






楔子:笔者写这篇文章主要是为了巩固、加深自己的印象,毕竟笔者是个小白,如果有什么不对,还望斧正。
ps:本篇只是粗浅的介绍一番数据结构,略微多讲一些树的概念,不涉及代码,介意误入。
目录
1、数据结构的概念
在介绍树之前,笔者认为还是有必要讲讲什么是数据结构,以及数据结构有哪些分类。不光是为了梳理自己的头绪,还为了多水几个字(嘿嘿bushi)!
ps:了解过的请直接跳过。。。。。。
1. 什么是数据结构?
数据结构是计算机科学中的一个核心概念,指的是一种特定方式在计算机中组织和存储数据,以便能够高效地进行访问和修改,也可以说是指相互之间存在一种或多种特定关系的数据元素的集合。
通常情况下,不同的数据结构适用于不同的问题和场景,选择合适的数据结构可以显著提高程序的性能。精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
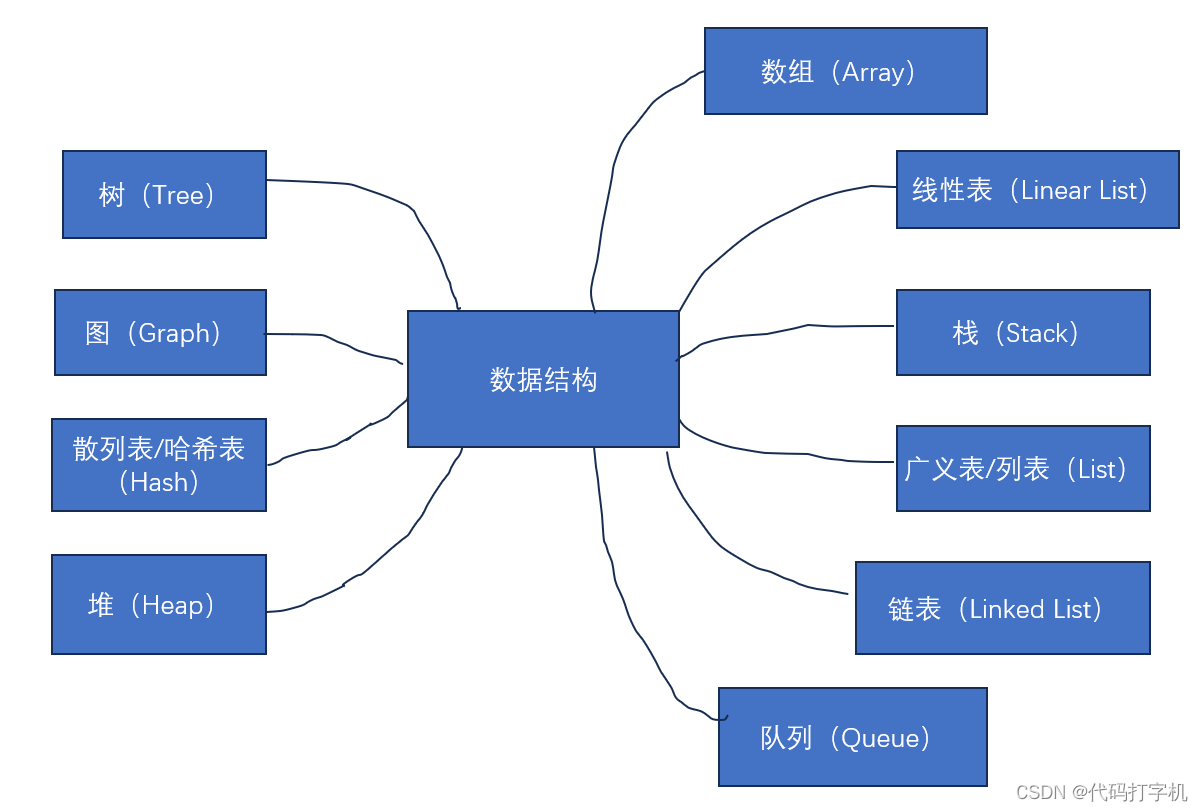
我们看一下下面的图,略有粗糙,但无伤大雅。这是我们数据结构的组成部分,因为本篇主讲树部分,所以大致了解一下就可以了,毕竟笔者也还没有每个都接触过。
2. 数据结构的好处
数据结构的主要有以下几点价值:
-
提高数据存储和操作的效率:通过选择合适的数据结构,可以降低数据处理过程中的时间和空间开销。
-
便于算法设计:选择合适的数据结构可以简化算法设计,提高算法的可读性和可维护性。
-
实现数据的抽象:数据结构将数据的表示和操作封装起来,使程序员能够更容易地处理复杂的数据问题。
3. 数据结构的大致分类
此处笔者借鉴了“逻辑实体”佬的文章,毕竟有好的总结可以利用,就不需要多费时间在这上面了,数据结构间的对比可以更为清晰地明白它们间的不同与作用所在。
1. 数组(Array)
数组是一种基本的数据结构,它在内存中分配连续的存储空间,通过索引直接访问元素。数组可以是一维的,也可以是多维的。
优点:
-
访问速度快,因为使用索引可以直接定位到具体的元素
-
适合处理固定大小的数据集
缺点:
-
插入和删除操作较慢,因为需要移动大量元素
-
内存空间需要预先分配,可能导致内存浪费
2. 链表(Linked List)
链表是由一系列节点组成的线性数据结构,每个节点包含一个数据元素和指向下一个节点的指针。链表可以是单向链表或双向链表。
优点:
-
插入和删除操作较快,只需修改指针
-
大小可以动态调整,适应不同数据量的需求
缺点:
-
访问速度较慢,需要遍历链表来定位元素
-
需要额外的空间存储指针
3. 栈(Stack)
栈是一种后进先出(LIFO)的数据结构,只允许在一端(称为栈顶)进行插入和删除操作。栈可以使用数组或链表实现。
优点:
-
简化了对数据的访问和操作,使得程序更易于理解
-
高效地支持需要后进先出访问模式的场景
缺点:
-
容量有限,当栈满时无法再插入新元素
-
不适用于需要快速访问任意位置元素的场景
4. 队列(Queue)
队列是一种先进先出(FIFO)的数据结构,允许在一端(队尾)进行插入操作,而在另一端(队首)进行删除操作。队列可以使用数组或链表实现。
优点:
-
简化了对数据的访问和操作,使得程序更易于理解
-
高效地支持需要先进先出访问模式的场景
缺点:
-
容量有限,当队列满时无法再插入新元素
-
不适用于需要快速访问任意位置元素的场景
5. 树(Tree)
此处是笔者将讲述的重点,还是需要细细看一下的。
树是一种分层的非线性数据结构,由节点组成,每个节点有零个或多个子节点。常见的树结构有二叉树、红黑树、AVL树等。
优点:
-
树形结构可以很好地表示层次关系和分支结构
-
在平衡树(如红黑树、AVL树)中,查找、插入、删除操作的时间复杂度较低,通常为O(log n)
-
