






目录
idea搭建基础环境(idea2022版本)
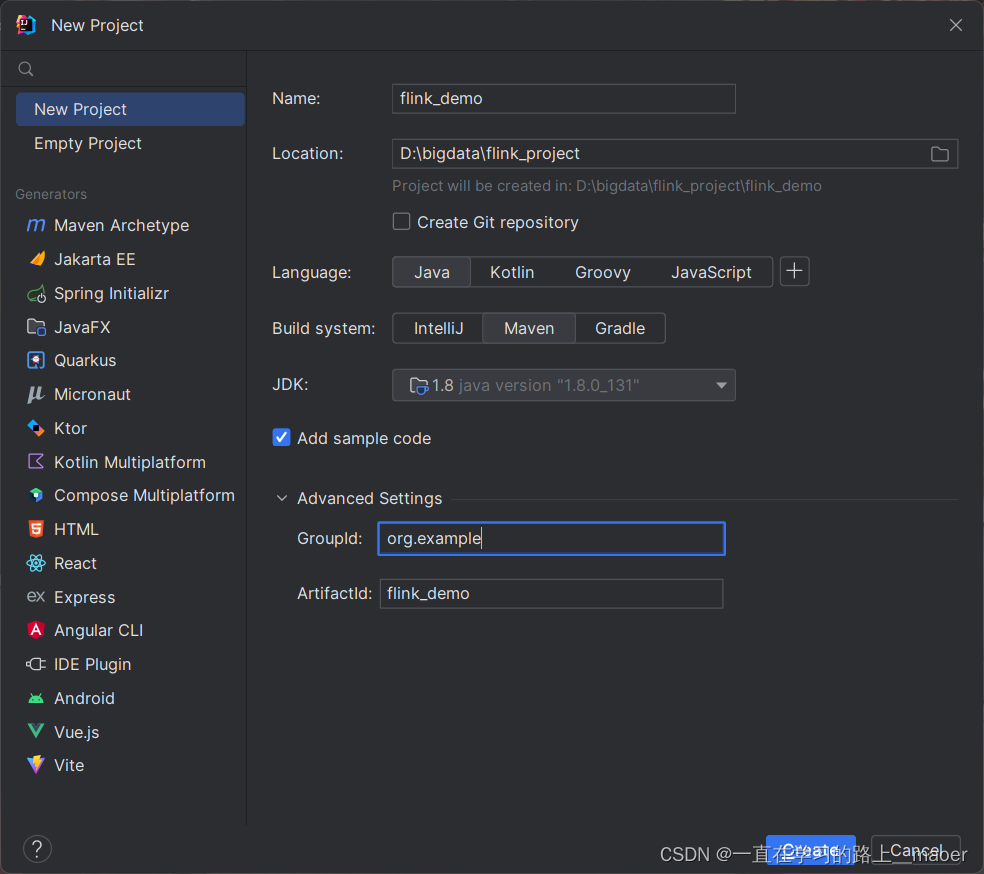
1.创建maven项目
2.在pom.xml文件中导入flink的相关依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.0</version>
</dependency>注意:第一次导入依赖可能会花费一些时间,请耐心等待!!!
3.代码实现过程
3.1批处理方式实现单词统计
/**
*
* 批处理单词统计类
*/
public class BatchWordCount {
// 主函数
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据 --> 按行读取 (存储元素为文件中的每行数据)
DataSource<String> lineDataSource = env.readTextFile("input/word");
// "input/word" 此处为相对路径,必须保证在整个项目中的input目录下存在word文件
System.out.println("-------------初始数据-------------");
lineDataSource.print();
// 切分、转换
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDataSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按照空格切分单词
String[] words = s.split(" ");
// 通过循环方式收集切分单词后的数组数据
for (String word : words) {
// 将单词转换为 (word,count) 元组形式
Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);
// 使用collector采集器,向下游发送数据
collector.collect(wordTuple2);
// 等效代码
//collector.collect(Tuple2.of(word,1));
}
}
});
System.out.println("-----------提取单词元组----------");
wordAndOne.print();
// 分组 --> 根据元组中第一个字段进行分组
UnsortedGrouping<Tuple2<String, Integer>> wordAndOneGroup = wordAndOne.groupBy(0);
// 分组内聚合统计 --> 统计每个单词的数量
AggregateOperator<Tuple2<String, Integer>> result = wordAndOneGroup.sum(1);
// 打印结果
System.out.println("-------------统计结果---------------");
result.print();
}
}3.2流处理方式实现单词统计
/**
* 流处理方式单词统计类
*/
public class StreamWordCount {
/**
* 主函数,用于启动流处理任务以统计输入文本文件中每个单词出现的次数。
*/
public static void main(String[] args) throws Exception {
// 创建一个流式执行环境,这是Flink程序的基础,用来配置和启动执行。
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取指定的相对路径("input/word")的文本文件,每一行数据将作为字符串单独处理。
DataStreamSource<String> lineStreamSource = senv.readTextFile("input/word");
// 对读取到的每行数据进行切分,将每一行的单词分割出来,并为每个单词计数初始化为1,
// 然后将单词与计数值封装成Tuple2类型的数据流。
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne =
lineStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
// 创建一个包含当前单词及其计数值1的元组
Tuple2<String, Integer> tuple2WordTuple = Tuple2.of(word, 1);
// 收集这个元组到数据流中,以便后续处理
collector.collect(tuple2WordTuple);
}
}
});
// 根据单词(即元组中的第一个元素f0)进行分组,为每个不同的单词创建一个独立的分组流。
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKey =
wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
// 返回元组的第一个元素(单词)作为分组的键
return stringIntegerTuple2.f0;
}
});
// 在每个分组内对第二个元素(计数值)进行求和,从而实现单词计数。
SingleOutputStreamOperator<Tuple2<String,Integer>> result = wordAndOneKey.sum(1);
// 打印最终的统计结果到控制台。
result.print();
// 执行流处理任务,启动Flink程序。
senv.execute();
}
}总结
以上是基于javaidea建立maven项目进行的简单词频统计,包括对文件的读取,分词,组合以及统计单词出现的个数,最后返回统计结果。整体代码结构简单易懂,可用于基本的flink使用的入门参考。















 3692
3692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









