







1. 提出问题
场景:我们的目标是设计一个面向具体任务的大语言模型。设计思路是:首先,选择开源的基座大语言模型,使用领域无关的数据预训练大语言模型,得到通用的大语言模型。然后,使用任务特定的数据微调通用的大语言模型,得到面向具体任务的大语言模型。
问题:如何对大语言模型开发的各个阶段进行评价,以确保每一步操作的有效性。
思考:第一次接触这个问题的时候,我想到的对大语言模型的评价是针对面向具体任务大语言模型的评价,在公用的开源数据集或者基准上计算评价指标的得分,通常情况下,如果得分高则意味着大语言模型性能好。但是,仅考虑对专用大语言模型的评价就会忽略之前开发的各阶段所做的努力。显然,评估大语言模型开发的各个阶段更加合理,能够证明每一步工作的有效性,提高开发的效率。
2. 大语言模型开发过程评估
根据我们设计领域特定大语言模型的思路,对大语言模型开发过程的评估主要有两个方面,一个是数据的评估,一个是模型的评估。
数据评估方法
对于数据评估方法,无论是预训练还是微调阶段,都需要使用训练数据对大语言模型进行训练。因此,数据评估方法主要是在数据的收集和处理后,评价得到的领域训练数据集。评价训练数据集以大语言模型的效果位评价标准,通常以大模型的测试集的交叉熵损失或困惑度作为数据数量、质量的评价指标。
- 数据数量评价依据尺度定律,判断继续增加数据规模能否有效降低模型交叉熵损失或困惑度
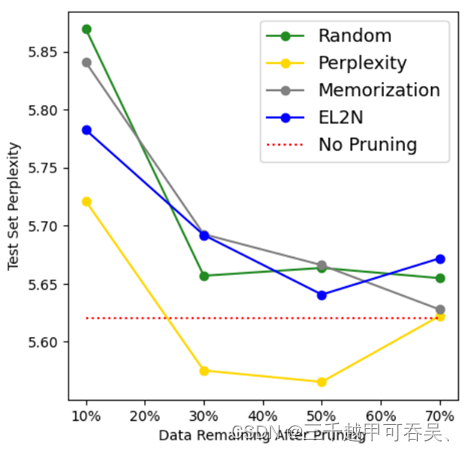
- 数据质量评价可参考数据剪枝,用困惑度判断数据集有效训练的比例
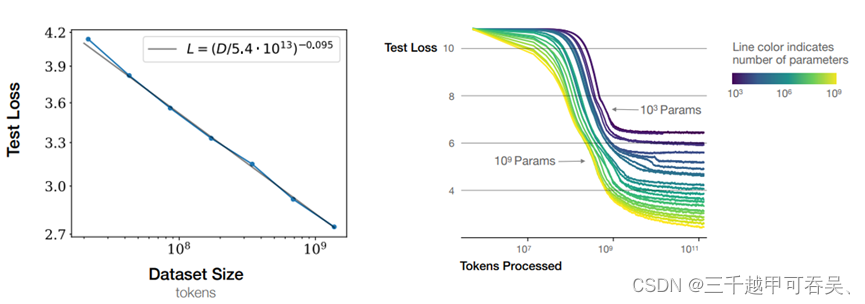
数据集数量评价的主要依据是大模型的Scaling Law(尺度定律)。该定律描述了模型的性能与计算量、模型参数量和数据大小三者之间的关系。具体来说,在不受其他因素制约的情况下,模型的性能与这三者呈现幂律关系。这意味着增加计算量、模型参数量或数据大小都可能提升模型的性能,但提升的效果会随着这些因素的增加而递减。根据Scaling Law,我们可以判断大模型的训练数据量是否已经饱和。即在固定模型参数和计算资源的情况下,进一步增加训练数据量是否还能显著降低大模型在测试集上的交叉熵损失或困惑度。
数据剪枝是指依据一定标准对数据集进行删减,以确保删减后的数据集在训练大模型时,其性能与删减前保持一致。举个例子,假设我们有10条数据,按照测试集困惑度大小进行排序后,我们删除困惑度最大的3条数据。然后,分别使用删减前后的数据来训练大模型,并观察性能的改变情况。数据剪枝能够反映构建数据集的冗余度。一个高质量的数据集应该具有尽可能小的冗余度,即有效训练的数据比例应尽可能大。因此,我们可以根据数据剪枝的结果来评估已有数据的质量。
模型评估方法
对于模型评估方法,首先是评估基准模型的性能以选择合适的基座模型,其次是评估预训练后的大语言模型的性能,最后是评估微调后的大语言模型的性能,所以评估模型主要有三个方面:
- 评估基座模型
- 评估预训练后的大语言模型
