







1、任务
使用大模型(包含向量模型和大语言模型)帮助分析学术论文,并利用streamlit框架实现与人的交互问答。
其中使用RAG技术,可以参考大模型2-初试大模型+RAG
2、具体步骤
主要包含模型的初始化、导入文件内容的向量化以及大模型与人交互的框架搭建。
2.1 大模型初始化
这里依然使用yuan大模型Yuan2-2B-Mars-hf作为大语言模型,bge-small-en-v1.5作为向量模型。首先定义yuan大模型推理框架(流程):
# 定义源大模型类
class Yuan2_LLM(LLM):
"""
class for Yuan2_LLM
"""
tokenizer: AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, mode_path :str):
super().__init__()
# 加载预训练的分词器和模型
print("Creat tokenizer...")
self.tokenizer = AutoTokenizer.from_pretrained(mode_path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')
self.tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Creat model...")
self.model = AutoModelForCausalLM.from_pretrained(mode_path, torch_dtype=torch.bfloat16, trust_remote_code=True).cuda()
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
# stop: 可选的停止词(在生成过程中遇到这些词时,停止生成)。
# run_manager: 回调管理器,用于在模型运行时监控状态。
prompt = prompt.strip()
prompt += "<sep>"
inputs = self.tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()
outputs = self.model.generate(inputs,do_sample=False,max_length=4096)
output = self.tokenizer.decode(outputs[0])
response = output.split("<sep>")[-1].split("<eod>")[0]
return response
# 这是一个类的属性,返回模型的类型,表示这个模型是自定义的 Yuan2_LLM 类型
@property
def _llm_type(self) -> str:
return "Yuan2_LLM"
2.2 导入论文内容并向量化
将论文内容导入,一般是PDF文件,使用PyPDF读取PDF内容:
def text_reader(summarizer):
# 上传pdf
uploaded_file = st.file_uploader("Upload your PDF", type='pdf')
text_pdf = None # 设置默认值
if uploaded_file:
# 加载上传PDF的内容
file_content = uploaded_file.read()
# 写入临时文件
temp_file_path = "temp.pdf"
with open(temp_file_path, "wb") as temp_file:
temp_file.write(file_content)
# 加载临时文件中的内容
loader = PyPDFLoader(temp_file_path)
text_pdf = loader.load()
print(text_pdf)
st.chat_message("assistant").write(f"正在生成论文概括,请稍候...")
# 生成概括
summary = summarizer.summarize(text_pdf)
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(summary)
return text_pdf
将输入论文内容分块向量化,用于RAG,可以参考下述内容。其中RecursiveCharacterTextSplitter是langchain框架中的函数用于分割文本。
# 定义ChatBot类
class ChatBot:
def __init__(self, llm, embeddings):
self.prompt = PromptTemplate(
input_variables=["text"],
template=chatbot_template
)
self.chain = load_qa_chain(llm=llm, chain_type="stuff", prompt=self.prompt)
self.embeddings = embeddings
# 加载 text_splitter
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=10,
length_function=len
)
def run(self, docs, query):
# 读取所有内容
text = ''.join([doc.page_content for doc in docs])
# 切分成chunks
all_chunks = self.text_splitter.split_text(text=text)
# 转成向量并存储
VectorStore = FAISS.from_texts(all_chunks, embedding=self.embeddings)
# 检索相似的chunks
chunks = VectorStore.similarity_search(query=query, k=1)
# 生成回复
response = self.chain.run(input_documents=chunks, question=query)
return chunks, response
在使用的时候需要对模型初始化:
# 大模型初始化
def LLM_Config():
# 获取llm和embeddings
llm, embeddings = get_models()
# 初始化summarizer
summarizer = Summarizer(llm)
# 初始化ChatBot
chatbot = ChatBot(llm, embeddings)
return summarizer, chatbot
其中,Summarizer用于获取论文摘要信息,如下所示,其中对摘要部分的截取,不同论文格式、内容形式不一样,可能需要调整,不一定是'Abstract'和'Index Terms'之间的内容。
# 定义Summarizer类
class Summarizer:
"""
class for Summarizer.
