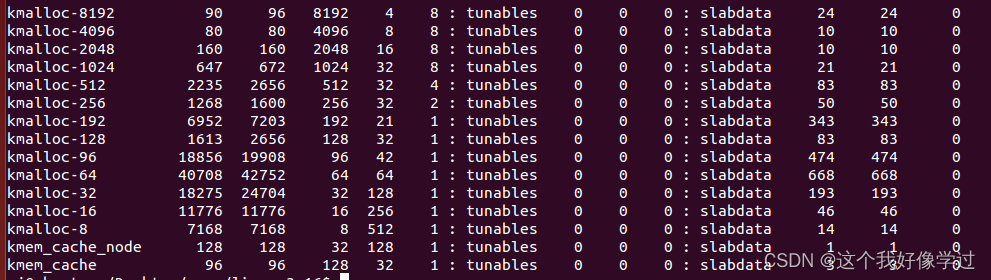
kmalloc也是基于slab机制,按照2^order创建对个slab描述符。在系统启动时通过函数 create_kmalloc_caches进行创建。从上图能够看到有8,16,32.....8192等等。
当分配n字节的内存块时,会向上对齐到上述的大小中。例如,申请30字节的内存块,会从kmalloc-32中分配一个对象出来。
void __init create_kmalloc_caches(unsigned long flags)
{
int i;
BUILD_BUG_ON(KMALLOC_MIN_SIZE > 256 ||
(KMALLOC_MIN_SIZE & (KMALLOC_MIN_SIZE - 1)));
for (i = 8; i < KMALLOC_MIN_SIZE; i += 8) {
int elem = size_index_elem(i);
if (elem >= ARRAY_SIZE(size_index))
break;
size_index[elem] = KMALLOC_SHIFT_LOW;
}
if (KMALLOC_MIN_SIZE >= 64) {
/*
* The 96 byte size cache is not used if the alignment
* is 64 byte.
*/
for (i = 64 + 8; i <= 96; i += 8)
size_index[size_index_elem(i)] = 7;
}
if (KMALLOC_MIN_SIZE >= 128) {
/*
* The 192 byte sized cache is not used if the alignment
* is 128 byte. Redirect kmalloc to use the 256 byte cache
* instead.
*/
for (i = 128 + 8; i <= 192; i += 8)
size_index[size_index_elem(i)] = 8;
}
for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
if (!kmalloc_caches[i]) {
kmalloc_caches[i] = create_kmalloc_cache(NULL,
1 << i, flags);
}
/*
* Caches that are not of the two-to-the-power-of size.
* These have to be created immediately after the
* earlier power of two caches
*/
if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)
kmalloc_caches[1] = create_kmalloc_cache(NULL, 96, flags);
if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)
kmalloc_caches[2] = create_kmalloc_cache(NULL, 192, flags);
}
/* Kmalloc array is now usable */
slab_state = UP;
for (i = 0; i <= KMALLOC_SHIFT_HIGH; i++) {
struct kmem_cache *s = kmalloc_caches[i];
char *n;
if (s) {
n = kasprintf(GFP_NOWAIT, "kmalloc-%d", kmalloc_size(i));
BUG_ON(!n);
s->name = n;
}
}
.................
}kmalloc:申请的大小如果超过KMALLOC_MAX_CACHE_SIZE,则通过kmalloc_large分配;反之通过__kmalloc分配
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
#endif
}
return __kmalloc(size, flags);
}
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, 0);
}可以看到__do_kmalloc最终也是调用slab_alloc,和普通的slab分配对象相同的接口
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
unsigned long caller)
{
struct kmem_cache *cachep;
void *ret;
cachep = kmalloc_slab(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = slab_alloc(cachep, flags, caller);
trace_kmalloc(caller, ret,
size, cachep->size, flags);
return ret;
}kmalloc_slab:主要是根据申请大小,选择从哪个slab中分配对象
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
{
int index;
if (unlikely(size > KMALLOC_MAX_SIZE)) {
WARN_ON_ONCE(!(flags & __GFP_NOWARN));
