






用于异常检测的竞争型和区别型重构学习算法
— 2019 发表于AAAI(CCF A)
目录
大多数现有的异常检测方法仅使用 正数据来学习数据分布,因此它们通常需要在检测阶段预先 定义阈值来确定测试实例是否是异常值。不幸的是,好的阈值对性能至关重要, 很难找到最佳阈值。 本文考虑了未标记数据中隐含的判别信息,提出了一种新的异常检测方法, 该方法可以直接学习未标记数据的标记。
我们提出的方法有一个端到端的架构,有一个编码器和两个解码器,它们被训练成以竞争的方式对正常数据和异常数据分布进行建模。该体系结构具有良好的区分性,不会出现过拟合现象,模型的训练算法采用了SGD算法,因此即使在大规模数据集上也是高效且可扩展的。
对KDD99、MNIST、加州理工学院-256、ImageNet等7个数据集进行实证研究。表明我们的模型优于最先进的方法。
Introduction
异常检测是对不符合预期正常模式的数据进行识别。这些数据可能来自一个新的类别,也可能来自一些没有意义的噪声数据。通常,我们将这些异常数据称为异常值,而将正常数据称为正常值。异常检测与许多现实世界的应用密切相关,例如计算机视觉领域的离群值检测、新颖性检测(Khan和Madden,2009;Chandola,Banerjee和Kumar,2009;Khan和Madden,2014),以及生物信息学中的医疗诊断和药物发现(魏等人)。(2018年)。它可以归类为单类学习,其中否定类的概念界定不清。根据实际应用环境,负面数据可能很难收集或核实。此外,可能存在任何类型的不可预测的异常数据。因此,这些数据被认为是新奇的(或离群值),而积极的数据则被训练数据很好地描述。由于分类器的惰性,传统的多类分类方法很难仅从带正标签的数据中学习。
- 单分类(one-class classification)是针对只有正样本的数据集所使用的分类方法。它试图从数据集寻找模式,因而从更大范围的假设空间中有效地将正样本和潜在的负样本分开。单分类算法只关注与样本的相似或匹配程度,对于未知的部分不妄下结论。分类问题,例如二分类和多分类,由于多分类问题都可以解体成多个二分类问题,所以,一般来说,二分类问题被看做是基本的分类问题。在二分类里,理想情况下,需要要求训练集中的每类元素的数量巨大且几乎相等,即使在现实世界中,会出现正负类样本失衡的情况,所幸,众多策略已经被提出来解决此类问题,有点偏题,不多赘述。但是如果训练集中仅仅只有一类数据,那么要如何测试新的数据呢?并如何判断它是否与训练数据相似?这就引入了 one class classification。在one-class classification中,仅仅只有一类的信息是可以用于训练,其他类别的(总称为outlier)信息是缺失的,也就是区分两个类别的边界线是通过仅有的一类数据的信息学习得到的。
在过去的几十年里,研究人员提出了许多方法来处理异常检测问题(Ekin 2000;Chandola,Banerjee和Kumar 2009;Liu,Huaand Smith 2014;Malhotra等人)。2016)。通常,这些方法要么为正常数据样本建立模型配置,并将不符合正态分布的样本识别为异常值,要么基于异常的统计或几何度量明确地隔离异常值。通常,不同的模型具有不同的描述数据分布的能力。传统的方法大多是线性模型,模型容量有限。虽然核函数可以用来提高它们的能力,但它不适合高维和大规模数据的背景。
近年来,深度学习方法已经显示出其强大的表征能力,并在许多应用中取得了巨大的成功(Vincent等人)。2010年;Krizhevsky、Sutskever和Hinton 2012年;Bengio、Courville和Vincent 2013年)。然而,**由于负数据的不可获得性,直接训练有监督的深度神经网络进行单类分类是困难的。**虽然人们已经做了一些努力来学习单类分类器,但大多数都不能建立异常检测的判别模型。通过选择预定义的阈值来完成检测。**从概率的角度来看,这可以解释为离群值应该位于模型分布的低密度区域。然而,由于异常值是不可预测的,因此很难确定一个适用于所有情况的阈值。同时,由于模型只对正数据进行训练,过度拟合是影响模型泛化性能的另一个关键因素。**这就是为什么我们不能简单地基于正数据训练DNN(Deep Neural Networks)分类器的原因。虽然人们可以使用一些策略,比如提前停止,以避免过度拟合,但这是非常棘手的,人们无法决定何时停止是对测试数据最好的。
为了解决这些问题,我们提出了一种新的模型–竞争性重构自动编码器(CORA)。我们的模型兼有监督和非监督两种方法的优点。我们提出了一种导引式半监督异常检测方法,该方法使用正训练数据和未标记的测试数据进行学习。
-
Auto encoder算法是一种常见的基于神经网络的无监督学习降维方法。Autoencoder包含两个主要的部分,Encoder(编码器)和 Decoder(解码器)。Encoder的作用是用来发现给定数据的压缩表示,Decoder是用来重建原始输入。在训练时,decoder 强迫 autoencoder 选择最有信息量的特征,最终保存在压缩表示中。最终压缩后的表示就在中间的coder层当中。

