






前言
根据头条项目整理所学
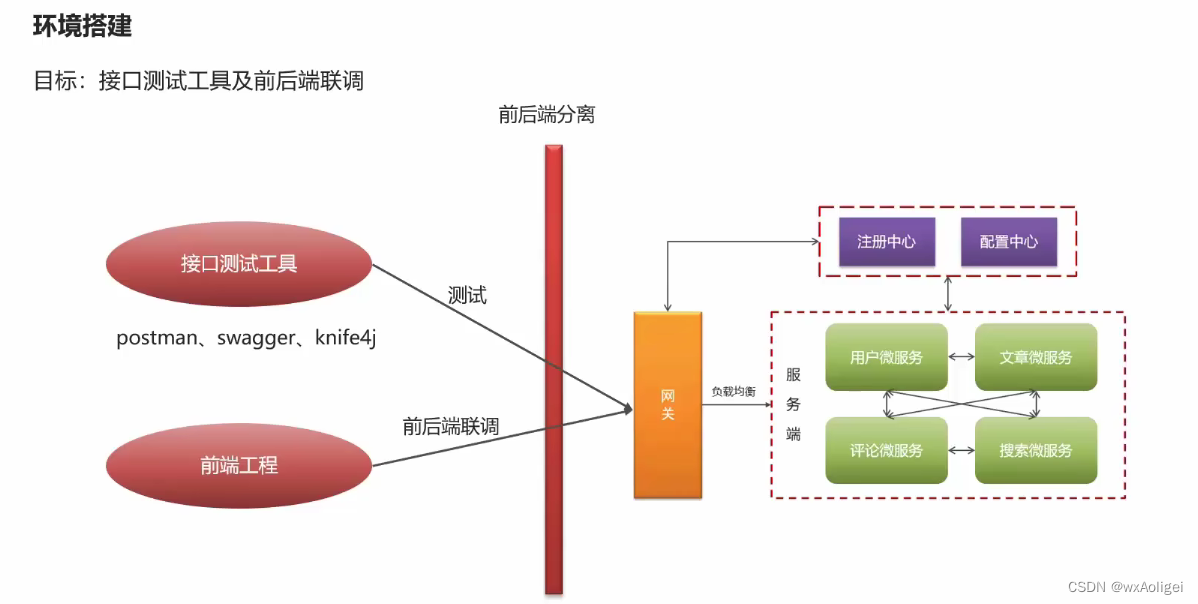
概要
Spring-Cloud-Gateway : 微服务之前架设的网关服务,实现服务注册中的API请求路由,以及控制流速控制和熔断处理都是常用的架构手段,而这些功能Gateway天然支持
运用Spring Boot快速开发框架,构建项目工程;并结合Spring Cloud全家桶技术,实现后端个人中心、自媒体、管理中心等微服务。
运用Spring Cloud Alibaba Nacos作为项目中的注册中心和配置中心
运用mybatis-plus作为持久层提升开发效率
运用Kafka完成内部系统消息通知;与客户端系统消息通知;以及实时数据计算
运用Redis缓存技术,实现热数据的计算,提升系统性能指标
使用Mysql存储用户数据,以保证上层数据查询的高性能
使用Mongo存储用户热数据,以保证用户热数据高扩展和高性能指标
使用FastDFS作为静态资源存储器,在其上实现热静态资源缓存、淘汰等功能
运用Hbase技术,存储系统中的冷数据,保证系统数据的可靠性
运用ES搜索技术,对冷数据、文章数据建立索引,以保证冷数据、文章查询性能
运用AI技术,来完成系统自动化功能,以提升效率及节省成本。比如实名认证自动化
PMD&P3C : 静态代码扫描工具,在项目中扫描项目代码,检查异常点、优化点、代码规范等,为开发团队提供规范统一,提升项目代码质量
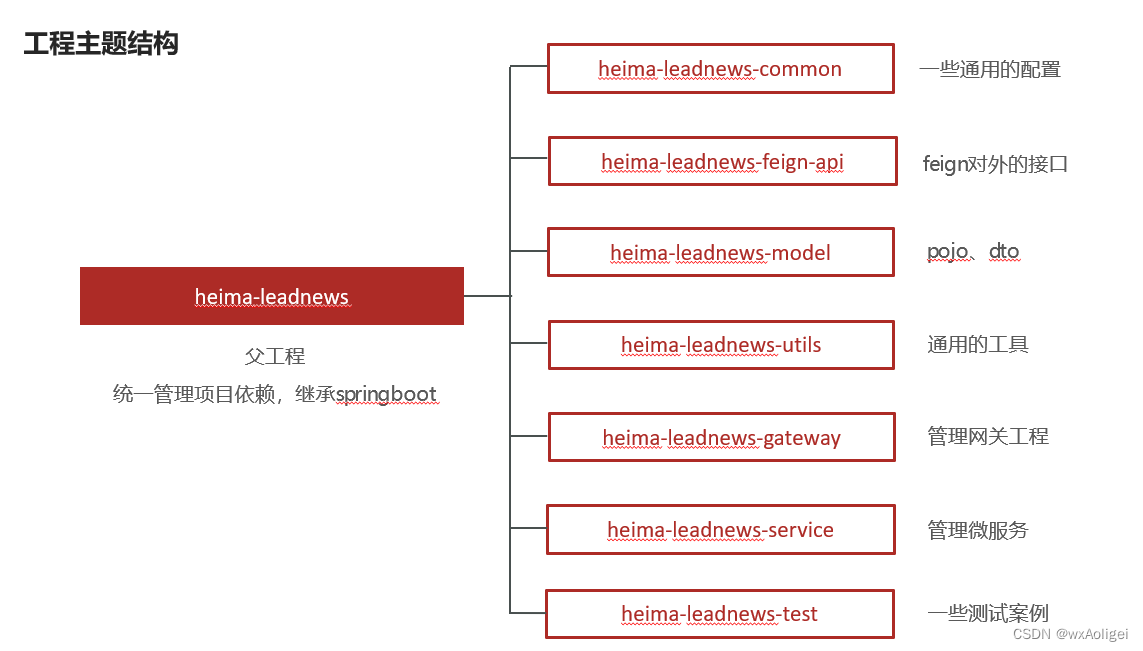
主体结构
技术细节
密码手动加密(md5+随机字符串)
md5是不可逆加密,md5相同的密码每次加密都一样,不太安全。在md5的基础上手动加盐(salt)处理
登录->使用盐来配合验证
1,用户输入了用户名和密码进行登录,校验成功后返回jwt(基于当前用户的id生成)
JSON Web Token(JWT)是一个非常轻巧的规范。这个规范允许我们使用 JWT 在用户和服务器之间传递安全可靠的信息。实际上就是一个字符串,它由三部分组成,头部、载荷与签名。前两部分需要经过 Base64 编码,后一部分通过前两部分 Base64 编码后再加密而成。
2,用户游客登录,生成jwt返回(基于默认值0生成)‘
接口工具postman、swagger、knife4j
postman
Swagger:
Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务(https://swagger.io/)。 它的主要作用是:
使得前后端分离开发更加方便,有利于团队协作
接口的文档在线自动生成,降低后端开发人员编写接口文档的负担
功能测试
Spring已经将Swagger纳入自身的标准,建立了Spring-swagger项目,现在叫Springfox。通过在项目中引入Springfox ,即可非常简单快捷的使用Swagger。
knife4
jknife4j是为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui,取名kni4j是希望它能像一把匕首一样小巧,轻量,并且功能强悍!
核心功能
该UI增强包主要包括两大核心功能:文档说明 和 在线调试
文档说明:根据Swagger的规范说明,详细列出接口文档的说明,包括接口地址、类型、请求示例、请求参数、响应示例、响应参数、响应码等信息,使用swagger-bootstrap-ui能根据该文档说明,对该接口的使用情况一目了然。
在线调试:提供在线接口联调的强大功能,自动解析当前接口参数,同时包含表单验证,调用参数可返回接口响应内容、headers、Curl请求命令实例、响应时间、响应状态码等信息,帮助开发者在线调试,而不必通过其他测试工具测试接口是否正确,简介、强大。
个性化配置:通过个性化ui配置项,可自定义UI的相关显示信息。
离线文档:根据标准规范,生成的在线markdown离线文档,开发者可以进行拷贝生成markdown接口文档,通过其他第三方markdown转换工具转换成html或pdf,这样也可以放弃swagger2markdown组件。
接口排序:自1.8.5后,ui支持了接口排序功能,例如一个注册功能主要包含了多个步骤,可以根据swagger-bootstrap-ui提供的接口排序规则实现接口的排序,step化接口操作,方便其他开发者进行接口对接
.网关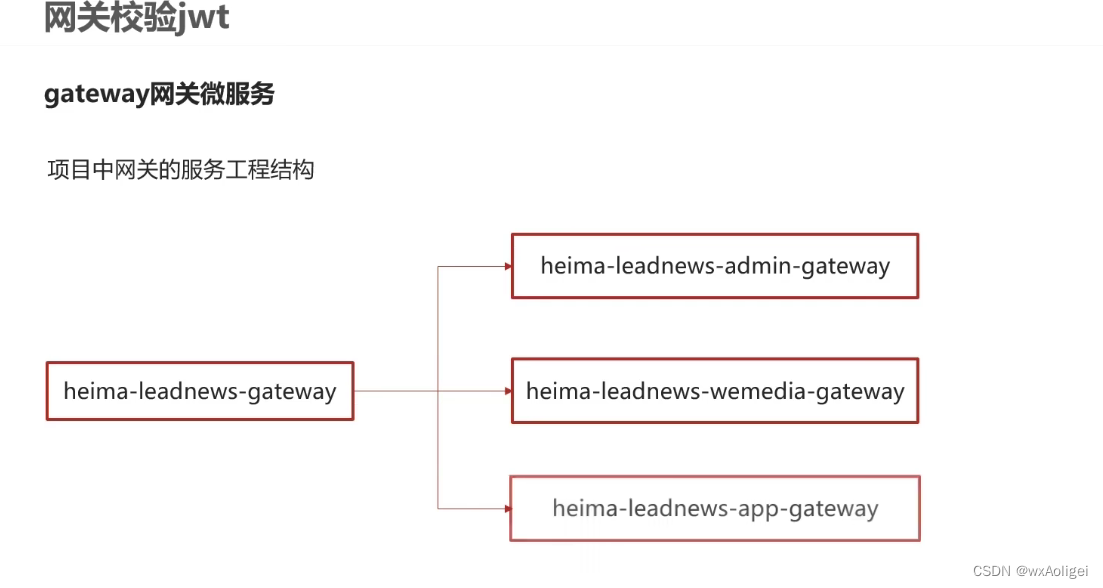
1配置网关微服务
2全局过滤器实现jwt校验
思路分析:
用户进入网关开始登陆,网关过滤器进行判断,如果是登录,则路由到后台管理微服务进行登录
用户登录成功,后台管理微服务签发JWT TOKEN信息返回给用户
用户再次进入网关开始访问,网关过滤器接收用户携带的TOKEN
网关过滤器解析TOKEN ,判断是否有权限,如果有,则放行,如果没有则返回未认证错误
具体实现:
第一:在认证过滤器中需要用到jwt的解析,所以需要把工具类拷贝一份到网关微服务
第二:在网关微服务中新建全局过滤器
AuthorizeFilter implements Ordered, GlobalFilter
测试:
启动user服务,继续访问其他微服务,会提示需要认证才能访问,这个时候需要在heads中设置设置token才能正常访问。
前端集成
app端文章查看,静态化freemarker,分布式文件系统minIO
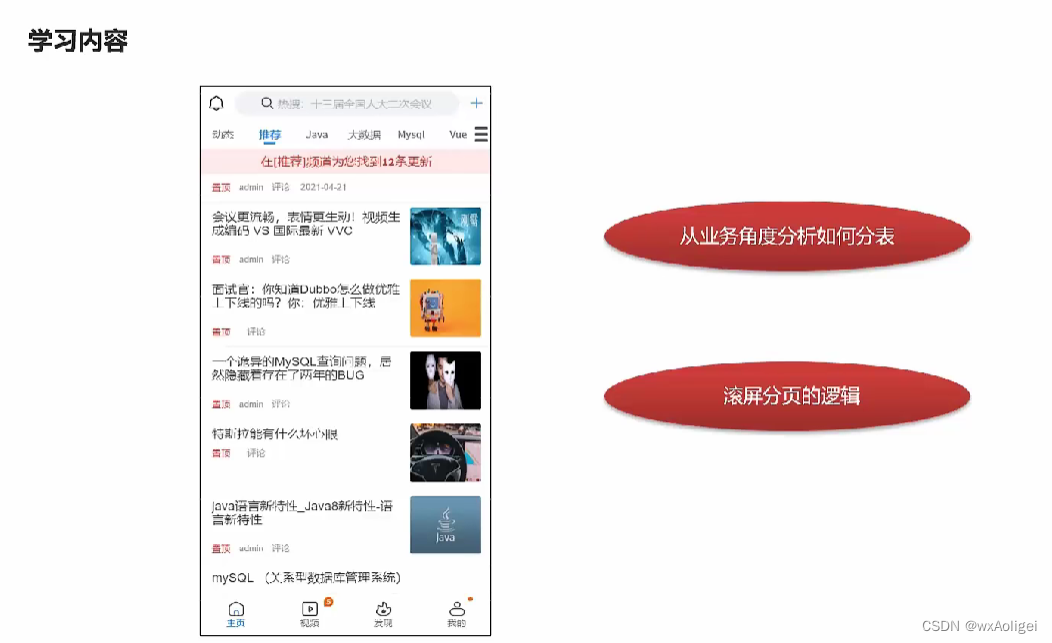

