







需求背景
HDFS的一张表需要在MySQL这边创建新的主键并对原有的主键进行去重处理。
之前已经把HDFS的数据使用load的方式导到MySQL这边。当时图快,就导到了没有主键和索引的40多张表里。导完以后每个表建了索引(因为有重复值,所以只是辅助索引)。
现在要把这些表的索引字段取出来,然后在另一张表里完成创建新的主键和去重的操作。
MySQL版本8.0,服务器4核8G,SQL语句执行时CPU占用100%-200%之间,innodb缓存区给了512M。
SQL语句如下,40多张表依次进行,每次操作10万条数据:
insert ignore into aio_bigdata.post_id_rebuild(wb_post_id)
select post_id from {表名}
order by post_id
limit {offset}, 100000
运行了一半,记录一下各个表花费的时间:
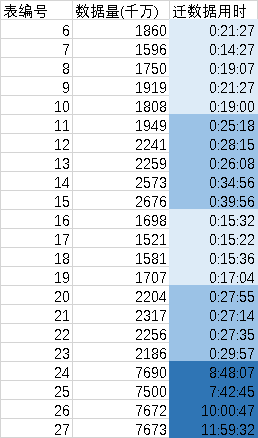
初始速度接近于每10分钟1千万条(颜色最浅部分)。后面的颜色深的部分慢得难以忍受,但是按表的数据量能得到一个规律,innodb表在把辅助索引按offset的方式遍历时,2500万条数据以下(224到225)性能还行,超过这个范围性能开始下降,超过2倍以后,性能极速下降。
然后看了一眼后面的表,有4个竟然是1.5亿的数据,果断停止这个程序,找新的办法导。各个表数据不均匀是因为HDFS分区数据不均匀。















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









