







 本文分享了使用Python爬虫抓取货运信息网站数据的实战经验,详细介绍了利用requests和BeautifulSoup库从运满满网站抓取货物信息、车型、时间等数据的过程。
本文分享了使用Python爬虫抓取货运信息网站数据的实战经验,详细介绍了利用requests和BeautifulSoup库从运满满网站抓取货物信息、车型、时间等数据的过程。
爬虫
- 周末没事想试一下Python的爬虫,跟着网上试了一个爬虎扑的
原文虎扑爬虫 - 然后试了一下一个货运信息网站,运满满,还专门安装了pycharm,大点的编译器,用来做项目。毕竟刚学Python,所以一直用的IDLE
import requests#库
from bs4 import BeautifulSoup#BeautifulSoup爬虫经常用的,具体不太明白
headers = {#用来模拟是浏览器正常发出的请求,每个浏览器都不同
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
url = 'http://www.ymm56.com/peihuo/sd_370000-gz_520000/' # 要爬的网址,
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text,'lxml')
news_list = soup.find('div', {'id': 'app'})#首先
news = news_list.find('section',{'class':'peihuo-cargolist grid-container'})
news2 = news.find_all('article',{'class':'grid-50'})
dizhi = []
chexing = []
news_title = []
news_source = []
time_=[]
for i in news2:
try:
#标题title = i.find('h4').get_text().strip()
#来源
xinxi= i.find_all('p',{'class':'grid-33 tablet-grid-33 mobile-grid-50'})
time=xinxi[4].find('font').get_text().strip()
#time = i.find('p',{'class':'grid-33 tablet-grid-33 mobile-grid-50'}).find('font').get_text().strip()
