






链接: 巨潮资讯网
最近接到一个需求,需要爬取上市公司近三年的年度报告,记录一下
1.初识请求与postman
页面如下
巨潮资讯网
首先需要明白这个网页是get和post请求,F12打开浏览器的开发者指令,点击右上角的网络(红色框框的地方)
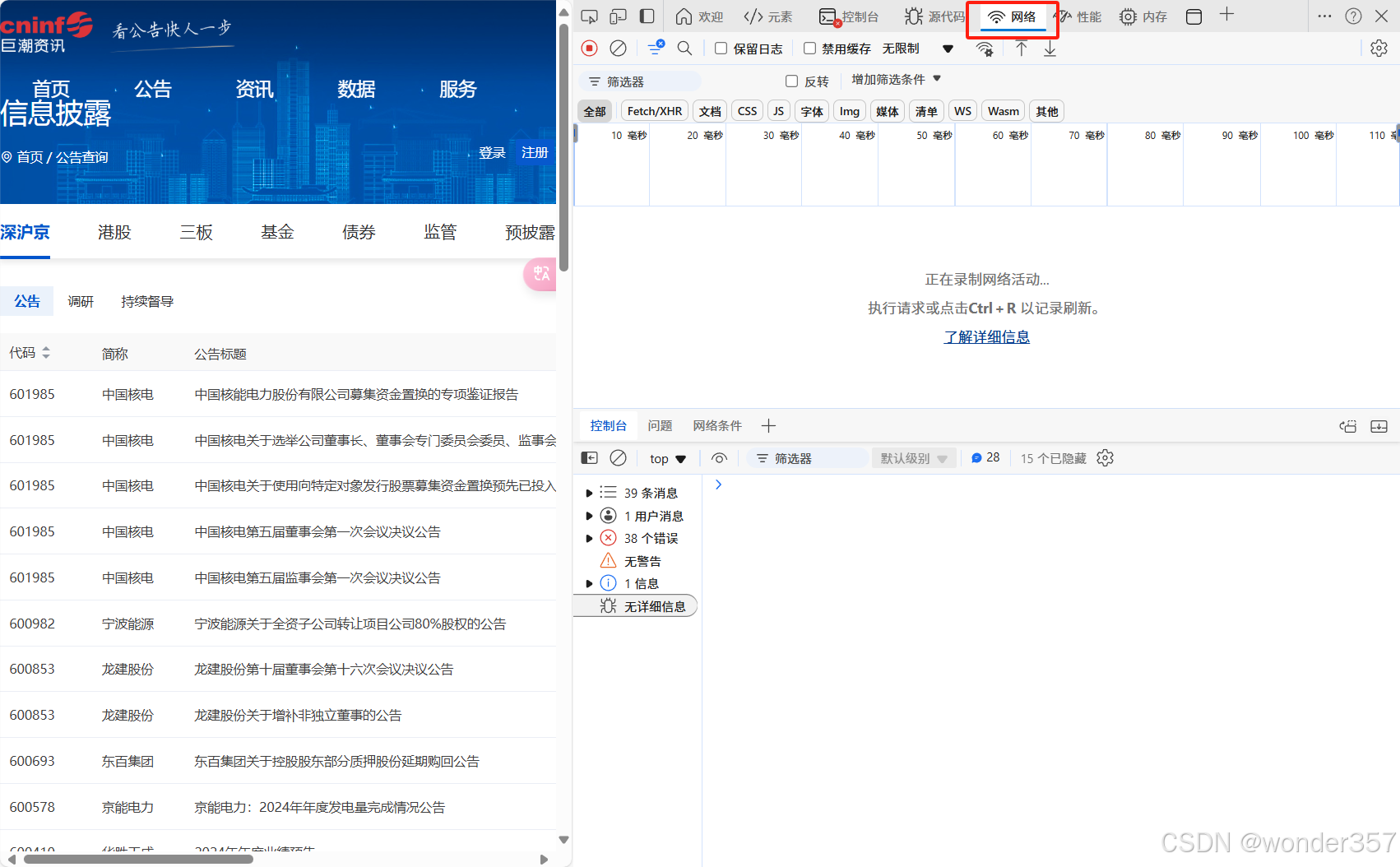
这时我们在左边点击翻页按钮,会发现出现了一个query请求,点击query可以查看请求url和 Request Method 。
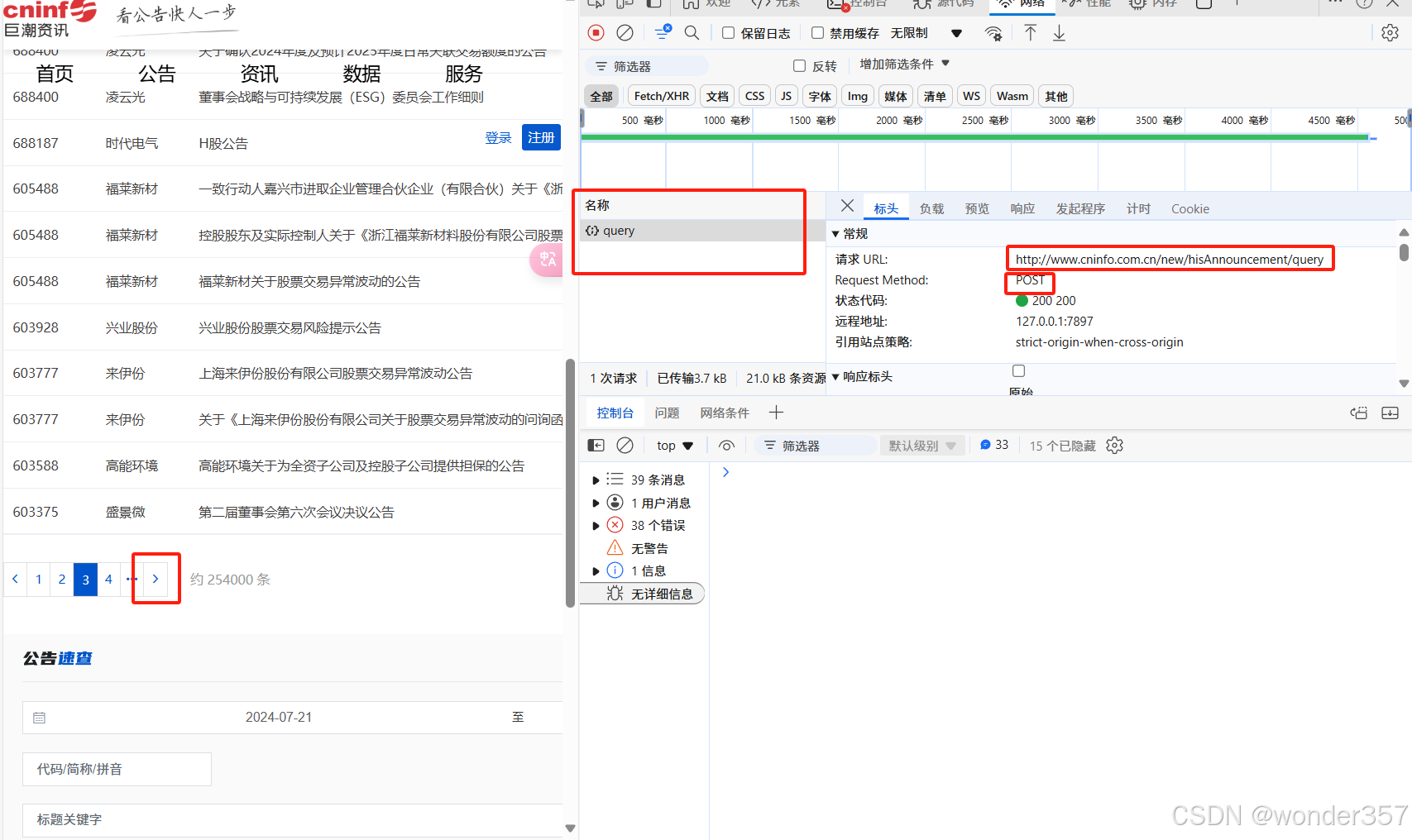
可以看到它是属于post请求,请求url是 http://www.cninfo.com.cn/new/hisAnnouncement/query
这时我们在浏览器另一个页面打开postman
巨潮资讯网
点击左边的 New Request
会进入如下这样一个页面
这时我们填入请求url: http://www.cninfo.com.cn/new/hisAnnouncement/query
并切换为post
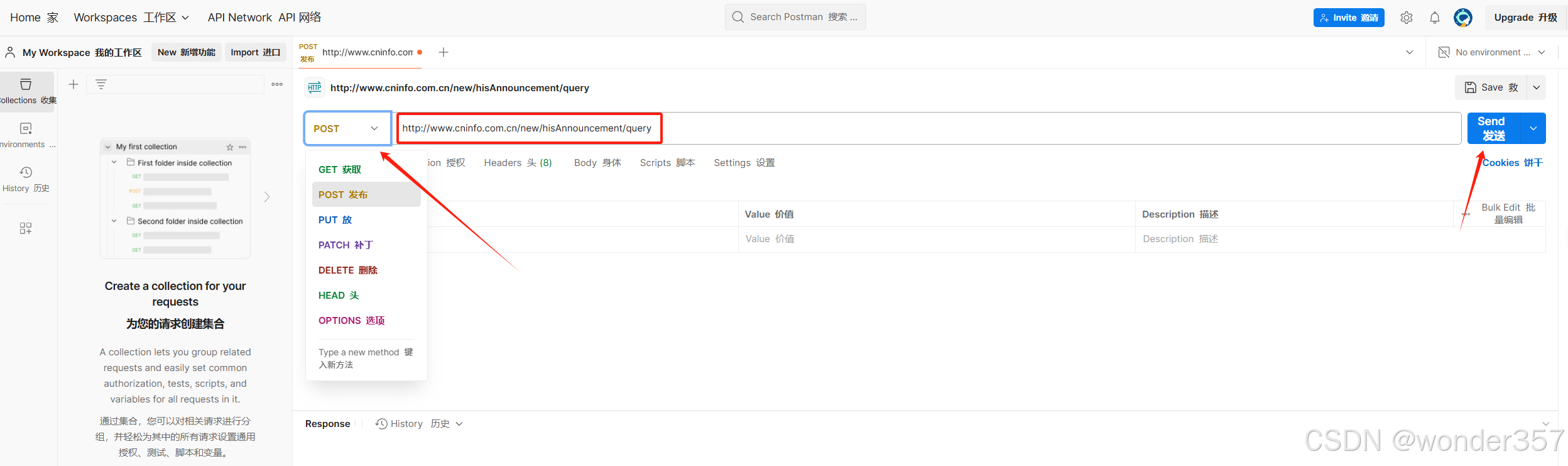
点击send会发到我们的请求结果
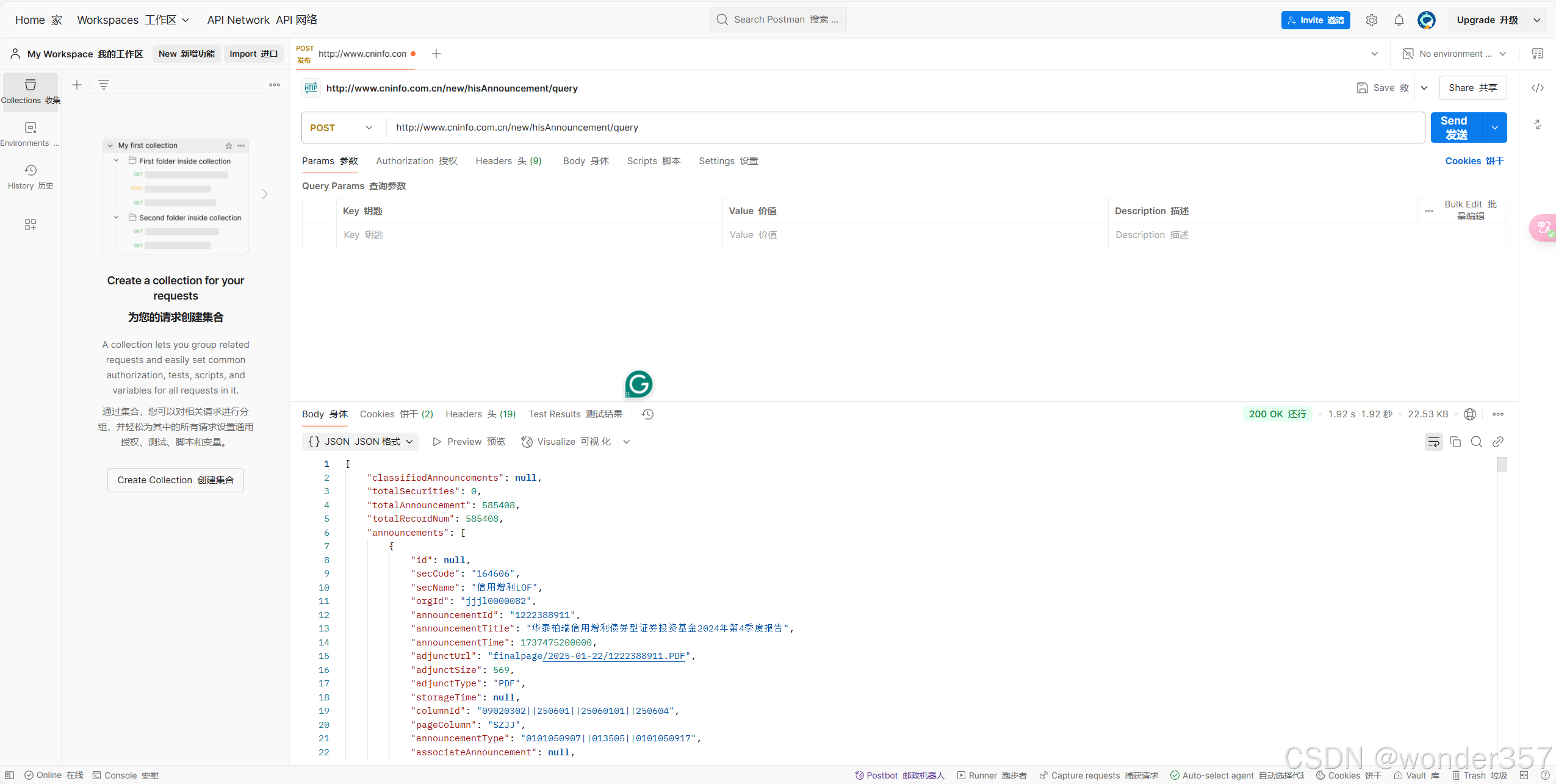
这里可以看到我们已经能够得到请求结果了
2.请求参数
由于我们想要按照时间来爬取内容
def get_page(page, day):
"""
获取请求参数数据-分类搜索-年报
:param page: 页码
