







高分期刊中频频登场的 方差分解分析(VPA) 到底是啥?这个分析可能还有很多同学没接触过。目前,群落分析中常见的环境因子分析包括典范对应分析(canonical correspondence analysis)和冗余分析 (Redundancy analysis),这两种类型分析都是基于降维的思想,将样本、物种、环境因子的信息映射到二维平面上,从而判断三者间的关系,可用于发现对群落结构有影响的环境变量。而VPA分析可以看做是CCA/RDA分析的一种升级。用几组解释变量(如环境、气候、土壤因子等数据)来共同解释一组响应变量的变化(如微生物数据),当我们需要某个解释变量所能够解释的方差变异程度信息(即某个环境因子对群落结构变化的贡献度)时,就可以采用VPA分析加以补充。 但是需要注意的是 ,该分析主要用于矩阵之间的评估(也就是多变量,多行多列的样本),如果是单变量不建议用该方法,需要选择其他途经!
🐣 一、方差分解分析的简介
方差分解的数学原理,可以参考该链接,有比较清晰且易理解的介绍方差分解原理
从土壤微生物生态领域的角度:就是将每个解释变量(环境因子)进行独立运行CCA或RDA,获得每个解释变量(环境因子)对于响应变量(微生物群落)的方差变异的解释贡献度,之后通过将多组数据取交并集的方式获得每个解释变量(环境因子)的独立解释贡献度以及环境因子共同解释的贡献度。

🐤 二、VPA分析的R语言实现过程
这里主要到"vegan"包中的varpart()函数并使用自带的数据集来进行VPA分析,并使用plot以图形式输出结果。温馨提示:关于VPA分析时所用的环境因子的分类是可以根据你自己选择来划分的,例如现有气候因子年均温、年降雨量;土壤理化因子有pH、SOC、TN、TP、TK、含水率、阳离子交换量。响应变量为土壤微生物丰度数据。因此,我将所有变量划分为两个解释变量:气候和土壤理化。
加载自带数据集 “mite”、“mite.env”、“mite.pcnm”。其中mite为物种丰度数据,mite.env和mite.pcnm为环境因子数据。
# intall.packages("vegan")
# 加载vegan包
library(vegan)
# 读取vegan包自带数据集
data(mite)
head(mite)
# Brachy PHTH HPAV RARD SSTR Protopl MEGR MPRO TVIE HMIN HMIN2 NPRA TVEL ONOV SUCT LCIL Oribatl1 Ceratoz1 PWIL Galumna1 Stgncrs2
# 1 17 5 5 3 2 1 4 2 2 1 4 1 17 4 9 50 3 1 1 8 0
# 2 2 7 16 0 6 0 4 2 0 0 1 3 21 27 12 138 6 0 1 3 9
# 3 4 3 1 1 2 0 3 0 0 0 6 3 20 17 10 89 3 0 2 1 8
# 4 23 7 10 2 2 0 4 0 1 2 10 0 18 47 17 108 10 1 0 1 2
# 5 5 8 13 9 0 13 0 0 0 3 14 3 32 43 27 5 1 0 5 2 1
# 6 19 7 5 9 3 2 3 0 0 20 16 2 13 38 39 3 5 0 1 1 8
# HRUF Trhypch1 PPEL NCOR SLAT FSET Lepidzts Eupelops Miniglmn LRUG PLAG2 Ceratoz3 Oppiminu Trimalc2
# 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 2 1 1 1 2 2 2 1 0 0 0 0 0 0 0
# 3 0 3 0 2 0 8 0 0 0 0 0 0 0 0
# 4 1 2 1 3 2 12 0 0 0 0 0 0 0 0
# 5 0 1 0 0 0 12 2 0 0 0 0 0 0 0
# 6 0 4 0 1 0 10 0 0 0 0 0 0 0 0
data("mite.env")
