







背景
Obsidian 原本是基于纯文本的,它只设计了基础的数据查询功能(也就是你打开 Obsidian 后能看到的搜索框),它本不支持将这些数据动态展示以及动态更替;不过事情在今年的 1 月 11 日~13 日这短短三天发生了变化,Obsidian 社区先后迎来了 Obsidian Query Language 插件以及 Dataview 插件,如果你曾经使用过这两者中的其一,你就会发现他们对数据都是动态索引、动态展示的,而这种方式就是我们所熟知的结构化查询语言,不过目前并不支持在查询后对对应的文本进行删改,因此只能说是 50% 结构化查询,侧重于执行查询、取回数据以及创建视图三大方面。
目前,Obsidian 作为日常记录文本的主力软件,想要简单介绍一些 Obsidian 使用过程中使用到的插件。首先就来介绍下载量最多的插件 —— DataView 插件。
网上已经有了很多关于 DataView 插件的介绍,对于我而言,DataView 给 Obsidian 带来了史诗级的加强,主要在于这插件能在这种记录文本的软件上提供类似数据库操作,可以自定义查询过滤操作。
基本方法
[!important]
因为主要使用 Table 方面,因此主要讲解关于这方面的方法如果是接触过 SQL 语句,这样上手 DataView 就会简单超级多
在代码块中选择 dataview 类型就是在编辑 DataView 方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nBs3G5Fg-1665847671765)(source/Pasted%20image%2020221015225340.png)]](https://i-blog.csdnimg.cn/blog_migrate/f6e5e366ec3e580742f38fc52c2d266e.png)
模版类型
以上是 DataView 插件提供的模版,可以看出其中使用 list|table|task 关键词表示 DataView 提供的三种模版类型,在日常使用的过程中,使用 table 类型会比较多。
任务类型的文件也有很多,但没有使用 DataView 的
task类型表示,而是使用 Obsidian 中的 Task 插件
展示数据
指定模版类型之后就要选择需要展示的数据(field 部分),其中 DataView 已经提供了一部分属性。在平时查询的过程中,使用这些属性已经足够了,但如果还需要自定义属性的话,可以通过使用这些属性构建表达式完成。
当然这些属性也可以想在 SQL 语句中那样起别名,也是使用 AS 关键词。
filed.name:文件标题filed.folder:该文件所属文件夹的路径filed.path:完整的文件路径filed.link:文件的链接filed.size:文件的大小filed.ctime:文件的创建时间filed.cday:文件的创建日期filed.mtime:文件的修改时间filed.mday:文件的修改日期filed.tags:笔记中所有标签的数组,子标签按照每个级别细分filed.etags:排除的标签,与tags相反filed.inlinks:指向此文件的所有链接的数组filed.outlinks:此文件所有出站链接的数组filed.aliases:注释的所有别名数组
数据来源
照着 SQL 语句的形式,选择完展示的数据之后就要选择数据来源,也就是 From 之后的数据来源,不同于 SQL 语句数据来自于数据库表,DataView 数据来自于各个 Folder 笔记文件夹,Tag 标签以及 Link 链接。
Folder 笔记文件夹使用 “” 表示, Tag 标签使用 # 表示,Link 使用 [[]] 表示
这里与 SQL 语句有个很大的不同就是连接多个数据来源的,DataView 插件只需要 () 以及 or 的结合使用,就可以连接多个文件
数据过滤
数据过滤跟 SQL 语句类似,这里就不再多说,只要在 Where 关键词后面添加关于属性的判断即可
排序
主要是 Desc 降序和 Asc 升序两种,使用 sort 关键词,选择排序依据的属性,再选择是 Desc 还是 Asc 方式即可
例子
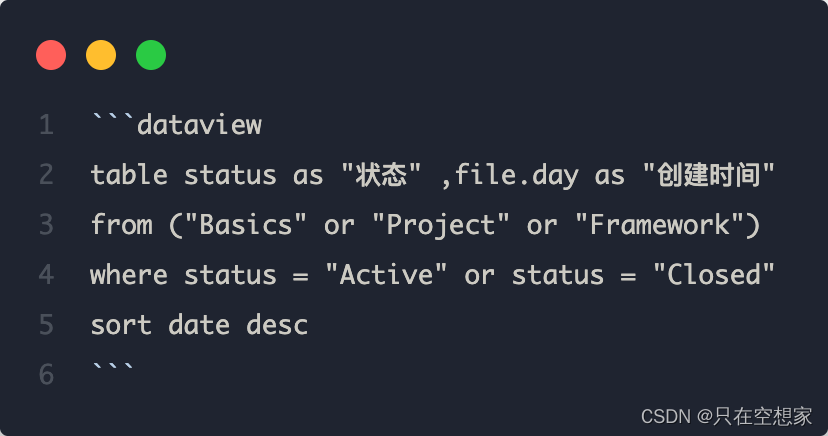


















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









