







 本文介绍了使用Python进行网购平台比价系统的设计,包括网络爬虫技术(requests和selenium)、UI设计(tkinter)和数据库设计。通过面向对象设计,实现了商品信息爬取、商品比价和关注列表管理等功能。
本文介绍了使用Python进行网购平台比价系统的设计,包括网络爬虫技术(requests和selenium)、UI设计(tkinter)和数据库设计。通过面向对象设计,实现了商品信息爬取、商品比价和关注列表管理等功能。
Python课程设计实战–网购平台比价系统
文章目录
一、前言
由于这篇博客是本人的开山之作。所以难免存在很多的问题,格式也有可能不是很标准,如果给读者带来了困扰还请谅解,我会慢慢提升自己的写作能力。本项目的所有代码及配置说明都发在CSDN里了,有需要的可以自己下载。点击这里
1.1 背景
近几年来网络购物越来越流行,基本上每个人都有过网购经历,本着“货比三家”的原则,我们往往倾向于对商品进行大量的比较。然而不同的网购平台其商品也不尽相通,而跨网站的比较又着实比较麻烦,因此就有了做一个快捷的网购平台比价系统的想法,实现在一个界面内实现多网购平台商品的比价操作。
其实很早就萌生了做这个程序的念头,但是一直都觉得实现起来比较麻烦所以就鸽了,但是由于在做学校的Python课设时没有好的想法,就还是把这个给提了出来,真正实现之后发现也并不是很难。
1.2 用到的技术简述
既然是比价系统,就肯定要实现数据的获取,那么就难免需要网络爬虫技术、数据库技术以及简单的UI设计。
1.2.1 网络爬虫技术
我们用到的是requests+selenium的方法进行爬虫,其实简单的爬虫用不到selenium,requests就足够了,但是有些网站不是静态加载的,我们用requests就获取不到数据,因此这里也用一下selenium,以便于进行扩展。
requests:可以直接利用get方法获取目标页面的HTML文本,使用起来十分简单。
selenium:可以实现模拟操作,其操作可以做到与手动一样,从而获取页面的文本(手动操作即在页面上右键->查看源代码从而获取HTML文本),虽然可能会有点慢,但是可以很好的绕过网站的反爬虫程序。