1.文章列表加载

1,在默认频道展示10条文章信息(分页)
2,可以切换频道查看不同种类文章
3,当用户下拉可以加载最新的文章(分页)本页文章列表中发布时间为最大的时间为依据
4,当用户上拉可以加载更多的文章信息(按照发布时间)本页文章列表中发布时间最小的时间为依据
2.freemarker
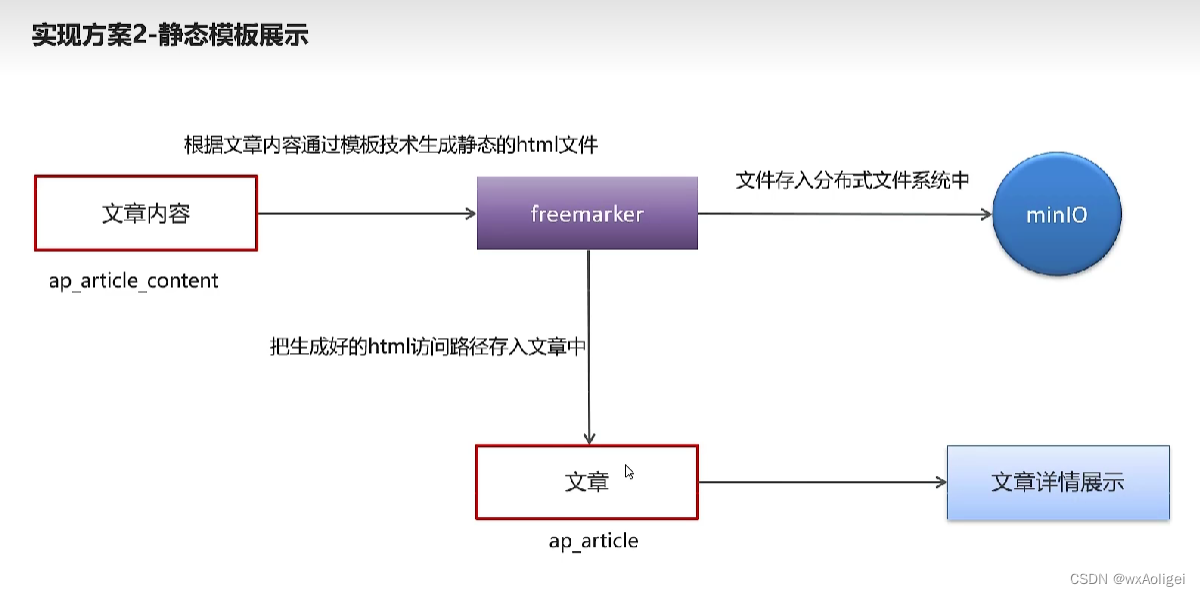
FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。 它不是面向最终用户的,而是一个Java类库,是一款程序员可以嵌入他们所开发产品的组件。
常用的java模板引擎还有哪些?
Jsp、Freemarker、Thymeleaf 、Velocity 等。
1.Jsp 为 Servlet 专用,不能单独进行使用。
2.Thymeleaf 为新技术,功能较为强大,但是执行的效率比较低。
3.Velocity从2010年更新完 2.0 版本后,便没有在更新。Spring Boot 官方在 1.4 版本后对此也不在支持,虽然 Velocity 在 2017 年版本得到迭代,但为时已晚。
4.Freemarker 性能好,强大的模板语,轻量。
2.2 环境搭建&&快速入门
freemarker作为springmvc一种视图格式,默认情况下SpringMVC支持freemarker视图格式。
需要创建Spring Boot+Freemarker工程用于测试模板。
2.3freemarker语法
3.对象存储服务MinIO
MinIO基于Apache License v2.0开源协议的对象存储服务,可以做为云存储的解决方案用来保存海量的图片,视频,文档。由于采用Golang实现,服务端可以工作在Windows,Linux, OS X和FreeBSD上。配置简单,基本是复制可执行程序,单行命令可以运行起来。
MinIO兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。
3.2 MinIO特点
数据保护
Minio使用Minio Erasure Code(纠删码)来防止硬件故障。即便损坏一半以上的driver,但是仍然可以从中恢复。
高性能
作为高性能对象存储,在标准硬件条件下它能达到55GB/s的读、35GB/s的写速率
可扩容
不同MinIO集群可以组成联邦,并形成一个全局的命名空间,并跨越多个数据中心
SDK支持
基于Minio轻量的特点,它得到类似Java、Python或Go等语言的sdk支持
有操作页面
面向用户友好的简单操作界面,非常方便的管理Bucket及里面的文件资源
功能简单
这一设计原则让MinIO不容易出错、更快启动
丰富的API
支持文件资源的分享连接及分享链接的过期策略、存储桶操作、文件列表访问及文件上传下载的基本功能等。
文件变化主动通知
存储桶(Bucket)如果发生改变,比如上传对象和删除对象,可以使用存储桶事件通知机制进行监控,并通过以下方式发布出去:AMQP、MQTT、Elasticsearch、Redis、NATS、MySQL、Kafka、Webhooks等。

