







 本文详细介绍了AlexNet卷积神经网络,包括其在2012年ImageNet比赛中的突出表现,创新点如多GPU训练、数据增强、ReLU激活函数等。此外,还阐述了网络结构,并提供了Keras实现的代码示例。
本文详细介绍了AlexNet卷积神经网络,包括其在2012年ImageNet比赛中的突出表现,创新点如多GPU训练、数据增强、ReLU激活函数等。此外,还阐述了网络结构,并提供了Keras实现的代码示例。
✨博客主页:王乐予🎈
✨年轻人要:Living for the moment(活在当下)!💪
🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】
目录
😺一、网络简介
我们知道LeNet是第一个经典的卷积神经网络,但第一个走进大家视线的是AlexNet!
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey E. Hinton三人提出的,文章发表于2012年,AlexNet网络拿到了ImageNet LSVRC-2010比赛的冠军(ImageNet LSVRC-2010比赛要求参赛者在具有1.2 million的高分辨率图像数据集中进行1000分类任务)。文中并没有对所提网络起名字,但因为该网络具有的影响力,后人也就逐渐的以第一作者的名字为网络命名。
AlexNet具有60 million的参数和650000的神经元,测试集的top-1和top-5的错误率为37.5%和17.0%,
论文链接:ImageNet Classification with Deep Convolutional Neural Networks
😺二、网络创新点
- 多GPU协同运算
- 使用ReLU激活函数
- 使用Local Response Normalization(局部响应归一化)
- 使用dropout正则化
- 通过数据增强的方式增加数据量
😺三、网络结构
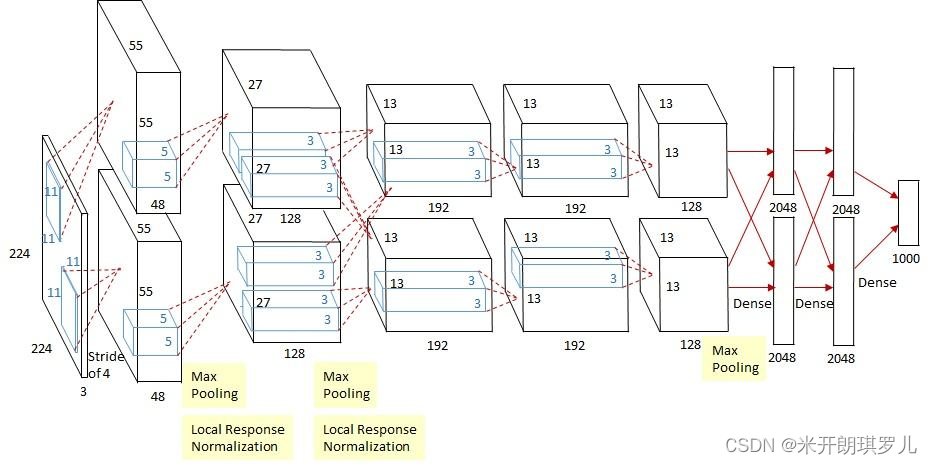
🐶3.1 网络立体图结构
🐶3.2 网络平面图结构