- 评估微调后的大语言模型
评估基座模型
评估选择的基座模型的主要方面有:具体应用的任务场景、具有的数据量规模以及拥有的算力
评估预训练后的大语言模型
评价预训练大语言模型分为粗粒度评估和细粒度评估,重点为后者。
- 粗粒度指测试集困惑度和测试集填词准确率进行评价
- 细粒度是构建能力测试基准,需要对关注的大模型能力(比如领域常识理解、推理能力)进行评价,每种能力的数量不用太多(几十条足够了),但多样性要大。具体形式可以做成选择题形式评估准确率,或者做成问答题评估ROUGE-L之类的指标,然后通过In-Context Learning(Few-shot)进行测试。需要注意,当前无法保证评测基准能够充分的评估大模型的效果,业界做法是尽可能多的覆盖想要观测的能力,就是把测试集做的丰富全面,然后打一个平均分。
评估微调后的大语言模型
评价微调的大模型类似预训练的细粒度评估。在具体的任务场景中,构建测试基准,覆盖需要评测的大模型能力,然后通过In-Context Learning(One-shot)进行测试。
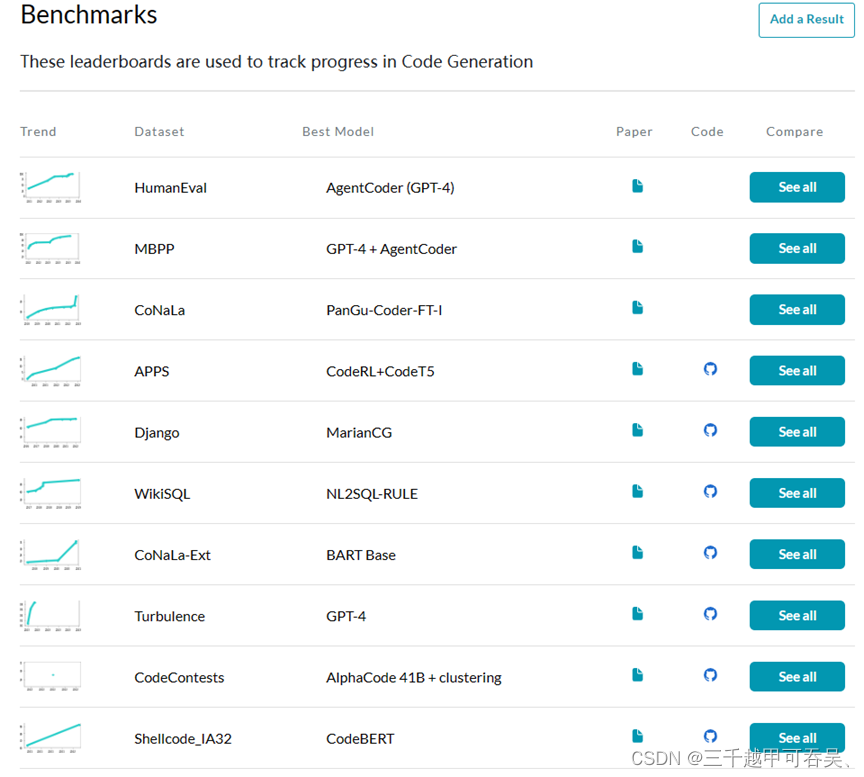
微调后的大语言模型面向具体的任务,需要设计任务特定的评估基准和对应的评价指标,以代码生成任务为例,介绍如何设计微调的评估基准。代码生成是一个重要领域,它可以从多模态数据源(如不完整的代码、另一种编程语言中的程序、自然语言描述或执行示例)中预测代码或程序结构。代码生成工具可以帮助开发自动编程工具,以提高编程生产力。针对用于代码生成的大语言模型的评价,首先选择用于评价的基准。在Papers With Code的相关网站上,针对用于代码生成任务的大语言模型,有一些普遍使用的基准。
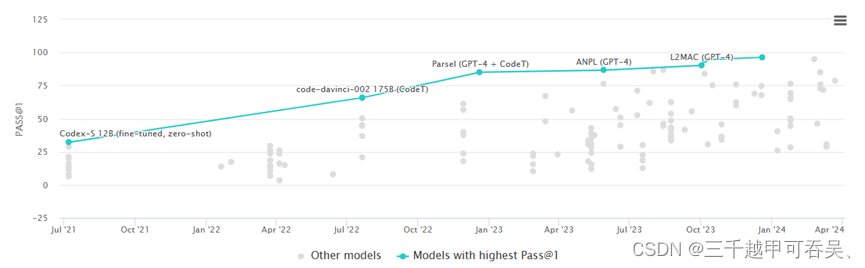
以HumanEval基准为例,它是为了评估大语言模型在代码生成任务上的功能正确性而专门设计和创建的一套手工编写的编程问题合集。该数据集中包含了164个独立的编程问题,每个问题都包含函数签名、文档字符串(用于描述函数的功能)、函数体以及一组单元测试用例(Python)。HumanEval的问题设计涵盖了语言理解、逻辑推理、算法知识及基础数学等多个方面,旨在全面检验模型解决实际编程任务的能力。与其相对应的评价指标是pass@k,为HumanEval中的每个问题生成n个代码采样(n≥k),统计通过单元测试正确程序采样的数量c(c≤n),计算概率以更准确地计算功能正确性。
p
a
s
s
@
k
:
=
E
P
r
o
b
l
e
m
s
[
1
−
(
n
−
c
k
)
(
n
k
)
]
pass@k:=E_{Problems}[1-\frac{\binom{n-c}{k}}{\binom{n}{k}}]
pass@k:=EProblems[1−(kn)(kn−c)]
还有很多可以用于评价代码生成大语言模型的评价指标,以下将进行简单的介绍:
- BLEU:将生成代码和参考代码看作tokens序列,比较两者单个或连续tokens的匹配程度评价生成代码的质量