4.文章详情
4.2)实现方案
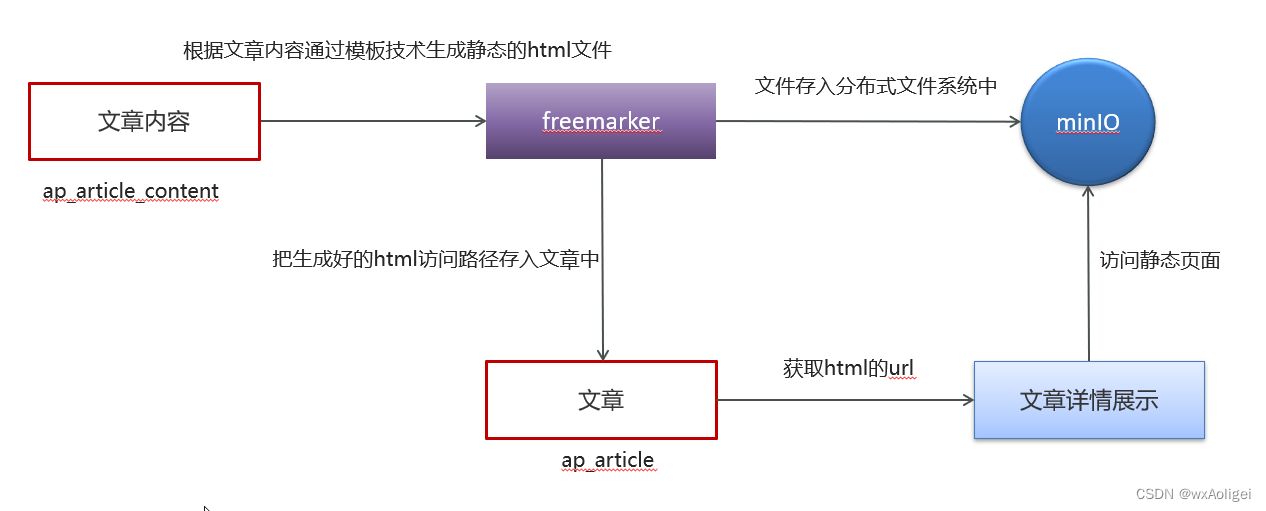
4.3)实现步骤
1.在artile微服务中添加MinIO和freemarker的支持,参考测试项目
直接把freemarker-demo和minio-demo模块相关的依赖和文件拷贝去heima-leadnews-article即可
2.资料中找到模板文件(article.ftl)拷贝到article微服务下
3.资料中找到index.js和index.css两个文件手动上传到MinIO中
4.在文章微服务中导入依赖
5.新建ApArticleContentMapper
6.在artile微服务中新增测试类(后期新增文章的时候创建详情静态页,目前暂时手动生成)运行之后static_url有字段填充,是一个url地址,我们访问一下,可以看到相关字段
自媒体文章发布
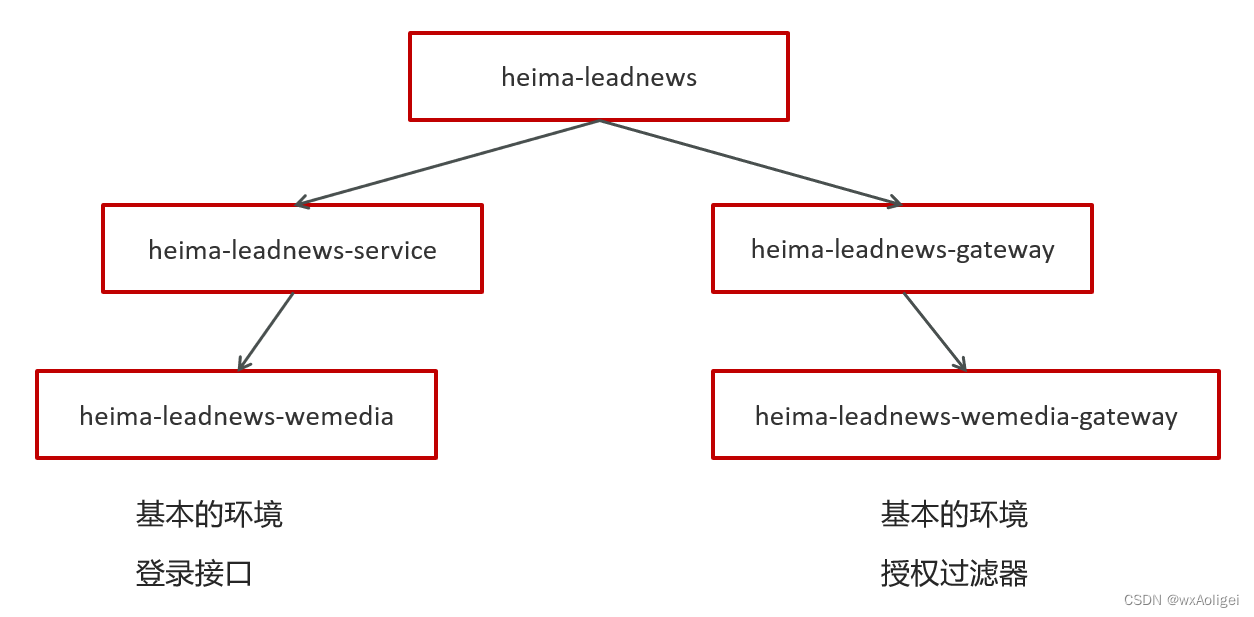
1.自媒体前后端搭建
1.1 后台搭建
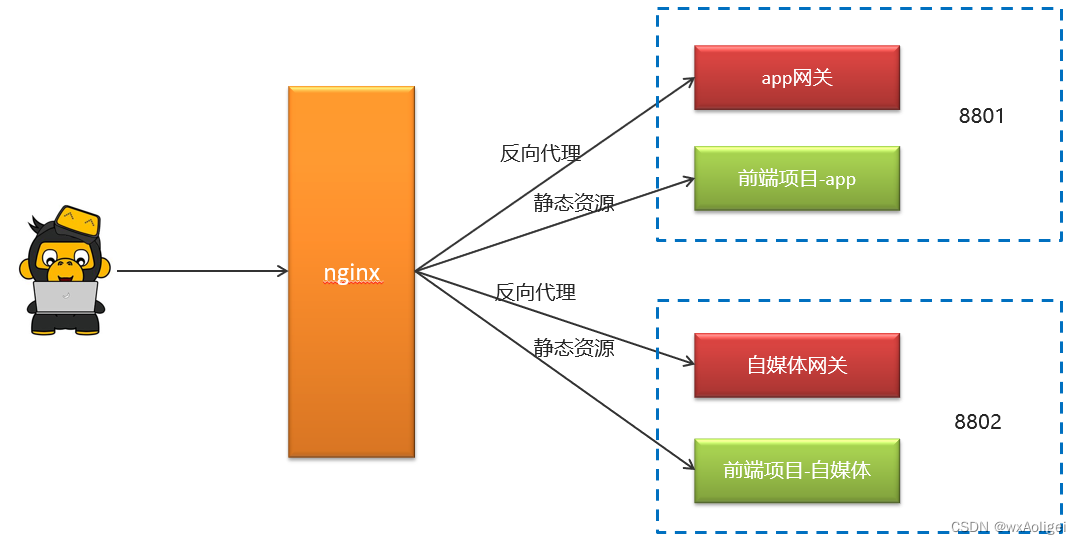
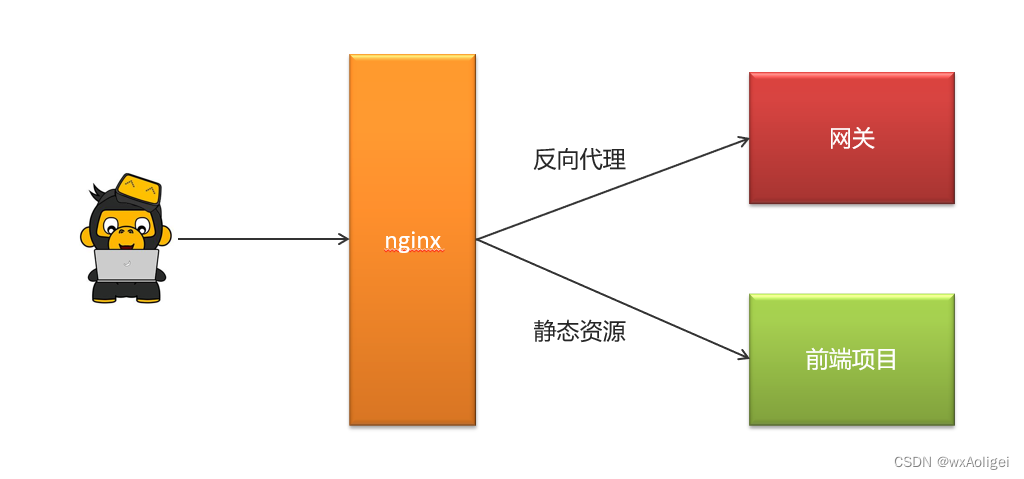
通过nginx的虚拟主机功能,使用同一个nginx访问多个项目
搭建步骤:
①:资料中找到wemedia-web.zip解压
②:在nginx中leadnews.conf目录中新增heima-leadnews-wemedia.conf文件
网关地址修改(localhost:51602)
前端项目目录修改(wemedia-web解压的目录)
访问端口修改(8802)
③:启动nginx,启动自媒体微服务和对应网关
④:联调测试登录功能
2.自媒体素材管理
2.1 素材上传
2.2.1 需求分析
2.2.2 素材管理-图片上传-表结构
2.2.3 实现思路
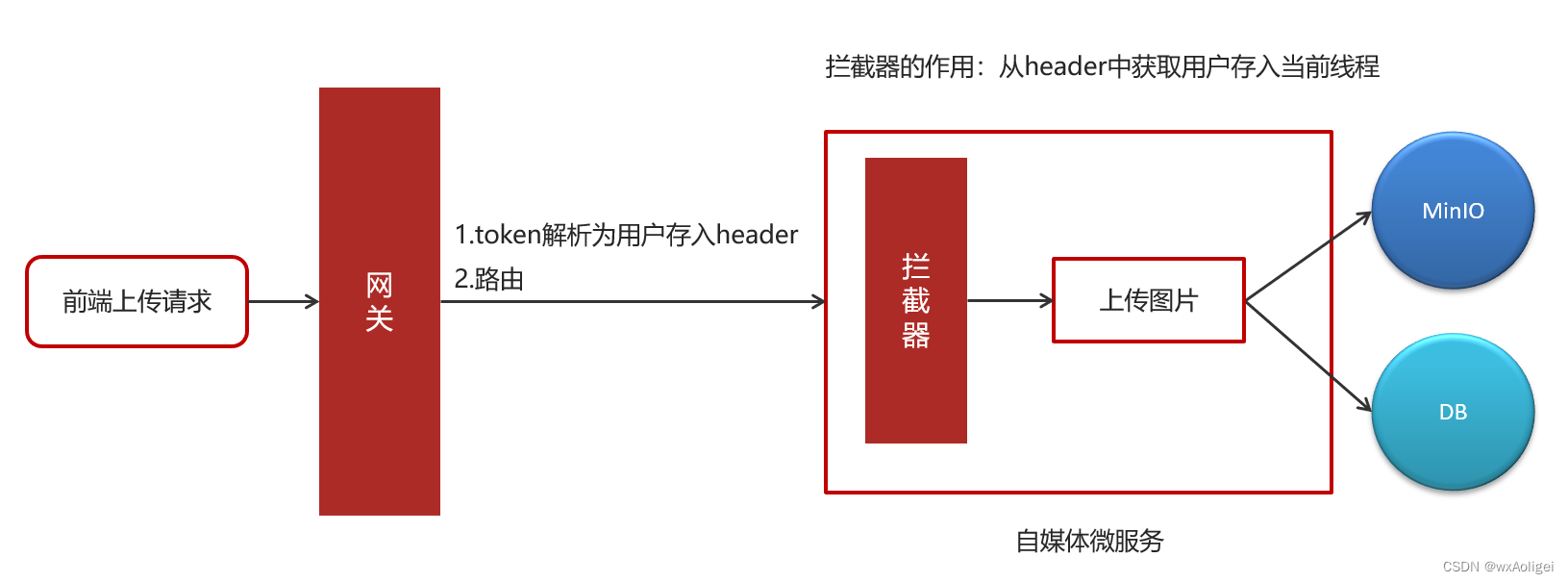
①:前端发送上传图片请求,类型为MultipartFile
②:网关进行token解析后,把解析后的用户信息存储到header中
③:自媒体微服务使用拦截器获取到header中的的用户信息,并放入到threadlocal中
在heima-leadnews-utils中新增工具类
注意:需要从资料中找出WmUser实体类拷贝到model工程下
在heima-leadnews-wemedia中新增拦截器
配置使拦截器生效,拦截所有的请求
④:先把图片上传到minIO中,获取到图片请求的路径——(2.2.5查看具体功能实现)
⑤:把用户id和图片上的路径保存到素材表中——(2.2.5查看具体功能实现)
2.2.5 自媒体微服务集成heima-file-starter
①:在heima-leadnews-wemedia子模块中导入heima-file-starter
②:在自媒体微服务的配置中心添加minIO配置
2.2.6 具体实现
①:创建WmMaterialController
②:mapper
③:业务层:
业务层实现类:
④:控制器
⑤:测试
2.3素材列表查询
2.3.1 接口定义
2.3.2 功能实现
①:在WmMaterialController类中新增方法findList
②:mapper已定义
③:业务层
在WmMaterialService中新增方法public ResponseResult findList( WmMaterialDto dto);
④:控制器:
@PostMapping(“/list”)
public ResponseResult findList(@RequestBody WmMaterialDto dto){
return wmMaterialService.findList(dto);
}
⑤:在自媒体heima-leadnews-wemedia模块中引导类中天mybatis-plus的分页拦截器
3.自媒体文章管理
3.1 查询所有频道
功能实现
接口定义:
@GetMapping(“/channels”)
public ResponseResult findAll(){
return null;
}
mapper:
@Mapper
public interface WmChannelMapper extends BaseMapper {
}
service:
public interface WmChannelService extends IService
实现类
控制层
public class WmchannelController {
@Autowired
private WmChannelService wmChannelService;
@GetMapping("/channels")
public ResponseResult findAll(){
return wmChannelService.findAll();
}
}
3.2 查询自媒体文章
3.2.1 需求说明:内容列表
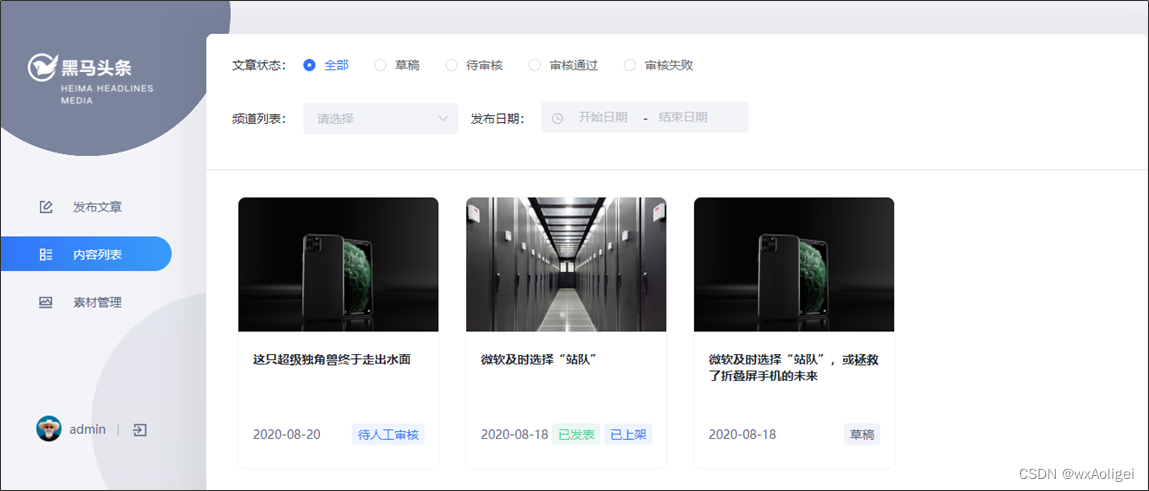
对应实体类:public class WmNews implements Serializable
接口定义
功能实现
①:新增WmNewsController
②:新增WmNewsMapper
③:新增WmNewsService
实现类:
④:控制器
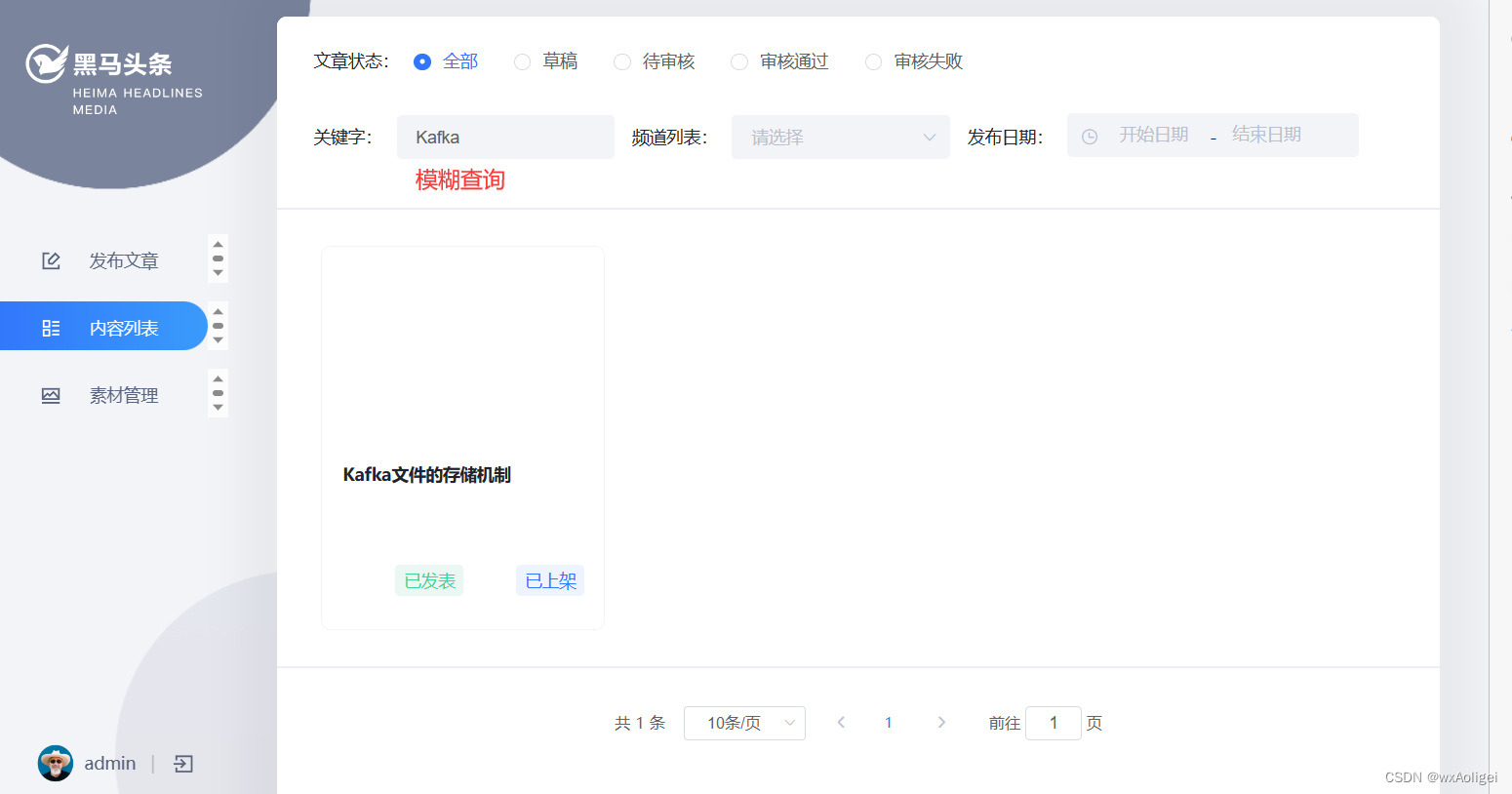
3.3 文章发布
3.3.1 需求分析
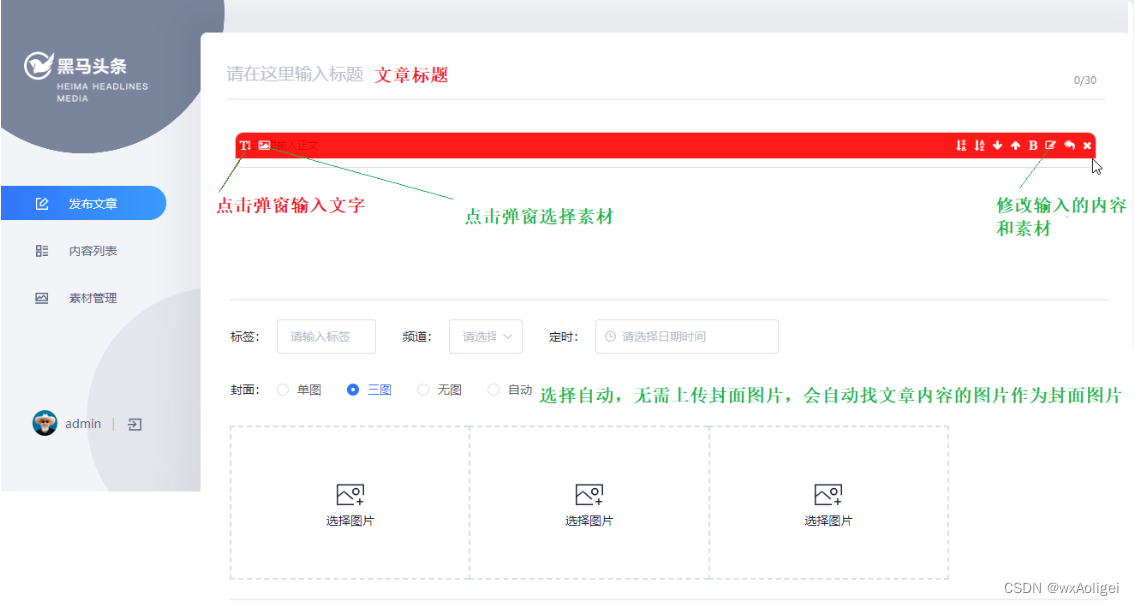
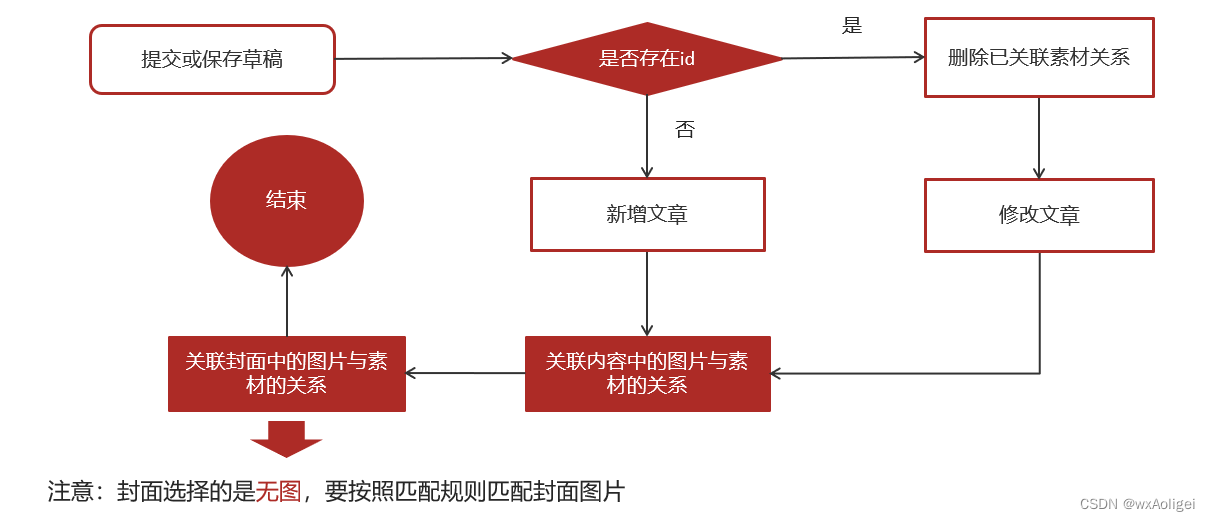
.前端提交发布或保存为草稿
2.后台判断请求中是否包含了文章id
3.如果不包含id,则为新增
3.1 执行新增文章的操作
3.2 关联文章内容图片与素材的关系
3.3 关联文章封面图片与素材的关系
4.如果包含了id,则为修改请求
4.1 删除该文章与素材的所有关系
4.2 执行修改操作
4.3 关联文章内容图片与素材的关系
4.4 关联文章封面图片与素材的关系
功能实现
①:在新增WmNewsController中新增方法
@PostMapping(“/submit”)
public ResponseResult submitNews(@RequestBody WmNewsDto dto){
return null;
}
②:新增WmNewsMaterialMapper类,文章与素材的关联关系需要批量保存,索引需要定义mapper文件和对应的映射文件
WmNewsMaterialMapper.xml
③:常量类准备WemediaConstants
④:在WmNewsService中新增方法
实现方法:
④:控制器
@PostMapping(“/submit”)
public ResponseResult submitNews(@RequestBody WmNewsDto dto){
return wmNewsService.submitNews(dto);
}
自媒体文章-自动审核
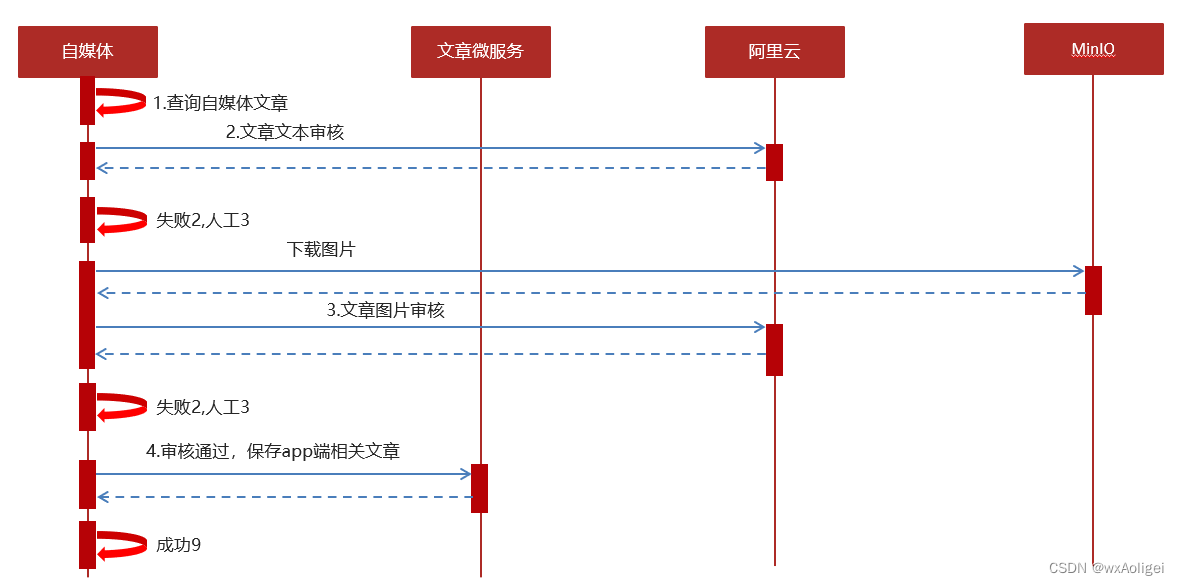
1.自媒体文章自动审核流程
文章数据流
流程:

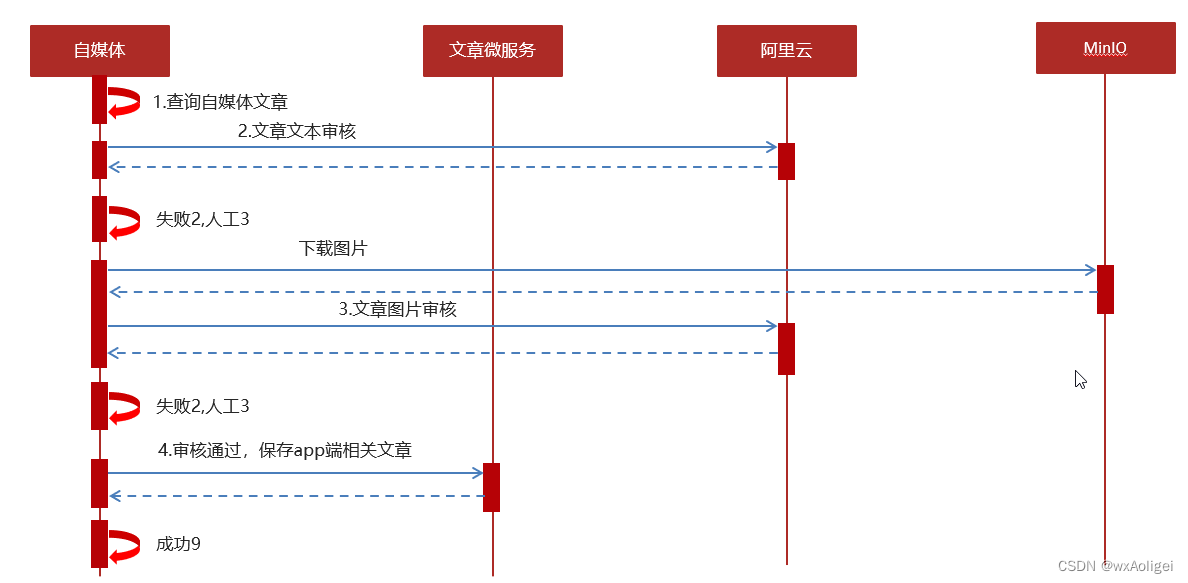
1 自媒体端发布文章后,开始审核文章
2 审核的主要是审核文章的内容(文本内容和图片)
3 借助第三方提供的接口审核文本
4 借助第三方提供的接口审核图片,由于图片存储到minIO中,需要先下载才能审核
5 如果审核失败,则需要修改自媒体文章的状态,status:2 审核失败 status:3 转到人工审核
6 如果审核成功,则需要在文章微服务中创建app端需要的文章
内容安全第三方接口
2.1 概述
内容安全是识别服务,支持对图片、视频、文本、语音等对象进行多样化场景检测,有效降低内容违规风险。
目前很多平台都支持内容检测,如阿里云、腾讯云、百度AI、网易云等国内大型互联网公司都对外提供了API。
按照性能和收费来看,黑马头条项目使用的就是阿里云的内容安全接口,使用到了图片和文本的审核。

①:拷贝资料文件夹中的类到common模块下面,并添加到自动配置
包括了GreenImageScan和GreenTextScan及对应的工具类
添加到自动配置中
②: accessKeyId和secret(需自己申请)
在heima-leadnews-wemedia中的nacos配置中心添加accessKeyId和secret
③:在自媒体微服务中测试类中注入审核文本和图片的bean进行测试
3.app端文章保存接口
3.2 分布式id
随着业务的增长,文章表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
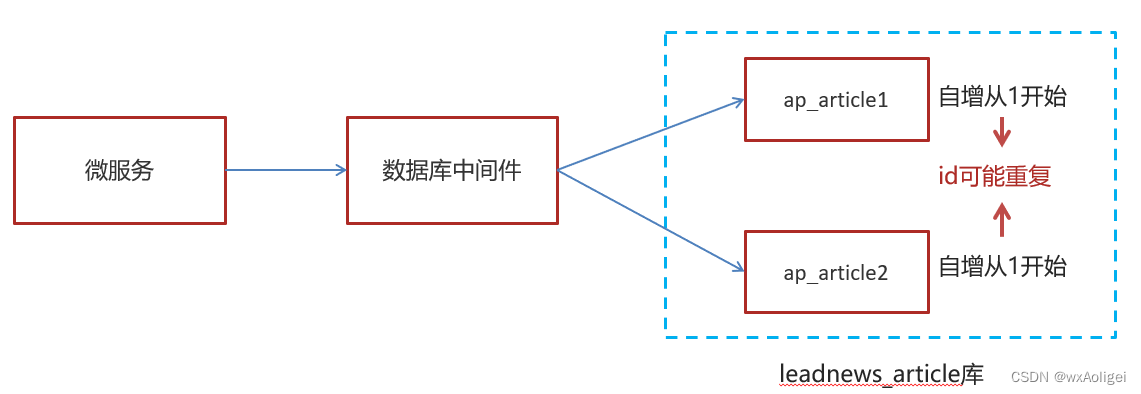
分布式id-技术选型
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0
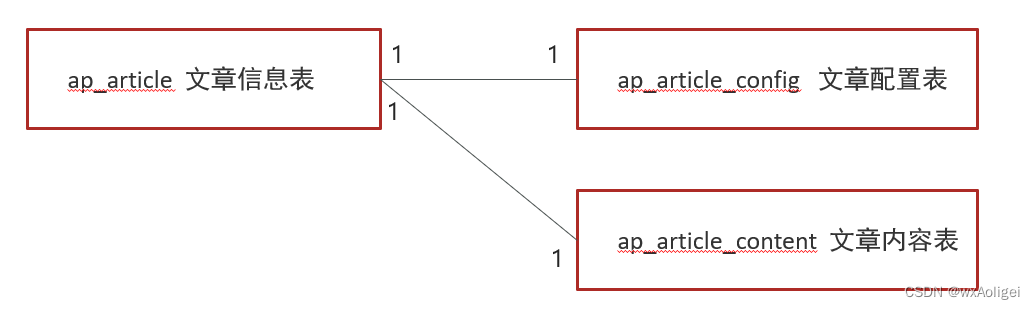
文章端相关的表都使用雪花算法生成id,包括ap_article、 ap_article_config、 ap_article_content
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
第一:在实体类中的id上加入如下配置,指定类型为id_worker
第二:在application.yml文件中配置数据中心id和机器id
3.3 思路分析
在文章审核成功以后需要在app的article库中新增文章数据
1.保存文章信息 ap_article
2.保存文章配置信息 ap_article_config
3.保存文章内容 ap_article_content
实现思路:
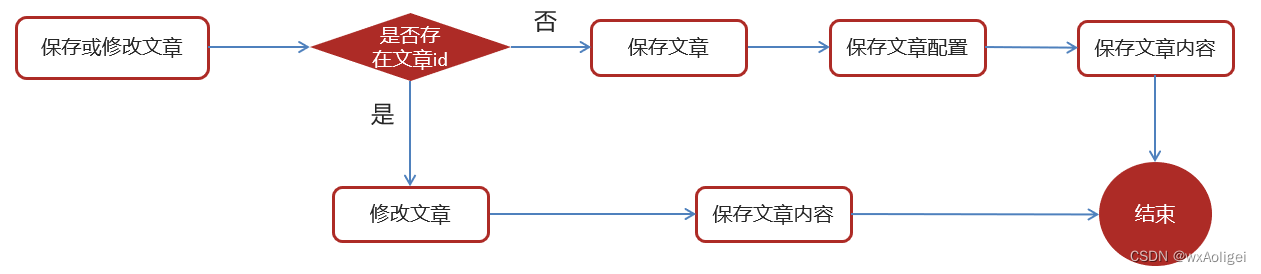
3.4 feign接口

ArticleDto: ArticleDto extends ApArticle
功能实现:
①:在heima-leadnews-feign-api中新增接口
第一:先导入feign的依赖
第二:定义文章端的接口
②:在heima-leadnews-article中实现该方法
③:拷贝mapper
在资料文件夹中拷贝ApArticleConfigMapper类到mapper文件夹中
同时,修改ApArticleConfig类,添加如下构造函数
④:在ApArticleService中新增方法
实现类:
⑤:测试
编写junit单元测试,或使用postman进行测试、
4.自媒体文章自动审核功能实现
4.1 表结构说明
wm_news 自媒体文章表
4.2 实现
在heima-leadnews-wemedia中的service新增接口 WmNewsAutoScanService
public interface WmNewsAutoScanService {
/**
* 自媒体文章审核
* @param id 自媒体文章id
*/
public void autoScanWmNews(Integer id);
}
实现类
4.3 单元测试
对WmNewsAutoScanService创建单元测试
4.4 feign远程接口调用方式

在heima-leadnews-wemedia服务中已经依赖了heima-leadnews-feign-apis工程,只需要在自媒体的引导类中开启feign的远程调用即可
注解为:@EnableFeignClients(basePackages = “com.heima.apis”) 需要指向apis这个包
4.5 服务降级处理

服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃
服务降级虽然会导致请求失败,但是不会导致阻塞。
实现步骤:
①:在heima-leadnews-feign-api编写降级逻辑
@Component
public class IArticleClientFallback implements IArticleClient {
@Override
public ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,“获取数据失败”);
}
}
在自媒体微服务中添加类,扫描降级代码类的包
②:远程接口中指向降级代码
③:客户端开启降级heima-leadnews-wemedia
在wemedia的nacos配置中心里添加如下内容,开启服务降级,也可以指定服务响应的超时的时间
④:测试
在ApArticleServiceImpl类中saveArticle方法添加代码
在自媒体端进行审核测试,会出现服务降级的现象
启动文章微服务即可,我们以id = 6232的数据来测试
5.发布文章提交审核集成
5.1 同步调用与异步调用
同步:就是在发出一个调用时,在没有得到结果之前, 该调用就不返回(实时处理)
异步:调用在发出之后,这个调用就直接返回了,没有返回结果(分时处理)
异步线程的方式审核文章
5.2 Springboot集成异步线程调用
①:在自动审核的方法上加上@Async注解(标明要异步调用)
②:在文章发布成功后调用审核的方法
③:在自媒体引导类中使用@EnableAsync注解开启异步调用
6.文章审核功能-综合测试
6.1 服务启动列表
1,nacos服务端
2,article微服务
3,wemedia微服务
4,启动wemedia网关微服务
5,启动前端系统wemedia
6.2 测试情况列表
1,自媒体前端发布一篇正常的文章
审核成功后,app端的article相关数据是否可以正常保存,自媒体文章状态和app端文章id是否回显
2,自媒体前端发布一篇包含敏感词的文章
正常是审核失败, wm_news表中的状态是否改变,成功和失败原因正常保存
3,自媒体前端发布一篇包含敏感图片的文章
正常是审核失败, wm_news表中的状态是否改变,成功和失败原因正常保存
最后我们测试一下异步调用出错,是否会影响发布文章本身。
修改WmNewsAutoScanServiceImpl.java
7.新需求-自管理敏感词
7.2 敏感词-过滤
技术选型
7.3 DFA实现原理
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。
存储:一次性的把所有的敏感词存储到了多个map中,就是下图表示这种结构

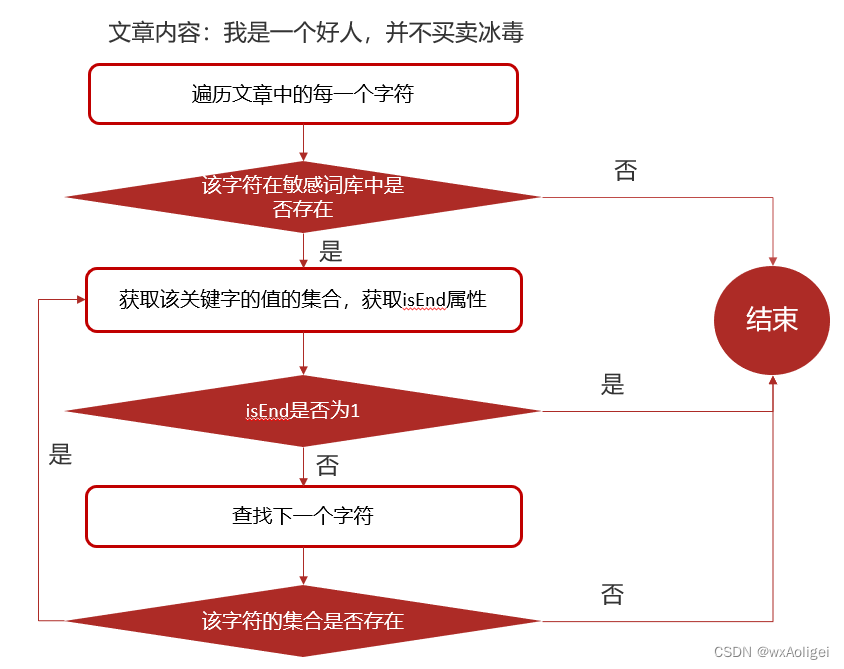
7.4 自管理敏感词集成到文章审核中
①:创建敏感词表,导入资料中wm_sensitive到leadnews_wemedia库中
②:拷贝对应的wm_sensitive的mapper到项目中
③:在文章审核的代码中添加自管理敏感词审核
第一:在WmNewsAutoScanServiceImpl中的autoScanWmNews方法上添加如下代码
新增自管理敏感词审核代码
8.新需求-图片识别文字审核敏感词
文章中包含的图片要识别文字,过滤掉图片文字的敏感词
什么是OCR?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程
8.3 Tess4j案例
新建tess4j-demo放在heima-leadnews-test模块下
①:创建项目导入tess4j对应的依赖
②:导入中文字体库, 把资料中的tessdata文件夹拷贝到自己的工作空间下
③:编写测试类进行测试
8.4 管理敏感词和图片文字识别集成到文章审核
①:在heima-leadnews-common中创建工具类,简单封装一下tess4j
③:在WmNewsAutoScanServiceImpl中的handleImageScan方法上添加如下代码
9.文章详情-静态文件生成
9.1 思路分析
文章端创建app相关文章时,生成文章详情静态页上传到MinIO中