head(mite.env)
# SubsDens WatrCont Substrate Shrub Topo
# 1 39.18 350.15 Sphagn1 Few Hummock
# 2 54.99 434.81 Litter Few Hummock
# 3 46.07 371.72 Interface Few Hummock
# 4 48.19 360.50 Sphagn1 Few Hummock
# 5 23.55 204.13 Sphagn1 Few Hummock
# 6 57.32 311.55 Sphagn1 Few Hummock
data("mite.pcnm")
head(mite.pcnm)# V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
# 1 0.01936957 -0.03564740 -0.004243617 0.013606215 -0.05189017 -0.03474468 0.04783919 -0.026592487 0.151774834 -0.12300738
# 2 0.02327134 -0.04809322 -0.004319021 -0.004129358 -0.06717623 -0.05795898 0.16017261 0.001190912 0.195925637 -0.24690953
# 3 0.02553531 -0.05844679 -0.003091072 -0.025699042 -0.07594608 -0.07619106 0.22316903 0.038178673 0.155709724 -0.21935603
# 4 0.03065998 -0.07805595 -0.001108683 -0.056124820 -0.08546514 -0.09535844 0.27612594 0.070969519 0.131881864 -0.19932613
# 5 0.03105726 -0.08758357 0.003294018 -0.092445741 -0.05775704 -0.08126478 0.21478882 0.098269886 -0.068740442 0.05495368
# 6 0.04127819 -0.12060082 0.004167658 -0.126085915 -0.10026023 -0.13218923 0.35013357 0.147698598 0.005177207 -0.02570014
# V11 V12 V13 V14 V15 V16 V17 V18 V19 V20
# 1 -0.26517774 0.023371850 0.005195660 0.3626868085 0.34076414 0.170882098 -0.059228827 -0.03939074 -0.11782730 -0.01147239
# 2 -0.37584499 -0.075700042 0.022159511 0.0006411373 0.01202768 