- METEOR:在BLEU的基础上增加了同义词的比较,且关注tokens出现的顺序,但是需要WordNet知识源,不在知识源内的单词无法比较
- CHRF:将生成代码和参考代码看作字符序列,比较两者单个或连续字符的匹配程度评价生成代码的质量
- CHRF++:字符和tokens的组合评价
- RUBY:设计了三个抽象层次由高到低的评价,图相似度、树相似度和字符串相似度评价。使用评价方法的抽象层次越高,就能实现与语义得分更高的相关系数。图相似度比较生成程序和参考程序的程序依赖图的相似度、树相似度比较生成程序和参考程序的抽象语法树子树的相似度、字符串相似度比较生成程序和参考程序的字符串相似度。当生成程序质量较差时可能无法构建程序依赖图和抽象语法树。程序依赖图和抽象语法树分别引入了代码的语义和语法信息
- CodeBLEU:由BLEU、权重BLEU、抽象语法树匹配和数据流匹配四部分组成。权重BLEU为匹配的关键字赋予更高的权重,抽象语法树和数据流匹配引入了代码的语法和语义信息
参考文献
[1] KAPLAN J, MCCANDLISH S, HENIGHAN T, 等. Scaling Laws for Neural Language Models[M/OL]. arXiv, 2020[2024-03-13]. http://arxiv.org/abs/2001.08361.
[2] HOFFMANN J, BORGEAUD S, MENSCH A, 等. Training Compute-Optimal Large Language Models[M/OL]. arXiv, 2022[2024-03-13]. http://arxiv.org/abs/2203.15556.
[3] ZHANG B, LIU Z, CHERRY C, 等. WHEN SCALING MEETS LLM FINETUNING: THE EFFECT OF DATA, MODEL AND FINETUNING METHOD[J]. 2024.
[4] MARION M, ÜSTÜN A, POZZOBON L, 等. When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale[M/OL]. arXiv, 2023[2024-04-08]. http://arxiv.org/abs/2309.04564.
[5] TIRUMALA K, SIMIG D, AGHAJANYAN A, 等. D4: Improving LLM Pretraining via Document De-Duplication and Diversification[M/OL]. arXiv, 2023[2024-03-19]. http://arxiv.org/abs/2308.12284.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









