







mariadb是mysql数据库的开源分支,在不细究差别的情况下,你完全可以当成mysql来看。
spider引擎是一个内置的支持数据分片特性的存储引擎,支持分区和XA事务,该引擎可以在服务器上建立和远程服务器表之间的链接,操作起来就像操作本地的表一样。并且后端可以是任何的存储引擎。spider引擎根据表的设置的规则以及server表的规则自动进行智能路由,实现对后端数据库不通的表或者数据分片的访问和修改。因此该引擎对业务是完全透明的。目前spider引擎已经集成到了MariaDB中,安装使用非常方面。
总结:
优点:
1.spider引擎对业务层不干涉,这意味着如果你要做数据分布式存储,完全可以做到不改动一行代码。
2.spider从mariadb10开始被集成到了mariadb安装包中,作为mariadb默认的分布式存储引擎,且安装简便。
3.方便横向扩展,能解决单台mysql得性能和存储瓶颈问题
4.对后端的存储引擎没有限制
缺点:
1.spider的容灾机制不完善。需要自己想办法做容灾机制,具体体现在:1):spider的server端不储存实际数据,如果后端数据库的一台宕机了,spider的server端也使用不了了。 2):由于spider不实际存储数据,所以数据备份要到实际存储数据的后端服务器上备份.
2.spider的表本身不支持查询缓存和全文索引,不过可以将全文索引添加在后端数据库中。

如图,图的左侧是没没有部署spider的场景,通常我们的项目直接连接数据库。右侧为部署了spider的场景,项目直连的变成了spider server ,再由spider server 去转发到 实际存储数据的 mariadb ,所以这就是前文说的spider 是不实际存储数据的,这里有点类似nginx web 转发的场景。对于代码层面来说,甚至连接数据库的连接串都不用改变。
1、spider的部署
spider的安装文件在mariadb安装目录下的share文件夹中(我这里的安装方式是使用mariadb源码编译后安装,mariadb的版本是10.2.8)

登录数据库后执行
source /xxx/xxx/xxx/install_spider.sql;


query ok 没有错误就说明spider已经安装好了
如果不放心的话,可以使用下列sql语句查看spider是否安装成功
select engine , support , transactions , xa from information_schema.engines;

查询结构如上图所示,表示spider已开启
注意:只需要在充当spider server的mariadb上开启spider就行了,实际存储数据的mariadb可以不用开启spider。
2、实战演示
我这里有三台mariadb的数据库服务器。
192.168.31.104 作为 spider server ,项目需要连接的就是它。
192.168.31.224 作为后端数据库,这里称它为db1。实际存储数据的就是它
192.168.31.226 作为后端数据库,这里称它为db2。实际存储数据的就是它
场景一:垂直拆分
1.table1表的数据存到 db1(192.168.31.224) 的test1 库中,
2.table2表的数据存到db2(192.168.31.226)中的test1库中
在spider server(192.168.31.104)上建立后端db的连接,实际就是在mysql.servers表中插入记录
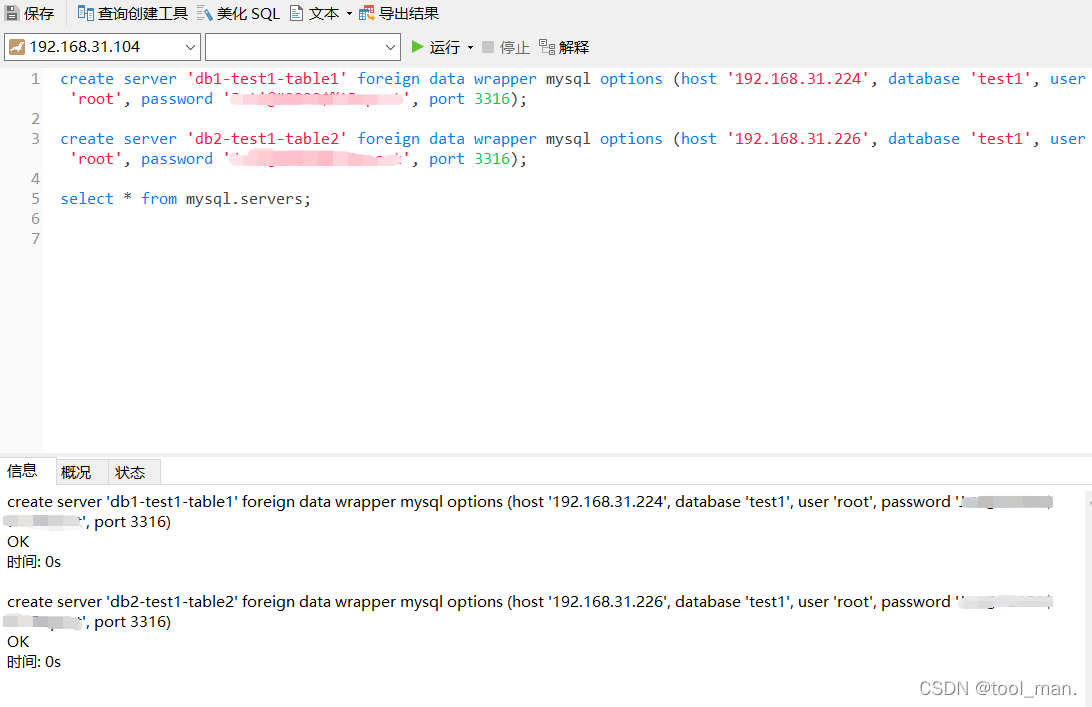
create server 'db1-test1-table1' foreign data wrapper mysql options (host '192.168.31.224', database 'test1', user 'root', password 'xxxxxx', port 3316);
create server 'db2-test1-table2' foreign data wrapper mysql options (host '192.168.31.226', database 'test1', user 'root', password 'xxxxxx', port 3316);
server 'test1-table1'
后端db的server名字,可以随便取,我这里为了好区分用的是db名-库名-表名(db1-test1-table1),你可以直接叫db1或db2或zhangsan什么的
host '192.168.31.224'
后端数据库的IP
database 'test1'
后端数据库对应的库
user 'root', password 'xxxxxx'
后端数据库对应的账号密码,我这里直接用了root,也可以在db上专门建一个用户用于spider server 的访问,当然别忘了给用户授权
port 3316
后端数据库的端口号
查询:
select * from mysql.servers;