树结构易于扩展,可以方便地实现各种高级数据结构
缺点:
-
实现相对复杂,需要维护各种平衡和指针关系
-
需要额外的空间存储指针
-
对于线性数据,树结构可能不如数组和链表高效
6. 图(Graph)
图是一种复杂的非线性数据结构,由节点(顶点)和连接这些节点的边(线)组成。图可以表示多对多的关系,可以是有向图或无向图。
优点:
-
图可以表示复杂的网络关系和拓扑结构
-
可以很好地解决各种路径、流量和连接性问题
-
灵活性高,可以表示多种实际问题
缺点:
-
实现复杂,需要维护顶点和边的关系
-
对于稀疏图,邻接矩阵表示法可能会浪费大量空间
-
图算法通常较难理解和实现,如最短路径、最小生成树等
以上是一些常见的数据结构,当然还有许多其他数据结构,如红黑树、AVL树、Trie树等。在实际应用中,根据问题的具体需求和场景选择合适的数据结构,可以大大提高程序的性能和可维护性。
而在这之中,线性数据结构有数组、链表、队列和堆栈,而非线性数据结构包括二维数组,多维数组、树(二叉树、二叉搜索树等)、堆和图。
此为描述原帖,内部还含各类数据结构的java实例:
https://baijiahao.baidu.com/s?id=1761129438126792260&wfr=spider&for=pc
2、其中常用的一例——树
1. 树结构的定义与对比
树结构是一种一对多的非线性结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
- 不要与现实中的树混在一起,当n>0时,树有且只有一个根结点。
- 除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
2. 树结构的相关概念
节点的度:一个节点含有的子树的个数称为该节点的度;
叶节点或终端节点:度为0的节点称为叶节点;
非终端节点或分支节点:度不为0的节点;
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
树的度:一棵树中,最大的节点的度称为树的度;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:双亲在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>0)棵互不相交的树的集合称为森林;
如Linux的文件夹系统就是这样一个结构:

此处只是较为笼统的介绍了树的相关概念,具体还请转至它住,笔者能力实在受限(/(ㄒoㄒ)/~~)
接下来就是树中较为常用的二叉树及其特殊分支的介绍了,
3. 二叉树
与数组,链接列表,堆栈和队列(它们是线性数据结构)不同,树是分层的数据结构。
二叉树是一种树形数据结构,其中每个节点最多具有两个子节点,称为左子节点和右子节点。它主要使用链接来实现。
1. 二叉树表示
树由指向树中最高节点的指针表示。如果树为空,则root的值为NULL。二叉树节点包含三部分:自己本身的数据、指向左孩子的指针以及指向右孩子的指针 。
可以通过两种方式遍历二叉树
第一种是 深度优先遍历(简称DFS):前序(根-左-右),中序(左根右)和后序(左右根)
第二种是 广度优先遍历(简称BFS):水平顺序 遍历
2. 二叉树属性
第i层的最大节点数= 2i;
二叉树最大节点数= 2h +1-1,这里h是指树的高度;
最小可能高度= ceil(Log2(n + 1))-1,ceil()意为向下取整;
叶子节点的数量总是比有两个孩子的节点数量多一;
树遍历的时间复杂度:O(n)。
二叉树举例说明
通常使用二叉树或树的原因就是要形成一个层次结构。它们在文件结构中很有用,其中每个文件都位于特定目录中,并且存在与文件和目录关联的特定层次结构。另外还有就是存储分层对象,例如JavaScript文档对象模型,将HTML页面视为一棵树,其中标签嵌套为父子关系。
