










SIMPLIFIED SELF-ATTENTION FOR TRANSFORMER-BASED END-TO-END SPEECH RECOGNITION
2021 IEEE
由于这篇所涉及的领域我并不了解,所以仅提供instruction和method部分,experiment其实也不太详尽,就不多赘述,需要者可自行观看。总的来说,本篇paper最大的亮点是提出了使用FSMN内存块来形成Q和K向量的SSAN层,并作用于Transformer模型,在确保性能没有降低的前提下,减少了传统Transformer训练的时长。
ABSTRACT
由于Transformer模型在建模长期依赖关系方面的优势,因此已被引入端到端语音识别中,在各种任务上具有最先进的性能。然而,这种改进通常是通过使用非常大的神经网络来获得的。Transformer模型主要包括位置前馈层和自注意层(SAN)层。在本文中,为了在保持良好性能的同时降低模型的复杂度,作者提出了一种简化的自注意(SSAN)层,它使用FSMN内存块而不是投影层来形成查询和关键向量,用于基于Transformer的端到端语音识别。本文评估了基于SSAN和传统的基于SSAN的变压器,在AISHELL-1内部1000小时和20000小时的大规模普通话任务。结果表明,本文提出的基于SSAN的Transformer模型在AISHELL-1任务中模型参数降低20%以上,相对CER降低6.7%。经过令人印象深刻的20%的参数减少,本文模型在20,000小时的大规模任务中显示出识别性能没有损失。
1. INTRODUCTION
传统的混合自动语音识别(ASR)系统主要有声学模型、语音模型和语言模型,分别使用个体优化目标进行训练。近年来,端到端(E2E)自动语音识别(ASR)取得了显著进展,目的是将三种模型结合成一个单一的神经网络,以显著简化ASR系统的构建。目前,主要有三个E2E框架:连接主义时间分类(CTC)、基于注意力的模型和传感器。这些模型将ASR视为一个Seq2Seq的任务,直接通过神经网络学习语音到文本的映射。这些模型也可以结合起来,以进一步提高性能。本文关注基于注意力的模型,旨在与简化的模型结构,更好的性能。
一个典型的基于注意的模型可以分为三个主要部分——编码器、注意器和解码器。对于ASR任务,编码器从输入语音中提取高级声学特征作为声学模型;解码器提取语言特征,并将输出序列预测为发音模型和语言模型;注意模块学习声学和语言特征之间的对齐。基于注意力的模型有几种结构,如听、注意和拼写(LAS)和Transformer。Transformer是一种典型的序列到序列模型,在机器翻译、自然语言理解和语言建模等各种自然语言处理任务上取得了重大进展。近年来,该Transformer模型已被应用于具有竞争性能的语音识别任务中。作为一种基于注意力的编码-解码器模型,该模型的核心是自注意网络(SAN)层,它可以建模长时间的上下文依赖关系。此外,Transformer没有递归结构,与LAS中的模型相比,并行化的训练速度要快得多。通过结构改造和模型/损耗集成,进一步探讨了变压器模型。在目前工作中,利用增强持久记忆获得自我注意层整个话语上下文长度之外的更多信息,提高ASR任务的表现。也有研究将CTC与Transformer集成起来进行联合训练和解码,这导致了各种ASR任务的显著改进。
E2E模型,包括变压器,有巨大的潜力,以部署在边缘设备与一个相对紧凑的足迹和更简单的建筑管道。然而,Transformer模型通过叠加多个SAN层,实现了优越的识别性能,导致了模型参数的大幅增加,并存在严重的解码延迟。例如,有研究报道的48个SAN编码器层加上另外48个SAN解码器层,总共构成了252M的模型参数。因此,本文研究了一些变体来简化变压器模型。有工作提出了一种全注意层来减小模型的大小,即通过增加具有持久记忆向量的自注意层来合并自注意层和位置级前馈层。结果表明,以键值向量形式存在的附加持久内存块可以存储一些全局信息,从而去除体积庞大的前馈层。该方法极大地简化了Transformer模型的结构,并且不会影响语言建模任务的性能。