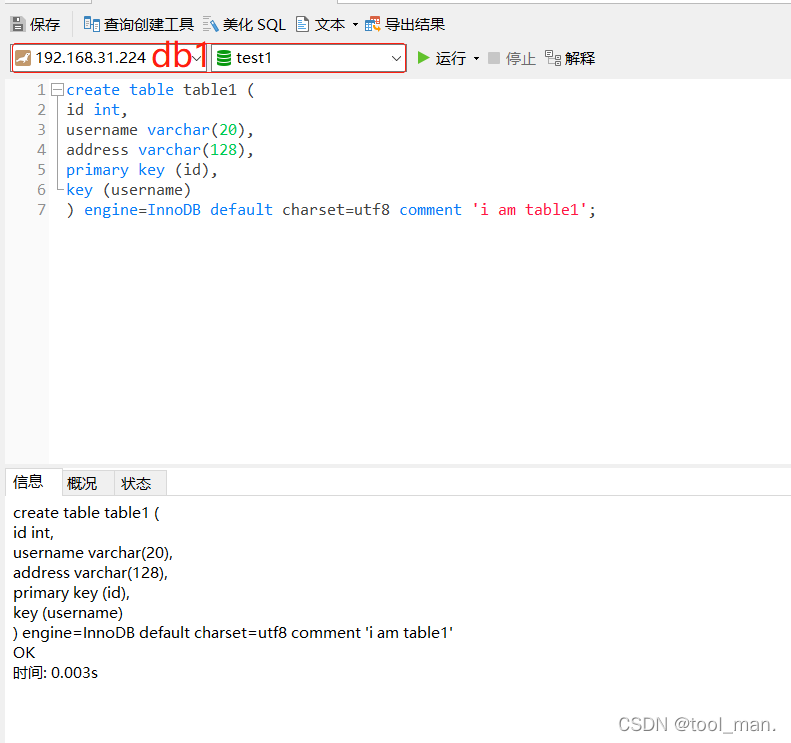
1.在后端db1中test1库中建立table1的表,这个表是实际存储数据的表,然后在spider server上的test1库中建立table1的关联表,通过建表语句中的注释指定此表会连接db1上的表
1.在后端db1上建立table1表
create table table1 (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) engine=InnoDB default charset=utf8 comment 'i am table1';
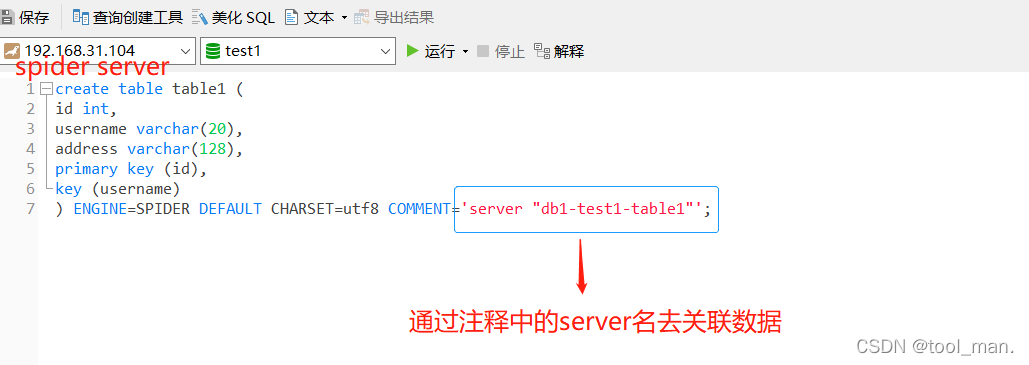
2.在spider server上建立关联表
create table table1 (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='server "db1-test1-table1"';
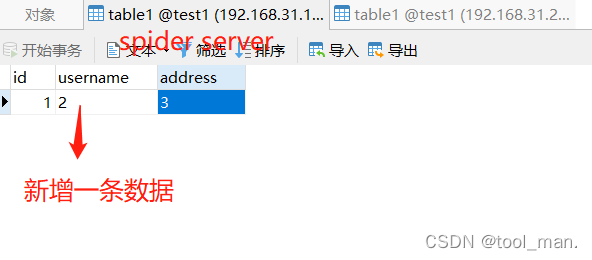
3.测试
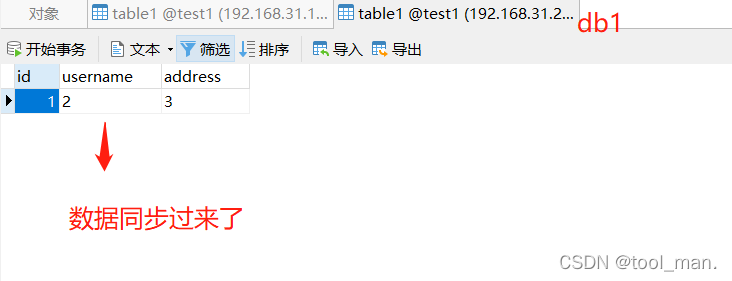
2.在后端db2中test1库中建立table2的表,这个表是实际存储数据的表,然后在spider server上的test1库中建立table2的关联表,通过建表语句中的注释指定此表会连接db2上的表
这个操作是一样的就不继续了…
场景二:水平拆分
水平拆分可以按hash、range、list等方式进行数据分片。
spider server和db分别需要使用的库和表:
spider server 使用test2库 tableHash表