return NULL;
}
if (size <= 192) {
if (!size)
return ZERO_SIZE_PTR;
index = size_index[size_index_elem(size)];
} else
index = fls(size - 1);
#ifdef CONFIG_ZONE_DMA
if (unlikely((flags & GFP_DMA)))
return kmalloc_dma_caches[index];
#endif
return kmalloc_caches[index];
}vmalloc
kmalloc通过其原理可知,slab缓冲区建立在一大块物理地址连续的多个page上,因此里面的内存块的物理地址都是连续的。而通过vmalloc申请的内存块的虚拟地址是连续的,但是物理地址不一定连续。并且vmalloc申请的内存是以page大小对齐的。即时申请的内存块为1字节,也还是会分配1个page大小的内存块出来,因此适合分配大块的内存
GFP_KERNEL | __GFP_HIGHMEM说明会优先使用高端内存high_memory
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL | __GFP_HIGHMEM);
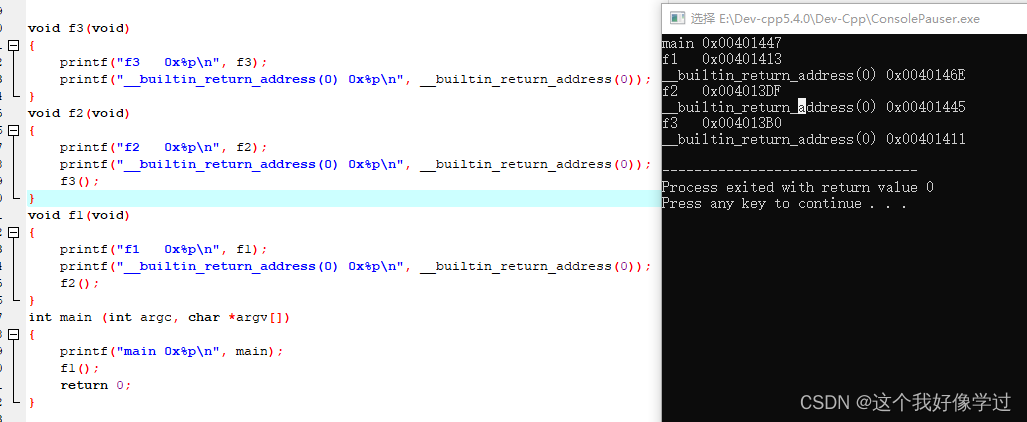
}- __builtin_return_address(0)的含义是,得到当前函数返回地址,即此函数被别的函数调用返回时的地址。f1调用f2,如果__builtin_return_address(0)在f2中,那此地址应该是f1中调用f2返回后的下一条指令地址。感觉比较像
- __builtin_return_address(1)的含义是,得到当前函数的调用者的返回地址。
内建函数 __builtin_return_address返回当前函数或其调用者的返回地址,参数LEVEL指定在栈上搜索farme栈的个数 ;
__builtin_return_address(0)表示在主调函数中的返回地址。f3中的__builtin_return_address(0)的地址应该在函数f2中,即0x004013DF < __builtin_return_address(0) < 0x00101413;0x00401411刚好在这个范围内。同样f2中的打印也刚好在f1 < x < main之间。并且刚好都只相差2(这个不知道为什么,可能需要看汇编才行)
static inline void *__vmalloc_node_flags(unsigned long size,
int node, gfp_t flags)
{
return __vmalloc_node(size, 1, flags, PAGE_KERNEL,
node, __builtin_return_address(0));
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, node, caller);
}书上说VMALLOC_START是在高端内存high_memory指定的地址0xc0000000的基础上加上8M(0x800000)的安全区域。VMALLOC_START = 0xc0800000。和我的环境能够吻合。VMALLOC_END = 0xff000000。vm大小为1000M

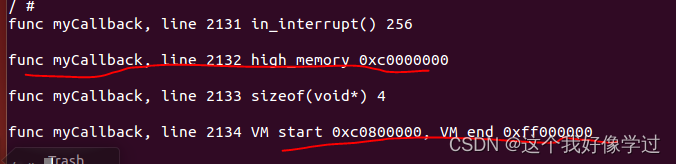
__vmalloc_node_range可以看到该函数中,会将申请的大小按照page大小进行对齐。因此最开始说了vmalloc申请的内存最后会是page的倍数。
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, int node, const void *caller)
{
struct vm_struct *area;
void *addr;
unsigned long real_size = size;
/* 申请的大小是按照PAGE_SIZE对齐 */
size = PAGE_ALIGN(size);
/* 申请的大小不能为0,不能大于系统总共的内存 */
if (!size || (size >> PAGE_SHIFT) > totalram_pages)
goto fail;
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNINITIALIZED,
start, end, node, gfp_mask, caller);
if (!area)
goto fail;
addr = __vmalloc_area_node(area, gfp_mask, prot, node);
if (!addr)
return NULL;
/*
* In this function, newly allocated vm_struct has VM_UNINITIALIZED
* flag. It means that vm_struct is not fully initialized.
* Now, it is fully initialized, so remove this flag here.
*/
clear_vm_uninitialized_flag(area);
/*
* A ref_count = 2 is needed because vm_struct allocated in
* __get_vm_area_node() contains a reference to the virtual address of
* the vmalloc'ed block.