9.2 实现步骤
1.新建ArticleFreemarkerService创建静态文件并上传到minIO中
实现
2.在ApArticleService的saveArticle实现方法中添加调用生成文件的方法
3.文章微服务开启异步调用
延迟任务精准发布文章
1.文章定时发布
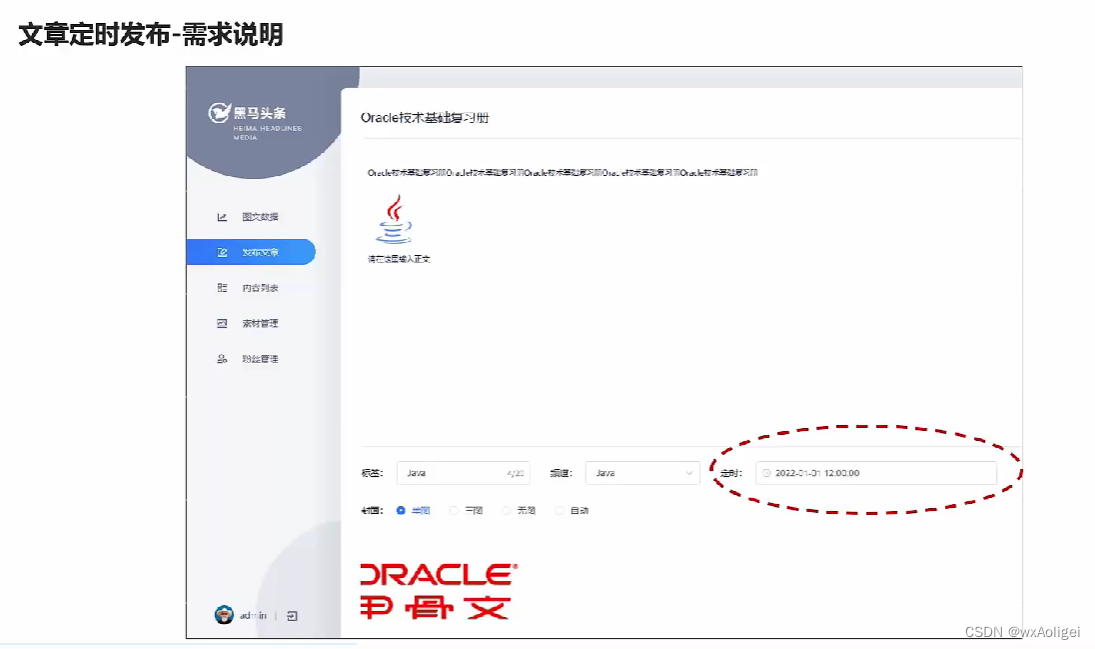
2.延迟任务概述
2.1 什么是延迟任务
定时任务:有固定周期的,有明确的触发时间。
延迟队列:没有固定的开始时间,它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件,任务可以立即执行,也可以延迟。
场景一:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单;如果期间下单成功,任务取消。
场景二:接口对接出现网络问题,1分钟后重试,如果失败,2分钟重试,直到出现阈值终止。
2.2 技术对比
2.2.1 DelayQueue
JDK自带DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素
DelayQueue属于排序队列,它的特殊之处在于队列的元素必须实现Delayed接口,该接口需要实现compareTo和getDelay方法
getDelay方法:获取元素在队列中的剩余时间,只有当剩余时间为0时元素才可以出队列。
compareTo方法:用于排序,确定元素出队列的顺序。

实现:
1:在测试包jdk下创建延迟任务元素对象DelayedTask,实现compareTo和getDelay方法,
2:在main方法中创建DelayQueue并向延迟队列中添加三个延迟任务,
3:循环的从延迟队列中拉取任务
DelayQueue实现完成之后思考一个问题:
使用线程池或者原生DelayQueue程序挂掉之后,任务都是放在内存,需要考虑未处理消息的丢失带来的影响,如何保证数据不丢失,需要持久化(磁盘)
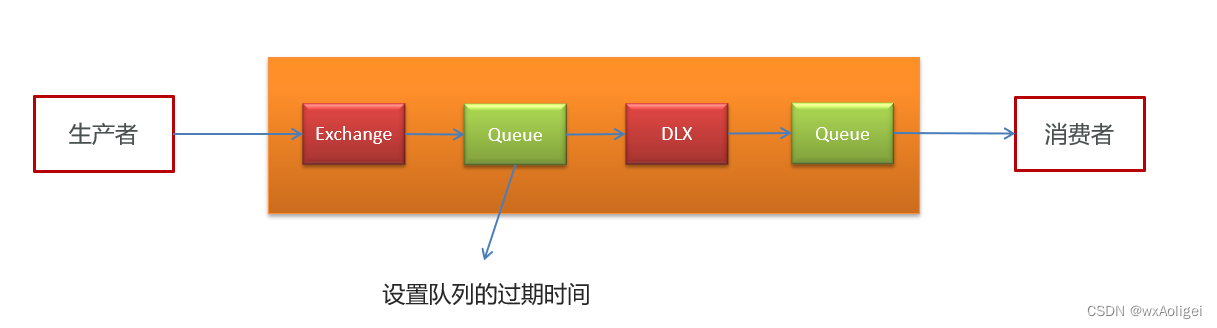
2.2.2 RabbitMQ实现延迟任务
TTL:Time To Live (消息存活时间)
死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以重新发送另一个交换机(死信交换机)
2.2.3 redis实现
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序

