






【论文阅读】Cross-lingual Knowledge Graph Alignment via Graph Matching Neural Network
Abstract
以前的跨语言知识图谱(KG)对齐研究依赖于仅从单语KG结构信息中派生的实体嵌入,这可能在匹配两个KG中具有不同事实的实体时失败。在本文中,我们引入了主题实体图,即实体的局部子图,以在KG中表示实体及其上下文信息。从这个视角来看,KB对齐任务可以被形式化为一个图匹配问题;我们进一步提出了一种基于图注意力的解决方案,该解决方案首先匹配两个主题实体图中的所有实体,然后联合建模局部匹配信息以导出一个图级匹配向量。实验证明,我们的模型在性能上大幅优于以往的技术方法。
1.Introduction
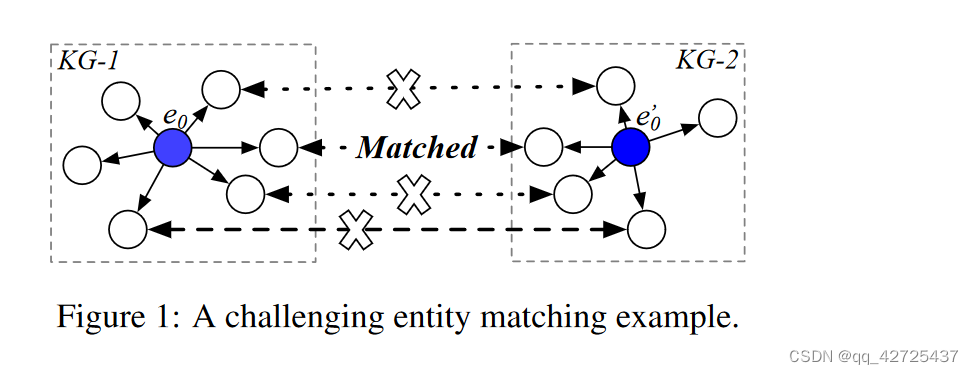
之前方法都是在单一语言知识图谱中得到节点表示,用节点表示去做相似度分析。会有下面的问题:
1.不同语言中的一些实体可能具有不同的 KG 事实,因此实体嵌入中编码的信息在不同语言中可能是不同的,这使得这些方法很难匹配这些实体。图 1 说明了这样一个示例,其中我们的目标是将 e0 与 e’0 对齐,但其周围的邻居中只有一个对齐的邻居。
2.此外,这些方法没有将实体表面形式编码到实体嵌入中,也使得很难匹配知识图谱中邻居较少、缺乏足够结构信息的实体。
为了解决这些缺点,我们提出了一个主题实体图来表示实体的KG上下文信息。与之前利用实体嵌入来匹配实体的方法不同,我们将这个任务形式化为主题实体图之间的图匹配问题。为了实现这一点,我们提出了一种新颖的图匹配方法来估计两个图的相似性。