本文提出了一种简化自注意层的新方法,同时保持了一个Transformer模型在语音识别中的性能优势。具体来说,通过引入FSMN记忆块来探索一个简化的自注意网络(SSAN)层。本文工作是受到前馈序列记忆网络的最新进展的启发。FSMN可以使用简单而优雅的非循环结构有效地建模长期上下文依赖,在声学建模和语言建模任务上实现减少模型规模和与循环神经网络的竞争性能。其中,对于每个自注意层,作者提出用FSMN记忆块而不是投影层来形成键查询向量,并将自注意输入直接分配给值向量,而不需要进行额外的计算。通过这种方式,键-查询向量可以有效地存储上下文信息,并进一步帮助自我注意层捕获长期的上下文依赖关系。同时,可以大大减少模型参数的数量。在几个ASR任务上的实验证明了本文方法的有效性。在公开AISHELL-1任务中,与竞争的基线Transformer模型相比,CER相对提高了6.7%,模型参数减少了21.7%。此外,对内部1000小时和20000小时大规模任务的实验表明,所提出的基于SSAN的Transformer可以在有效降低模型参数20%的情况下,不损失ASR性能。
2. MODEL ARCHITECTURE

如图1所示,改进的基于SSAN的Transformer建立在典型的Transformer上,具有基于注意的编解码器结构。编码器将一个帧级声学特征的输入序列 ( x 1 , . . . , x T ) (x_1,...,x_T) (x1,...,xT)映射到一个高级表示序列 ( h 1 , . . . , h T ) (h_1,...,h_T) (h1,...,hT),解码器在一个时间步长生成一个转录 ( y 1 , . . . , y L ) (y_1,...,y_L) (y1,...,yL)一个标记。原来的基于自注意网络(SAN)的编码器有两个子模块:多头自注意层(编码器注意)和位置级前馈层。解码器网络有三个子模块,包括掩蔽的多头自注意层(解码器-注意)、编码器和解码器之间的多头交叉注意层和位置级前馈层。每一层之后都是一个跳过连接和每一层的标准化。
在Transformer中,每个自注意头的输入被投影到查询、键和值向量中。为了简化自注意层,作者将查询和关键向量的投影层替换为FSMN记忆块,并将自注意的输入直接分配给值向量。更多的细节将在第2.4节中描述。
如图1所示,原来的编码器和解码器的自注意层被简化的自注意网络(SSAN)层所取代,而其他模块保持不变。
2.1. Multi-head self-attention
Transformer模型的核心是多头自我注意层,其目的是捕获长期的上下文依赖性。多头自注意旨在共同关注来自不同位置的不同表示子空间的信息。每个注意头采用缩放的点产品注意,将一个查询和一组键值对映射到一个输出。多头自注意的计算过程公式如下:
MultiHead ( Q , K , V ) = Concat ( h e a d 1 , . . . , h e a d h ) W O \text{MultiHead}(Q,K,V)=\text{Concat}(head_1,...,head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
h e a d i = SelfAttn ( X W i Q , X W i K , X W i V ) head_i=\text{SelfAttn}(XW^Q_i,XW^K_i,XW^V_i) headi=SelfAttn(XWiQ,XWiK,XWiV)
SelfAttn ( Q i , K i , V i ) = Softmax ( Q i K i d k ) V i \text{SelfAttn}(Q_i,K_i,V_i)=\text{Softmax}(\frac{Q_iK_i}{\sqrt{d_k}})V_i SelfAttn(Qi,Ki,Vi)=Softmax(dkQiKi)Vi
h e a d i , W i Q ∈ R d m o d e l × d q , W i K ∈ R d m o d e l × d k , W i V ∈ R d m o d e l × d v head_i,W_i^Q∈R^{d_{model}×d_q},W_i^K∈R^{d_{model}×d_k},W_i^V∈R^{d_{model}×d_v} headi,WiQ∈Rdmodel×dq,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv分别是查询投影矩阵、键投影矩阵和值投影矩阵。 W O ∈ R h d v × d m o d e l W^O∈R^{hd_v×d_{model}} WO∈Rhdv×dmodel为输出投影矩阵, h h h为头数, d m o d e l d_{model} dmodel为注意维数。在本工作中, d k = d v = d m o d e l / h d_k=d_v=d_{model}/h dk=dv=dmodel/h。
