






本文来自于DW的课程总结https://gitee.com/datawhalechina/hands-on-data-analysis/blob/master/%E7%AC%AC%E4%BA%8C%E7%AB%A0%E9%A1%B9%E7%9B%AE%E9%9B%86%E5%90%88/%E7%AC%AC%E4%BA%8C%E7%AB%A0%EF%BC%9A%E7%AC%AC%E4%B8%89%E8%8A%82%E6%95%B0%E6%8D%AE%E9%87%8D%E6%9E%842.ipynb
总的来说是:分组-->聚合
看例子 :泰坦尼克号的数据集
result.head() # 查看表的前五行

· 计算泰坦尼克号男性与女性的平均票价
# 首先对男性女性进行分组
result.groupby('Sex')
#由于上面这行代码是个可迭代数据类型
#用list()转换成列表类型
list(result.groupby('Sex'))这样就可以查看里面的分组数据了
list(result.groupby('Sex'))[0] # 女性
list(result.groupby('Sex'))[1] # 男性部分结果显示如下:
上面只是帮助我们看一下分组后的数据 ,可以看一下各个特征的统计信息
groupby_sex = result.groupby('Sex')
groupby_sex.describe() #查看一下分组后的每个特征的统计信息
这里如果想要看单独的票价的统计信息
type(groupby_sex.describe()) #pandas.core.frame.DataFrame
groupby_sex.describe()['Fare']

我们要的是男女分组后的平均票价
groupby_sex['Fare'].mean()
·统计男女存活人数 这里为什么可以直接求和 是因为0标记的意思是死亡 所以可以直接求和 不用分类了
#groupby_sex['Survived'].sum() 
· 计算客舱不同等级的存活人数(先对等级分类 最对存活人数求和)
result.groupby('Pclass')['Survived'].sum()
上述求男、女的平均票价 存货人数 可以用agg()函数操作
result.groupby('Sex').agg({'Fare':'mean','Survived':'sum'},rename = {'Fare':'fare_mean','Survived':'sum'}) 是DataFrame类型的

· 统计在不同等级的票中的不同性别的船票花费的平均值
需要两个groupby 分组,然后再求票价的平均值
result.groupby(['Pclass','Sex'])['Fare'].mean() 
·将男女分组后的平均票价与存活人数数据合并,并保存到sex_fare_survived.csv
sex_survived = groupby_sex['Survived'].sum()
sex_faremean = groupby_sex['Fare'].mean()
由于 有相同的列索引Sex 所以可以采用merge进行合并
pd.merge(sex_survived,sex_faremean,on ='Sex')
也可以用agg()函数 然后进行改列名
result.groupby('Sex').agg({'Fare':'mean','Survived':'sum'}).rename(columns = {'Survived': 'Survived_sum','Fare':'fare_mean'})
·#得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数)
①首先得出先得出不同年龄的总的存活人数,
age_survived = result.groupby('Age')['Survived'].sum() 
②然后找出存活人数最多的年龄
max_survived = max(result.groupby('Age')['Survived'].sum())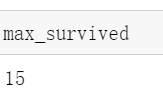
可以看出最大存活人数是15 但是不知道年龄 让max_survived == age_survived.value 就连可以找到了
age_survived.values == max_survived
找到年龄
age_survived[age_survived.values == max_survived]
或者可以这样做(查看某值所在的一行)
df[df['列名'].isin([相应的值])] # 这个是df数据类型的
se[se.isin([相应的值])]# 这个是Series类型的
age_survived[age_survived.isin([15])] # age_survived 是Series序列的③最后计算存活人数最高的存活率(存活人数/总人数)
rate = max_survived/result['Survived'].sum()
#格式化输出
'最大存活率:{}'.format(rate)














 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









