






关于就绪队列rq:
1、可以看到每个cpu都有一个就绪队列。
static void __sched __schedule(void)
{
struct rq *rq;
int cpu;
....................
cpu = smp_processor_id();
rq = cpu_rq(cpu);
}
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))2、感觉就绪队列细分,又会为每个调度类都设置一个就绪队列cfs、rt、dl
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
.......................
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
...............
};__pick_next_entity调度程序负责决定哪个进程投入运行,何时运行以及运行多长时间。
主要系统中可运行的进程数大于处理器个数,就注定了在一个时刻,肯定有进程不能被执行
非抢占式多任务:进程能够一直运行,除非自己主动让出cpu,即进行了休眠等操作,才会导致进程切换。即使进程被中断打断了,当中断执行完成以后,也会回到被打断的进程继续执行。(所以这种情况下一般都有什么死锁检测等机制,防止进程死锁或者一个真的死循环导致系统挂死;还有就是watch dog,可以用来检测系统挂死。看门狗是一种NMI,不可屏蔽中断,即使关闭本cpu中断,也不行。如果中断发生时没有喂狗,说明cpu被冻结了)。
抢占式多任务:此模式下,由调度程序来决定什么时候停止一个进程的运行,这个强制挂起进程的动作叫做抢占。进程被抢占之前能够使用的时间是被设置好的,被称为时间片。(在时钟中断里面,更新这个时间片,设置TIF_NEED_RESCHED,在所有的中断处理程序退出时,检查是否需要重新调度程序)
不同的进程有不同的调度策略。目前内核中有4中调度策略 :deadline,realtime,CFS和idle,它们分别使用struct sched_class定义调度类
schedule是调度器的核心函数,其作用是让调度器选手和切换到一个合适的进程运行。进程切换的时机如下:
1、阻塞操作:感觉就是进程休眠了。互斥量,信号量等,这些都可能会让进程休眠
2、在中断返回前、系统调用返回用户空间时。这个时候会去检查TIF_NEED_RESCHED标志,判断是否需要调度。
3、被唤醒的进程,不会马上调用schedule调度,而是被加入到CFS就绪队列(rq???)中,并且设置TIF_NEED_RESCHED。那么被唤醒的进程是在何时被调度呢?
对于可抢占的内核:如果唤醒动作发生在系统调用或者一次处理上下文中,preempt_enable(即使能内核抢占)就会检查是否需要抢占调度。__preempt_schedule最终会去调用schedule;如果唤醒动作发生在硬件中断处理的上下文,则在中断返回时就会去检查是否需要抢占调度
#define preempt_enable() \
do { \
barrier(); \
if (unlikely(preempt_count_dec_and_test())) \
__preempt_schedule(); \
} while (0)对于不可抢占的内核:1、进程调用cond_resched;2、进程主动调用schedule;3、系统调用或者异常返回用户空间;4、中断处理完成返回用户空间。(之前我看过如果中断发生在内核__irq_svc会去检查是否需要抢占,其他的没有去看过)
书上说硬件中断返回前夕和硬件中断返回用户空间是两个东西。。。
static void __cond_resched(void)
{
__preempt_count_add(PREEMPT_ACTIVE);
__schedule();
__preempt_count_sub(PREEMPT_ACTIVE);
}完全公平调度(CFS)linux中对于sched_normal
大致思想:
1、假设系统中只有文本编辑器和视频解码程序,两个进程,且都具有同样的优先级,那么它们应该是各占50%的处理器时间。因为文本编辑器更多的时间是用于等待用户输入,因此它实际上占用CPU的时间会少于50%。而视频解码程序会超过50%。一旦文本编辑器被唤醒,CFS发现该进程使用处理器的时间少于50%,为了实现公平调度。调度器会选择立即抢占视频解码进程。
2、CFS基于一个理念:假设系统中存在n个进程,那么每个进程能够获得处理器的时间是1/n。当系统中的进程数量变多时,每个进程所获得的时间会变小。时间变小了意味着更加频繁的进程切换。进程切换也会消耗时间,因此CFS引入了一个时间片底线,默认为1ms。
3、CFS允许每个进程运行一段时间,循环轮转,选择运行最少的进程作为下一个运行的进程,而不是采用给每个进程分配时间片的做法。CFS在所有可运行进程总数基础上计算出一个进程应该运行多久(不知道这个是怎么计算的哦)。CFS中的nice值被用来计算进程获得处理器运行比的权重。nice越高,进程优先级越低,处理器使用比越低。
CFS四个组成部分:时间记账;进程选择;调度器入口;睡眠和唤醒
时间记账:
所以调度器必须对进程运行时间记账。对于多数Unix系统,分配一个时间片给每个进程。那么当每次系统时钟节拍发生时,时间片都会被减少一个节拍周期。当进程的时间片减少到0时,该进程就可以被另外时间片非0的进程抢占。
CFS中没有时间片的概念。但是它也需要维护每个进程运行的时间记账。因为它需要确保每个进程只在公平分配给他的处理器时间内运行。CFS使用调度器实体结构体sched_entity来追踪进程运行记账。
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
................................