例如:
生产者添加到4个任务到延迟队列中,时间亳秒值分别为97、98、 99、 100。 当前时间的亳秒值为90。
消费者端进行监听,如果当前时间的毫秒值匹配到了延迟队列中的秒值就立即消费。
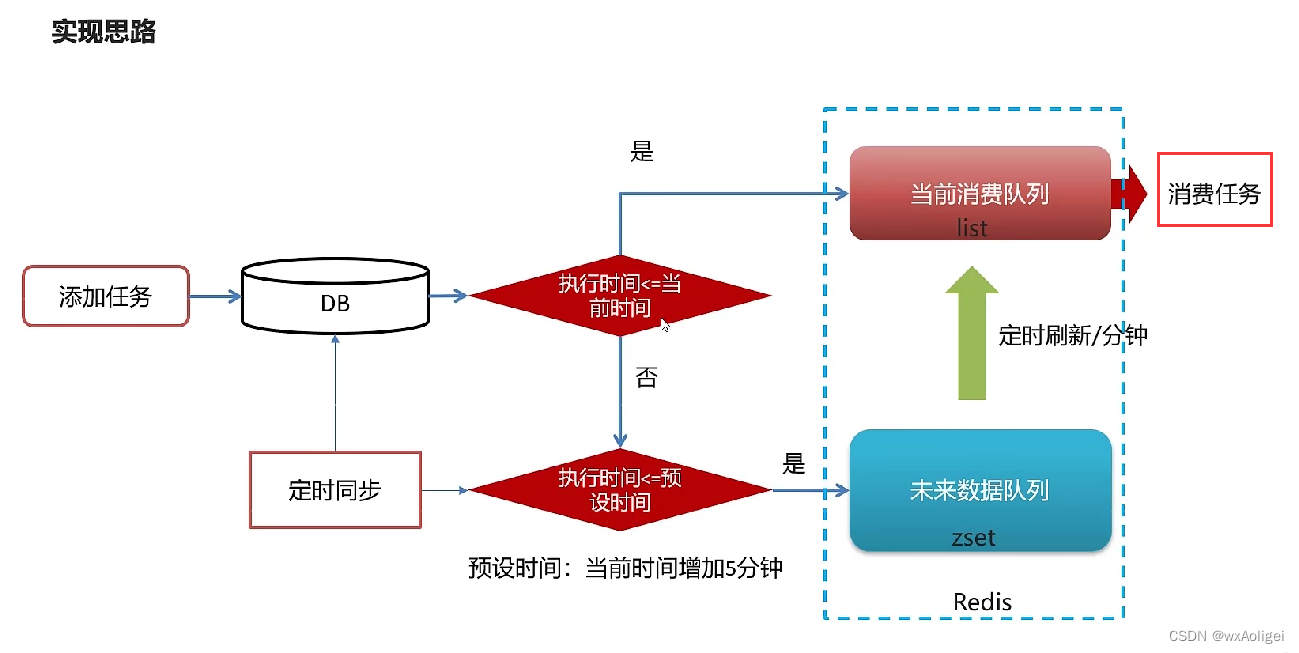
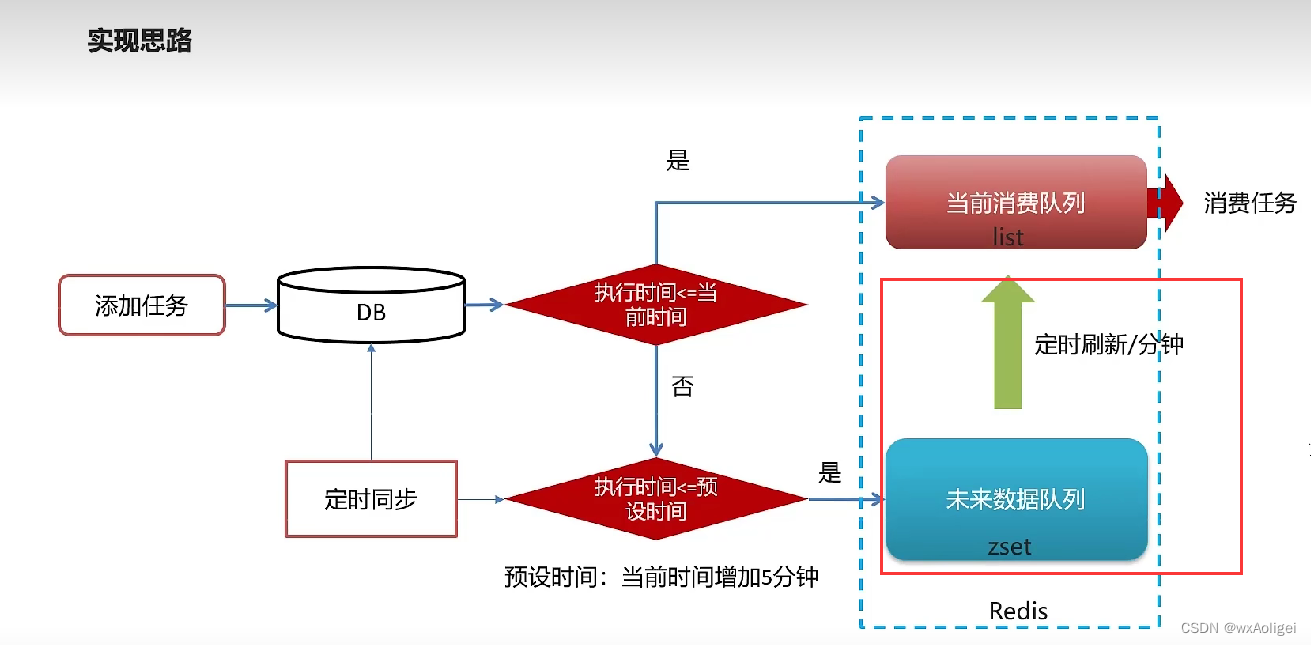
3.redis实现延迟任务
实现思路
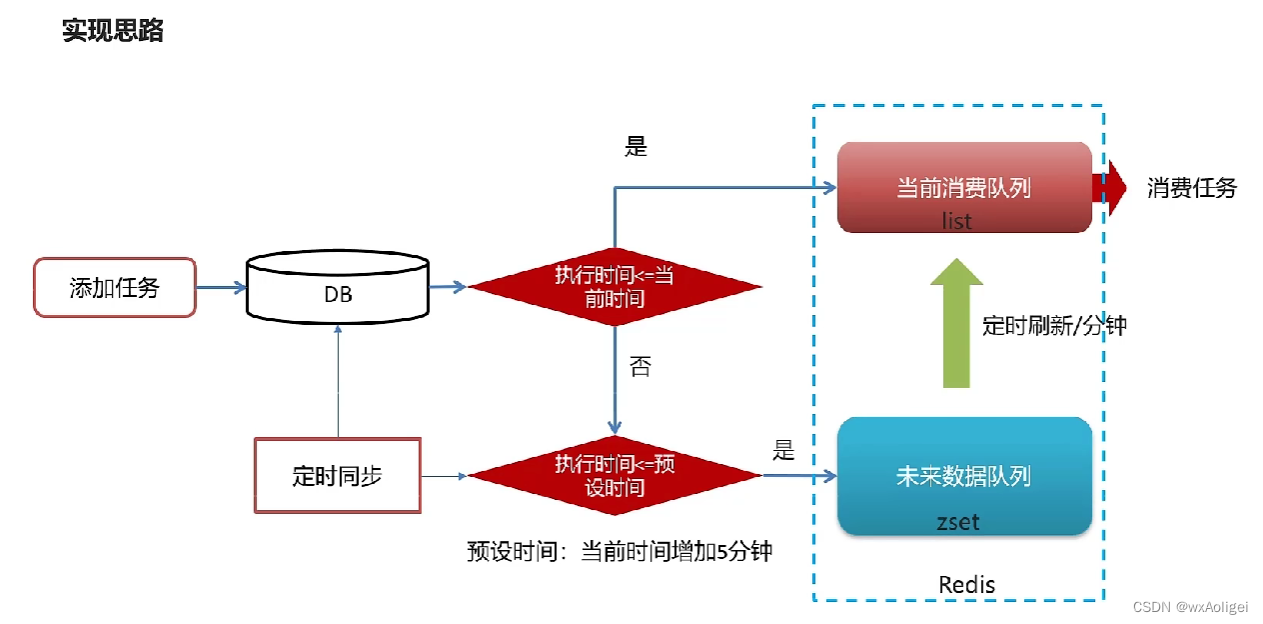
1).为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑。
2).为什么redis中使用两种数据类型,list和zset?
原因一: list存储立即执行的任务,zset存储未来的数据。
原因二:任务量过大以后,zset的性能会下降。
时间复杂渡:执行时间(次数)随着数据规模增长的变化趋势
操作redis中的list命令LPUSH: 时间复杂度: 0(1)
操作redis中的zset命令zadd: 时间复杂度: O(M*log(n))
3).在添加zset数据的时候,为什么需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题,如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可,是一种优化形式。
4.延迟任务服务实现
4.1 搭建heima-leadnews-schedule模块
leadnews-schedule是一个通用的服务,单独创建模块来管理任何类型的延迟任务
①:导入资料文件夹下的heima-leadnews-schedule模块到heima-leadnews-service下,如下所示:
在pom.xml中添加子模块
heima-leadnews-schedule
②:添加bootstrap.yml
③:在nacos中添加对应配置,并添加数据库及mybatis-plus的配置
4.2 数据库准备
导入资料中leadnews_schedule数据库
注意事项
MySQL中,BLOB是一个二 进制大型对象,是一个可以存储大量数据的容器。
LongBlob 最大存储4G
实体类public class Taskinfo implements Serializable
4.2.1 数据库准备-数据库自身解决并发两种策略
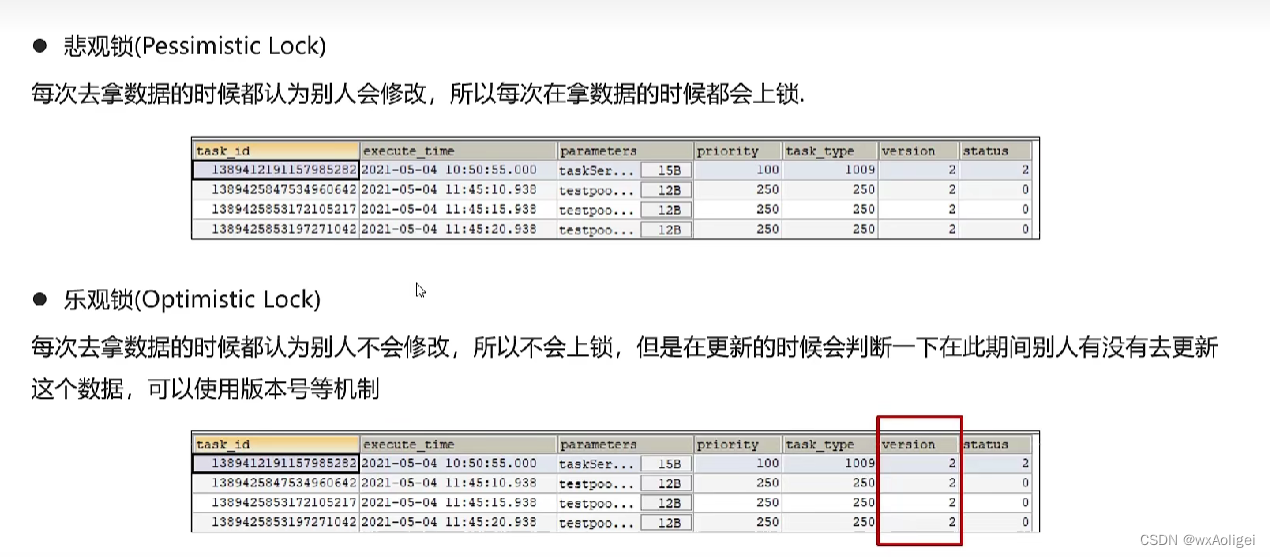
4.2.2 数据库准备-mybatis-plus集成乐观锁的使用
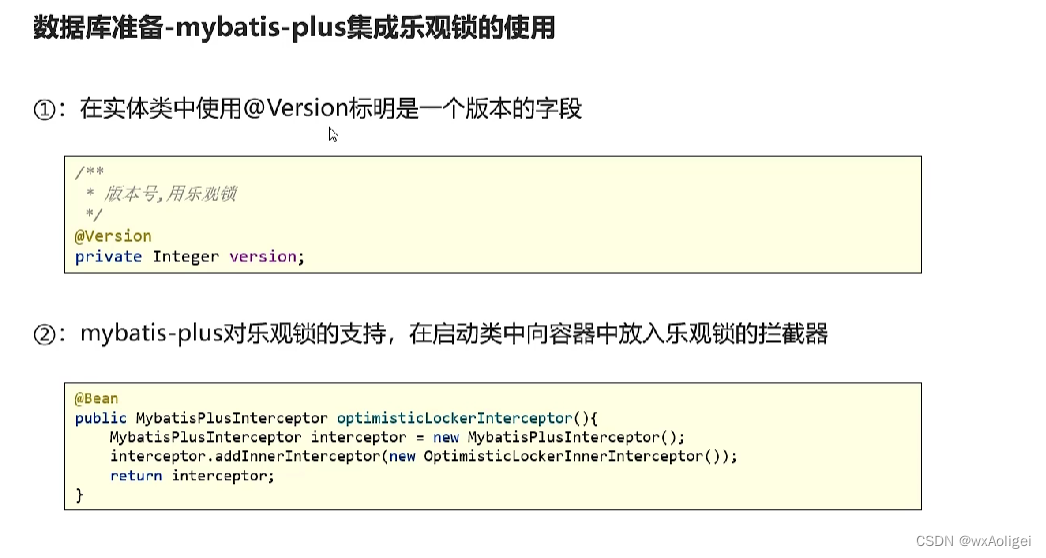
乐观锁支持:
4.3 安装redis
4.4 项目集成redis
① 在heima-leadnews-common项目导入redis相关依赖,已经完成
② 在heima-leadnews-schedule中集成redis,添加以下nacos配置,链接上redis
③ 拷贝资料文件夹下的类:CacheService到heima-leadnews-common模块下,并添加自动配置
④:测试
4.5 添加任务
①:拷贝mybatis-plus生成的文件,mapper
②:创建task类,用于接收添加任务的参数
③:创建TaskService
实现:
ScheduleConstants常量类
④:测试
对TaskService,使用快捷键Alt + Enter选择Create Test,勾选addTask
把时间进一步增加,超过5分钟,发现数据库有存数据,redis缓存:没有数据。
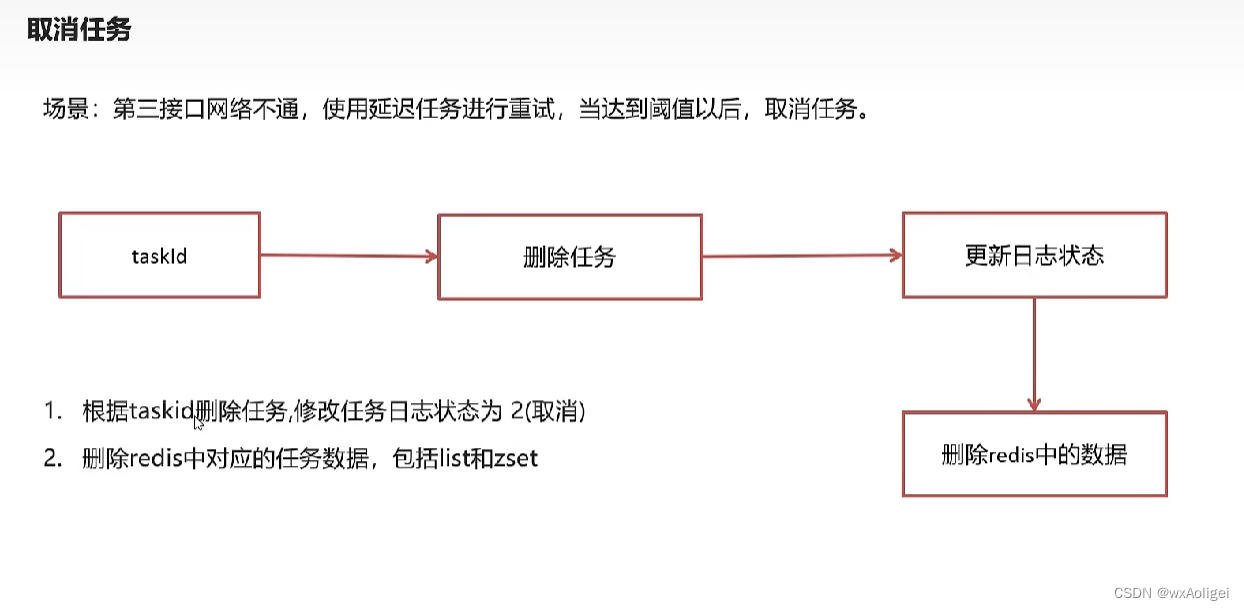
4.6 取消任务
4.7 消费任务
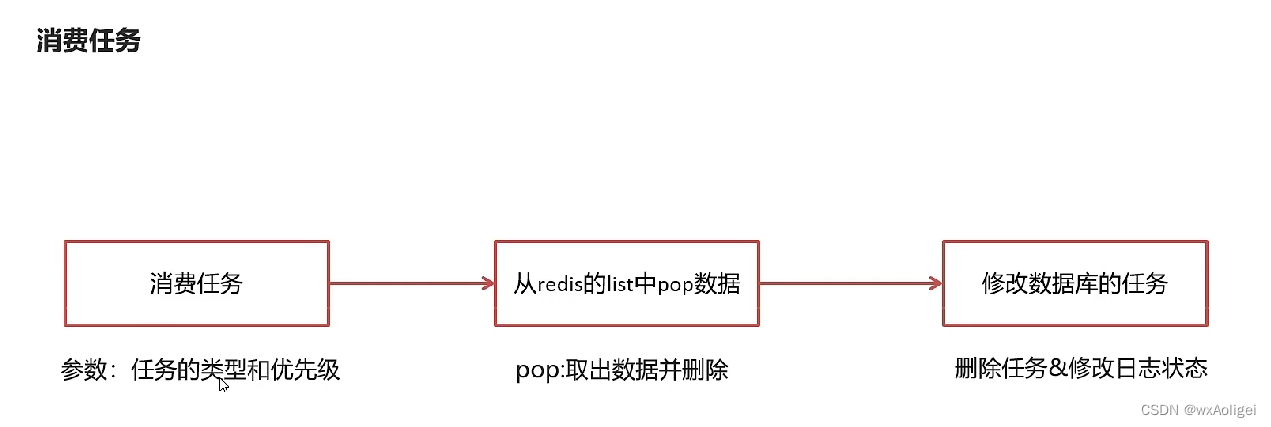
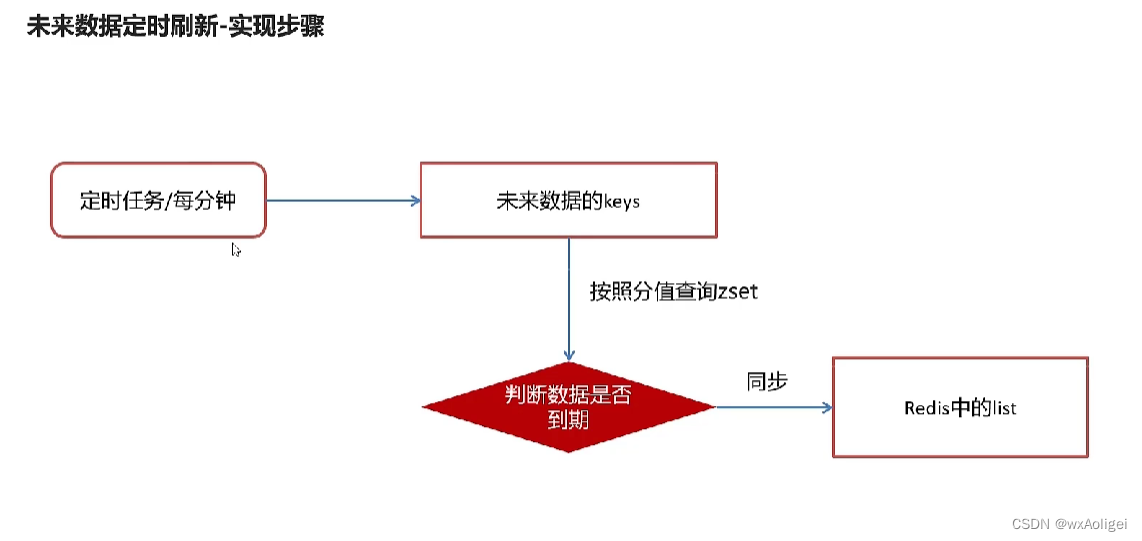
4.8 未来数据定时刷新
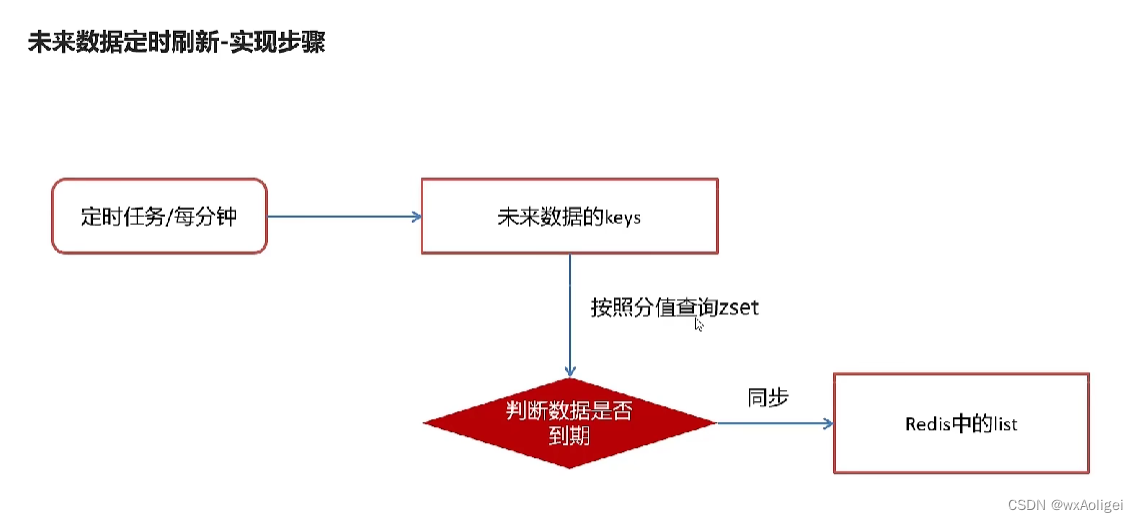
4.8.1 redis key值匹配
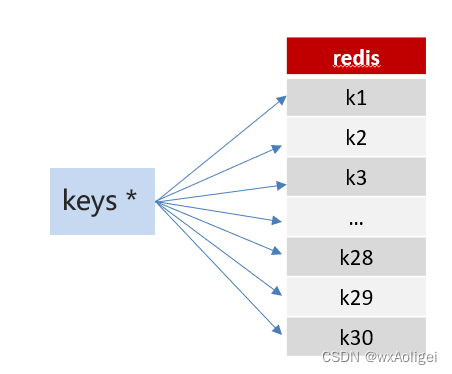
方案1:keys 模糊匹配
keys的模糊匹配功能很方便也很强大,但是在生产环境需要慎用!开发中使用keys的模糊匹配却发现redis的CPU使用率极高,所以公司的redis生产环境将keys命令禁用了!redis是单线程,会被堵塞
方案2:scan
SCAN 命令是一个基于游标的迭代器,SCAN命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数, 以此来延续之前的迭代过程。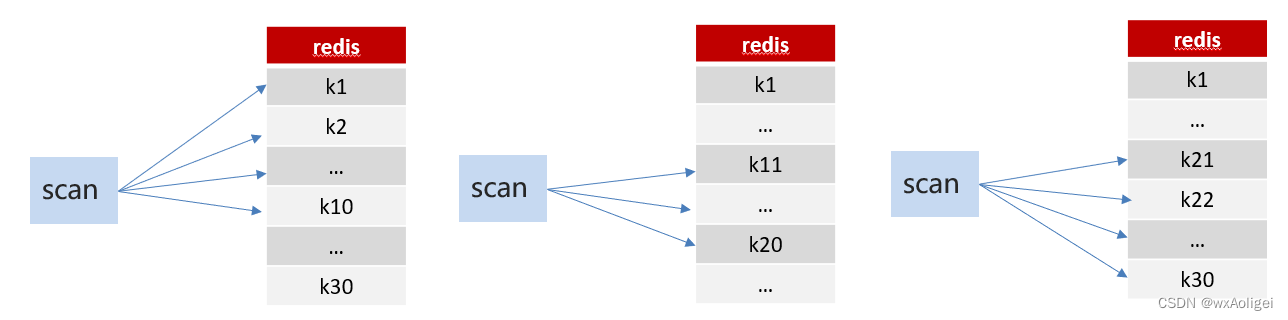
4.8.2 redis管道
4.8.3 未来数据定时刷新-功能完成
4.9 分布式锁解决集群下的方法抢占执行
4.9.1 问题描述
启动两台heima-leadnews-schedule服务,每台服务都会去执行refresh定时任务方法