4. 二叉搜索树(也叫二叉排序树)
二叉搜索树中其实只是多了一些属性特点的二叉树,多出的属性有以下三点:
1.节点的值大于其左子树中任意一个节点的值;
2.节点的值小于其右节点中任意一节点的值;
3.左子树和右子树也都必须是二叉搜索树。
时间复杂度方面:
搜索:O(h)
插入:O(h)
删除:O(h)
空间:O(n);(h是指二叉搜索树的高度,n是指二叉搜索树中的节点数。)
如果二叉搜索树是高度平衡的,则h = O(log n),自平衡二叉搜索树(例如AVL树,红黑树和Splay树)可确保二叉搜索树的高度保持为O(log n)。
二叉搜索树访问/搜索速度比链表更快,比数组慢。但是二叉搜索树的插入/删除速度比数组更快,比链表慢。
二叉搜索树举例说明
它的主要用途是在搜索应用程序中,在该应用程序中,数据不断输入/释放,并且需要按排序顺序打印数据。例如,在电子商务网站的实施中,其中添加了新产品或产品缺货,并且所有产品均按排序顺序列出。
5. 二叉堆
二叉堆其实就是增加了几重属性的二叉树,他们区别在于:
1. 二叉堆是一种完全二叉树,除了最后一个层,其他所有层都已完全填满,二叉堆的此属性使它们适合存储在数组中。
2. 二叉堆既是大根堆也是小根堆,子结点总是大于或小于父结点。
大根堆:顾名思义,根是最大的,每个子结点都要小于父结点,不区分左右儿子谁大谁小,也不必保证某个“孙子结点”一定要小于另一个“儿子结点”。
小根堆:恰恰相反,根是最小的,每个子结点都要大于父结点,不区分左右儿子谁大谁小,也不必保证某个“孙子结点”一定要大于另一个“儿子结点”。
在最小堆中获取最小值:O(1)[或在最大堆中获取最大值]
插入:O(Log n)
删除:O(Log n)
二叉堆的示例
用于实现高效的优先级队列,而这些优先级队列又用于调度操作系统中的进程。优先队列也用在Dijikstra和Prim的图算法中。
堆数据结构可用于有效地查找数组中的k个最小(或最大)元素,合并k个排序数组等。堆是一种特殊的数据结构,不能用于搜索特定的元素。
Extra. Hash表
这里笔者给自己打个广告,和树都为非线性的数据结构,Hash表的用法也是很广阔的。
Hash函数能够将一个输入的大键(key)转换为更小的整数值(value)。该映射的整数值用作哈希表中的索引。良好的哈希函数应具有以下属性
1)高效可计算。
2)应均匀分配输入值(每个输入值在表中的位置均等)
要理解Hash表,其中的哈希函数、冲突处理、链接、开放式寻址要弄清楚。
而这具体可以在我之前写的博客中找到:哈希(Hash)表的初相识
https://blog.csdn.net/qq_42785084/article/details/134839182?spm=1001.2014.3001.5502
复杂度方面:
空间:O(n);
搜索:平均情况下是O(1),最坏情况下是 O(n);
插入:平均情况下是O(1),最坏情况下是 O(n);
删除:平均情况下是O(1),最坏情况下是 O(n)。
对于所有操作,哈希似乎比二叉搜索树更好。但是在哈希中,元素是无序的,而在二叉搜索树中,元素是以有序的方式存储的。同样,二叉搜索树易于实现,但是哈希函数的生成有时可能非常复杂。在二叉搜索树中,我们还可以很快地找到最大值、最小值。
好了,洋洋洒洒也有四千字了。笔者知道其中干货不多,但也能够让小白们大致了解数据结构方面的内容了。至于更加具体地,可能要等到笔者给自己充充电,才能继续深入拓展了。
那么今天就到这里为止,希望能够读到这里的小伙伴点点赞,我们下次再见!















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









