






Python机器学习步骤
一、机器学习步骤
1、数据选择
数据包括结构化数据(例如:表格)和非结构化数据(例如:图像和文本)。
2、特征工程
特征工程就是对原始数据分析处理,转化为模型可用的特征,这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。特征工程按技术上可分为如下几步:
① 探索性数据分析:数据分布、缺失、异常及相关性等情况;
② 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;
③ 特征提取:特征表示,特征衍生,特征选择,特征降维等;
Python有很多包可以帮我们处理进行数据预处理,比如numpy和pandas包等。
3、选择模型类型和算法
机器学习主要分为分类、回归和聚类方法,包括决策树、随机森林、支持向量机、神经网络等,根据数据集选择合适的模型。Python中有许多机器学习库和框架可以使用,包括Scikit-learn、Keras和TensorFlow等。
4、划分训练集和测试集
在选择模型类型和算法之后,将处理好的数据集拆分成三个部分:训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型的参数,测试集用于最终模型的测试。Python中通常使用sklearn库model_selection中的train_test_split方法。
5、模型训练和调参
在划分训练集和测试集后,使用训练集数据训练模型,检查模型效果。通常可以使用以下指标来评估模型,例如准确率、召回率、精确率和f1-score。结合这些指标使用验证集数据进行调参,了解模型的预测能力,检查模型效果。最后,将测试集数据放入调整好的模型中进行预测,分析模型的评估指标。
6、应用模型预测
将训练好的模型应用到实际问题中。
二、Python实现
1、数据选择
数据包括结构化数据(例如:表格)和非结构化数据(例如:图像和文本)。
# 导入Python需要的包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, ElasticNet, Lasso
from sklearn.impute import KNNImputer
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import r2_score
import xgboost as xgb
# 导入数据
train_df = pd.read_csv('Kaggle/house_price/train.csv')
test_df = pd.read_csv('Kaggle/house_price/test.csv')
all_data_df = pd.concat([train_df, test_df])
print("Training dataframe shape is: {}".format(train_df.shape))
print("Full dataframe shape is: {}".format(all_data_df.shape))

train_df.head(5)

2、特征工程
特征工程就是对原始数据分析处理,转化为模型可用的特征,这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。特征工程按技术上可分为如下几步:
① 探索性数据分析:数据分布、缺失、异常及相关性等情况;
② 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;
③ 特征提取:特征表示,特征衍生,特征选择,特征降维等;
Python有很多包可以帮我们处理进行数据预处理,比如numpy和pandas包等。
探索性数据分析
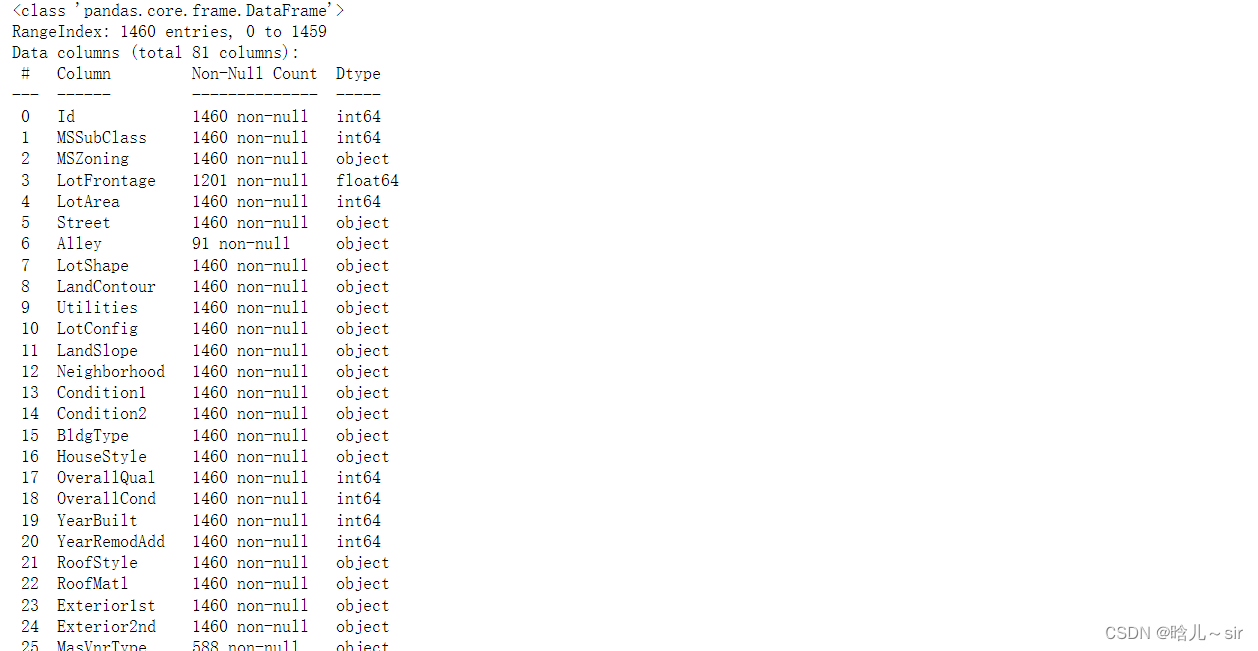
# 查看数据情况
train_df.info()
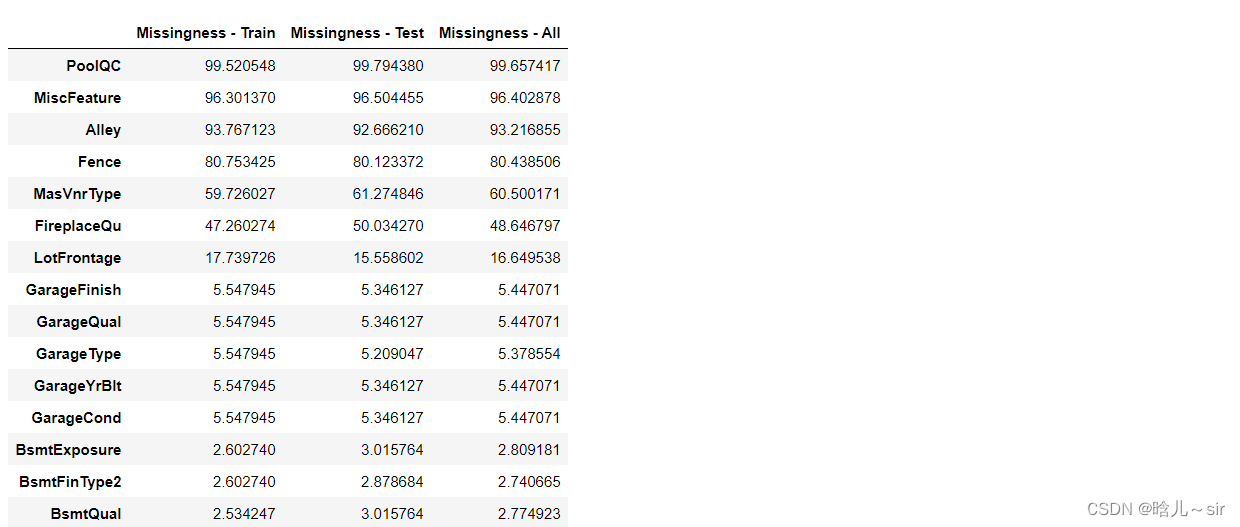
# 缺失值处理
train_df_na = ((train_df.isnull().sum()) / len(train_df)) * 100
test_df_na = ((test_df.isnull().sum()) / len(test_df)) * 100
all_data_df_na = ((all_data_df.isnull().sum()) / len(all_data_df)) * 100
missing_df = pd.DataFrame({'Missingness - Train':train_df_na,'Missingness - Test':test_df_na,'Missingness - All':all_data_df_na})
missing_df = missing_df.sort_values(by=['Missingness - Train'], ascending=False)
missing_df.head(15)
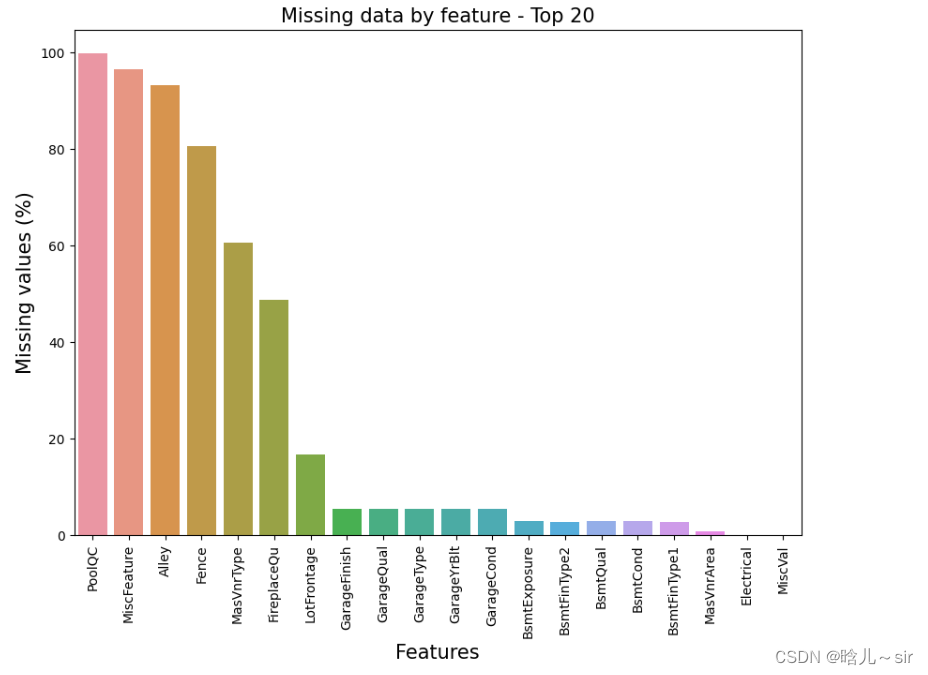
f, ax = plt.subplots(figsize=(10, 7))
plt.xticks(rotation='vertical')
sns.barplot(x=missing_df[:20].index, y=missing_df['Missingness - All'][:20])
plt.xlabel('Features', fontsize=15)
plt.ylabel('Missing values (%)', fontsize=15)
plt.title('Missing data by feature - Top 20', fontsize=15)
plt.show()
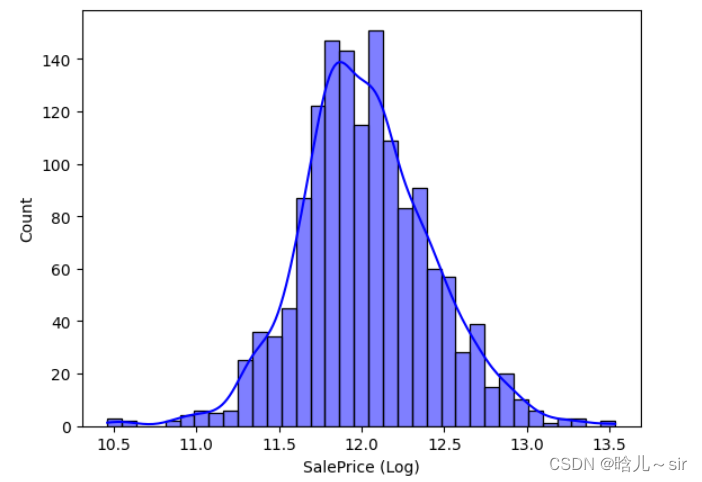
# 目标变量
train_df['SalePrice'].describe()

sns.histplot(train_df['SalePrice'])

train_df['SalePrice (Log)'] = np.log(train_df['SalePrice'])
sns.histplot(train_df, x="SalePrice (Log)", kde=True, color='blue')
plt.show()
特征提取
# 将特征划分为类别特征和非类别特征
categorial_values = ['ExterQual', 'ExterCond', 'BsmtQual','BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', \