4.9.2 分布式锁
分布式锁:控制分布式系统有序的去对共享资源进行操作,通过互斥来保证数据的一致性。
4.9.3 redis分布式锁
sexnx (SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值
这种加锁的思路是,如果 key 不存在则为 key 设置 value,如果 key 已存在则 SETNX 命令不做任何操作
客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
客户端A执行代码完成,删除锁
客户端B在等待一段时间后再去请求设置key的值,设置成功
客户端B执行代码完成,删除锁
4.9.4 在工具类CacheService中添加方法
在heima-leadnews-common中添加方法
4.10 数据库同步到redis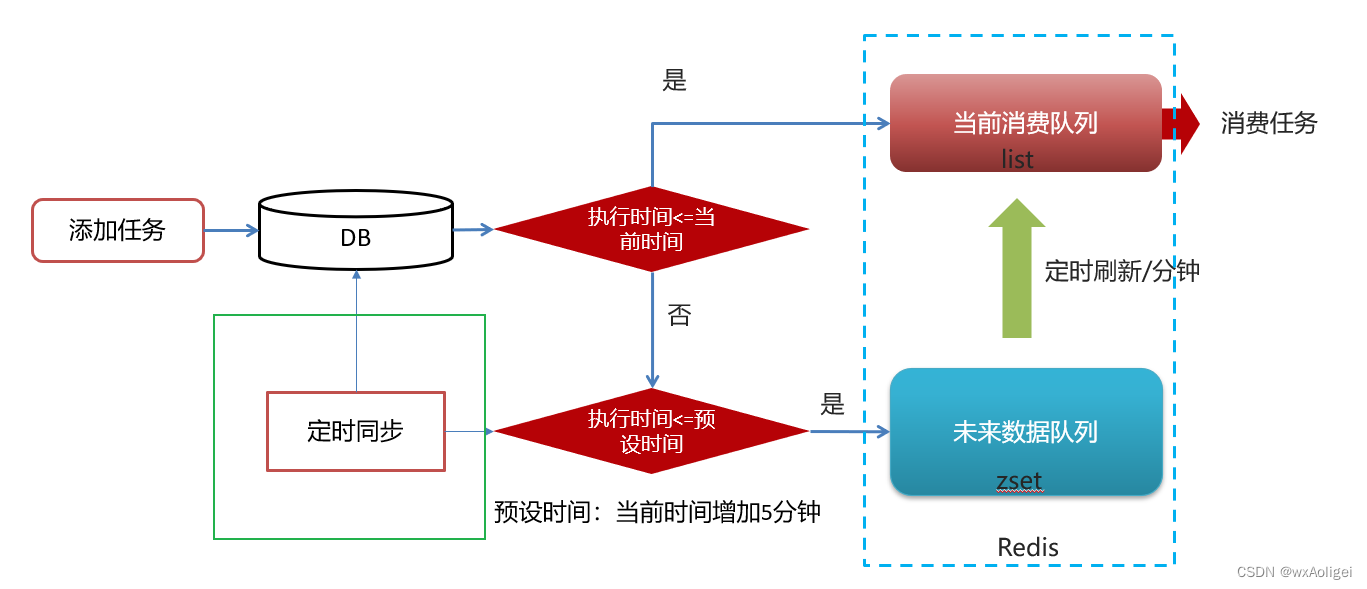
5.延迟队列解决精准时间发布文章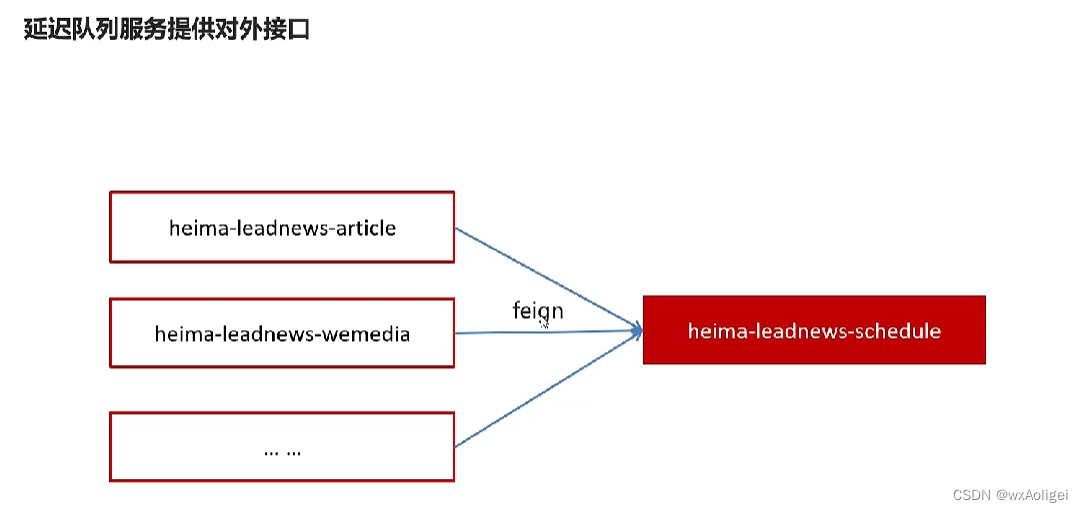
5.1 延迟队列服务提供对外接口
提供远程的feign接口,在heima-leadnews-feign-api编写类
注意这里的@FeignClient要与服务一致
在heima-leadnews-schedule微服务下提供对应的实现
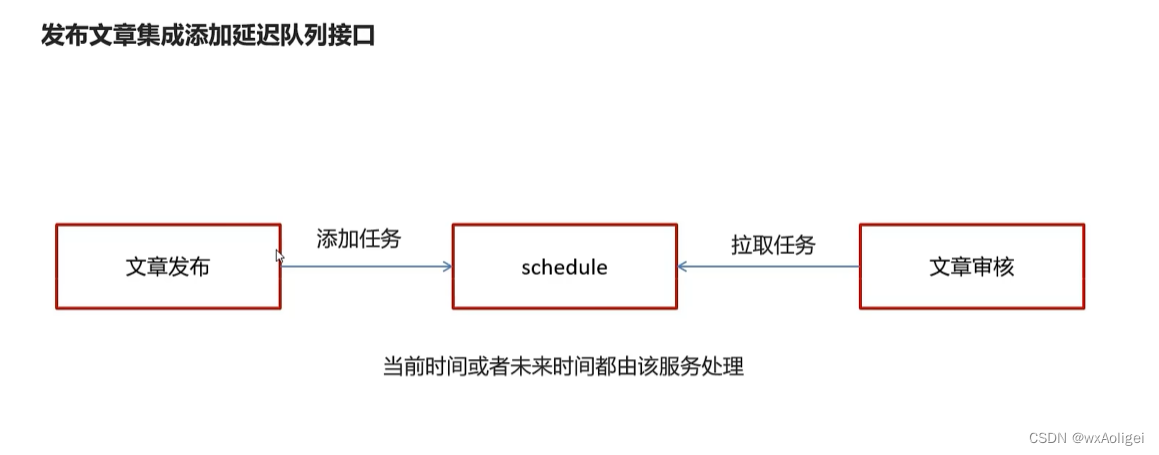
5.2 发布文章集成添加延迟队列接口
序列化工具对比
JdkSerialize:java内置的序列化能将实现了Serilazable接口的对象进行序列化和反序列化, ObjectOutputStream的writeObject()方法可序列化对象生成字节数组
Protostuff:google开源的protostuff采用更为紧凑的二进制数组,表现更加优异,然后使用protostuff的编译工具生成pojo类
拷贝资料中的两个类到heima-leadnews-utils下
可以发现protostuff花费的时间是很少的
修改发布文章代码:
把之前的异步调用修改为调用延迟任务
5.3 消费任务进行审核文章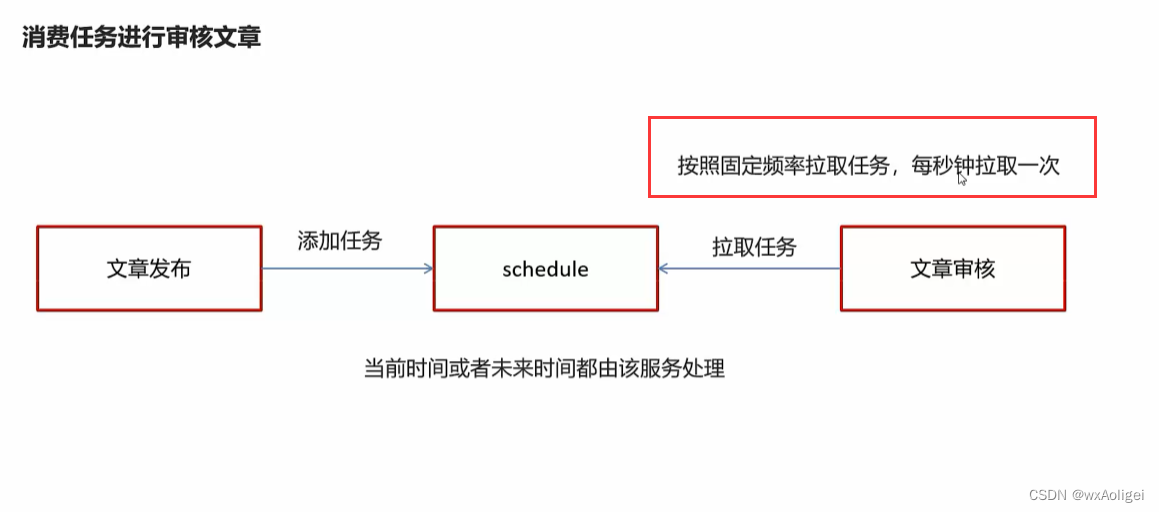
在WemediaApplication自媒体的引导类中添加开启任务调度注解@EnableScheduling
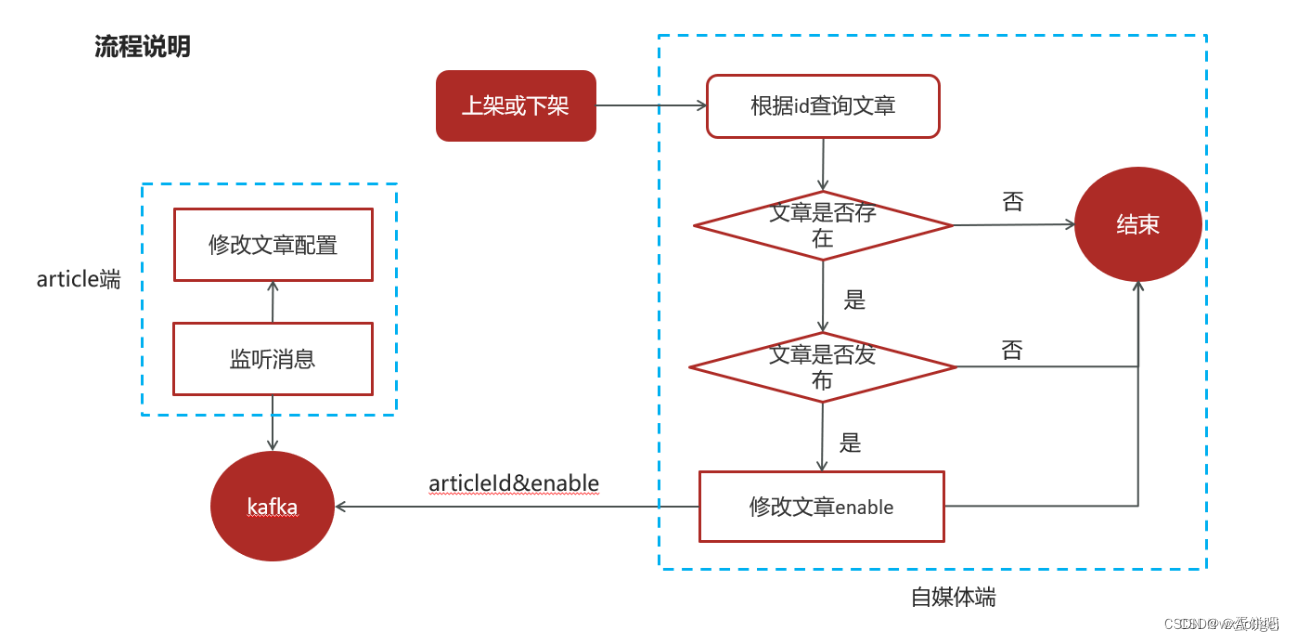
1自媒体文章上下架功能完成
已发表且已上架的文章可以下架
已发表且已下架的文章可以上架
流程说明
4、自媒体文章上下架-功能实现
1.接口定义
在heima-leadnews-wemedia工程下的WmNewsController新增方法
2.业务层编写
3.控制器
5、消息通知article端文章上下架
1.在heima-leadnews-common模块下导入kafka依赖
2.在自媒体端的nacos配置中心配置kafka的生产者
3.在自媒体端文章上下架后发送消息
4.在article端的nacos配置中心配置kafka的消费者
5.在article端编写监听,接收数据
6.修改ap_article_config表的数据
文章搜索-
1安装
拉取镜像 docker pull elasticsearch:7.7.0
安装ik分词器
2.添加文章索引库
1查询所有的文章信息,批量导入到es索引库中
3文章搜索功能实现
添加依赖
实现:1搜索接口定义search
4.文章自动审核构建索引
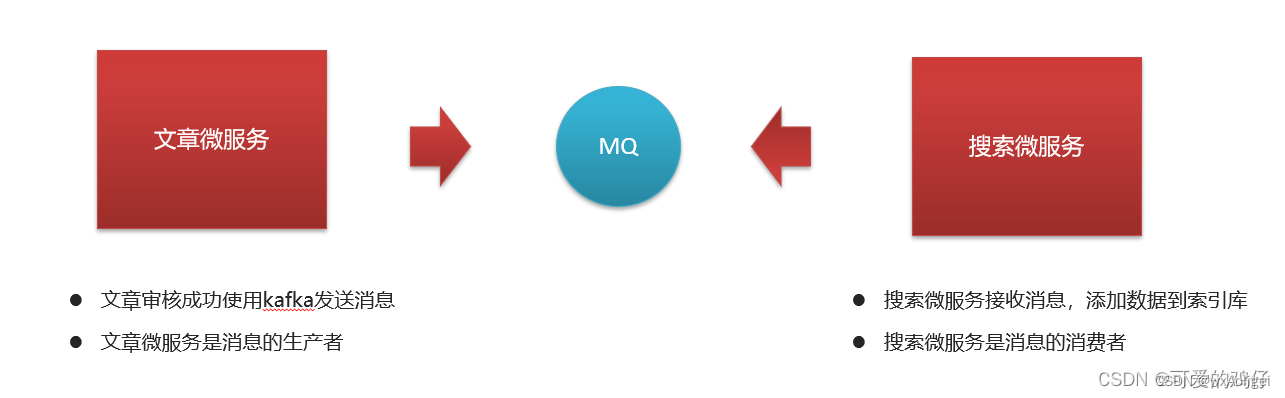
文章微服务发送消息
文章微服务集成kafka发送消息
定义监听接收消息,保存索引数据
5.保存用户搜索记录
展示用户的搜索记录10条,按照搜索关键词的时间倒序
可以删除搜索记录
保存历史记录,保存10条,多余的则删除最久的历史记录
用户的搜索记录,需要给每一个用户都保存一份,数据量较大,要求加载速度快,通常这样的数据存储到mongodb更合适,不建议直接存储到关系型数据库中
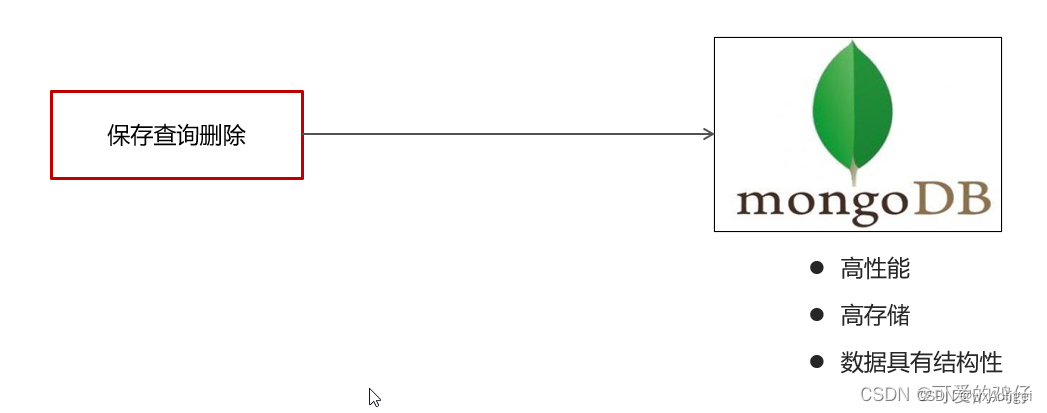
MongoDB安装及集成
保存搜索记录
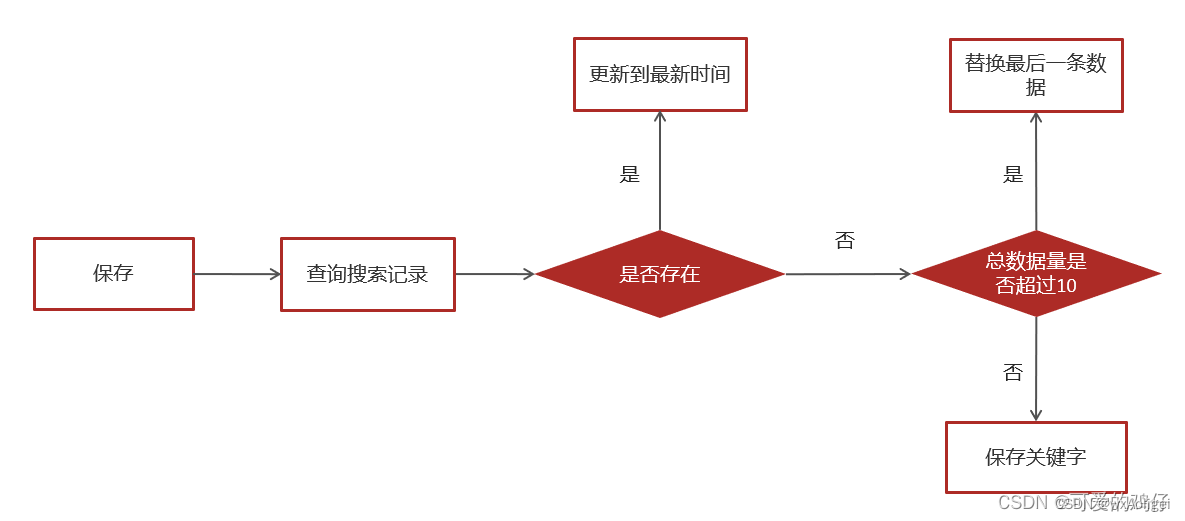
实现步骤
依赖
配置
创建ApUserSearchService新增insert方法
参考自媒体相关微服务,在搜索微服务中获取当前登录的用户
在ArticleSearchService的search方法中调用保存历史记录
保存历史记录中开启异步调用,添加注解@Async
在搜索微服务引导类上开启异步调用
6.查询用户搜素记录
要求:当点击搜索框时,获取用户的搜索记录:
在ApUserSearchService中新增方法findUserSearch()
控制器
七.删除用户搜索记录 delUserSearch
八.联想词搜索
搜索词-数据来源
通常是网上搜索频率比较高的一些词,通常在企业中有两部分来源:
第一:自己维护搜索词
通过分析用户搜索频率较高的词,按照排名作为搜索词
第二:第三方获取
关键词规划师(百度)、5118、爱站网
执行查询 模糊查询
用户在看文章时,应该是查询出来热点文章,而不是根据时间查询最新的文章,热点文章,也就是观看量,点赞量,评论数等,
目前实现的思路:从数据库直接按照发布时间倒序查询
问题1:
如何访问量较大,直接查询数据库,压力较大
问题2:
新发布的文章会展示在前面,并不是热点文章
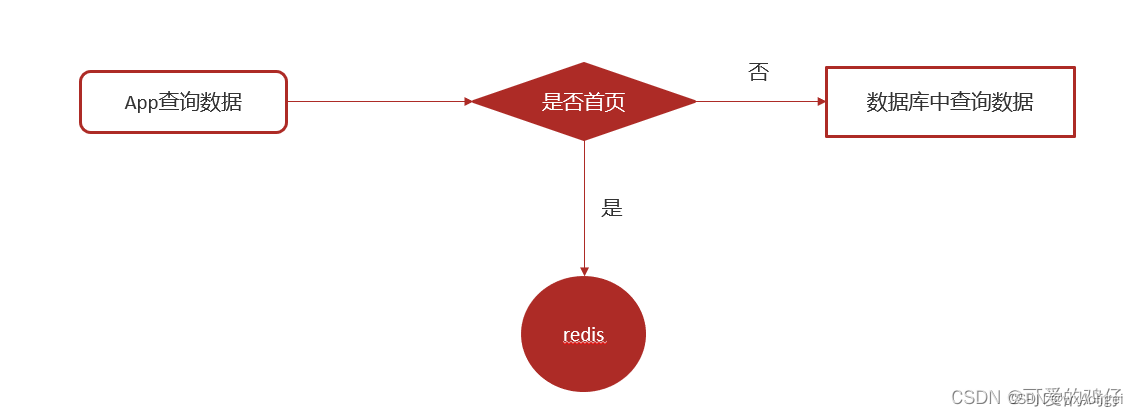
实现思路
把热点数据存入redis进行展示
判断文章是否是热点,有几项标准: 点赞数量,评论数量,阅读数量,收藏数量
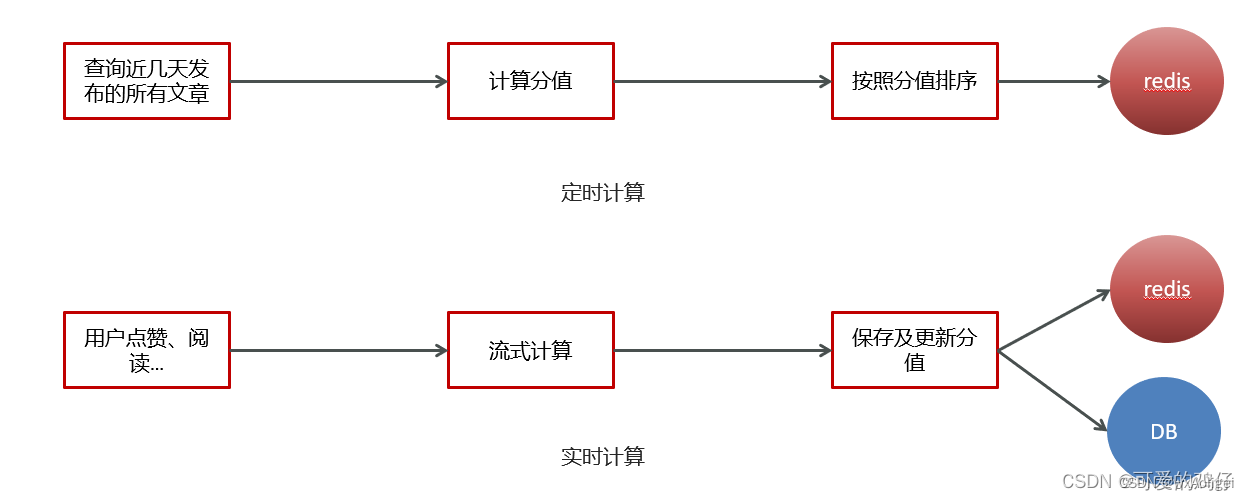
计算文章热度,有两种方案:
定时计算文章热度
实时计算文章热度
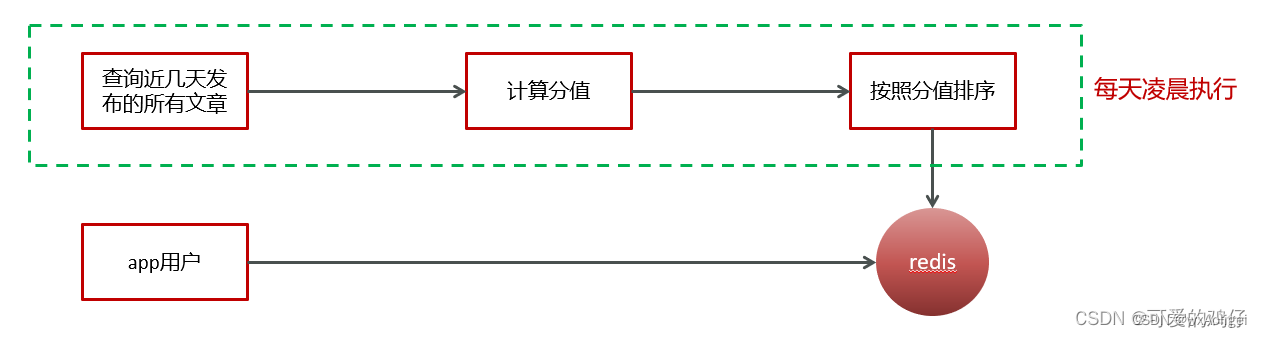
定时任务框架-xxljob
spring传统的定时任务@Scheduled,但是这样存在这一些问题 :
做集群任务的重复执行问题
cron表达式定义在代码之中,修改不方便
定时任务失败了,无法重试也没有统计
如果任务量过大,不能有效的分片执行
解决这些问题的方案为:
xxl-job 分布式任务调度框架