具体而言,我们首先利用图卷积神经网络(GCN)(Kipf和Welling,2016; Hamilton等,2017)对两个图,比如G1和G2进行编码,得到每个图的实体嵌入列表。然后,我们通过使用一种注意匹配方法,将G1(或G2)中的每个实体与G2(或G1)中的所有实体进行比较,从而为G1和G2中的所有实体生成跨语言KG敏感的匹配向量。因此,我们使用另一个GCN来在整个图中传播局部匹配信息。这为每个主题图产生了一个全局匹配向量,用于最终的预测。背后的动机是,图卷积可以共同将所有实体的相似性(包括主题实体和其邻居实体)编码为一个匹配向量。实验结果表明,我们的模型在性能上大幅优于以前的最先进模型。
2 Topic Entity Graph
如Wang等人(2018)所指出的,KG中实体的局部上下文信息对于KG对齐任务非常重要。在我们的模型中,我们提出了一个结构,即主题实体图,用于表示给定实体(称为主题实体)与其在知识库中的邻居之间的关系。图2显示了Lebron James在英文和中文知识图中的主题图。为了构建主题图,我们首先收集主题实体的1-hop邻居实体,得到一组实体{e1,…,en},它们是图的节点。然后,对于每对实体(ei,ej),如果ei和ej在KG中通过关系r直接连接,我们在主题图中的相应节点之间添加一个有向边。请注意,我们不用r来标记该边在KG中ei和ej所持有的关系,而只保留r的方向。实践证明,这个策略显著提高了效率和性能,我们将在第4节中讨论。
3 Graph Matching Model
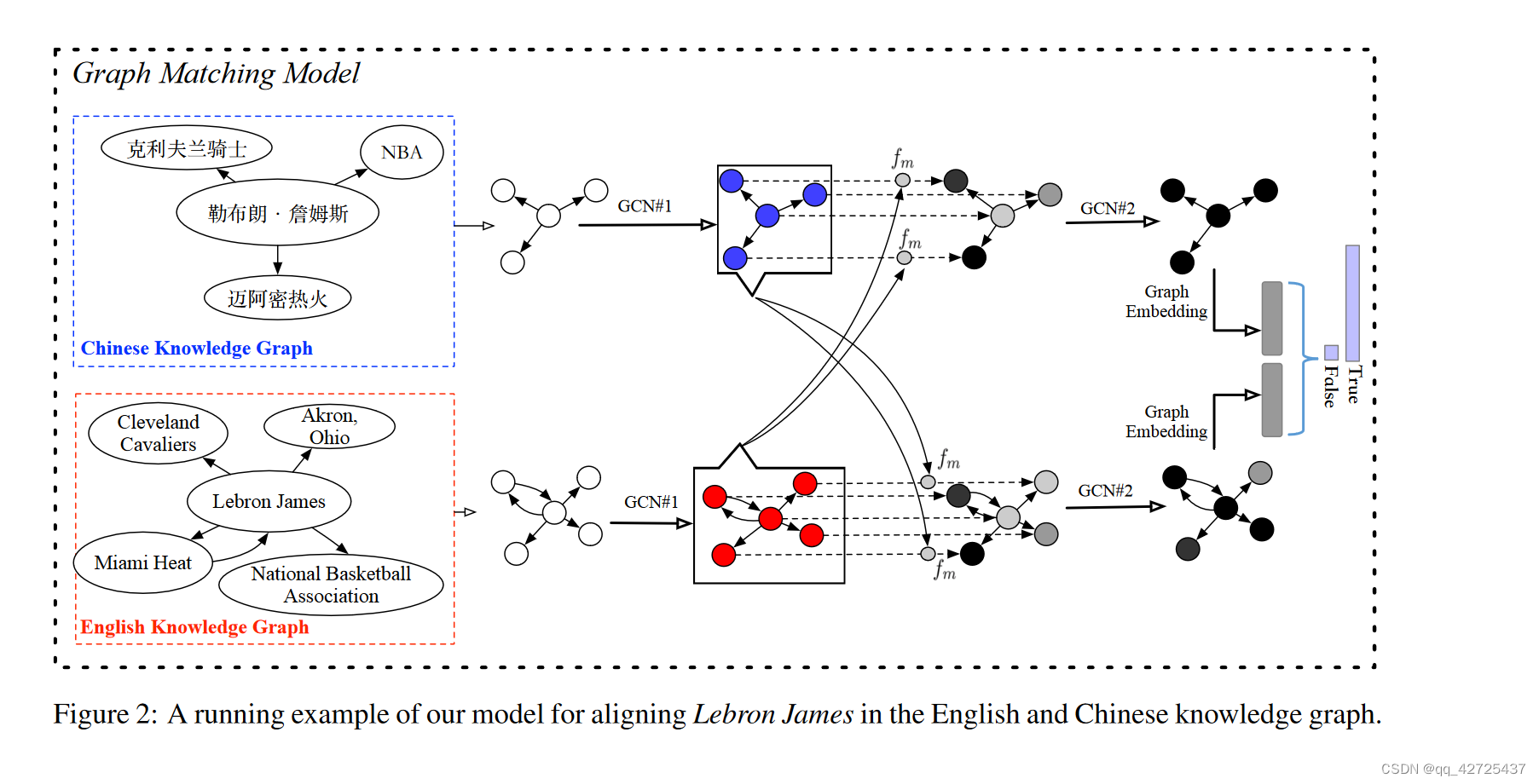