'HeatingQC', 'KitchenQual', 'FireplaceQu', 'GarageQual', 'GarageCond', 'Fence',\
'MSZoning', 'Street', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', \
'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl', \
'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea', 'Foundation', 'Heating', 'CentralAir', 'Electrical', \
'Functional', 'GarageType', 'GarageFinish', 'PavedDrive', 'SaleType']
non_categorical_values = ['Id', 'MSSubClass', 'LotFrontage', 'LotArea', 'OverallQual', 'OverallCond', 'BsmtFinSF1','BsmtFinSF2', 'BsmtUnfSF', \
'TotalBsmtSF', '1stFlrSF', '2ndFlrSF','LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath',\
'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageYrBlt', 'GarageCars', 'GarageArea', \
'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', \
'MiscVal', 'MoSold', 'YrSold', 'SalePrice', 'SalePrice (Log)']
# 特征变量one-hot处理
train_df_dummy = pd.get_dummies(train_df[categorial_values], dtype=int)
test_df_dummy = pd.get_dummies(test_df[categorial_values], dtype=int)
# 合并特征变量和非特征变量
train_df_final = pd.concat([train_df_dummy, train_df[non_categorical_values]], join='inner', axis=1)
test_df_final = pd.concat([test_df_dummy, test_df[non_categorical_values[:-2]]], join='inner', axis=1)
# 缺失值处理
train_columns = list(train_df_final.columns)
test_columns = list(test_df_final.columns)
# knn插补缺失值
imputer = KNNImputer(n_neighbors = 5)
train_df_final = pd.DataFrame(imputer.fit_transform(train_df_final), columns=train_columns)
