import threading
import time
def countNum(n): # 定义某个线程要运行的函数
print("running on number:%s" %n)
time.sleep(3)
if __name__ == '__main__':
t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例
t2 = threading.Thread(target=countNum,args=(34,))
t1.start() #启动线程
t2.start()
print("ending!")
2.1.2 Thread类继承式创建
#继承Thread式创建
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num=num
def run(self):
print("running on number:%s" %self.num)
time.sleep(3)
t1=MyThread(56)
t2=MyThread(78)
t1.start()
t2.start()
print("ending")
2.2 Thread类的实例方法
2.2.1 join()和setDaemon()
# join():在子线程完成运行之前,这个子线程的父线程将一直被阻塞。
# setDaemon(True):
'''
将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。
当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦'''
import threading
from time import ctime,sleep
import time
def Music(name):
print ("Begin listening to {name}. {time}".format(name=name,time=ctime()))
sleep(3)
print("end listening {time}".format(time=ctime()))
def Blog(title):
print ("Begin recording the {title}. {time}".format(title=title,time=ctime()))
sleep(5)
print('end recording {time}'.format(time=ctime()))
threads = []
t1 = threading.Thread(target=Music,args=('FILL ME',))
t2 = threading.Thread(target=Blog,args=('',))
threads.append(t1)
threads.append(t2)
if __name__ == '__main__':
#t2.setDaemon(True)
for t in threads:
#t.setDaemon(True) #注意:一定在start之前设置
t.start()
#t.join()
#t1.join()
#t2.join() # 考虑这三种join位置下的结果?
print ("all over %s" %ctime())
daemon
A boolean value indicating whether this thread is a daemon thread (True) or not (False). This must be set before start() is called, otherwise RuntimeError is raised. Its initial value is inherited from the creating thread; the main thread is not a daemon thread and therefore all threads created in the main thread default to daemon = False.
The entire Python program exits when no alive non-daemon threads are left.
当daemon被设置为True时,如果主线程退出,那么子线程也将跟着退出,
反之,子线程将继续运行,直到正常退出。
'''
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对Python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。 GIL:在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。 在调用任何Python C API之前,要先获得GIL GIL缺点:多处理器退化为单处理器;优点:避免大量的加锁解锁操作
2.3.1 GIL的早期设计
Python支持多线程,而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
#coding:utf8
from threading import Thread
import time
def counter():
i = 0
for _ in range(50000000):
i = i + 1
return True
def main():
l=[]
start_time = time.time()
for i in range(2):
t = Thread(target=counter)
t.start()
l.append(t)
t.join()
# for t in l:
# t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
'''
py2.7:
串行:25.4523348808s
并发:31.4084379673s
py3.5:
串行:8.62115597724914s
并发:8.99609899520874s
'''
#coding:utf8
from multiprocessing import Process
import time
def counter():
i = 0
for _ in range(40000000):
i = i + 1
return True
def main():
l=[]
start_time = time.time()
for _ in range(2):
t=Process(target=counter)
t.start()
l.append(t)
#t.join()
for t in l:
t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
'''
py2.7:
串行:6.1565990448 s
并行:3.1639978885 s
py3.5:
串行:6.556925058364868 s
并发:3.5378448963165283 s
'''
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
#num-=1
temp=num
time.sleep(0.1)
num =temp-1 # 对此公共变量进行-1操作
num = 100 #设定一个共享变量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('Result: ', num)
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s',)
def worker(event):
logging.debug('Waiting for redis ready...')
event.wait()
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
def main():
readis_ready = threading.Event()
t1 = threading.Thread(target=worker, args=(readis_ready,), name='t1')
t1.start()
t2 = threading.Thread(target=worker, args=(readis_ready,), name='t2')
t2.start()
logging.debug('first of all, check redis server, make sure it is OK, and then trigger the redis ready event')
time.sleep(3) # simulate the check progress
readis_ready.set()
if __name__=="__main__":
main()
def worker(event):
while not event.is_set():
logging.debug('Waiting for redis ready...')
event.wait(2)
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
import threading
import time
semaphore = threading.Semaphore(5)
def func():
if semaphore.acquire():
print (threading.currentThread().getName() + ' get semaphore')
time.sleep(2)
semaphore.release()
for i in range(20):
t1 = threading.Thread(target=func)
t1.start()
应用:连接池
思考:与Rlock的区别?