图 2 概述了我们在英文和中文知识图谱中对齐 Lebron James 的方法1。具体来说,我们首先从两个 KG(即 G1 和 G2)中检索 Lebron James 的主题实体图。然后,我们提出了一个图匹配模型来估计 G1 和 G2 描述同一实体的概率。具体来说,匹配模型包括以下四层:
输入表示层 该层的目标是通过使用 GCN(以下称为 GCN1)学习主题实体图中出现的实体的嵌入(Xu 等人,2018a)。最近,GCN 已成功应用于许多 NLP 任务,例如语义解析(Xu et al., 2018b)、文本表示(Zhang et al., 2018)、关系提取(Song et al., 2018)和文本生成(徐等人,2018c)。我们以如下实体v的嵌入生成为例来解释GCN算法:
通过LSTM将节点名转变为初始特征,得到两个列表分别表示,该层的输出是两组实体嵌入。
节点级(本地)匹配层 在这一层中,我们以两种方式(从 G1 到 G2 以及从 G2 到 G1)将一个主题实体图的每个实体嵌入与另一图的所有实体嵌入进行比较,如图 2 所示.我们提出了一种类似于(Wang et al., 2017)的注意匹配方法。具体来说,我们首先计算 G1 中实体 ei1 与 G2 中所有实体 {ej2} 在其表示空间中的余弦相似度。
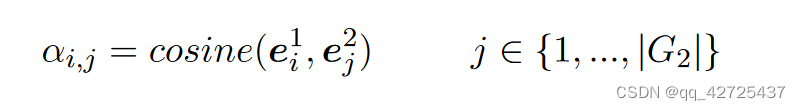
然后,我们将这些相似度作为权重,通过对 G2 的所有实体嵌入进行加权求和来计算整个图 G2 的注意力向量。
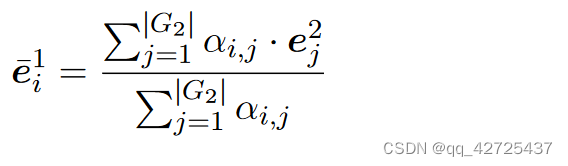
我们在每个匹配步骤中使用多视角余弦匹配函数 fm 计算 G1 和 G2 中所有实体的匹配向量
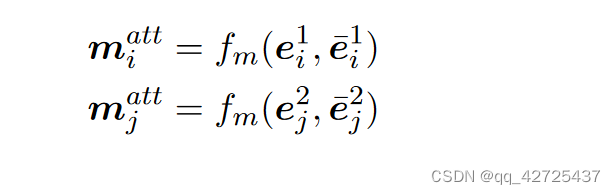
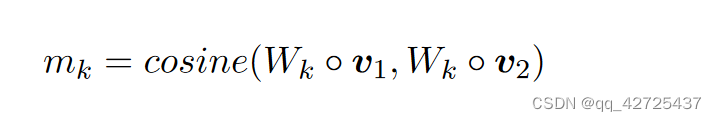