从Input到Output的这个过程中,autoencoder实际上也起到了降噪的作用。AutoEncoder无监督异常检测:首先算法假设异常点服从不同分布,根据AutoEncoder能将正常数据样本重建还原,而无法较好还原异于正常分布数据的特性,将还原误差较大的点标记为异常值。

自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。自编码器能从数据样本中进行无监督学习,这意味着可将这个算法应用到某个数据集中,来取得良好的性能,且不需要任何新的特征工程,只需要适当地训练数据。但是,自编码器在图像压缩方面表现得不好。它在处理与训练集相类似的数据时可达到合理的压缩结果,但是在压缩差异较大的其他图像时效果不佳。


图1展示了我们的方法与大多数现有方法之间的学习过程的差异。与传统的自动编码器不同,该结构由一个编码器和两个解码器组成。**这两个解码器被设计成在重建过程中相互竞争,其中一个被学习来重构正数据,被称为Inlier解码器,而另一个被学习来重构离群值,被称为outliers解码器。在正训练数据的指导下,Inlier解码器可以为正类建立一个合适的轮廓,而大部分异常数据将被分配给孤立点解码器。通过比较这两个解码器的重建误差来进行区分标记。**训练结束后,最终的作业构成了对未标记(或测试)数据的预测。
众所周知,自动编码器将针对不同的数据空间学习不同的特征子空间。由于我们的两个竞争解码器共用一个编码器,因此在子空间上增加一个正则化项是合理的,以最大限度地提高正向数据和离群点的可分离性,这将进一步提高CORA。因此,在本文中,我们提出了一种流形正则化方法来保留子空间中正数据和离群点的数据结构。
在本文中,我们提出了一种可以以端到端的方式训练的转导半监督异常检测方法。我们的工作具有以下优点:•新颖的体系结构。针对异常检测问题,提出了一种由具有一个编码器和两个竞争性解码器的自动编码器实现的新的半监督超导神经网络框架。 •新标准。虽然先前的基于重建的算法使用阈值作为分类标准,但我们提出了一种新的方案来做出决策,这可以帮助我们摆脱这种超参数选择。 •坚固性。大量实验表明,与许多最新方法相比,所提出的模型对异常值比率的鲁棒性更高。 •高效且可扩展的优化过程。我们在模型中采用了随机梯度下降(SGD),使其训练非常有效,可用于大规模数据。 •全面的实验。我们对七个模型的模型进行了全面评估,并与多种最新方法进行了比较。
Related Work
异常检测属于单类分类,单类分类与离群点检测或新颖性检测密切相关。这些应用程序的共同目标是发现新概念,这些新概念很少或从未出现,并且与已知概念有本质上的不同。传统的研究通常对积极/目标类建模,排斥不遵循他们的样本。这类方法通常是从正数据估计概率密度函数。通过从正样本建立参数或非参数概率估计器,包括核密度估计器(KDE) (Parzen 1962)和最近的稳健核密度估计器(RKDE) (Kim和Scott 2012),可以识别出概率密度较低的离群样本。这些方法假设正数据分布更加密集。其他统计模型,如PCA (De La Torre和Black 2003;Candes等2011年;Xu, Caramanis, and Mannor 2013)假设正数据比离群值之间的相关性更强,从低维子空间得到更好的重构。**大多数异常检测的深度学习方法都建立在自动编码器的基础上,其中重建误差用于区分异常值和inliers。**这些方法仅从正数据中学习,但也存在一些问题。一方面,这些方法需要重新定义误差阈值来确定未标记样本,但很难找到最优阈值。另一方面,自动编码器对正数据进行训练会出现过拟合问题,特别是在正样本数量较小的情况下。
最近,(翟田田等人)。2016)提出了一种新的基于能量的深度神经网络来检测离群值。他们没有直接使用重建误差作为决策标准,而是表明能量可以成为识别异常值的另一个标准。然而,该方法仍然需要一个预先定义的阈值来区分离群值。一些研究人员试图用生成式对抗性网络(GANS)来解决单类分类问题,而不是自动编码。其中之一是将去噪自动编码器与鉴别器相结合,并以对抗性的方式对它们进行训练(Sabokrou等人)。(2018年)。其关键思想是增强解码器,使其在失真离群值的同时,能够完美地重构正常值。虽然他们使用GaN的鉴别器对样本进行分类,但分类实际上是基于一个任务相关的阈值,即如果f(X)<σ,x就是一个离群值。
我们的方法与用于异常检测或离群值消除的一些无监督方法密切相关。与仅从正数据中学习的监督方法不同,无监督方法通过引入辅助标签来获取未标签数据中的区分信息,并最大化内在和离群值之间的区别,它们迭代地完善标签并最终输出预测。 (Liu,Hua,and Smith 2014)提出了一种无监督的一类学习(UOCL)方法,该方法利用辅助标签变量,并共同优化基于内核的最大余量分类器和软标签分配。另一个基于深度学习的无监督方法是判别式重构自动编码器(DRAE)(Xia等人,2015年),他们还为未标出的数据引入了判别性标签,并优化了正常值和离散值重构误差的类内方差。
注意,我们的异常检测公式不同于正向无标记(PU)学习(Elkan和Noto 2008)或归纳半监督异常检测(Kimura和Y anagihara 2018)。在这两种情况下,假设用于训练的未标记数据与测试数据共享相同的分布。在我们的例子中,与非监督方法类似,只有正面数据和未标记(或测试)数据用于训练。我们的方法属于传导性半监督学习(Chapelle,Scholkopf和Zien 2009),其中学习是只为给定的未标记数据推断正确的标签。为了更好地理解现有的大多数深度学习模型与我们的方法之间的差异,我们在表1中从三个角度对它们进行了比较。
Competitive Reconstruction Auto-encoder
在这一部分中,我们将详细介绍我们设计的竞争性重构自动编码器(CORA)。本文首先介绍了CORA的体系结构和目标函数,然后说明了如何对该模型进行优化。