2.8 队列(queue)
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
'''
Python Queue模块有三种队列及构造函数:
1、Python Queue模块的FIFO队列先进先出。 class queue.Queue(maxsize)
2、LIFO类似于堆,即先进后出。 class queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class queue.PriorityQueue(maxsize)
import queue
Multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency,effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. Due to this, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine. It runs on both Unix and Windows.
# Process类调用
from multiprocessing import Process
import time
def f(name):
print('hello', name,time.ctime())
time.sleep(1)
if __name__ == '__main__':
p_list=[]
for i in range(3):
p = Process(target=f, args=('alvin:%s'%i,))
p_list.append(p)
p.start()
for i in p_list:
p.join()
print('end')
# 继承Process类调用
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self):
super(MyProcess, self).__init__()
# self.name = name
def run(self):
print ('hello', self.name,time.ctime())
time.sleep(1)
if __name__ == '__main__':
p_list=[]
for i in range(3):
p = MyProcess()
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('end')
3.2 process类
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
from multiprocessing import Process, Manager
def f(d, l,n):
d[n] = n
d["name"] ="alvin"
l.append(n)
#print("l",l)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
p_list = []
for i in range(10):
p = Process(target=f, args=(d,l,i))
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
from multiprocessing import Pool
import time
def foo(args):
time.sleep(1)
print(args)
if __name__ == '__main__':
p = Pool(5)
for i in range(30):
p.apply_async(func=foo, args= (i,))
p.close() # 等子进程执行完毕后关闭线程池
# time.sleep(2)
# p.terminate() # 立刻关闭线程池
p.join()
import gevent
import time
def foo():
print("running in foo")
gevent.sleep(2)
print("switch to foo again")
def bar():
print("switch to bar")
gevent.sleep(5)
print("switch to bar again")
start=time.time()
gevent.joinall(
[gevent.spawn(foo),
gevent.spawn(bar)]
)
print(time.time()-start)
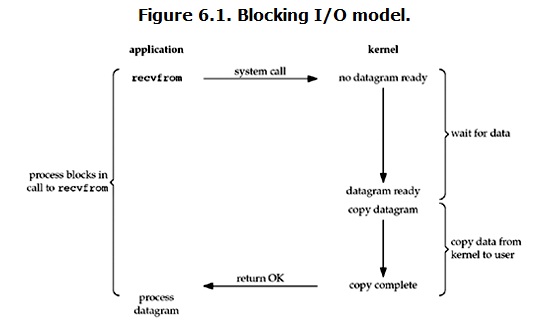
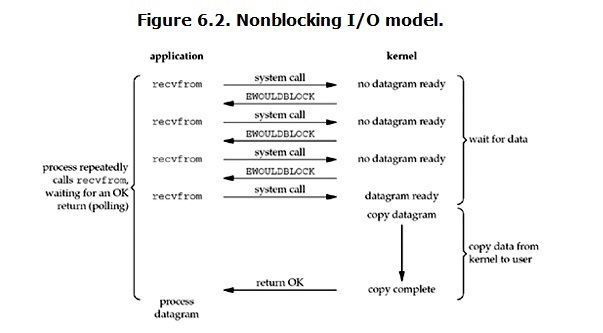
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。 先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
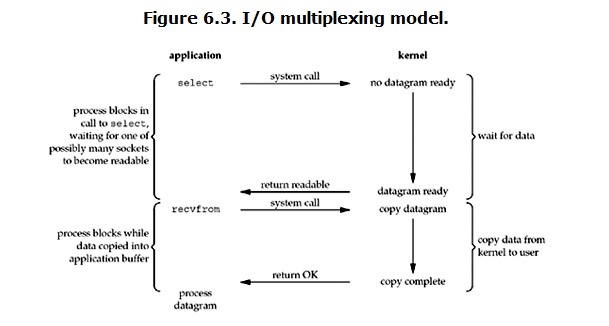
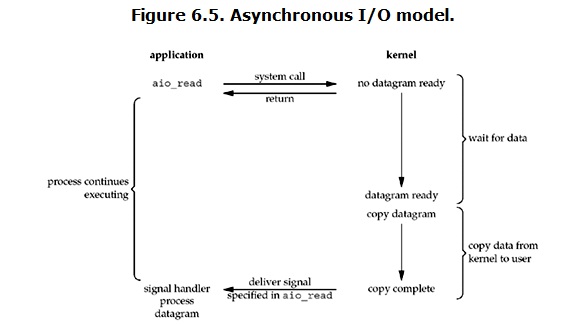
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的: A synchronous I/O operation causes the requesting process to be blocked until that I/O operationcompletes; An asynchronous I/O operation does not cause the requesting process to be blocked; 两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
import threading
import time
def countNum(n): # 定义某个线程要运行的函数
print("running on number:%s" %n)
time.sleep(3)
if __name__ == '__main__':
t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例
t2 = threading.Thread(target=countNum,args=(34,))
t1.start() #启动线程
t2.start()
print("ending!")
2.1.2 Thread类继承式创建
#继承Thread式创建
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num=num
def run(self):