😺四、网络结构详解
论文第5页Figure 2中指出:
An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities between the GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts at the bottom. The GPUs communicate only at certain layers.
也就是说:由于网络分上下两个部分,这两个部分是在两块GPU中运行的,只有在特定层中两块GPU才发生交互。
此外两块GPU训练的网络也并非完全一致,具体的网络结构参数与张量流过程见下图:
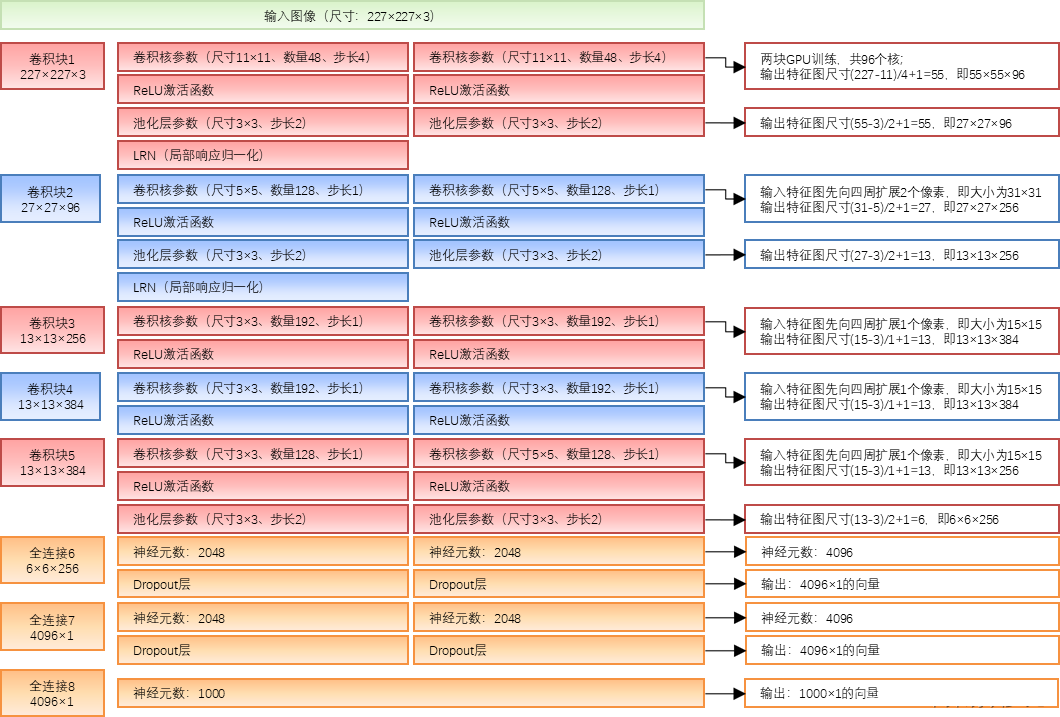
参考:https://blog.csdn.net/chenyuping333/article/details/82178335
😺五、AlexNet较之前神经网络的改进
🐶5.1 多GPU并行训练
AlexNet将网络分为两部分,这两部分由不同的GPU训练,大幅提高了训练速度。
🐶5.2 使用数据增强
常用的数据增强方法有:水平翻转、随机裁剪、平移变换、颜色、光照、对比度变换。
🐶5.3 使用Dropout
AlexNet使用随机失活神经元的方式有效防止过拟合情况的产生。
🐶5.4 使用ReLU激活函数
使用ReLU激活函数代替了传统的sigmoid或tanh激活函数。
关于激活函数的介绍,详见另一篇文章:
🐶5.5 使用LRN
参考了生物学上神经网络的侧抑制的功能,做了临近数据归一化,提高来模型的泛化能力,但这一功能的作用有争议。
🐶5.6 使用Overlapping Pooling
重叠池化(Overlapping Pooling)减少了系统的过拟合,减少了top-5和top-1错误率的0.4%和0.3%。
参考:https://blog.csdn.net/dcrmg/article/details/79241211?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-5.essearch_pc_relevant&spm=1001.2101.3001.4242.4
😺六、Keras实现
🐶6.1 程序编写
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, Dropout, MaxPooling2D, BatchNormalization
model = Sequential()
model.add(Conv2D(96, (11, 11), strides=(4, 4), input_shape=(227, 227, 3), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
print(model.summary())
🐶6.2 打印模型信息
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 57, 57, 96) 34944
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 28, 28, 96) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 28, 28, 96) 384
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 256) 614656
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 256) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 13, 13, 256) 1024
_________________________________________________________________
conv2d_2 (Conv2D) (None, 13, 13, 384) 885120
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 384) 1327488
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 256) 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 9216) 0
_________________________________________________________________
dense (Dense) (None, 4096) 37752832
_________________________________________________________________
dropout (Dropout) (None, 4096) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 40970
=================================================================
Total params: 58,323,722
Trainable params: 58,323,018
Non-trainable params: 704
_________________________________________________________________



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