*/
kmemleak_alloc(addr, real_size, 2, gfp_mask);
return addr;
fail:
warn_alloc_failed(gfp_mask, 0,
"vmalloc: allocation failure: %lu bytes\n",
real_size);
return NULL;
}
vmalloc会休眠,因此不能在中断上下文中使用。此外vmalloc除了会对申请大小按照4k对齐以外,还会增加一个guard page,在原有基础上还会增加4k大小 .这个会不会就是书上这么画的原因哦?但是我看va_end其实是包含了这个guard page的大小的
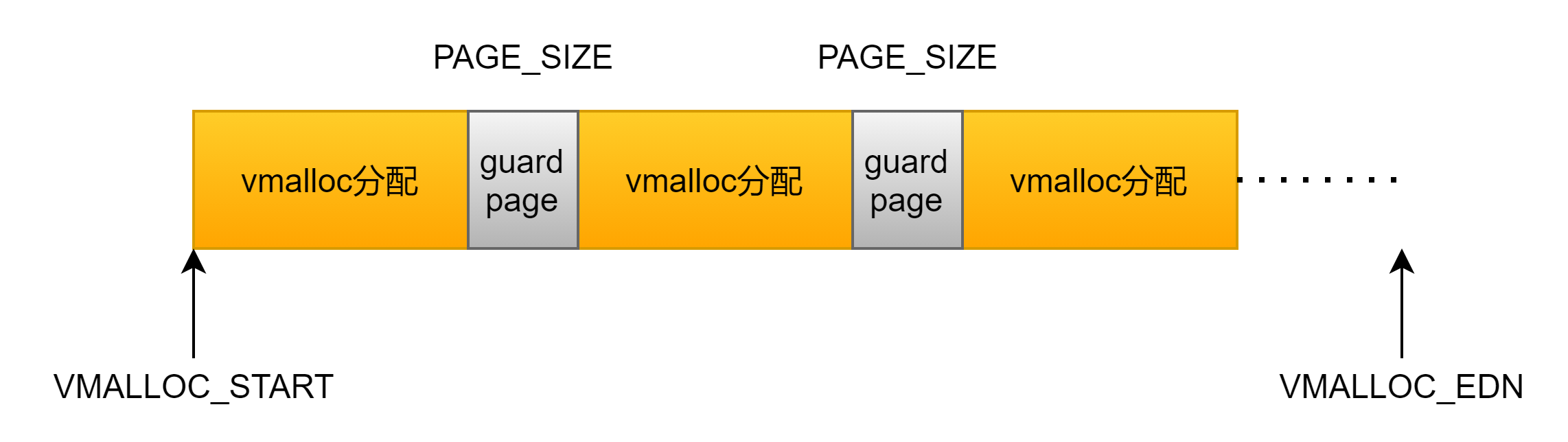
static struct vm_struct *__get_vm_area_node(unsigned long size,
unsigned long align, unsigned long flags, unsigned long start,
unsigned long end, int node, gfp_t gfp_mask, const void *caller)
{
struct vmap_area *va;
struct vm_struct *area;
/* 不能在中断上下文中,因为vmalloc会休眠 */
BUG_ON(in_interrupt());
if (flags & VM_IOREMAP)
align = 1ul << clamp(fls(size), PAGE_SHIFT, IOREMAP_MAX_ORDER);
size = PAGE_ALIGN(size);
if (unlikely(!size))
return NULL;
/*
申请一个vm_struct来描述vmalloc申请的区域
kzalloc_node往下追,最后会发现还是通过kmalloc从slab里面去分配
*/
area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!area))
return NULL;
/*
* We always allocate a guard page.
*/
/*
此外这里还会增加一个guard page
因此如果申请的4k,最后也会变为8k大小
*/
size += PAGE_SIZE;
va = alloc_vmap_area(size, align, start, end, node, gfp_mask);
if (IS_ERR(va)) {
kfree(area);
return NULL;
}
setup_vmalloc_vm(area, va, flags, caller);
return area;
}static struct vmap_area *alloc_vmap_area(unsigned long size,
unsigned long align,
unsigned long vstart, unsigned long vend,
int node, gfp_t gfp_mask)
{
struct vmap_area *va;
struct rb_node *n;
unsigned long addr;
int purged = 0;
struct vmap_area *first;
BUG_ON(!size);
BUG_ON(size & ~PAGE_MASK);
BUG_ON(!is_power_of_2(align));
va = kmalloc_node(sizeof(struct vmap_area),
gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!va))
return ERR_PTR(-ENOMEM);
/*
* Only scan the relevant parts containing pointers to other objects
* to avoid false negatives.
*/
kmemleak_scan_area(&va->rb_node, SIZE_MAX, gfp_mask & GFP_RECLAIM_MASK);
retry:
spin_lock(&vmap_area_lock);
/*
* Invalidate cache if we have more permissive parameters.