:param day: 日期
:return:
"""
parameter = {
"pageNum": str(page),
"pageSize": SysConfig.PAGE_SIZE,
"tabName": "fulltext",
"column": "szse", # 深沪京-顶部类型
"stock": "",
"searchkey": "",
"secid": "",
"plate": "", # 板块
"category": "category_ndbg_szsh;category_bndbg_szsh;category_yjdbg_szsh;category_sjdbg_szsh", # 分类
"trade": "",
"seDate": day + "~" + day,
"sortName": "time",
"sortType": "desc",
"isHLtitle": "true"
}
return parameter
data = self.get_parameter_data_by_annual_report(page, day) # 获取列表页面信息
page_text = RequestUtil.method_post(SysConfig.TARGET_URL, data=data, proxy_select=0).text
这里的page_text就是我们想要的网页爬取的内容
try:
# 解析文字
text = json.loads(page_text)
# 总条数
total_record_num = text['totalRecordNum']
# 总页面数
total_page = int(total_record_num / SysConfig.PAGE_SIZE) + 1
LogUtil.log_json(describe="->爬取详情", kwargs={"日期:": day, "当前页:": page, "总页数:": total_page})
# 解析字段
if 'announcements' in text and text['announcements']:
count = 0
for announcement in text['announcements']:
try:
# 下载地址
pdf_url = SysConfig.SITE_URL + announcement['adjunctUrl']
return pdf_url
def download_pdf(announcement, pdf_url):
try:
LogUtil.log_json("下载pdf", kwargs={"下载地址:": pdf_url})
time_array = time.localtime(int(str(announcement['announcementTime'])[:-3]))
time_day_format = time.strftime("%Y-%m-%d", time_array)
file_id = str(announcement['announcementTime']) + str(announcement["announcementId"])
pdf_path = SysConfig.PDF_SAVE_PATH + time_day_format
file_path = pdf_path + "/" + file_id + ".pdf"
# 最多重试3次
for i in range(3):
response = RequestUtil.method_get(pdf_url, proxy_select=0)
flag = Crawler.save_pdf(response.content, file_path, pdf_path)
if response.status_code != 200 or not flag:
time.sleep(3)
LogUtil.log_json("重试...", kwargs={"下载地址:": pdf_url, "存储路径:": file_path})
else:
break
LogUtil.log_json("下载成功", kwargs={"下载地址:": pdf_url, "存储路径:": file_path})
return file_path
except (Exception, RuntimeError) as e:
LogUtil.logger.error("pdf下载出现异常: {0}".format(str(traceback.format_exc())))
return None
在下载端加了一个重试的代码,设定需要爬取的时间和页数就好啦

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