分布式任务调度
当前软件的架构已经开始向分布式架构转变,将单体结构拆分为若干服务,服务之间通过网络交互来完成业务处理。在分布式架构下,一个服务往往会部署多个实例来运行我们的业务,如果在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度。
1、并行任务调度
并行任务调度实现靠多线程,如果有大量任务需要调度,此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。如果将任务调度程序分布式部署,每个结点还可以部署为集群,这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行,来提高任务调度的处理效率。
2、高可用
若某一个实例宕机,不影响其他实例来执行任务。
3、弹性扩容
当集群中增加实例就可以提高并执行任务的处理效率。
4、任务管理与监测
对系统中存在的所有定时任务进行统一的管理及监测。让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
特性
简单灵活 提供Web页面对任务进行管理,管理系统支持用户管理、权限控制; 支持容器部署; 支持通过通用HTTP提供跨平台任务调度;
丰富的任务管理功能 支持页面对任务CRUD操作; 支持在页面编写脚本任务、命令行任务、Java代码任务并执行; 支持任务级联编排,父任务执行结束后触发子任务执行; 支持设置指定任务执行节点路由策略,包括轮询、随机、广播、故障转移、忙碌转移等; 支持Cron方式、任务依赖、调度中心API接口方式触发任务执行
高性能 任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰;
高可用 任务调度中心、任务执行节点均 集群部署,支持动态扩展、故障转移 支持任务配置路由故障转移策略,执行器节点不可用是自动转移到其他节点执行 支持任务超时控制、失败重试配置 支持任务处理阻塞策略:调度当任务执行节点忙碌时来不及执行任务的处理策略,包括:串行、抛弃、覆盖策略
易于监控运维 支持设置任务失败邮件告警,预留接口支持短信、钉钉告警; 支持实时查看任务执行运行数据统计图表、任务进度监控数据、任务完整执行日志;
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例;
如果mysql做主从,调度中心集群节点务必强制走主库;
热点文章-定时计算
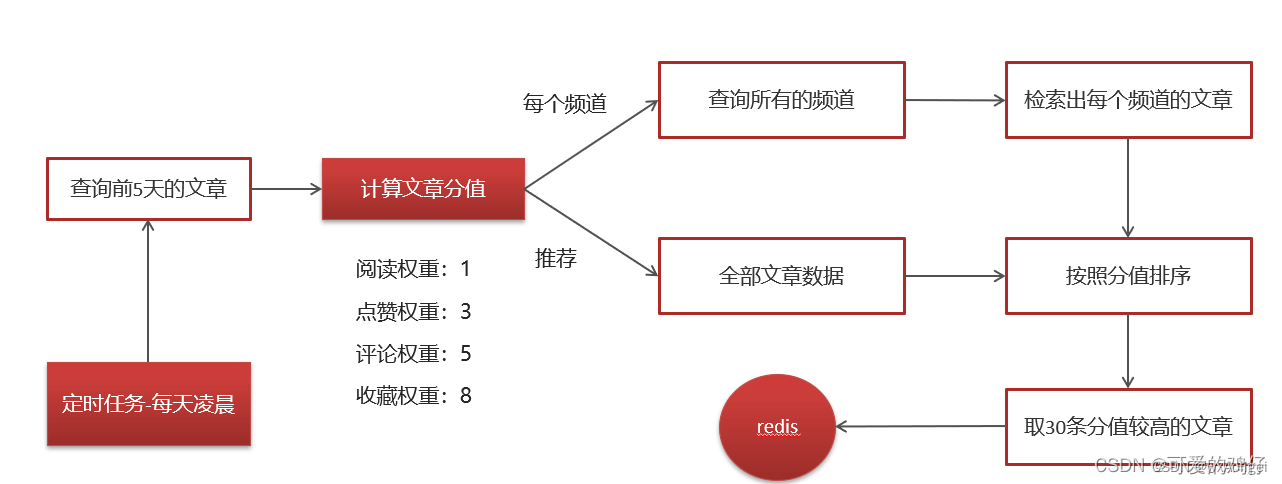
xxl-job定时计算-步骤
①:在heima-leadnews-article中的pom文件中新增依赖
② 在xxl-job-admin中新建执行器和任务。新建任务:路由策略为轮询,Cron表达式:0 0 2 * * ?
③ leadnews-article中集成xxl-job
XxlJobConfig、在nacos配置新增配置
④:在article微服务中新建任务类
四.查询文章接口改造
定时计算与实时计算
 kafkaStream
kafkaStream
什么是流式计算
kafkaStream概述
kafkaStream入门案例
Springboot集成kafkaStream
实时计算
用户行为发送消息
kafkaStream聚合处理消息
更新文章行为数量
替换热点文章数据
实时流式计算
1.概念
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。
- 应用场景
日志分析
网站的用户访问日志进行实时的分析,计算访问量,用户画像,留存率等等,实时的进行数据分析,帮助企业进行决策
大屏看板统计
可以实时的查看网站注册数量,订单数量,购买数量,金额等。
公交实时数据
可以随时更新公交车方位,计算多久到达站牌等
实时文章分值计算
头条类文章的分值计算,通过用户的行为实时文章的分值,分值越高就越被推荐。
技术方案选型
Hadoop
Apche Storm
Storm 是一个分布式实时大数据处理系统,可以帮助我们方便地处理海量数据,具有高可靠、高容错、高扩展的特点。是流式框架,有很高的数据吞吐能力。
Kafka Stream
可以轻松地将其嵌入任何Java应用程序中,并与用户为其流应用程序所拥有的任何现有打包,部署和操作工具集成
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点如下:
Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
除了Kafka外,无任何外部依赖
充分利用Kafka分区机制实现水平扩展和顺序性保证
通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
支持正好一次处理语义
提供记录级的处理能力,从而实现毫秒级的低延迟
支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
Kafka Streams的关键概念
源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
app端热点文章计算

功能实现
用户行为(阅读量,评论,点赞,收藏)发送消息,以阅读和点赞为例
①在heima-leadnews-behavior微服务中集成kafka生产者配置
修改nacos,新增内容
②修改ApLikesBehaviorServiceImpl新增发送消息
定义消息发送封装类:UpdateArticleMess
③修改阅读行为的类ApReadBehaviorServiceImpl发送消息
3,使用kafkaStream实时接收消息,聚合内容
①在leadnews-article微服务中集成kafkaStream (参考kafka-demo)
②定义实体类,用于聚合之后的分值封装
③ 定义stream,接收消息并聚合
4.重新计算文章的分值,更新到数据库和缓存中
①在ApArticleService添加方法,用于更新数据库中的文章分值
②定义监听,接收聚合之后的数据,文章的分值重新进行计算















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