* cached_hole_size notes the largest hole noticed _below_
* the vmap_area cached in free_vmap_cache: if size fits
* into that hole, we want to scan from vstart to reuse
* the hole instead of allocating above free_vmap_cache.
* Note that __free_vmap_area may update free_vmap_cache
* without updating cached_hole_size or cached_align.
*/
if (!free_vmap_cache ||
size < cached_hole_size ||
vstart < cached_vstart ||
align < cached_align) {
nocache:
cached_hole_size = 0;
free_vmap_cache = NULL;
}
/* record if we encounter less permissive parameters */
cached_vstart = vstart;
cached_align = align;
/* find starting point for our search */
if (free_vmap_cache) {
first = rb_entry(free_vmap_cache, struct vmap_area, rb_node);
addr = ALIGN(first->va_end, align);
if (addr < vstart)
goto nocache;
if (addr + size < addr)
goto overflow;
} else {
addr = ALIGN(vstart, align);
if (addr + size < addr)
goto overflow;
n = vmap_area_root.rb_node;
first = NULL;
/*
vmap_area_root存放系统正在使用的vmalloc块
从红黑树vmap_area_root开始查找
书上说这个循环返回的是正在使用的最小的vmalloc区块
*/
while (n) {
struct vmap_area *tmp;
tmp = rb_entry(n, struct vmap_area, rb_node);
/* 查找一个块的va_start <= addr <= va_end */
if (tmp->va_end >= addr) {
first = tmp;
if (tmp->va_start <= addr)
break;
n = n->rb_left;
} else
n = n->rb_right;
}
if (!first)
goto found;
}
/* from the starting point, walk areas until a suitable hole is found */
/* 从找到的first开始,查找每个存在的vmalloc区块的缝隙hole能否容纳目前要分配的内存大小 */
while (addr + size > first->va_start && addr + size <= vend) {
if (addr + cached_hole_size < first->va_start)
cached_hole_size = first->va_start - addr;
addr = ALIGN(first->va_end, align);
if (addr + size < addr)
goto overflow;
if (list_is_last(&first->list, &vmap_area_list))
goto found;
first = list_entry(first->list.next,
struct vmap_area, list);
}
found:
if (addr + size > vend)
goto overflow;
va->va_start = addr;
va->va_end = addr + size;
va->flags = 0;
__insert_vmap_area(va);
free_vmap_cache = &va->rb_node;
spin_unlock(&vmap_area_lock);
BUG_ON(va->va_start & (align-1));
BUG_ON(va->va_start < vstart);
BUG_ON(va->va_end > vend);
return va;
overflow:
spin_unlock(&vmap_area_lock);
if (!purged) {
purge_vmap_area_lazy();
purged = 1;
goto retry;
}
if (printk_ratelimit())
printk(KERN_WARNING
"vmap allocation for size %lu failed: "
"use vmalloc=<size> to increase size.\n", size);
kfree(va);
return ERR_PTR(-EBUSY);
}__vmalloc_node_range->__vmalloc_area_node:计算vmalloc分配内存大小有几个page,然后使用alloc_pages分配物理页面,最后调用map_vm_area建立页面映射
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
const int order = 0;
struct page **pages;
unsigned int nr_pages, array_size, i;
gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
nr_pages = get_vm_area_size(area) >> PAGE_SHIFT;
array_size = (nr_pages * sizeof(struct page *));
area->nr_pages = nr_pages;
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) {
pages = __vmalloc_node(array_size, 1, nested_gfp|__GFP_HIGHMEM,
PAGE_KERNEL, node, area->caller);
area->flags |= VM_VPAGES;
} else {
pages = kmalloc_node(array_size, nested_gfp, node);
}
area->pages = pages;
if (!area->pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
gfp_t tmp_mask = gfp_mask | __GFP_NOWARN;
if (node == NUMA_NO_NODE)
page = alloc_page(tmp_mask);
else
page = alloc_pages_node(node, tmp_mask, order);
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
area->pages[i] = page;
}
if (map_vm_area(area, prot, &pages))
goto fail;
return area->addr;
fail:
warn_alloc_failed(gfp_mask, order,
"vmalloc: allocation failure, allocated %ld of %ld bytes\n",
(area->nr_pages*PAGE_SIZE), area->size);
vfree(area->addr);
return NULL;
}nt map_vm_area(struct vm_struct *area, pgprot_t prot, struct page ***pages)
{
unsigned long addr = (unsigned long)area->addr;
unsigned long end = addr + get_vm_area_size(area);
int err;
err = vmap_page_range(addr, end, prot, *pages);
if (err > 0) {
*pages += err;
err = 0;
}
return err;
}map_vm_area->vmap_page_range->vmap_page_range_noflush:
建立页面映射关系。pgd_offset_k从init_mm中获取执行pgd页目录项的基地址,然后通过addr来找到对应的PGD表项。循环调用vmap_pud_range处理PGD页表
static int vmap_page_range_noflush(unsigned long start, unsigned long end,