既然已经获取到了HTML文本,那么就肯定需要进行解析,从而获取到我们想要的数据。常用的解析方法是BeautifulSoup和正则表达式re。
BeautifulSoup:利用HTML中的标签进行查找,在查找目标数据时需要观察目标数据在哪个Tag下,可以利用父Tag到子Tag的方式逐级查找,或者利用目标数据所在Tag的位置进行查找(这个方法风险比较大,网页源码稍有改动就有可能完蛋)。例如以下HTML(只是做个示例,没有详细学过HTML,可能会写错还请勿喷):
<tag1>
<title> a </title>
</tag1>
<tag2>
<title> b </title>
</tag2>
<tag3>
<title> c </title>
</tag3>
比如我们想要获取tag2下的title(即b),我们可以先查找tag1,然后查找title,然后获取title中的内容;也可以直接查所有的title,在返回的列表中选择第二个,之后获取其下的内容。
正则表达式re:具体语法就不讲了,比较麻烦,不懂的可以自己查一下,这里给一个连接:正则表达式–菜鸟教程,学起来还是比较快的,值得一提的是,在HTML中利用正则表达式时往往需要进行最短匹配(默认的匹配是贪婪匹配),这就需要我们利用好“?”这个符号。以上面的例子为例,我们可以利用正则表达式<//tag1>.* ?<title>.*?<//title>来获取目标字符串,然后利用正则表达式<title>.*?<//title>从该字符串中扣出来仅包含目标数据的字符串,从而可以利用下标来获取指定数据,比如此处我们可以选择第8—(-8)个字符来获取目标数据“b”(-8代表倒数第8),为了防止出现错误,在每次的匹配任意多个字符的时候最好都加上"?"。
1.2.2 UI设计
我们用到的是Python中的tkinter第三方库,可以很容易的实现简单的UI设计。涉及到的操作就是控件的布局、鼠标点击的响应事件、控件中数据的获取,都是一些比较简单的操作。这里简单放一下我设计的结果(设计的比较简陋,因为俺也是现学的这东西,不是很懂那些高级控件),具体操作我们后面说。