2.2. Position-wise Feedforward
除了多头自注意层外,编码器和解码器中的每一层都包含一个全连接的前馈层。该层由两个线性变换组成,中间有一个ReLU激活:
FFN ( X ) = RELU ( X W 1 + b 1 ) W 2 + b 2 \text{FFN}(X)=\text{RELU}(XW_1+b_1)W_2+b_2 FFN(X)=RELU(XW1+b1)W2+b2
其中 W 1 W_1 W1和 W 2 W_2 W2是维数 d m o d e l × d f f n d_{model}×d_{ffn} dmodel×dffn的矩阵, b 1 b_1 b1和 b 2 b_2 b2是偏差。
2.3. FSMN
FSMN扩展了标准的前馈全连接神经网络,通过增加一些内存块,功能作为类似FIR的滤波器。内存块的公式采用以下形式:
m ‾ t = m t + ∑ i = 0 N 1 a i ⊙ m t − i + ∑ j = 1 N 2 c j ⊙ m t + j \overline{m}_t=m_t+\sum_{i=0}^{N_1}a_i \odot m_{t-i}+\sum_{j=1}^{N_2}c_j \odot m_{t+j} mt=mt+i=0∑N1ai⊙mt−i+j=1∑N2cj⊙mt+j
其中 ⊙ \odot ⊙表示两个等大小向量的元素乘法。 N 1 N_1 N1称为回顾顺序,表示回顾过去的历史项目的数量, N 2 N_2 N2称为展望顺序,表示进入未来的展望窗口的大小。从等式(5)可以观察到FSMN中的关键元素是可学习的类似FIR的过滤器,用于将长上下文信息编码为固定大小。
2.4. The proposed SSAN
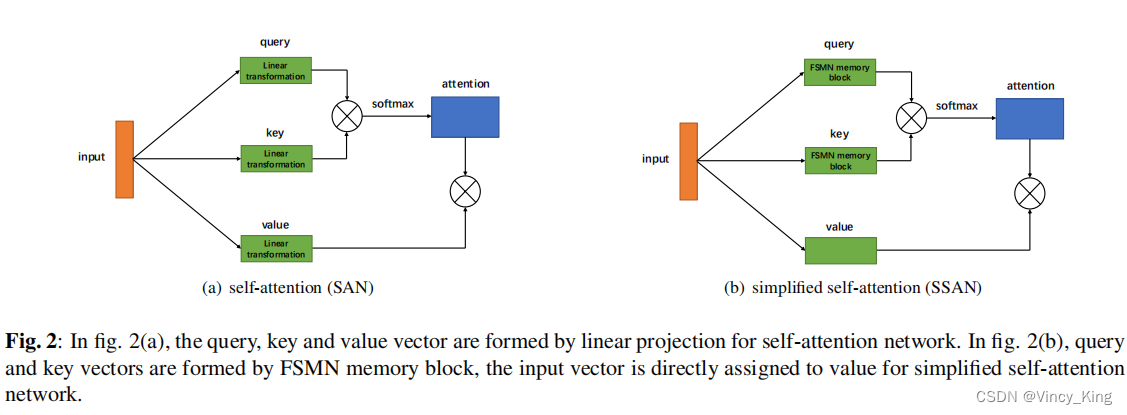
图2(a)显示了自注意层形式查询、键、投影层值。将自注意层的输入向量表示为 X = [ x 1 , . . . , x T ] X=[x_1,...,x_T] X=[x1,...,xT]。查询、键、值的计算过程表述为 Q t = W Q x t , K t = W K x t , V t = W V x t Q_t=W^Qx_t,K_t=W^Kx_t,V_t=W^Vx_t Qt=WQxt,Kt=WKxt,Vt=WVxt。为了简化自注意层,本文提出了一种新的形成查询、键值和值向量的方法,如图2(b).所示具体来说,作者使用第2.3节中介绍的FSMN内存块来形成查询和键,而输入向量 X X X被直接分配给值。形式上,查询、键和值变成。
Q t = x t + ∑ i = 0 N 1 x i ⊙ m t − i + ∑ j = 1 N 2 c j ⊙ x t + j Q_t=x_t+\sum_{i=0}^{N_1}x_i \odot m_{t-i}+\sum_{j=1}^{N_2}c_j \odot x_{t+j} Qt=xt+i=0∑N1xi⊙mt−i+j=1∑N2cj⊙xt+j
K t = x t + ∑ i = 0 N 1 b i ⊙ x t − i + ∑ j = 1 N 2 d j ⊙ x t + j K_t=x_t+\sum_{i=0}^{N_1}b_i \odot x_{t-i}+\sum_{j=1}^{N_2}d_j \odot x_{t+j} Kt=xt+i=0∑N1bi⊙xt−i+j=1∑N2dj⊙xt+j
V t = x t V_t=x_t Vt=xt
从查询、键和值形成的角度来看,可以看到SAN本身没有考虑上下文信息,而由于引入了FSMN记忆块,所提出的SSAN可以提取上下文信息用于计算注意矩阵。对于模型大小,SAN层需要 3 ∗ d m o d e l ∗ d m o d e l 3*d_{model}*d_{model} 3∗dmodel∗dmodel参数来形成查询、键向量和值向量,而SSAN层需要 2 ∗ ( N 1 + N 2 ) ∗ d m o d e l 2∗(N_1+N_2)∗d_{model} 2∗(N1+N2)∗dmodel参数。如果取FIR宽度(N1+N2)较小,则SSAN的参数数量将比SAN小得多。















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