0.087636037 -0.001942823 0.05588741 -0.22830818 -0.15116529
# 3 -0.28061570 -0.099198666 0.008921100 -0.2035796515 -0.18501351 -0.007381247 0.027437893 0.06861847 0.02131584 -0.02865909
# 4 -0.23039945 -0.102046893 0.004433267 -0.2052618137 -0.16789083 0.009568853 0.007357390 0.01615628 -0.01806509 -0.03897287
# 5 0.14857244 0.009435476 0.014393038 0.0297003749 0.07653256 -0.032179051 -0.137244148 -0.29799001 0.34456985 0.23947188
# 6 0.05764401 -0.042577994 -0.030850935 -0.1161627137 -0.08461676 -0.013815945 -0.005356515 -0.01820232 0.25465418 0.17103563
# V21 V22
# 1 -0.21718792 -0.239723133
# 2 -0.05943333 -0.138925891
# 3 0.08954033 0.074659665
# 4 0.11164163 0.136237788
# 5 0.03596404 -0.047024199
# 6 -0.02836968 -0.004707296
注意,数据格式的模仿:数据集的行为样本编号,列为物种或者环境变量。
接着,我们利用varpart()函数进行拟合模型。由于mite.pcnm的数据集太大了,我们就取了取了前5个作为第二个环境因子。
# 拟合模型
?varpart # 简单了解函数用法
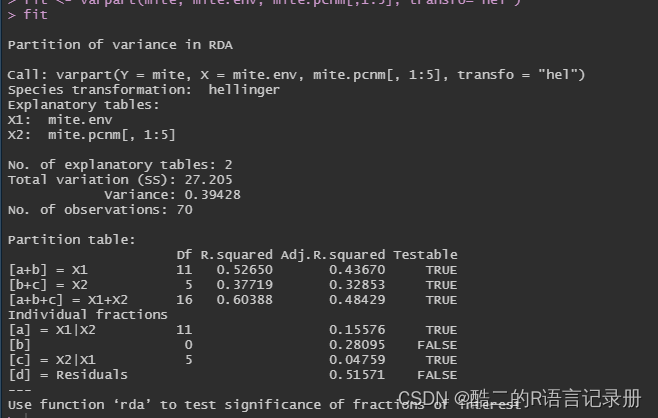
fit <- varpart (mite, mite.env, mite.pcnm[,1:5], transfo="hel")
fit
进行VPA分析时,需要记住:第一个数据物种数据,之后两个数据分别代表不同的环境变量,transfo表示对数据进行转换,hel为hellinger转换,避免“弓形效应”。
第一个函数介绍的结果: 大家可以利用help查阅相关资料;
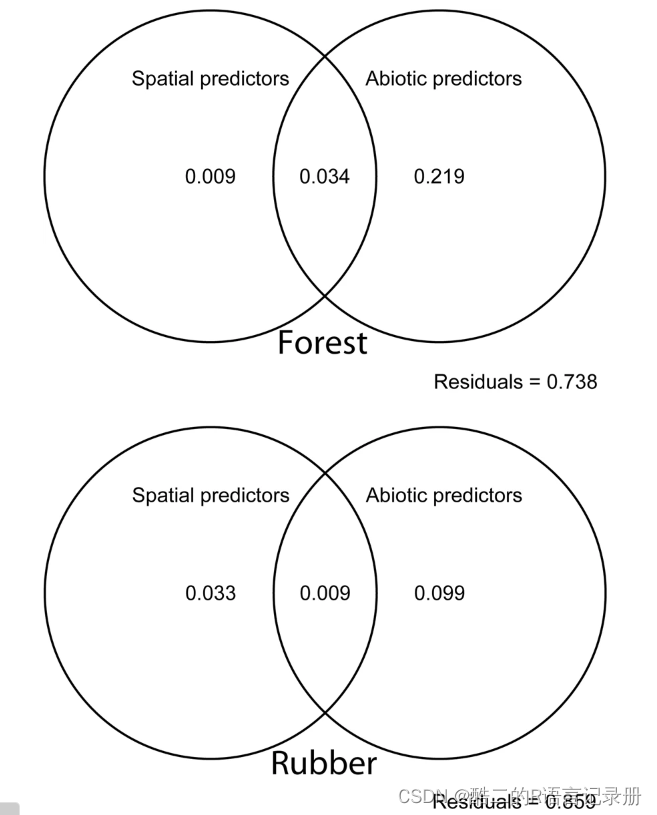
为了让大家更好的理解VPA分析的结果,这里举例解读
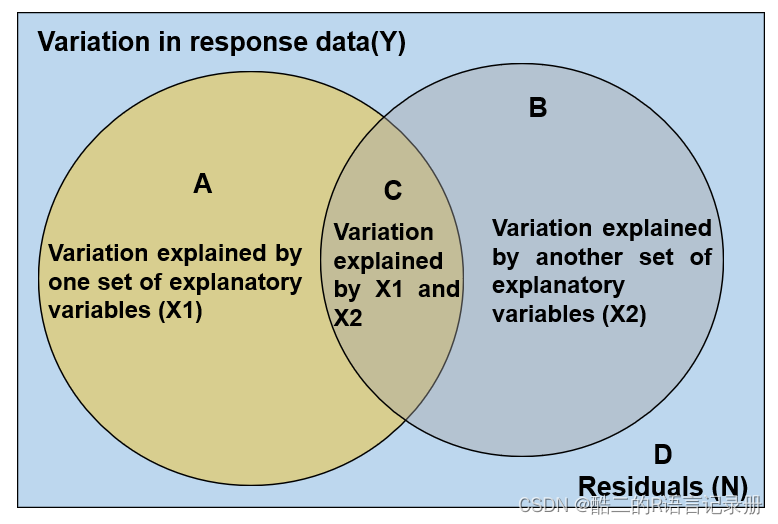
如图所示微生物群落的方差总体解释量为Y,检测了两个环境因子数据X1、X2。VPA是将两个环境因子的数据各自独立运行RDA分析(RDA则为标准化后的解释变量对响应变量逐一进行多元回归分析,获得拟合值、残差值,最终整合成为拟合值矩阵,该矩阵进行PCA、然后排序所得结果),获得每个环境因子对于群落整体变差校正解释量,再运行两者共同存在时获得校正后解释度数据R方,具体得到如下结果:
-
[独立运行X1的RDA]:A+C部分解释贡献度占比
-
[独立运行X2的RDA]:B+C部分解释贡献度占比
-
[共同运行X1和X2的RDA]:A+B+C部分解释贡献度占比
最后可以得到:
[A]= [共同运行X1、X2的RDA]- [独立运行X2的RDA]
[B]= [共同运行X1、X2的RDA]- [独立运行X1的RDA]
