







先介绍事务的四个特性:
- 原子性:要么成功要么失败,A给B转账,要么成功,要么失败,原子性是指数据库的事务是一个不可分割的工作单位,只有数据库事务都成功才算成功,任何一个SQL的失败,数据库状态都必须回退到事务开始前的状态
- 隔离性: 互不影响的操作,A给B转账,A给C转账,事务之间对数据对象的读写是相互隔离的,具体是提交后可见还是提交后也不可见取决于隔离等级
- 一致性:数据的合理变化,A给B转账,A的钱少了,B的钱多了,一致性是指事务将数据库的状态从一种状态转变为下一个一致的状态。在事务的开始和结束后,数据库的完整性约束都没有被破坏
- 持久性:转账记录的保存,持久性是指事务一旦提交,其修改是永久性的,即使还未写入磁盘时发生宕机,也能恢复数据
事务的隔离级别:
- 读未提交
- 读提交(解决了’读未提交‘的脏读)
- 可重复读(大多数数据库默认隔离级别 解决了"读提交"的幻读和不可重复读问题)
- 串行化
现在我们来说一下什么是MVCC:
-
定义:MVCC(Multi-Version Concurrency Control,多版本并发控制)一种并发控制机制,在数据库中用来控制并发执行的事务,控制事务隔离进行。
-
核心思想:MVCC是通过保存数据在某个时间点的快照来进行控制的(在同一个事务中生成快照的不同)。使用MVCC就是允许同一个数据记录拥有多个不同的版本。然后在查询时通过添加相对应的约束条件,就可以获取用户想要的对应版本的数据。(通俗的讲就是我们对数据库操作时候,都会产生一个事务id,在这个事务中,可以执行增删改查,然后commit之后提交数据,这个事务结束,很多事务同时都对一条数据进行修改,则该条数据后面有多个事务id,即版本链,每一个事务修改都是一个版本,而且是并发的,所以叫做并发版本链 undo日志)
-
MVCC实现原理:其实,在我们的数据表中,有两列隐藏的数据我们是看不到的:

那么trx_id, roll_pointer是什么那?这个就是在表中隐藏的两列,我们先来说trx_id:- trx_id: InnoDB里面每个事务有一个唯一的事务ID,叫作transaction id,它是在事务开始的时候向InnoDB的事务系统申请的,是按申请顺序严格递增的(我们可以理解成时间戳,按创建事务的时间顺序来排序)用来区分事务,我创建了一条数据id为1,那么innodb给我一个事务为1,那么,我又开启一个事务,假设事务id为2,这个事务就是来查询id为1的这条数据,同时,别的用户也操作了这张表,他来修改这条id为1的数据,他的事务id为3,那么,这就通过roll_pointer(版本链)来触发数据库并发读写了
- roll_pointer:这里面存储的就是指针,指向上一个版本链中的数据
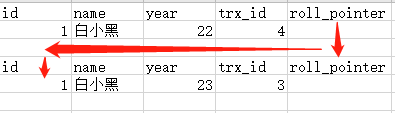
rolle_pointer这一列就是长这个样子,那接下来说一下MVCC和隔离事务级别的关系了,上面的图就是一个版本链,事务id大家可以看出,事务id3和4分别作了不同的事情,那么我在事务2中究竟能查到name和year是什么数值那? - 其实,在我们执行select查询数据时,事务在每次查询开始时都会生成一个独立的ReadView,这个ReadView来决定我们查询出来的数据是那个事务id的数据,当事务隔离级别为“读已提交”时,当事务id3和4都提交数据后,我们在事务id2中执行每次查询时,都会产生都会产生一个ReadView,ReadView会选择事务id最大的来作为你查询的最新数据,当事务隔离级别为“可重复读”时,只有在这个事务中,你第一次执行select查询时产生一个ReadView,选择事务id最大的那个作为查询数据,当在这个事务中第二次执行select查询时,不再产生新的ReadView,所以这就是隔离级别的底层实现
- 举个例子,这是一个版本链,此时隔离性的隔离级别是 已提交读:

此时, 表中id为1数据中版本连最新的数据就是name等于 小白 的数据,此时trx_id为100, 这时候,有一个更新请求进来了,要将name变为 白小白 ,此时开启一个事务transaction_id为101,然后将 transaction_id复制给trx_id, 那么id=1的这条数据的版本链长什么样那?

有图可以看出,此时id=1的最新数据就是姓名为白小白的数据,注意此时trx_id=101的事务还没有结束(commit), 此时一个select请求进来并开启了事务A(注意 select请求是不会产生版本链的增加的,只有insert update delete有),此时会生成一个readview,里面放着[101],瞬间知道了trx_id=101的事务还没有提交,那不能查,那查出来的数据只能是name=小白 这一条,当trx_id=101事务提交后,又一个select请求过来了(注意,此时事务A并没有结束),又产生了一个readview,此时一看readview是[],什么都没有放,就取出了name=白小白 这一条数据,然后事务A结束,但是在事务A中查询了两次,出现了不同的数据,这就是"幻读" - 举个例子,这是一个版本链,此时隔离性的隔离级别是 可重复度:

此时, 表中id为1数据中版本连最新的数据就是name等于 小白 的数据,此时trx_id为100, 这时候,有一个更新请求进来了,要将name变为 白小白 ,此时开启一个事务transaction_id为101,然后将 transaction_id复制给trx_id, 那么id=1的这条数据的版本链长什么样那?

有图可以看出,此时id=1的最新数据就是姓名为白小白的数据,注意此时trx_id=101的事务还没有结束(commit), 此时一个select请求进来并开启了事务A(注意 select请求是不会产生版本链的增加的,只有insert update delete有),此时会生成一个readview,里面放着[101],瞬间知道了trx_id=101的事务还没有提交,那不能查,那查出来的数据只能是name=小白 这一条,当trx_id=101事务提交后,又一个select请求过来了(注意,此时事务A并没有结束),这时,并不会再产生一个readview,而是使用上一个的readview(在事务A中产生的第一个readview), 此时取出的依然是name=小白这条数据,这就解决了"幻读"的问题
-
总结:
- 所以说 mvcc里面跟事务隔离级别相关的,只有可重复读和读已提交这两种,因为串行化是加锁,而读未提交根本不需要mvcc,这样反而浪费了性能
- 从上边的描述中我们可以看出来,所谓的MVCC(Multi-Version Concurrency Control ,多版本并发控制)指的就是在使用读已提交(READ COMMITTD)、可重复读(REPEATABLE READ)这两种隔离级别的事务在执行普通的SELECT操作时访问记录的版本链的过程,这样子可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
- 这两个隔离级别的一个很大不同就是:生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadView,而REPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,数据的可重复读其实就是ReadView的重复使用。
参考文章:https://blog.csdn.net/qq_35190492/article/details/106915564















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