db1 使用test2库 tableHash表
db2 使用test2库 tableHash表
1.第一步先查询mysql.servers表,如果已经存在后端db对应库的连接串,那么就不需要创建新的连接串,否则则要创建
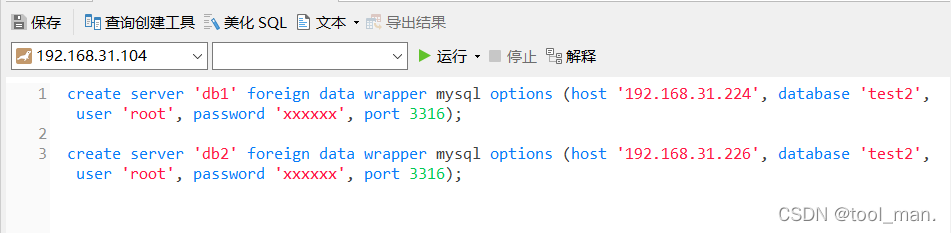
2.分别在后端db创建表
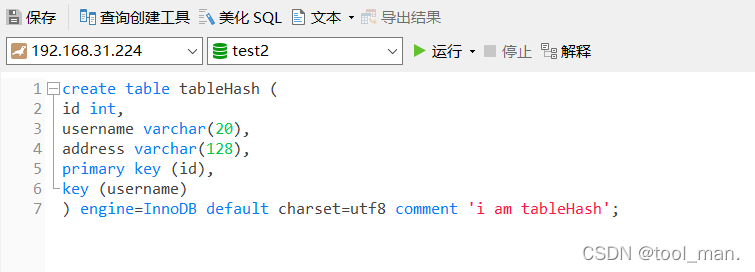
 3.在spider server中创建关联表
3.在spider server中创建关联表
create table tableHash (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", table "tableHash"'
PARTITION BY HASH(id)
( PARTITION pt1 COMMENT = 'server "db1"',
PARTITION pt2 COMMENT = 'server "db2"') ;
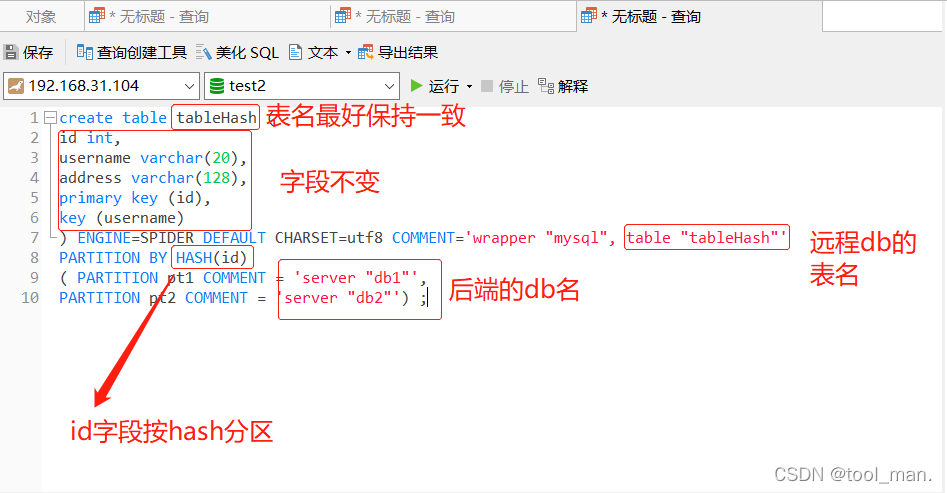
说明:上方建表语句的作用是,建立一张名为tableHash的表,使用了spider引擎,关联远程db1,db2上的test2库中的tableHash表。表中的数据会按hash分片。
测试
spider server写10条数据
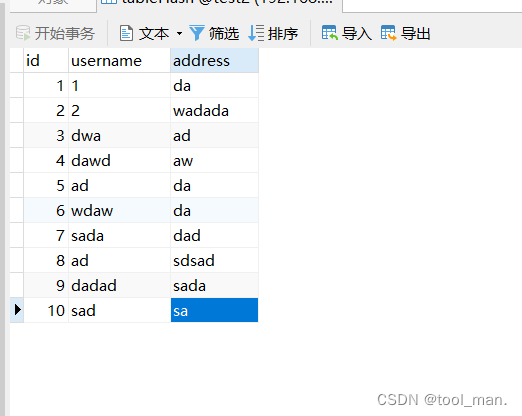
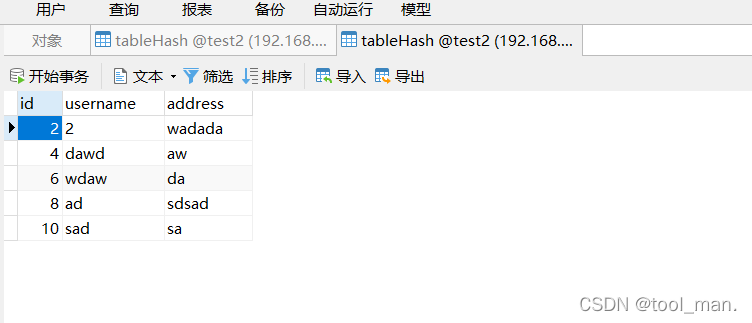
db1查看
db2查看
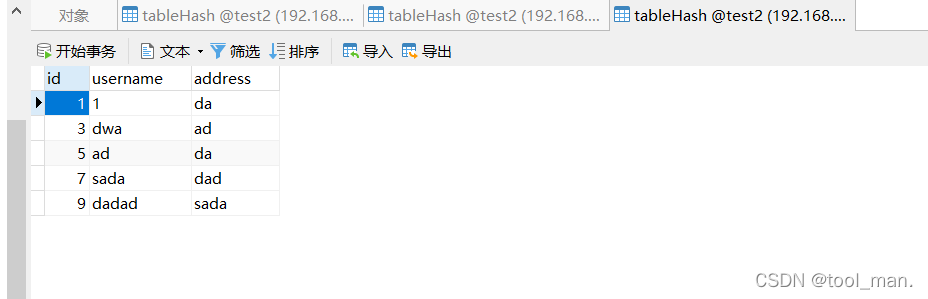
每个db分别存了5条数据
下面是range、list 分区的建表语句
range: 表名是tableRange ,db上得先建,下面的是spider server需要建的
create table tableRange (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", table "tableRange "'
PARTITION BY range columns (id)
( PARTITION pt1 values less than (100000) COMMENT = 'server "db1"',
PARTITION pt2 values less than (200000) COMMENT = 'server "db2"') ;
list: 表名是tableList ,db上得先建,下面的是spider server需要建的
create table tableList (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", table "tableList "'
PARTITION BY list columns (id)
( PARTITION pt1 values in (1,3,5,7,9) COMMENT = 'server "db1"',
PARTITION pt2 values in (2,4,6,8,10) COMMENT = 'server "db2"') ;
综上,使用spider垂直拆分和横向拆分就完成了。















 2285
2285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