[C]= [共同运行X1、X2的RDA]- [A]- [B]
[未被这两种环境因子解释到的残差(D)]=Y- [A]-[B]- [C]
第二个结果:
使用plot函数可视化得到的VPA分析结果:
plot(fit, bg = c("hotpink","skyblue")) # bg表示两个变量的背景颜色
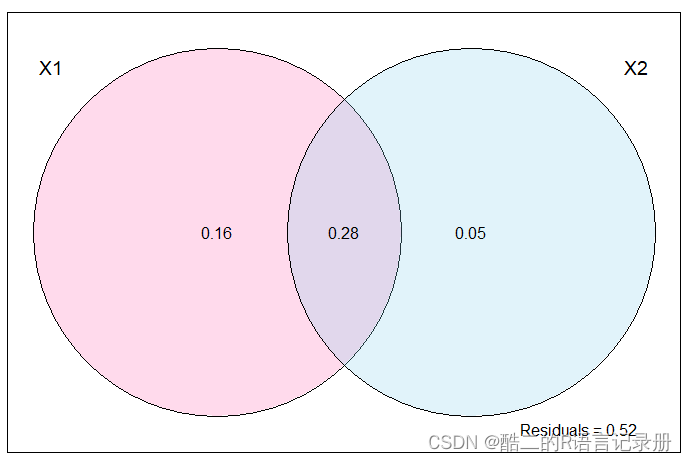
通过维恩图的展示就可以清楚的看到每种环境因子对于总体变异的解释程度、共有解释程度以及残差。需要注意的事,图中共有的部分产生的原因在于环境因子数据对微生物解释存在着共线性而产生,如果环境因子完全相互独立理论上重叠部分=0;此外,如果解释贡献度出现负数,则说明这组环境因子数据对群落数据方差变化解释程度比使用随机变量的解释程度还要低,一般当做贡献度为0进行解释,建议在选择环境因子时减少共线性程度较高的环境因子以及贡献度为负数的环境因子数据,以保证结果准确。
🦅 三、VPA分析中不同变量的显著性检验
实际上RDA和方差分解的结果是相同的(这里不做展示),可以发现环境X1与X2共同解释了26% 的群落结构变异,其中X1解释了 16% 的群落组成变异,气候解释了5% 的群落组成变异。然而对于二者是否显著,是可以做进一步检验。特殊情况,关于冗余分析(RDA)中环境因子共同解释部分出现负值的说明。我推荐赖江山老师对于该结果的深刻解读为什么VPA分析的结果会出现负值。
# 首先将两个环境因子合并
mite.total <- data.frame(mite.env,mite.pcnm[,1:5])
# 描述partial RDA的公式
# X1
formula_X1 <- formula(mite ~ SubsDens+WatrCont+Substrate+Shrub+Topo+ Condition(V1)+Condition(V2)+Condition(V3)+Condition(V4)+Condition(V5))
# X2
formula_X2 <- formula(mite ~ Condition(SubsDens)+Condition(WatrCont)+Condition(Substrate)+Condition(Shrub)+Condition(Topo)+V1+V2+V3+V4+V5)
# X1和X2
formula_X1X2 <- formula(mite ~ SubsDens:WatrCont:Substrate:Shrub:Topo:V1:V2:V3:V4:V5)
# 利用partial RDA进行999次的置换检验,最后得出模型的显著性
anova(rda(formula_X1, data = mite.total))
anova(rda(formula_X2, data = mite.total))
anova(rda(formula_X1X2, data = mite.total))
其中:Condition是表示控制一部分变量,只探究非condition部分的变量,即控制mite.pcnm则只探究mite.env。反之,探究另一个环境因子。特别强调:最后一种情况是我理解上的共同解释部分的显著性检验,但是对错与否目前我也没找到正确答案。这里需要更多的统计学专业的同学给出建议来完善。
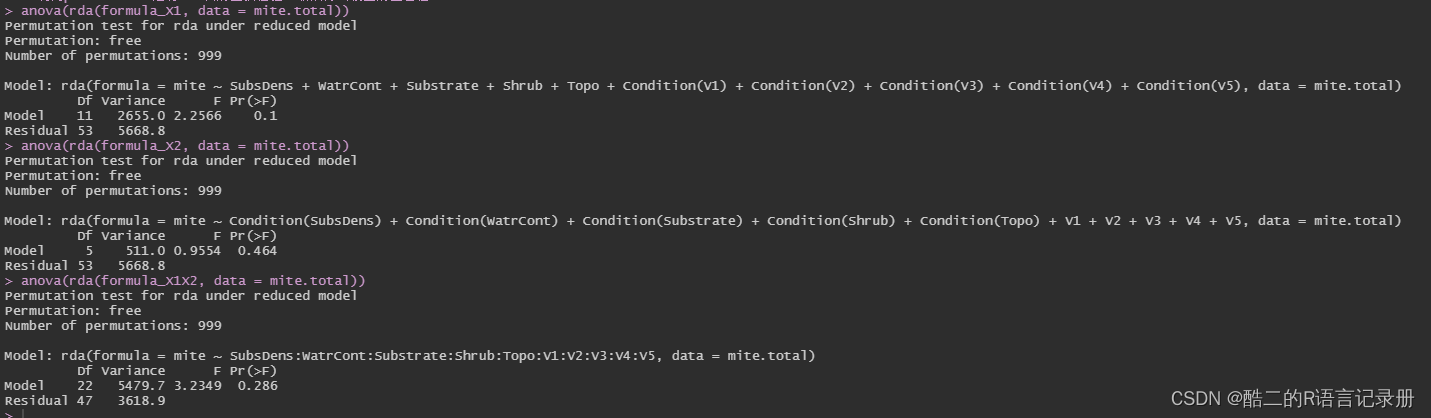
因此,结论是两个环境因子对物种的解释及其共同解释均不显著。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