print("running on number:%s" %self.num)
time.sleep(3)
t1=MyThread(56)
t2=MyThread(78)
t1.start()
t2.start()
print("ending")
2.2 Thread类的实例方法
2.2.1 join()和setDaemon()
# join():在子线程完成运行之前,这个子线程的父线程将一直被阻塞。
# setDaemon(True):
'''
将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。
当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦'''
import threading
from time import ctime,sleep
import time
def Music(name):
print ("Begin listening to {name}. {time}".format(name=name,time=ctime()))
sleep(3)
print("end listening {time}".format(time=ctime()))
def Blog(title):
print ("Begin recording the {title}. {time}".format(title=title,time=ctime()))
sleep(5)
print('end recording {time}'.format(time=ctime()))
threads = []
t1 = threading.Thread(target=Music,args=('FILL ME',))
t2 = threading.Thread(target=Blog,args=('',))
threads.append(t1)
threads.append(t2)
if __name__ == '__main__':
#t2.setDaemon(True)
for t in threads:
#t.setDaemon(True) #注意:一定在start之前设置
t.start()
#t.join()
#t1.join()
#t2.join() # 考虑这三种join位置下的结果?
print ("all over %s" %ctime())
daemon
A boolean value indicating whether this thread is a daemon thread (True) or not (False). This must be set before start() is called, otherwise RuntimeError is raised. Its initial value is inherited from the creating thread; the main thread is not a daemon thread and therefore all threads created in the main thread default to daemon = False.
The entire Python program exits when no alive non-daemon threads are left.
当daemon被设置为True时,如果主线程退出,那么子线程也将跟着退出,
反之,子线程将继续运行,直到正常退出。
'''
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对Python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。 GIL:在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。 在调用任何Python C API之前,要先获得GIL GIL缺点:多处理器退化为单处理器;优点:避免大量的加锁解锁操作
2.3.1 GIL的早期设计
Python支持多线程,而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
#coding:utf8
from threading import Thread
import time
def counter():
i = 0
for _ in range(50000000):
i = i + 1
return True
def main():
l=[]
start_time = time.time()
for i in range(2):
t = Thread(target=counter)
t.start()
l.append(t)
t.join()
# for t in l:
# t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
'''
py2.7:
串行:25.4523348808s
并发:31.4084379673s
py3.5:
串行:8.62115597724914s
并发:8.99609899520874s
'''
#coding:utf8
from multiprocessing import Process
import time
def counter():
i = 0
for _ in range(40000000):
i = i + 1
return True
def main():
l=[]
start_time = time.time()
for _ in range(2):
t=Process(target=counter)
t.start()
l.append(t)
#t.join()
for t in l:
t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
'''
py2.7:
串行:6.1565990448 s
并行:3.1639978885 s
py3.5:
串行:6.556925058364868 s
并发:3.5378448963165283 s
'''
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
#num-=1
temp=num
time.sleep(0.1)
num =temp-1 # 对此公共变量进行-1操作
num = 100 #设定一个共享变量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('Result: ', num)
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s',)
def worker(event):
logging.debug('Waiting for redis ready...')