pgprot_t prot, struct page **pages)
{
pgd_t *pgd;
unsigned long next;
unsigned long addr = start;
int err = 0;
int nr = 0;
BUG_ON(addr >= end);
pgd = pgd_offset_k(addr);
do {
next = pgd_addr_end(addr, end);
err = vmap_pud_range(pgd, addr, next, prot, pages, &nr);
if (err)
return err;
} while (pgd++, addr = next, addr != end);
return nr;
}
malloc:
malloc是c函数库封装的一个函数,该函数最终是通过系统调用brk是申请内存的。
每个用户进程都拥有3G虚拟地址空间(不一定为3:1,比例可以改变),1G内核空间。用户空间由保留区、可执行文件的代码段、数据段以及堆区和栈区组成。堆区和栈区是动态变化的。堆向上生长,栈区向下生长。系统调用brk分配的内存属于堆区,它从数据段顶部end_data开始分配,到用户栈底部截止。每次分配空间就是将这个边界向上推进一段。中间这个mmap还不知道是干什么的

SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long rlim, retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
unsigned long min_brk;
bool populate;
down_write(&mm->mmap_sem);
#ifdef CONFIG_COMPAT_BRK
/*
* CONFIG_COMPAT_BRK can still be overridden by setting
* randomize_va_space to 2, which will still cause mm->start_brk
* to be arbitrarily shifted
*/
if (current->brk_randomized)
min_brk = mm->start_brk;
else
min_brk = mm->end_data;//数据段的结束地址
#else
min_brk = mm->start_brk;//min_brk是brk申请的下界
#endif
if (brk < min_brk)//请求边界小于min_brk,无效请求
goto out;
/*
* Check against rlimit here. If this check is done later after the test
* of oldbrk with newbrk then it can escape the test and let the data
* segment grow beyond its set limit the in case where the limit is
* not page aligned -Ram Gupta
*/
rlim = rlimit(RLIMIT_DATA);
if (rlim < RLIM_INFINITY && (brk - mm->start_brk) +
(mm->end_data - mm->start_data) > rlim)
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);//mm->brk应该是记录的当前brk的边界
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {//新边界<老边界,表示需要释放空间
if (!do_munmap(mm, newbrk, oldbrk-newbrk))
goto set_brk;
goto out;
}
/* 以老边界oldbrk去查找系统中是否有一块已经存在的VMA */
/* Check against existing mmap mappings. */
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
goto out;
set_brk:
mm->brk = brk;
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
up_write(&mm->mmap_sem);
if (populate)/* 表示需要马上分配物理内存,并建立映射 */
mm_populate(oldbrk, newbrk - oldbrk);
return brk;
out:
retval = mm->brk;
up_write(&mm->mmap_sem);
return retval;
}static unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct * mm = current->mm;
struct vm_area_struct * vma, * prev;
unsigned long flags;
struct rb_node ** rb_link, * rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(len);//申请的内存大小需要也页面大小进行对齐
if (!len)
return addr;
flags = VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;
/* 判断虚拟内存空间是否有足够的空间,并返回一段没有映射过空间的起始地址 */
error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);
if (error & ~PAGE_MASK)
return error;
error = mlock_future_check(mm, mm->def_flags, len);
if (error)
return error;
/*
* mm->mmap_sem is required to protect against another thread
* changing the mappings in case we sleep.
*/
verify_mm_writelocked(mm);
/*
* Clear old maps. this also does some error checking for us
*/
munmap_back:
/* 根据addr查找最合适插入到红黑树的节点 */
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
goto munmap_back;
}
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* 查看能不能合并addr附近的VMA,如果不行,则重新创建一个VMA */
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
/* 不能合并,创建一个新的VMA */
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
/* VM_LOCKED表示需要马上分配物理内存并建立映射 */
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return addr;//返回VAM的起始地址
}do_brk其实就只是分配了一个虚拟地址给malloc,并未将这个虚拟地址和物理内存建立映射,也就是并没有为其分配物理内存。物理内存的分配只有当指定VM_LOCK或者是用户去访问这个虚拟地址发生缺页中断时。
当指定VM_LOCK标志时,表示需要马上为这块进程的地址空间VMA分配物理页并建立映射。
static inline void mm_populate(unsigned long addr, unsigned long len)
{
/* Ignore errors */
(void) __mm_populate(addr, len, 1);
}int __mm_populate(unsigned long start, unsigned long len, int ignore_errors)
{
struct mm_struct *mm = current->mm;
unsigned long end, nstart, nend;
struct vm_area_struct *vma = NULL;
int locked = 0;
long ret = 0;
VM_BUG_ON(start & ~PAGE_MASK);
VM_BUG_ON(len != PAGE_ALIGN(len));
end = start + len;
for (nstart = start; nstart < end; nstart = nend) {
/*
* We want to fault in pages for [nstart; end) address range.