"""
def __init__(self, llm):
self.llm = llm
self.prompt = PromptTemplate(
input_variables=["text"],
template=summarizer_template
)
self.chain = LLMChain(llm=self.llm, prompt=self.prompt)
# self.chain = self.prompt | self.llm | StrOutputParser()
def summarize(self, docs):
# 从第一页中获取摘要
content = docs[0].page_content.split('Abstract')[1].split('Index Terms')[0]
summary = self.chain.run(content)
return summary
2.3 大模型与人交互
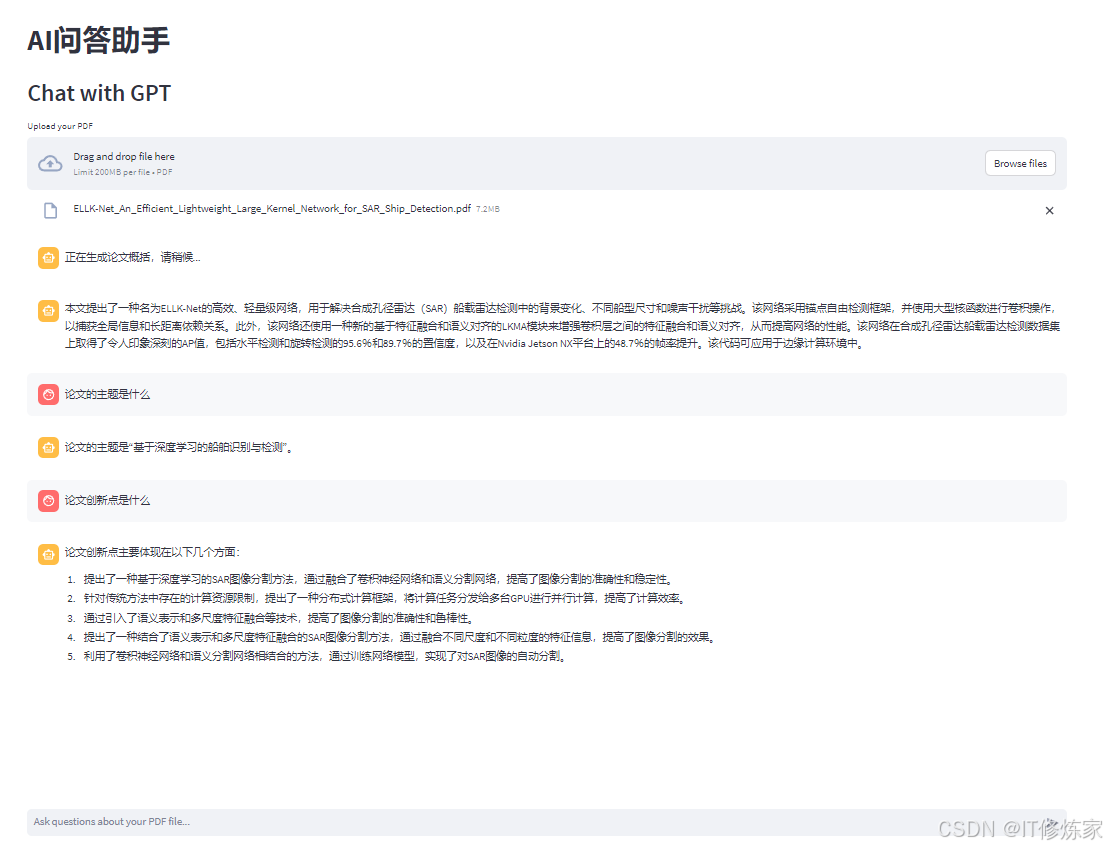
使用streamlit框架搭建问答交互界面,并记录每次交互的内容。
# AI交互
def AI_Chat():
global docs
# 设置页面的基本配置,包括页面标题和布局
st.set_page_config(page_title="Welcome to AI问答", layout="wide")
# 创建一个标题
st.title("AI问答助手")
summarizer, chatbot = LLM_Config()
# 检查会话状态中是否存在 messages 列表,如果不存在,则初始化为空列表
# 用于存储交流过程中的消息
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 创建一个容器,用于聊天界面的展示
with st.container():
st.header("Chat with GPT") # 显示聊天界面的标题
# 文件读取并分析
# if st.session_state["messages"] == []:
docs = text_reader(summarizer)
# 遍历保存在会话状态中的消息,并根据消息类型(人类或AI)分别显示
for message in st.session_state["messages"]:
if isinstance(message, HumanMessage): # 这里不应该用 system message
with st.chat_message("user"): # 不用 container;user
st.markdown(message.content)
elif isinstance(message, AIMessage):
with st.chat_message("assistant"): # 不用 container;assistant
st.markdown(message.content)
# 当用户输入后,处理用户的输入
if query := st.chat_input("Ask questions about your PDF file..."):
st.session_state["messages"].append(HumanMessage(content=query)) #保存human msg
with st.chat_message("user"):
st.markdown(query)
# 调用 ChatOpenAI 对象处理用户输入,获得 AI 的回复
chunks, response = chatbot.run(docs, query)
# 将模型的输出加入到历史信息中
st.session_state["messages"].append(AIMessage(content=response))
with st.chat_message("assistant"):
st.markdown(response)
3、优化
当前使用效果其实一般,这里也只是搭建了一个非常基础的框架,后续还需要进一步优化,可以优化的方向:
1、换更好的大语言模型和向量模型
2、AI交互的逻辑
3、对PDF论文内容读取优化
4、对读取到的内容向量化上的调优
…
4、完整代码
下面是完整代码,注意运行代码使用streamlit run xxx.py
# 导入所需的库
import torch
import streamlit as st
from transformers import AutoTokenizer, AutoModelForCausalLM