#ifdef CONFIG_SMP
/* Per-entity load-tracking */
struct sched_avg avg;
#endif
};vruntime:存放进程的虚拟运行时间,单位ns,该运行时间(花在运行上的时间和)的计算经过了所有可运行进程总数的标准化。理论上优先级相同的进程,它们的vruntime应该是相同的
权重计算:
内核使用struct load_weight记录调度实体的权重信息
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
进程的优先级有40个等级-20-19。内核定义了一个数组,可以通过nice值直接获取权重
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};CFS调度器计算虚拟运行时间的公式:
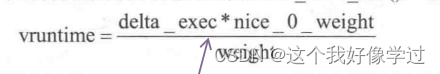
为了加快计算,将除法变为了乘法和移位操作。上面的公式变为了下面这样

static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight);//NICE_0_LOAD
int shift = WMULT_SHIFT;
__update_inv_weight(lw);//得到inv_weight
if (unlikely(fact >> 32)) {
while (fact >> 32) {
fact >>= 1;
shift--;
}
}
/* hint to use a 32x32->64 mul */
/* nice0_0_weight * inv_weight */
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32) {
fact >>= 1;
shift--;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}
delta_exec是时间运行时间。nice_0_weight = prio_to_weight[0]
通过公式可以看到,优先级高(nice小)的进程,weight越高。所以在实际运行时间固定的情况下,高优先级进程的虚拟运行时间更短。
CFS调度器总是选择虚拟时钟跑得慢的进程。因此优先级高的进程虽然可能时间运行时间长一点,但是它对应的虚拟运行时间会更短。从而能更多的被调度器选择调度。
update_curr实现了时间记账功能。没有看明白。。。
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
/*
获取从最后一次修改负载后当前任务所占用的运行时间
*/
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}进程选择:
对于一个完美的多任务处理器,所有可运行的进程的vrumtime将是一致的。但是并没有这种完美的多任务处理器。CFS试图利用一个简单的规则去均衡进程的虚拟运行时间:当CFS需要选择下一个运行进程时,它会挑选一个具有最小vruntime的进程去调度。
CFS使用红黑树组织可运行的进程队列,这样能够迅速找到最小的vruntime的进程。
挑选下一个任务:红黑树中节点的键值是可运行进程的虚拟运行时间。那么所以进程的中虚拟运行时间最小的节点则是树中最左侧的节点。
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
if (!left || (curr && entity_before(curr, left)))
left = curr;
se = left; /* ideally we run the leftmost entity */
if (cfs_rq->skip == se) {
struct sched_entity *second;
if (se == curr) {
second = __pick_first_entity(cfs_rq);
} else {
second = __pick_next_entity(se);
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
clear_buddies(cfs_rq, se);
return se;
}static struct sched_entity *__pick_next_entity(struct sched_entity *se)
{
struct rb_node *next = rb_next(&se->run_node);
if (!next)
return NULL;
return rb_entry(next, struct sched_entity, run_node);
}__pick_next_entity并没有真的去遍历红黑树,找到最左侧的叶子节点。因此该节点已经已经被缓存到了rb_leftmost成员中。这样能比遍历红黑树更加高效,虽然红黑树查找已经很高效了。如果 rb_leftmost为NULL,表示没有可运行的进程,CFS调度器变选择idle任务运行。
向树中加入进程:当进程变为可运行状态(被唤醒)或者是通过fork调用第一次创建进程时
eg第一次创建进程:do_fork函数中,新进程创建完成后需要wake_up_new_task,将新创建的进程加入到调度器中
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through calling update_curr().