* Find first corresponding VMA.
*/
if (!locked) {
locked = 1;
down_read(&mm->mmap_sem);
vma = find_vma(mm, nstart);
} else if (nstart >= vma->vm_end)
vma = vma->vm_next;
if (!vma || vma->vm_start >= end)
break;
/*
* Set [nstart; nend) to intersection of desired address
* range with the first VMA. Also, skip undesirable VMA types.
*/
nend = min(end, vma->vm_end);
if (vma->vm_flags & (VM_IO | VM_PFNMAP))
continue;
if (nstart < vma->vm_start)
nstart = vma->vm_start;
/*
* Now fault in a range of pages. __mlock_vma_pages_range()
* double checks the vma flags, so that it won't mlock pages
* if the vma was already munlocked.
*/
/* 为VMA分配物理内存 */
ret = __mlock_vma_pages_range(vma, nstart, nend, &locked);
if (ret < 0) {
if (ignore_errors) {
ret = 0;
continue; /* continue at next VMA */
}
ret = __mlock_posix_error_return(ret);
break;
}
nend = nstart + ret * PAGE_SIZE;
ret = 0;
}
if (locked)
up_read(&mm->mmap_sem);
return ret; /* 0 or negative error code */
}
__mlock_vma_pages_range:为VAM分配物理内存
long __mlock_vma_pages_range(struct vm_area_struct *vma,
unsigned long start, unsigned long end, int *nonblocking)
{
struct mm_struct *mm = vma->vm_mm;
unsigned long nr_pages = (end - start) / PAGE_SIZE;
int gup_flags;
VM_BUG_ON(start & ~PAGE_MASK);
VM_BUG_ON(end & ~PAGE_MASK);
VM_BUG_ON(start < vma->vm_start);
VM_BUG_ON(end > vma->vm_end);
VM_BUG_ON(!rwsem_is_locked(&mm->mmap_sem));
gup_flags = FOLL_TOUCH | FOLL_MLOCK;
/*
* We want to touch writable mappings with a write fault in order
* to break COW, except for shared mappings because these don't COW
* and we would not want to dirty them for nothing.
*/
if ((vma->vm_flags & (VM_WRITE | VM_SHARED)) == VM_WRITE)
gup_flags |= FOLL_WRITE;
/*
* We want mlock to succeed for regions that have any permissions
* other than PROT_NONE.
*/
if (vma->vm_flags & (VM_READ | VM_WRITE | VM_EXEC))
gup_flags |= FOLL_FORCE;
/*
* We made sure addr is within a VMA, so the following will
* not result in a stack expansion that recurses back here.
*/
/* 为用户空间的虚拟地址和物理内存建立映射 */
return __get_user_pages(current, mm, start, nr_pages, gup_flags,
NULL, NULL, nonblocking);
}__get_user_pages:为进程的地址空间分配物理内存并建立映射关系。该函数为用户空间分配物理内存。相当于把用户态的虚拟地址传到内核空间,内核空间为其分配物理内存并建立映射关系
这个进程的地址空间是属于用户空间的,即上图的堆区的。而在文章的最开始vmalloc这个是内核的,分配的虚拟地址空间也是属于内核态的。
long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *nonblocking)
{
long i = 0;
unsigned int page_mask;
struct vm_area_struct *vma = NULL;
if (!nr_pages)
return 0;
VM_BUG_ON(!!pages != !!(gup_flags & FOLL_GET));
/*
* If FOLL_FORCE is set then do not force a full fault as the hinting
* fault information is unrelated to the reference behaviour of a task
* using the address space
*/
if (!(gup_flags & FOLL_FORCE))
gup_flags |= FOLL_NUMA;
do {
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;
/* first iteration or cross vma bound */
if (!vma || start >= vma->vm_end) {
vma = find_extend_vma(mm, start);
if (!vma && in_gate_area(mm, start)) {
int ret;
ret = get_gate_page(mm, start & PAGE_MASK,
gup_flags, &vma,
pages ? &pages[i] : NULL);
if (ret)
return i ? : ret;
page_mask = 0;
goto next_page;
}
if (!vma || check_vma_flags(vma, gup_flags))
return i ? : -EFAULT;
if (is_vm_hugetlb_page(vma)) {
i = follow_hugetlb_page(mm, vma, pages, vmas,
&start, &nr_pages, i,
gup_flags);
continue;
}
}
retry:
/*
* If we have a pending SIGKILL, don't keep faulting pages and
* potentially allocating memory.