from langchain.prompts import PromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import PyPDFLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.chains import LLMChain,StuffDocumentsChain
from langchain.chains.question_answering import load_qa_chain
from langchain.llms.base import LLM
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
# from langchain_core.output_parsers import StrOutputParser
# from langchain_core.prompts import PromptTemplate
from typing import Any, List, Optional
# 定义模型路径
model_path = './IEITYuan/Yuan2-2B-Mars-hf'
# 定义向量模型路径
embedding_model_path = './AI-ModelScope/bge-small-en-v1___5'
# 定义模型数据类型
torch_dtype = torch.bfloat16 # A10
# torch_dtype = torch.float16 # P100
# 定义源大模型类
class Yuan2_LLM(LLM):
"""
class for Yuan2_LLM
"""
tokenizer: AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, mode_path :str):
super().__init__()
# 加载预训练的分词器和模型
print("Creat tokenizer...")
self.tokenizer = AutoTokenizer.from_pretrained(mode_path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')
self.tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Creat model...")
self.model = AutoModelForCausalLM.from_pretrained(mode_path, torch_dtype=torch.bfloat16, trust_remote_code=True).cuda()
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
# stop: 可选的停止词(在生成过程中遇到这些词时,停止生成)。
# run_manager: 回调管理器,用于在模型运行时监控状态。
prompt = prompt.strip()
prompt += "<sep>"
inputs = self.tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()
outputs = self.model.generate(inputs,do_sample=False,max_length=4096)
output = self.tokenizer.decode(outputs[0])
response = output.split("<sep>")[-1].split("<eod>")[0]
return response
# 这是一个类的属性,返回模型的类型,表示这个模型是自定义的 Yuan2_LLM 类型
@property
def _llm_type(self) -> str:
return "Yuan2_LLM"
# 定义一个函数,用于获取llm和embeddings
@st.cache_resource
def get_models():
llm = Yuan2_LLM(model_path)
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model_path,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
return llm, embeddings
summarizer_template = """
假设你是一个AI科研助手,请用一段话概括下面文章的主要内容,200字左右。
{text}
"""
# 定义Summarizer类
class Summarizer:
"""
class for Summarizer.