event.wait()
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
def main():
readis_ready = threading.Event()
t1 = threading.Thread(target=worker, args=(readis_ready,), name='t1')
t1.start()
t2 = threading.Thread(target=worker, args=(readis_ready,), name='t2')
t2.start()
logging.debug('first of all, check redis server, make sure it is OK, and then trigger the redis ready event')
time.sleep(3) # simulate the check progress
readis_ready.set()
if __name__=="__main__":
main()
def worker(event):
while not event.is_set():
logging.debug('Waiting for redis ready...')
event.wait(2)
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
import threading
import time
semaphore = threading.Semaphore(5)
def func():
if semaphore.acquire():
print (threading.currentThread().getName() + ' get semaphore')
time.sleep(2)
semaphore.release()
for i in range(20):
t1 = threading.Thread(target=func)
t1.start()
应用:连接池
思考:与Rlock的区别?
2.8 队列(queue)
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
1、Python Queue模块的FIFO队列先进先出。 class queue.Queue(maxsize) 2、LIFO类似于堆,即先进后出。 class queue.LifoQueue(maxsize) 3、还有一种是优先级队列级别越低越先出来。 class queue.PriorityQueue(maxsize)
Multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency,effectively side-stepping the Global Interpreter Lock by using subprocesses instead of threads. Due to this, the multiprocessing module allows the programmer to fully leverage multiple processors on a given machine. It runs on both Unix and Windows.
# Process类调用
from multiprocessing import Process
import time
def f(name):
print('hello', name,time.ctime())
time.sleep(1)
if __name__ == '__main__':
p_list=[]
for i in range(3):
p = Process(target=f, args=('alvin:%s'%i,))
p_list.append(p)
p.start()
for i in p_list:
p.join()
print('end')
# 继承Process类调用
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self):
super(MyProcess, self).__init__()
# self.name = name
def run(self):
print ('hello', self.name,time.ctime())
time.sleep(1)
if __name__ == '__main__':
p_list=[]
for i in range(3):
p = MyProcess()
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('end')
3.2 process类
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
from multiprocessing import Process, Manager
def f(d, l,n):
d[n] = n
d["name"] ="alvin"
l.append(n)
#print("l",l)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
p_list = []
for i in range(10):
p = Process(target=f, args=(d,l,i))
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
from multiprocessing import Pool
import time
def foo(args):
time.sleep(1)
print(args)
if __name__ == '__main__':
p = Pool(5)
for i in range(30):
p.apply_async(func=foo, args= (i,))
p.close() # 等子进程执行完毕后关闭线程池
# time.sleep(2)
# p.terminate() # 立刻关闭线程池
p.join()
import gevent
import time
def foo():
print("running in foo")
gevent.sleep(2)
print("switch to foo again")
def bar():
print("switch to bar")
gevent.sleep(5)
print("switch to bar again")
start=time.time()
gevent.joinall(
[gevent.spawn(foo),
gevent.spawn(bar)]
)
print(time.time()-start)
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。 先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的: A synchronous I/O operation causes the requesting process to be blocked until that I/O operationcompletes; An asynchronous I/O operation does not cause the requesting process to be blocked; 两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。


































 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