*/
if (unlikely(fatal_signal_pending(current)))
return i ? i : -ERESTARTSYS;
cond_resched();
page = follow_page_mask(vma, start, foll_flags, &page_mask);
if (!page) {
int ret;
ret = faultin_page(tsk, vma, start, &foll_flags,
nonblocking);
switch (ret) {
case 0:
goto retry;
case -EFAULT:
case -ENOMEM:
case -EHWPOISON:
return i ? i : ret;
case -EBUSY:
return i;
case -ENOENT:
goto next_page;
}
BUG();
}
if (IS_ERR(page))
return i ? i : PTR_ERR(page);
if (pages) {
pages[i] = page;
flush_anon_page(vma, page, start);
flush_dcache_page(page);
page_mask = 0;
}
next_page:
if (vmas) {
vmas[i] = vma;
page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
return i;
}有了虚拟地址,我们就可以得到pmd,pte的在对应表项的位置。最后我们只需要分配一个物理页面,将其物理地址和虚拟地址建立映射即可。
struct page *follow_page_mask(struct vm_area_struct *vma,
unsigned long address, unsigned int flags,
unsigned int *page_mask)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
spinlock_t *ptl;
struct page *page;
struct mm_struct *mm = vma->vm_mm;
*page_mask = 0;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
return page;
}
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
return no_page_table(vma, flags);
pud = pud_offset(pgd, address);
if (pud_none(*pud))
return no_page_table(vma, flags);
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
if (flags & FOLL_GET)
return NULL;
page = follow_huge_pud(mm, address, pud, flags & FOLL_WRITE);
return page;
}
if (unlikely(pud_bad(*pud)))
return no_page_table(vma, flags);
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
return no_page_table(vma, flags);
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pmd(mm, address, pmd, flags & FOLL_WRITE);
if (flags & FOLL_GET) {
/*
* Refcount on tail pages are not well-defined and
* shouldn't be taken. The caller should handle a NULL
* return when trying to follow tail pages.
*/
if (PageHead(page))
get_page(page);
else
page = NULL;
}
return page;
}
if ((flags & FOLL_NUMA) && pmd_numa(*pmd))
return no_page_table(vma, flags);
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(vma, address, pmd);
return follow_page_pte(vma, address, pmd, flags);
}
ptl = pmd_lock(mm, pmd);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(ptl);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(vma, address,
pmd, flags);
spin_unlock(ptl);
*page_mask = HPAGE_PMD_NR - 1;
return page;
}
} else
spin_unlock(ptl);
}
return follow_page_pte(vma, address, pmd, flags);
}
static struct page *follow_page_pte(struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd, unsigned int flags)
{
struct mm_struct *mm = vma->vm_mm;
struct page *page;
spinlock_t *ptl;
pte_t *ptep, pte;
retry:
if (unlikely(pmd_bad(*pmd)))
return no_page_table(vma, flags);
ptep = pte_offset_map_lock(mm, pmd, address, &ptl);
pte = *ptep;
if (!pte_present(pte)) {
swp_entry_t entry;
/*
* KSM's break_ksm() relies upon recognizing a ksm page
* even while it is being migrated, so for that case we
* need migration_entry_wait().
*/
if (likely(!(flags & FOLL_MIGRATION)))
goto no_page;
if (pte_none(pte) || pte_file(pte))
goto no_page;
entry = pte_to_swp_entry(pte);
if (!is_migration_entry(entry))
goto no_page;
pte_unmap_unlock(ptep, ptl);
migration_entry_wait(mm, pmd, address);
goto retry;
}
if ((flags & FOLL_NUMA) && pte_numa(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !pte_write(pte)) {
pte_unmap_unlock(ptep, ptl);
return NULL;
}
page = vm_normal_page(vma, address, pte);
if (unlikely(!page)) {
if ((flags & FOLL_DUMP) ||
!is_zero_pfn(pte_pfn(pte)))
goto bad_page;
page = pte_page(pte);
}
if (flags & FOLL_GET)
get_page_foll(page);
if (flags & FOLL_TOUCH) {
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here, and migration is
* blocked by the pte's page reference, and we
* know the page is still mapped, we don't even
* need to check for file-cache page truncation.