"""
def __init__(self, llm):
self.llm = llm
self.prompt = PromptTemplate(
input_variables=["text"],
template=summarizer_template
)
self.chain = LLMChain(llm=self.llm, prompt=self.prompt)
# self.chain = self.prompt | self.llm | StrOutputParser()
def summarize(self, docs):
# 从第一页中获取摘要
content = docs[0].page_content.split('Abstract')[1].split('Index Terms')[0]
summary = self.chain.run(content)
return summary
chatbot_template = '''
假设你是一个AI科研助手,请基于背景,简要回答问题。
背景:
{context}
问题:
{question}
'''.strip()
# 定义ChatBot类
class ChatBot:
def __init__(self, llm, embeddings):
self.prompt = PromptTemplate(
input_variables=["text"],
template=chatbot_template
)
self.chain = load_qa_chain(llm=llm, chain_type="stuff", prompt=self.prompt)
self.embeddings = embeddings
# 加载 text_splitter
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=10,
length_function=len
)
def run(self, docs, query):
# 读取所有内容
text = ''.join([doc.page_content for doc in docs])
# 切分成chunks
all_chunks = self.text_splitter.split_text(text=text)
# 转成向量并存储
VectorStore = FAISS.from_texts(all_chunks, embedding=self.embeddings)
# 检索相似的chunks
chunks = VectorStore.similarity_search(query=query, k=1)
# 生成回复
response = self.chain.run(input_documents=chunks, question=query)
return chunks, response
# 大模型初始化
def LLM_Config():
# 获取llm和embeddings
llm, embeddings = get_models()
# 初始化summarizer
summarizer = Summarizer(llm)
# 初始化ChatBot
chatbot = ChatBot(llm, embeddings)
return summarizer, chatbot
def text_reader(summarizer):
# 上传pdf
uploaded_file = st.file_uploader("Upload your PDF", type='pdf')
text_pdf = None # 设置默认值
if uploaded_file:
# 加载上传PDF的内容
file_content = uploaded_file.read()
# 写入临时文件
temp_file_path = "temp.pdf"
with open(temp_file_path, "wb") as temp_file:
temp_file.write(file_content)
# 加载临时文件中的内容
loader = PyPDFLoader(temp_file_path)
text_pdf = loader.load()
print(text_pdf)
st.chat_message("assistant").write(f"正在生成论文概括,请稍候...")
# 生成概括
summary = summarizer.summarize(text_pdf)
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(summary)
return text_pdf
# AI交互
def AI_Chat():
global docs
# 设置页面的基本配置,包括页面标题和布局
st.set_page_config(page_title="Welcome to AI问答", layout="wide")
# 创建一个标题
st.title("AI问答助手")
summarizer, chatbot = LLM_Config()
# 检查会话状态中是否存在 messages 列表,如果不存在,则初始化为空列表
# 用于存储交流过程中的消息
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 创建一个容器,用于聊天界面的展示
with st.container():
st.header("Chat with GPT") # 显示聊天界面的标题
# 文件读取并分析
# if st.session_state["messages"] == []:
docs = text_reader(summarizer)
# 遍历保存在会话状态中的消息,并根据消息类型(人类或AI)分别显示
for message in st.session_state["messages"]:
if isinstance(message, HumanMessage): # 这里不应该用 system message
with st.chat_message("user"): # 不用 container;user
st.markdown(message.content)
elif isinstance(message, AIMessage):
with st.chat_message("assistant"): # 不用 container;assistant
st.markdown(message.content)
# 当用户输入后,处理用户的输入
if query := st.chat_input("Ask questions about your PDF file..."):
st.session_state["messages"].append(HumanMessage(content=query)) #保存human msg
with st.chat_message("user"):
st.markdown(query)
# 调用 ChatOpenAI 对象处理用户输入,获得 AI 的回复
chunks, response = chatbot.run(docs, query)
# 将模型的输出加入到历史信息中
st.session_state["messages"].append(AIMessage(content=response))
with st.chat_message("assistant"):
st.markdown(response)
def main():
AI_Chat()
if __name__ == '__main__':
main()
参考文献
2、大模型webapp搭建:Steamlit 快速上手二(多轮对话)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