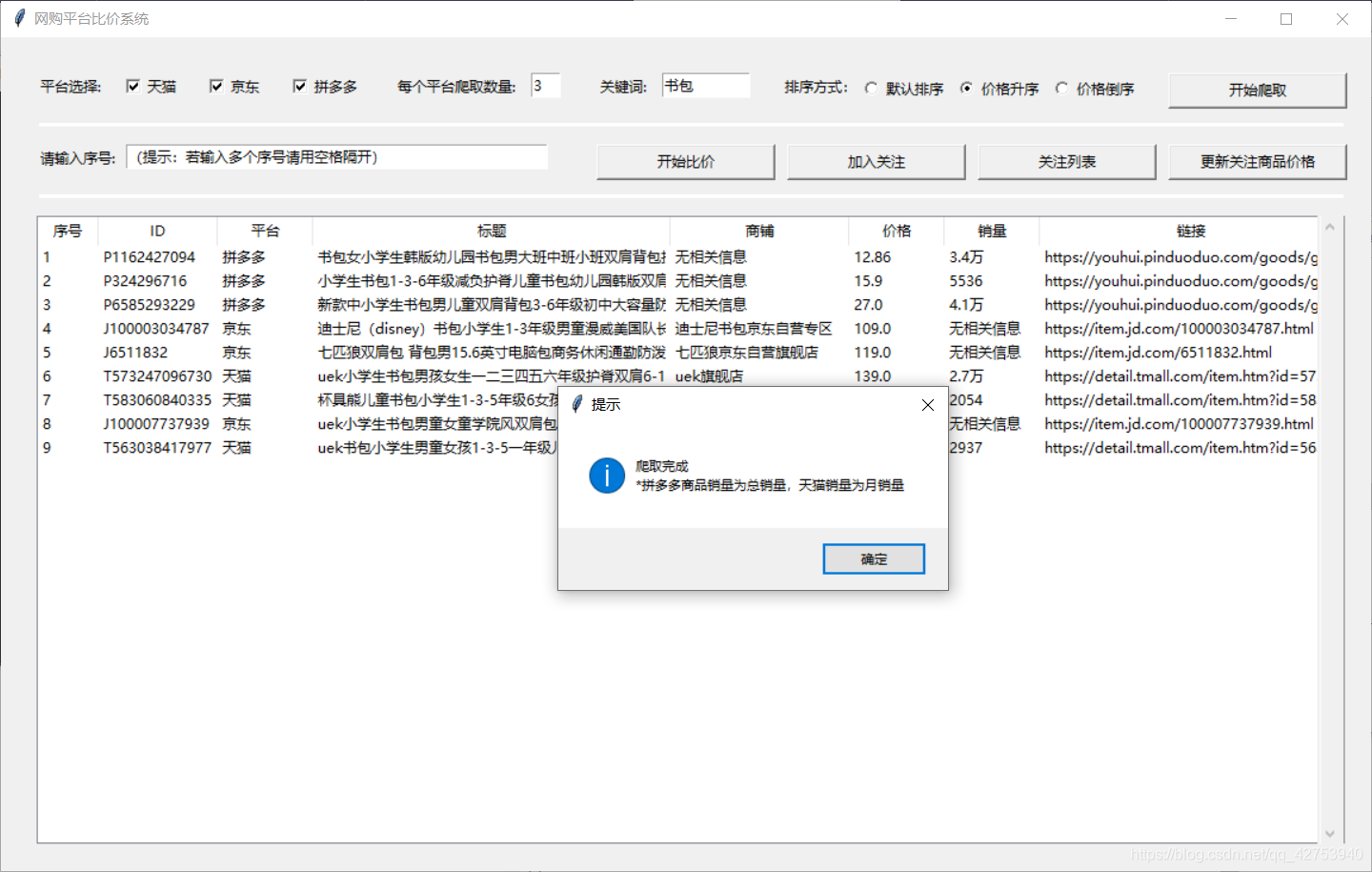
1.2.3 数据库设计
我这里用的是SQL Server,不过所有的关系型数据库的语法啥的都差不多,只不过是导入的第三方库略有不同。我这里用的是pymssql库,这个就根据具体情况来,比如MySQL就对应了pymysql库。这个程序其实就用到了一个表(此处数据随便写的,仅作为示例):
| ID | 平台 | 标题 | 商铺 | 价格 | 销量 | 链接 |
|---|---|---|---|---|---|---|
| J123123 | 京东 | 全自动钢笔 | 钢笔店 | 200.0 | 2000 | www.csdn.com |
| SQL具体的语法就不说了,此处给出创建数据库的语句: | ||||||
create table goods(goodsID nvarchar(20) Primary key,platform nvarchar(10),title nvarchar(100),shop nvarchar(100),price float,sales nvarchar(10),href nvarchar(300)) |
对数据库的读取以及数据的插入更新我们用到的时候再说。
二、设计过程
2.1 面向对象设计
说来惭愧,我之前一直是按照结构化的设计来进行的,突然看到老师要求面向对象设计才在中途改了,所以这个设计说起来并不是很完美,至少来说内聚性不是特别好。因此没有被要求面向对象设计的同学duck不必像我这样。但是我这个东西其实也不是很注重面向对象的设计,所以大家体谅一下(这都是当初随性设计出来的,就按着第一次的设计往下走了,懒得重新设计了)。
2.1.1 由需求导出用例图
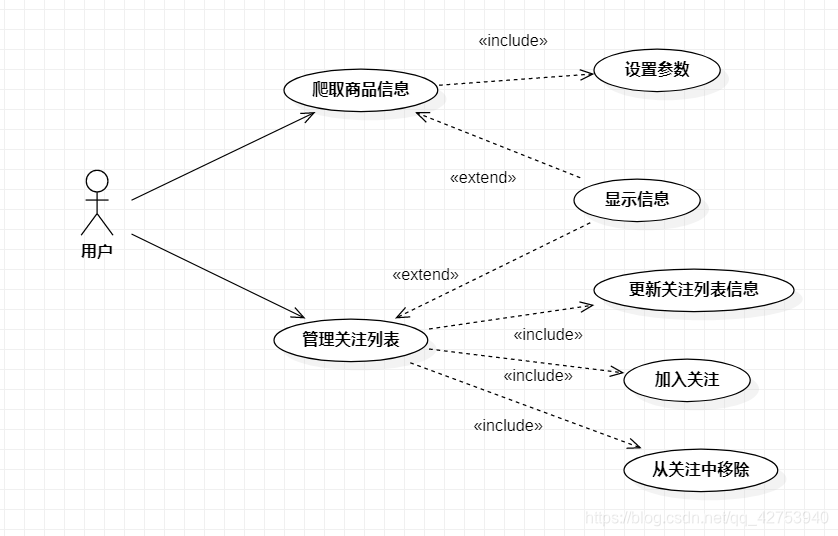
用户大体上应该可以进行两大类的操作:对指定商品信息的爬取以及对关注列表的管理(增删改查等)。