*/
mlock_vma_page(page);
unlock_page(page);
}
}
pte_unmap_unlock(ptep, ptl);
return page;
bad_page:
pte_unmap_unlock(ptep, ptl);
return ERR_PTR(-EFAULT);
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return NULL;
return no_page_table(vma, flags);
}struct page *vm_normal_page(struct vm_area_struct *vma, unsigned long addr,
pte_t pte)
{
unsigned long pfn = pte_pfn(pte);
if (HAVE_PTE_SPECIAL) {
if (likely(!pte_special(pte) || pte_numa(pte)))
goto check_pfn;
if (vma->vm_flags & (VM_PFNMAP | VM_MIXEDMAP))
return NULL;
if (!is_zero_pfn(pfn))
print_bad_pte(vma, addr, pte, NULL);
return NULL;
}
/* !HAVE_PTE_SPECIAL case follows: */
if (unlikely(vma->vm_flags & (VM_PFNMAP|VM_MIXEDMAP))) {
if (vma->vm_flags & VM_MIXEDMAP) {
if (!pfn_valid(pfn))
return NULL;
goto out;
} else {
unsigned long off;
off = (addr - vma->vm_start) >> PAGE_SHIFT;
if (pfn == vma->vm_pgoff + off)
return NULL;
if (!is_cow_mapping(vma->vm_flags))
return NULL;
}
}
check_pfn:
if (unlikely(pfn > highest_memmap_pfn)) {
print_bad_pte(vma, addr, pte, NULL);
return NULL;
}
if (is_zero_pfn(pfn))
return NULL;
/*
* NOTE! We still have PageReserved() pages in the page tables.
* eg. VDSO mappings can cause them to exist.
*/
out:
return pfn_to_page(pfn);
}__pfn_to_page:从这个宏的实现来看,物理空间是被划分为了一个已4k为单位的数组,我们有了虚拟地址,就可以推测到下标。通过mem_map或者node_mem_map就是数组起始地址,这样我们就能得到对应的物理page
但是这样我感觉其实也没有得到真正的物理地址,mem_map[idx]保存的是struct page*,这个只是管理物理page的一个数据结构
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
#elif defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})mmap
entry-common.S
sys_mmap2:
#if PAGE_SHIFT > 12
tst r5, #PGOFF_MASK
moveq r5, r5, lsr #PAGE_SHIFT - 12
streq r5, [sp, #4]
beq sys_mmap_pgoff
mov r0, #-EINVAL
mov pc, lr
#else
str r5, [sp, #4]
b sys_mmap_pgoff
#endif
ENDPROC(sys_mmap2)#define SYSCALL_METADATA(sname, nb, ...) \
static const char *types_##sname[] = { \
__MAP(nb,__SC_STR_TDECL,__VA_ARGS__) \
}; \
static const char *args_##sname[] = { \
__MAP(nb,__SC_STR_ADECL,__VA_ARGS__) \
}; \
SYSCALL_TRACE_ENTER_EVENT(sname); \
SYSCALL_TRACE_EXIT_EVENT(sname); \
static struct syscall_metadata __used \
__syscall_meta_##sname = { \
.name = "sys"#sname, \
.syscall_nr = -1, /* Filled in at boot */ \
.nb_args = nb, \
.types = nb ? types_##sname : NULL, \
.args = nb ? args_##sname : NULL, \
.enter_event = &event_enter_##sname, \
.exit_event = &event_exit_##sname, \
.enter_fields = LIST_HEAD_INIT(__syscall_meta_##sname.enter_fields), \
}; \
static struct syscall_metadata __used \
__attribute__((section("__syscalls_metadata"))) \
*__p_syscall_meta_##sname = &__syscall_meta_##sname;
#else
#define SYSCALL_METADATA(sname, nb, ...)
#endif
#define SYSCALL_DEFINE0(sname) \
SYSCALL_METADATA(_##sname, 0); \
asmlinkage long sys_##sname(void)
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__))
SYSCALL_DEFINE6按照上面的展开之后就会得到sys_mmap_pgoff(应该是这样,没有验证过)
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
unsigned long retval = -EBADF;
if (!(flags & MAP_ANONYMOUS)) {
audit_mmap_fd(fd, flags);
file = fget(fd);
if (!file)
goto out;
if (is_file_hugepages(file))
len = ALIGN(len, huge_page_size(hstate_file(file)));
retval = -EINVAL;
if (unlikely(flags & MAP_HUGETLB && !is_file_hugepages(file)))
goto out_fput;
} else if (flags & MAP_HUGETLB) {
struct user_struct *user = NULL;
struct hstate *hs;
hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & SHM_HUGE_MASK);
if (!hs)
return -EINVAL;
len = ALIGN(len, huge_page_size(hs));
/*
* VM_NORESERVE is used because the reservations will be
* taken when vm_ops->mmap() is called
* A dummy user value is used because we are not locking
* memory so no accounting is necessary
*/
file = hugetlb_file_setup(HUGETLB_ANON_FILE, len,
VM_NORESERVE,
&user, HUGETLB_ANONHUGE_INODE,
(flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
if (IS_ERR(file))
return PTR_ERR(file);
}
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
out_fput:
if (file)
fput(file);
out:
return retval;
}vm_mmap_pgoff-->do_mmap_pgoff-->mmap_region

















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