test_df_final = pd.DataFrame(imputer.fit_transform(test_df_final), columns=test_columns)
train_df_final.head()
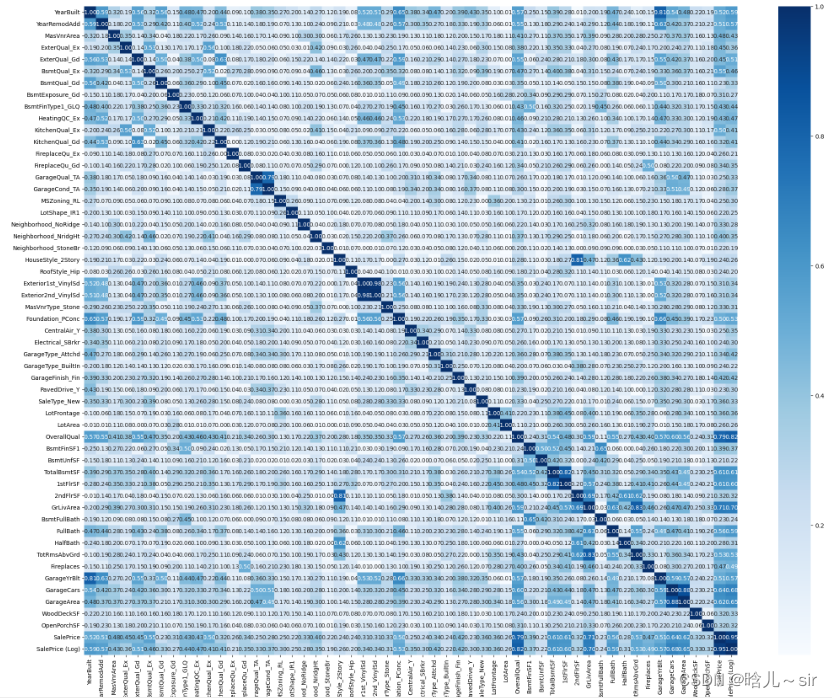
# 热力图(相关度>0.2)
subset_corr_input_features = []
for column in train_df_final.columns:
if np.corrcoef(train_df_final['SalePrice'],train_df_final[column])[0,1]>0.2:
subset_corr_input_features.append(column)
f, ax = plt.subplots(figsize=(25, 20))
sns.heatmap(np.abs(train_df_final[subset_corr_input_features].corr()), annot = True, fmt = ".2f", cmap="Blues")
plt.show()
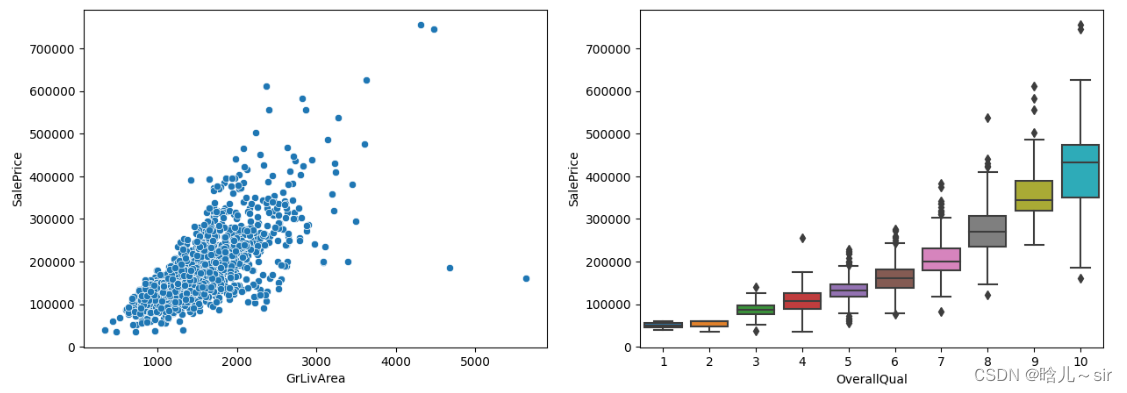
# 重要特征
var1 = 'GrLivArea'
var2 = 'OverallQual'
data1 = pd.concat([train_df['SalePrice'], train_df[var1]], axis=1)
data2 = pd.concat([train_df['SalePrice'], train_df[var2]], axis=1)
fig,axs=plt.subplots(1,2,figsize=(15,5))
sns.scatterplot(data=data1, x=var1, y='SalePrice', ax=axs[0])
sns.boxplot(data=data2, x=var2, y='SalePrice', ax=axs[1])
plt.show()
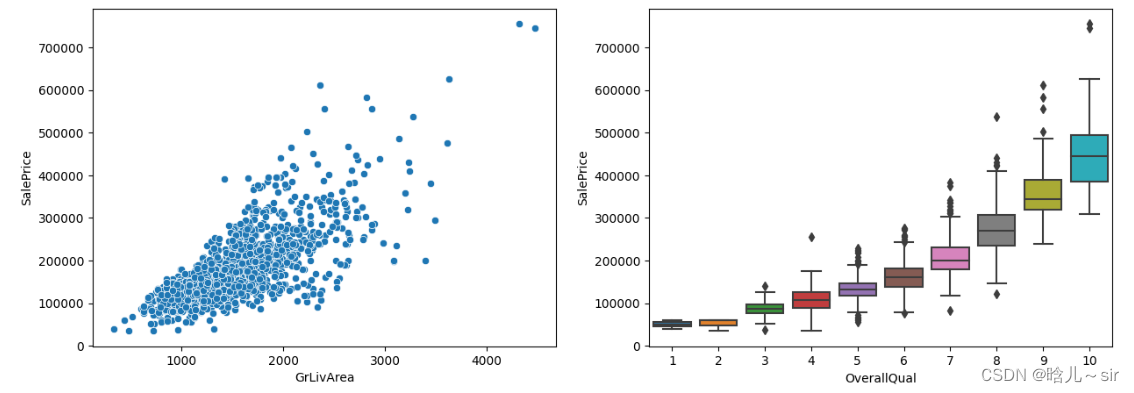
# 筛选数据
train_df = train_df[~((train_df["GrLivArea"] > 4000) & (train_df["SalePrice"] < 200000))]
var1 = 'GrLivArea'
var2 = 'OverallQual'
data1 = pd.concat([train_df['SalePrice'], train_df[var1]], axis=1)
data2 = pd.concat([train_df['SalePrice'], train_df[var2]], axis=1)
fig,axs=plt.subplots(1,2,figsize=(15,5))
sns.scatterplot(data=data1, x=var1, y='SalePrice', ax=axs[0])
sns.boxplot(data=data2, x=var2, y='SalePrice', ax=axs[1])
plt.show()
3、选择模型类型和算法