1、 用户可以通过设置参数爬取商品信息,从而获取指定的商品信息并按照要求进行显示,比如可以选择排列方式、显示出的商品数量等。
2、 用户也可以通过管理关注列表实现对关注商品的增删改查以及更新操作,更新操作可以获取关注列表种所有商品的最新信息并能给出关注商品的价格变化情况。
从而我们得到用例图:
2.1.2 类的确定
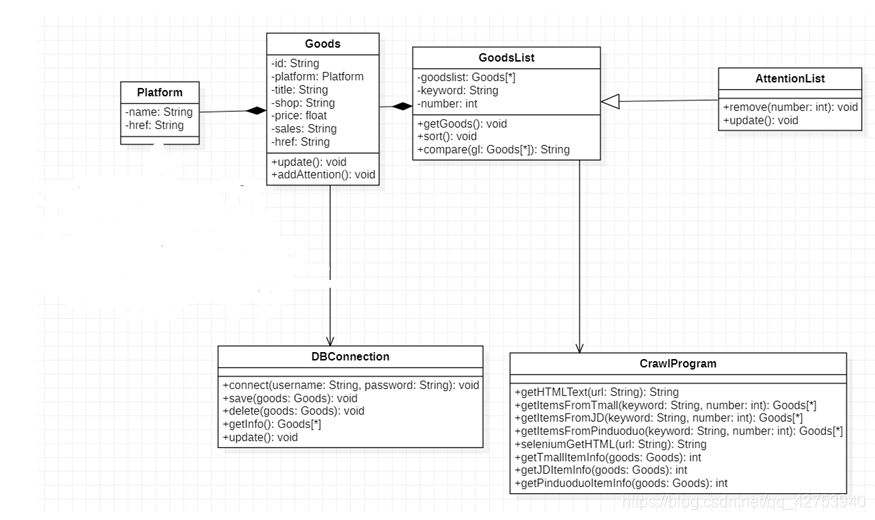
我的这个设计包含了四个实体类和两个功能类,实体类:商品、商品清单、关注的商品列表(继承自商品清单)、购物平台。功能类:数据库功能类、网络爬虫功能类。
这里简单介绍以下各个类的功能:
商品:存放商品的信息,包含信息更新和加入关注列表两个方法。
商品清单:存放爬取到的数据列表,属性为商品对象的列表、查找商品的关键字以及获取到的商品的数量,包含商品比价、查找并获取商品信息、修改查找关键字三个方法。
关注列表:继承自商品清单,多了移除商品以及更新信息两个方法。
购物平台:用于存放平台的信息。
数据库功能类:封装了对数据库的增删改查功能。
爬虫功能类:封装了爬虫的相关功能(比如对HTML的获取、对数据的解析、对目标数据的获取及返回等)。
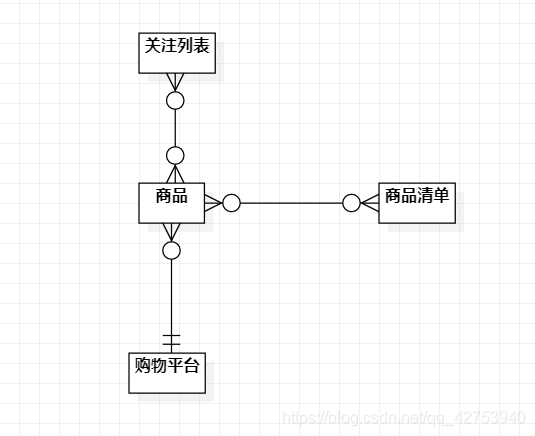
这是本菜鸡画的E-R图:
本菜鸡做的分析类图:
2.1.3 实体类的设计
这个我觉得有点基础的应该都能设计出来吧,这里就不赘述了。说白了实体类也就是包含一些属性和对属性的set和get方法,实在没什么好说的,那我们跳过。
2.1.4 功能类的设计
i. 数据库功能类设计
数据库的功能类主要包含了五个方法:数据库连接以及对数据库的增删改查。
首先是数据库的连接:
def connect(self):
#连接到数据库,获取数据库对象,四个参数:数据库服务器、用户名、用户密码、所要链接的数据库名(这里需要提前创建好Goods这个数据库)
database = pymssql.connect("localhost", "sa",  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









