







用自然语言处理做金融领域的大模型,数据是第一要素。
这里我们介绍用python爬取巨潮资讯网所有股票的年度报告数据
巨潮资讯网的网址:巨潮资讯网官网
首先分析下巨潮资讯网的网页结构,在谷歌浏览器打开巨潮资讯网官网,右键,然后选择检查:
巨潮资讯网的主要按钮是这个查询 的按钮,我们可以在代码、标题关键字等方面输入我们需要查询的数据,点击查询 按钮提交之后发现在Network 里面出现一个query的请求。
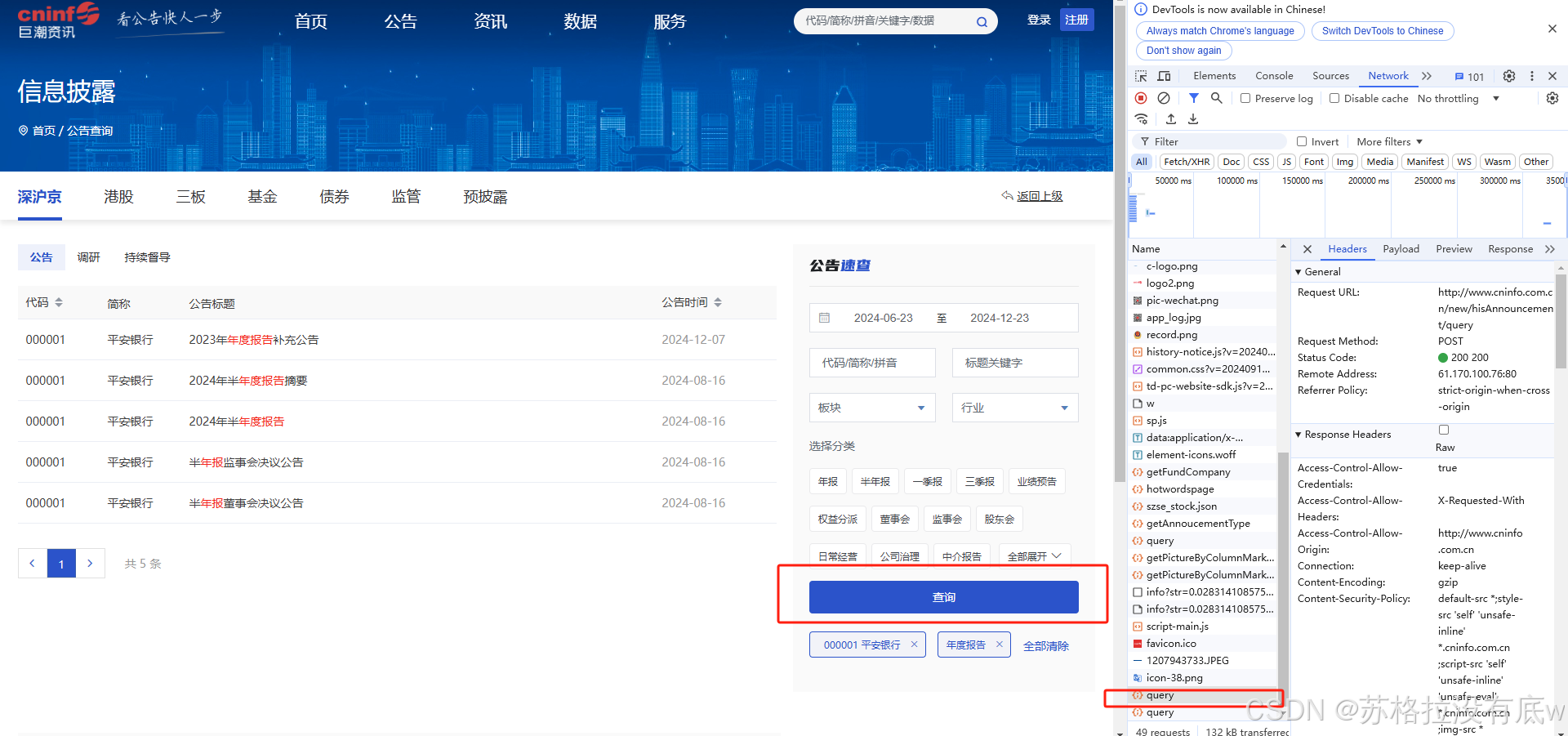
1.复制头文件:选择Network, 点击刚刚的query,选择Headers,复制User-Agent字段,这个可以让我们的代码模拟浏览器向巨潮资讯网的服务器。
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36”,
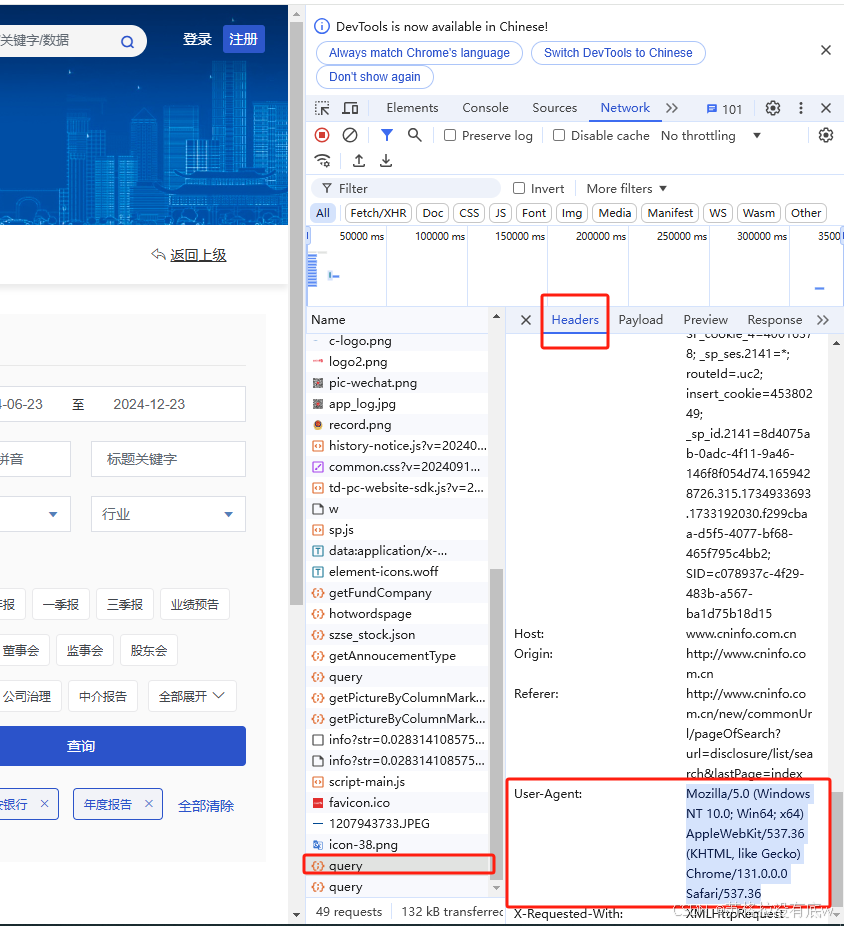
2.分析请求的参数数据:
点击这个Payload获取我们请求的参数,主要的参数如下所示
“pageNum”: “1”, # 第几页
“pageSize”: “30”, # 只能固定30
“column”: “szse”, #
“tabName”: “fulltext”, # 公告fulltext, 调研relation, 持续督导supervise
“plate”: “shkcp”, # 板块:深圳主板szmb, 创业板szcy, 沪主板shmb, 上海科创板shkcp
“stock”: “”, # 股票代码
“searchkey”: “”, # 标题关键字
“secid”: “”,
“category”: “category_ndbg_szsh”, # 选择分类:年报、三季报等
“trade”: “”, # 行业
“seDate”: “2023-11-30~2024-05-30”,
“sortName”: “code”, # 排序id
“sortType”: “desc”, # 排序方式 asc, desc
“isHLtitle”: “true”
把参数拼接到url里获得的url:
http://www.cninfo.com.cn/new/hisAnnouncement/query?pageNum=1&pageSize=30&column=szse&tabName=fulltext&plate=&stock=605358,9900038308&searchkey=年度报告&secid=&category=category_ndbg_szsh&trade=&seDate=2021-11-26~2024-11-25&sortName=code&sortType=asc&isHLtitle=true&
用post方式请求数据:
response = requests.post(url_code, headers=headers).json()
发现可以获取数据,也就是基本成功了。
返回的数据:
{‘classifiedAnnouncements’: None, ‘totalSecurities’: 0, ‘totalAnnouncement’: 6, ‘totalRecordNum’: 6, ‘announcements’: [{‘id’: None, ‘secCode’: ‘605358’, ‘secName’: ‘立昂微’, ‘orgId’: ‘9900038308’, ‘announcementId’: ‘1216518080’, ‘announcementTitle’: ‘立昂微2022年年度报告摘要’, ‘announcementTime’: 1682092800000, ‘adjunctUrl’: ‘finalpage/2023-04-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