*/
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
enqueue_entity_load_avg(cfs_rq, se, flags & ENQUEUE_WAKEUP);
account_entity_enqueue(cfs_rq, se);
update_cfs_shares(cfs_rq);
if (flags & ENQUEUE_WAKEUP) {
place_entity(cfs_rq, se, 0);
enqueue_sleeper(cfs_rq, se);
}
update_stats_enqueue(cfs_rq, se);
check_spread(cfs_rq, se);
if (se != cfs_rq->curr)
__enqueue_entity(cfs_rq, se);//将节点真正加入红黑树
se->on_rq = 1;
if (cfs_rq->nr_running == 1) {
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
}
}static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
int leftmost = 1;
/*
* Find the right place in the rbtree:
*/
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
if (entity_before(se, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = 0;
}
}
/*
* Maintain a cache of leftmost tree entries (it is frequently
* used):
*/
if (leftmost)
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}从树中删除进程
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
dequeue_entity_load_avg(cfs_rq, se, flags & DEQUEUE_SLEEP);
update_stats_dequeue(cfs_rq, se);
if (flags & DEQUEUE_SLEEP) {
#ifdef CONFIG_SCHEDSTATS
if (entity_is_task(se)) {
struct task_struct *tsk = task_of(se);
if (tsk->state & TASK_INTERRUPTIBLE)
se->statistics.sleep_start = rq_clock(rq_of(cfs_rq));
if (tsk->state & TASK_UNINTERRUPTIBLE)
se->statistics.block_start = rq_clock(rq_of(cfs_rq));
}
#endif
}
clear_buddies(cfs_rq, se);
if (se != cfs_rq->curr)
__dequeue_entity(cfs_rq, se);
se->on_rq = 0;
account_entity_dequeue(cfs_rq, se);
/*
* Normalize the entity after updating the min_vruntime because the
* update can refer to the ->curr item and we need to reflect this
* movement in our normalized position.
*/
if (!(flags & DEQUEUE_SLEEP))
se->vruntime -= cfs_rq->min_vruntime;
/* return excess runtime on last dequeue */
return_cfs_rq_runtime(cfs_rq);
update_min_vruntime(cfs_rq);
update_cfs_shares(cfs_rq);
}static void __dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (cfs_rq->rb_leftmost == &se->run_node) {
struct rb_node *next_node;
next_node = rb_next(&se->run_node);
cfs_rq->rb_leftmost = next_node;
}
rb_erase(&se->run_node, &cfs_rq->tasks_timeline);
}
调度器入口:
调度器主要入口是schedule函数。schedule通过需要和一个具体的调度类相关联。找到一个最高优先级的调度类,然后调度类负责从自己的运行队列中找到下一个需要被运行的进程。然后使用schedule进行进程切换。
可以看到schedule就是调用了pick_next_task去挑选下一个该被运行的进程。pick_next_task会从最高优先级的调度类中寻找一个合适进程。如果最高的没有找到,那么就找次高的。每个调度类都会去实现一个pick_next_task成员函数,它会返回下一个可运行的进程。
static void __sched __schedule(void)
{
....................................
next = pick_next_task(rq, prev);
....................................
}
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev)
{
const struct sched_class *class = &fair_sched_class;
struct task_struct *p;
/*
CFS是普通进程的调度类,系统中绝大多数进程都是普通进程
因此当所有可运行进程的数量是CFS调度类的可运行进程数量时,
我们就只需要从CFS调度类,寻找下一个可运行进程即可
*/
if (likely(prev->sched_class == class &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev);
if (unlikely(p == RETRY_TASK))
goto again;
/* assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev);
return p;
}
again:
/* 从优先级最高的调度类还是寻找进程 */
for_each_class(class) {
p = class->pick_next_task(rq, prev);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
BUG(); /* the idle class will always have a runnable task */
}
进程休眠与唤醒
休眠的进程处于一种特殊的不可执行的状态。进程休眠有很多原因,比如等待文件I/O,或者获取信号量失败等等。
无论哪种情况下的休眠,内核操作都相同:进程将自己标记为休眠状态,并从可执行的红黑树中移除(调度器有个红黑树保存了该调度类的所有可执行的进程),然后将自己放入等待队列(那是不是每个调度类都有自己的等待队列,就绪队列这些),最后调用schedule选择一个其他的进程执行。
唤醒的过程刚好相反:进程被设置为可执行状态,然后从等待队列中移除,并将其加入可执行红黑树中。
之前想错了一个事情。进程在切换的时候(函数schedule),必然会将当前进程的状态设置为非running状态,例如休眠。实际上schedule函数不会修改进程的状态。例如进程A被换下cpu,去执行进程B。进程A可以仍然在就绪队列中。不需要被换到等待队列里面。。















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









