







✨博客主页:王乐予🎈
✨年轻人要:Living for the moment(活在当下)!💪
🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】
😺一、MediaPipe概述
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。
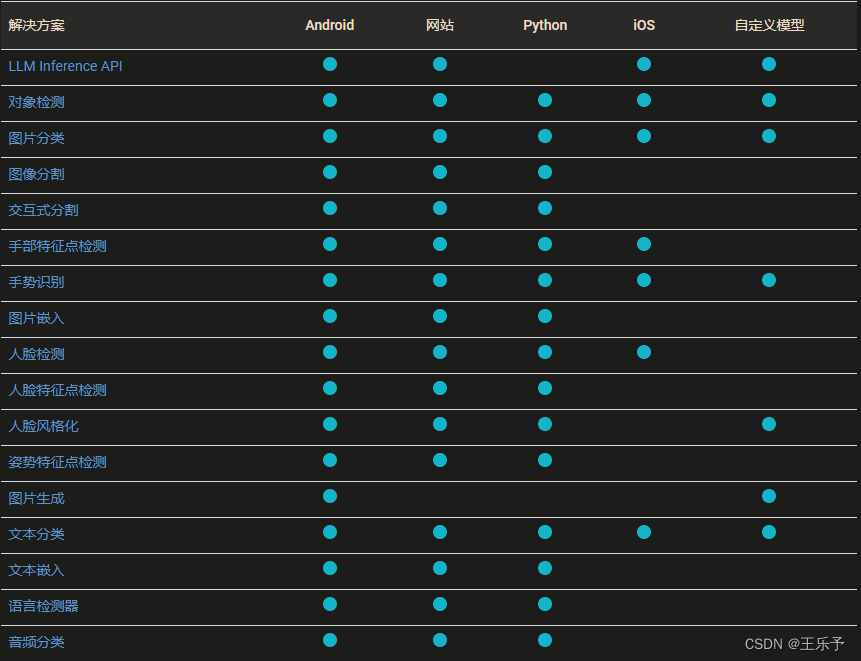
MediaPipe目前支持的解决方案(Solution)及支持的平台如下图所示:
😺二、MediaPipe人脸关键点检测概述
MediaPipe Face Landmarker 任务允许检测图像和视频。可以使用此任务来识别人类的面部表情,应用面部滤镜和效果,并创建虚拟形象。该任务输出 3D 人脸标志。
MediaPipe人脸关键点检测模型包含了478个3D关键点,如下图所示:

人脸标记使用一系列模型来预进行预测。 第一个模型检测人脸,第二个模型在检测到的人脸上实现定位,第三个模型使用这些标记来识别面部特征。
😺三、关键函数
import mediapipe as mp
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(static_image_mode=False,
max_num_faces=5, # Maximum number of detected faces
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
参数解释如下:
- max_num_faces:要检测的最大人脸数
- refine_landmarks:是否进一步细化眼睛和嘴唇周围的地标坐标,并输出虹膜周围的其他地标。
- min_detection_confidence:人脸检测的置信度
- min_tracking_confidence:人脸跟踪的置信度
😺四、代码实现
import mediapipe as mp
import numpy as np
import cv2
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(static_image_mode=False,
max_num_faces=5, # Maximum number of detected faces
refine_landmarks=True, # Whether to further refine the landmark coordinates around the eyes and lips
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
height, width, channels = np.shape(img)
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = face_mesh.process(img_RGB)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# Draw a facial mesh
mp_drawing.draw_landmarks(image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style())
# Draw facial contours
mp_drawing.draw_landmarks(image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_contours_style())
# Draw iris contours
mp_drawing.draw_landmarks(image=img,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_IRISES,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_iris_connections_style())
# Draw facial keypoints
# if face_landmarks:
# for i in range(478):
# pos_x = int(face_landmarks.landmark[i].x * width)
# pos_y = int(face_landmarks.landmark[i].y * height)
# cv2.circle(img, (pos_x, pos_y), 3, (0, 255, 0), -1)
num_faces = len(results.multi_face_landmarks)
print(f"Detected {num_faces} faces")
cv2.imshow('faces', img)
key = cv2.waitKey(1)
if key == ord('q'):
break
cap.release()
😺五、检测结果

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