机器学习主要分为分类、回归和聚类方法,包括决策树、随机森林、支持向量机、神经网络等,根据数据集选择合适的模型。Python中有许多机器学习库和框架可以使用,包括Scikit-learn、Keras和TensorFlow等。
本案例是回归问题,这里选择了5种算法:
i. Elastic Net
ii. Lasso
iii. Ridge
iv. Extreme Gradient Boosting (XGB)
v. Gradient Boosting Regressor (GBR)
4、划分训练集和测试集
在选择模型类型和算法之后,将处理好的数据集拆分成三个部分:训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型的参数,测试集用于最终模型的测试。Python中通常使用sklearn库model_selection中的train_test_split方法。
# 划分训练集和测试集
X_train,X_test,Y_train,Y_test = train_test_split(train_df_final.drop('SalePrice (Log)',axis = 1),train_df_final['SalePrice (Log)'],random_state=0)
5、模型训练和调参
在划分训练集和测试集后,使用训练集数据训练模型,检查模型效果。通常可以使用以下指标来评估模型,例如准确率、召回率、精确率和f1-score。结合这些指标使用验证集数据进行调参,了解模型的预测能力,检查模型效果。最后,将测试集数据放入调整好的模型中进行预测,分析模型的评估指标。
# 模型训练
classifier_list = [ElasticNet(), Lasso(), Ridge(), xgb.XGBRegressor(), GradientBoostingRegressor()]
model_list = ['Elastic Net', 'Lasso', 'Ridge', 'XGB', 'GBR']
r2_score_list = []
for classifier in classifier_list:
model = classifier.fit(X_train, Y_train)
Y_pred = model.predict(X_test)
r2_score_list.append(r2_score(Y_test, Y_pred))
df_results = pd.DataFrame(data={'Model':model_list,'$R^2$':r2_score_list})
df_results

从结果可知,GradientBoostingRegressor效果最好。
model = GradientBoostingRegressor().fit(X_train,Y_train)
Y_pred_log = model.predict(X_test)
Y_pred = np.exp(Y_pred_log)
final_result = pd.DataFrame({'Id':X_test['Id'].astype(int), 'SalePrice':Y_pred})
final_result

6、应用模型预测
将训练好的模型应用到实际问题中。














 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









