







tf.keras.datasets.imdb.load_data()
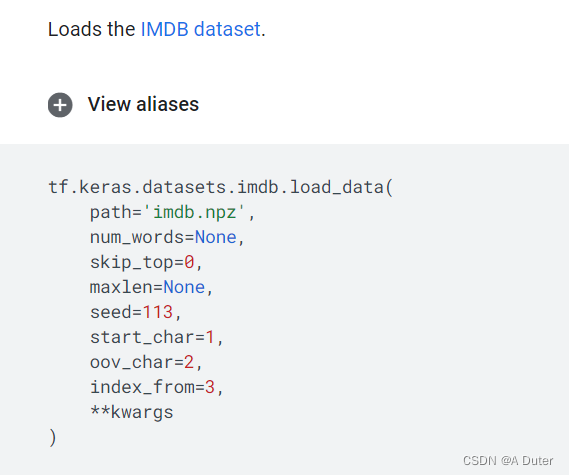
skip_top 参数
跳过最频繁出现的前N个词(可能没有信息),这些词将作为ov_char值出现在数据集中,默认为0,所以没有词被跳过。
oov_char 参数
int. 词汇外的字符,由于num_words或skip_top限制而被剔除的词将被这个字符所取代。
index_from 参数
int,指数为该指数及以上的实际词语。
start_char 参数
int. 一个序列的开始将被标记为这个字符,默认为1,因为0通常是填充字符。(这也是为什么当index_from=3时,开头1不加3的原因)
oov_char默认为2,start_char默认为1时
index_from=3 和 index_from=0的不同:
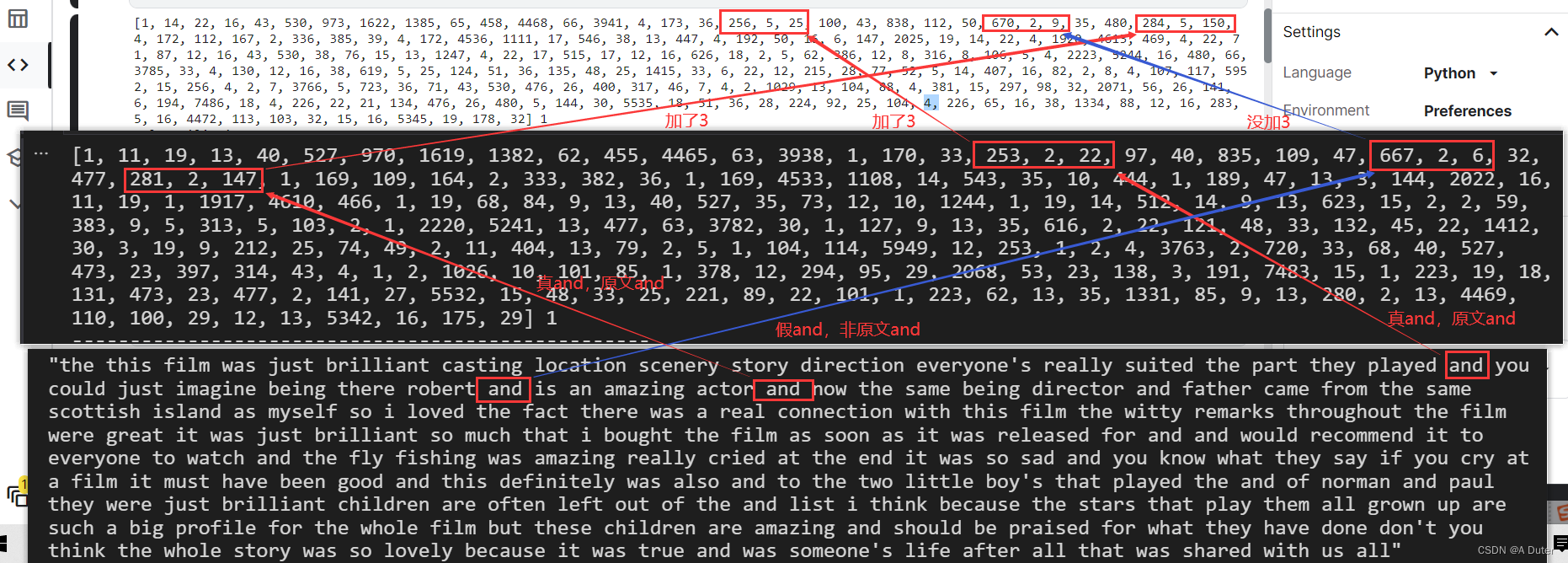
坑了我好久,淦!!!!我真是闲着没事干了要搞懂这个,焯!!!!

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