chexing_ =i.find('p',{'class':'grid-33 tablet-grid-33 mobile-grid-50'}).find('font').get_text().strip()
sourse = i.find('h3',{'class':'grid-100'}).find('a').get_text().strip()
chexing.append(chexing_)
news_source.append(sourse)
time_.append(time)
print('时间',time)
print('车型:',chexing_)
print('地址: ',sourse)
print()
except AttributeError as e:
continue
news_list = soup.find(‘div’, {‘id’: ‘app’})#首先这个是一个大的范围,包扩多条信息
可以看到,当鼠标放在这一行,网页分会高亮。
然后继续往下找
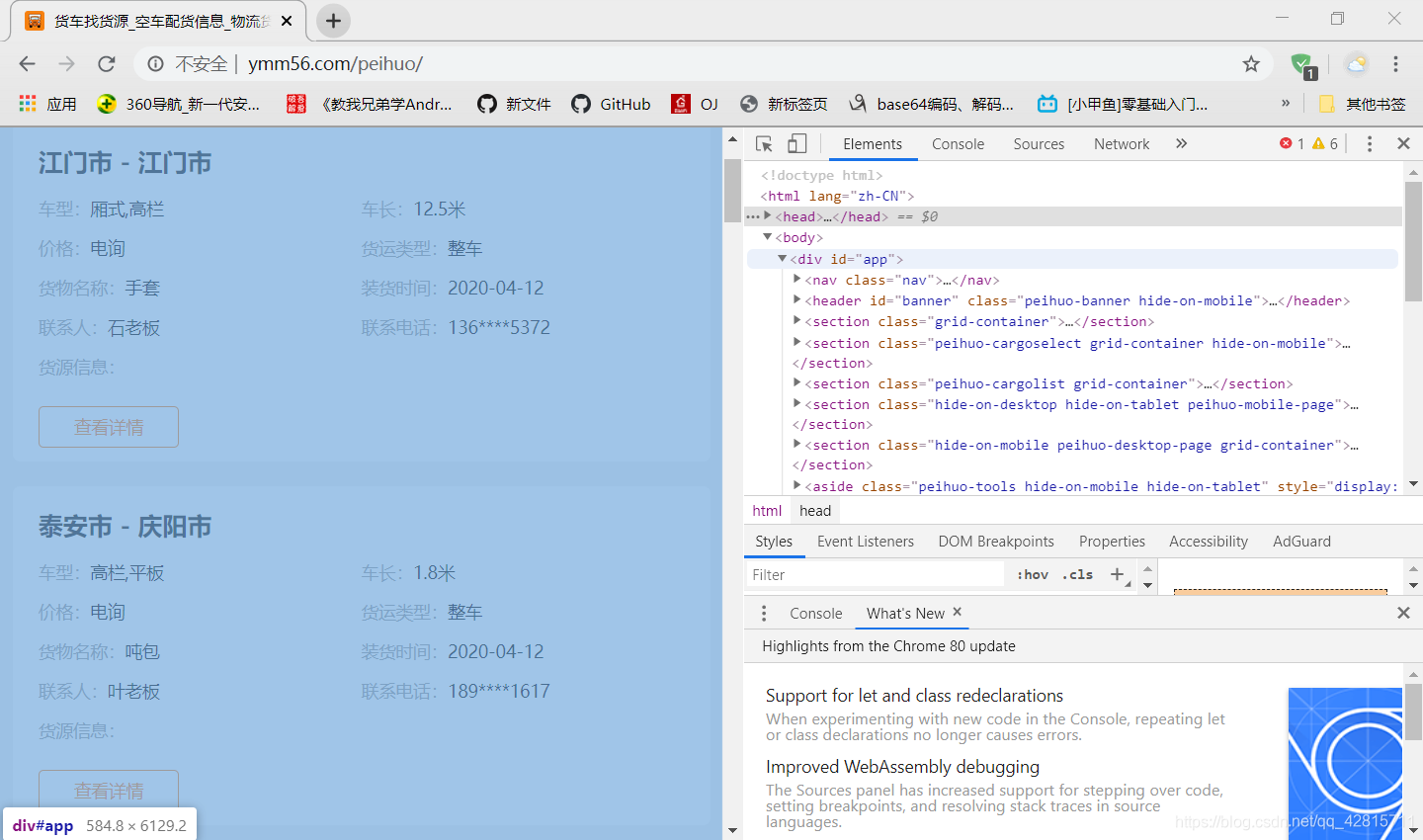
news = news_list.find(‘section’,{‘class’:‘peihuo-cargolist grid-container’})
div里面的分标签货物信息在section class等于peihuo-cargolist grid-container的,然后里面的每条article就是每个货的信息
然后往下就要找所有的article,所以用了find_all
news2 = news.find_all(‘article’,{‘class’:‘grid-50’})
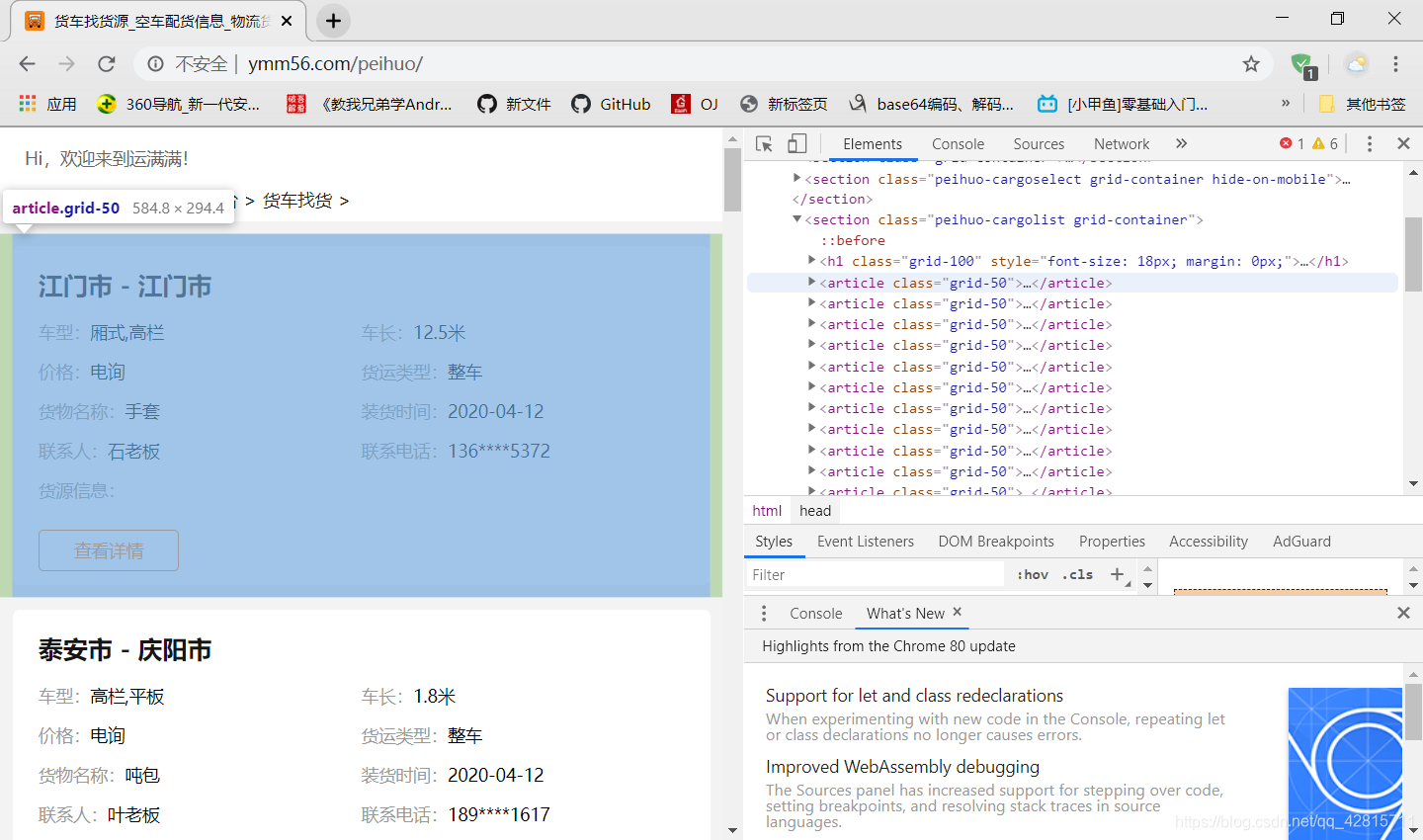
-
再往下就是article里的各种信息,车型,货物种类或者时间什么的,
-

-
直接用for遍历所有的article
因为在article的子标签里(没学过HTML),有多个p class 等于grid-33 tablet-grid-33 mobile-grid-50
所以也直接用find_all来找所有的相同的标签,然后第四个是时间就是

然后差不多就能看懂了吧 -
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
- get_text()清空所有html标签元素
之后就会返回干净的文字

















 3289
3289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