图级(全局)匹配层 直观地,上述匹配向量(matts)捕获了 G1(G2)中的每个实体如何与其他语言的主题图进行匹配。然而,它们是局部匹配状态,不足以衡量全局图相似度。例如,许多实体只有很少的邻居实体同时出现在 G1 和 G2 中。对于这些实体,利用本地匹配信息的模型可能很有可能错误地预测这两个图描述不同的主题实体,因为 G1 和 G2 中的大多数实体在其嵌入空间中并不接近。
为了解决这个问题,我们应用了另一个GCN(以下简称GCN2)来在整个图中传播局部匹配信息。直观地说,如果每个节点都被表示为其自己的匹配状态,则设计一个具有足够多跳数的GCN能够编码整个图对之间的全局匹配状态。然后,我们将这些匹配表示馈送到一个全连接的神经网络,并应用逐元素最大池化和平均池化方法生成一个固定长度的图匹配表示。
预测层我们使用两层前馈神经网络来消耗固定长度的图匹配表示并在输出层中应用softmax函数。
训练和推理 为了训练模型,我们使用启发式方法为每个正例 <ei1, ej2> 随机构造 20 个负例。也就是说,我们首先通过对每个实体表面形式中预训练的单词嵌入求和来生成 G1 和 G2 的粗略实体嵌入;然后,我们在粗嵌入空间中选择 10 个与 ei1(或 ej2)最接近的实体来构造与 ej2(或 ei1)的负对。在测试过程中,给定 G1 中的一个实体,我们按照模型估计的匹配概率的降序对 G2 中的所有实体进行排名。
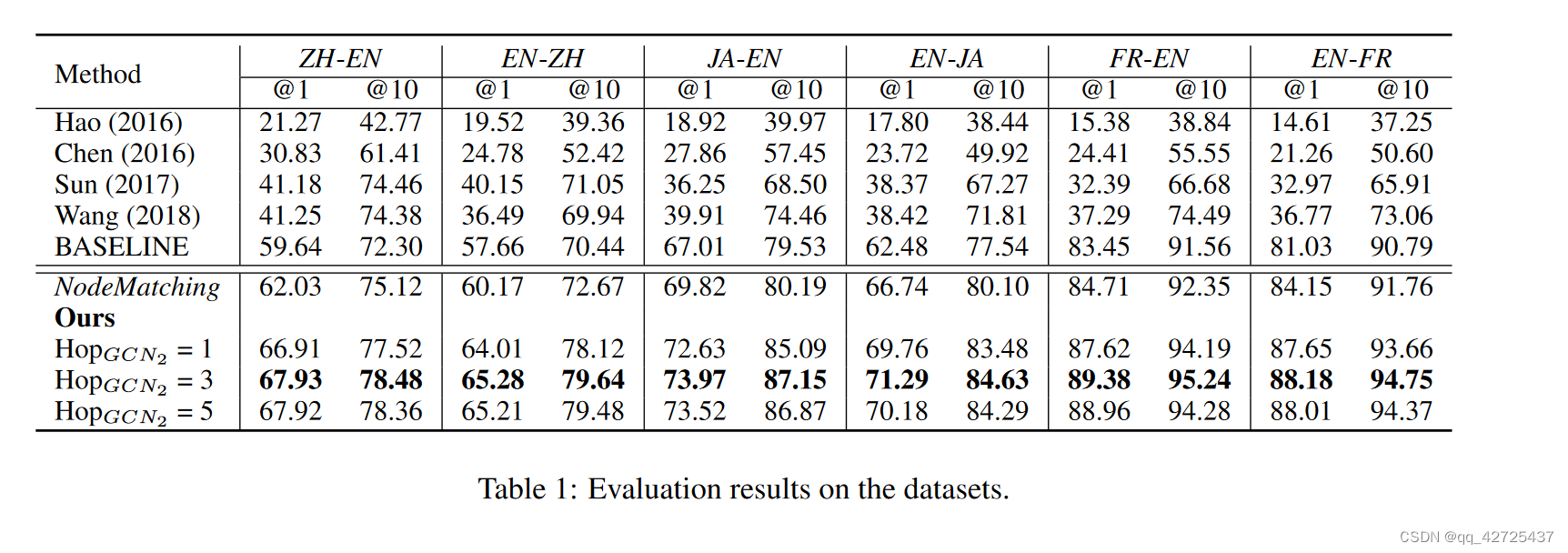
4 实验















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