Model Architecture
提出的竞争重构自动编码器由三个主要模块组成:(1)编码器网络E,(2)正常值译码网络Din和(3)离群值译码网络DOUT。编码器将数据映射到由正常值和离群值共享的公共子空间中。DIN执行正常值样本的重建,而DOUT充当离群值的重建器。DIN和DOUT以竞争的方式工作,因为它们都试图为输入样本提供较低的重建误差。然而,每个样本只能由一个解码器解释。提出的模型的体系结构如图2所示。可以看出,正训练数据和未标记测试数据都被送入E,当训练数据为正时,我们直接选择Din进行重构。对于未标记的测试数据,标签由两个解码器的重建误差确定。
形式上,设Xp为正训练数据,其中Xp i是Xp的第i个样本,i=1,…m。同样,设Xu是未标记数据,Xu j是Xu的第j个样本,其中j=1,…,n。为了给每个Xu j分配标签,我们提出了如下损失函数。
Competitive Reconstruction Loss
之前的工作(Xia et al. 2015)表明,通过对目标类的样本进行训练,自动编码器的重构误差是检测新颖性样本的有用度量。具体地说,如果训练一个自动编码器来重建目标类样本(inliers),对新样本的重建误差会很大。为了分别模拟正数据和离群值的分布。我们为我们的模型设计了一个竞争机制。**通过正数据的引导,训练Din学习目标类的分布。对于可能是内联或外联的未标记数据,如果Din的重构误差小于Dout的重构误差,则它很可能是正常的。**在本文中,我们使用均方误差作为所有实验的重构误差。为简单起见,我们定义样本x的重构为Rin(x) = Din (E(x))和Rout (x) = Dout (E(x)),竞争性重建损失定义为:
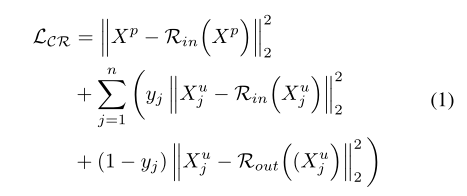
其中yj,j=1,…,n是第j个样本的标签分配,其计算公式为:
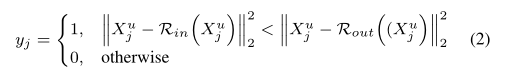
请注意,每次迭代都会更新yj。稍后我们将提供有关如何优化模型的详细说明。为了清楚起见,我们省略了总和符号的平均值。如前所述,CoRA将不同的数据映射到子空间中的不同区域。因此,一个直观的想法是将正数据和异常数据的数据结构保留在子空间中,以便类似的示例在子空间中保持紧密联系。我们提出了一个保留结构的正则化项来改善我们模型的性能。
Subspace Structure-preserving Regularization
除了竞争损失,我们还提出了一个正则项来保持子空间中的数据结构。子空间正则化在以前的工作中已经探索过(Agarwal,Gerber,Daume 2010刘、华、史密斯2014;Y ao等人,2015年)。这里我们使用块对称亲和矩阵,因为我们使用正数据和未标记的测试数据进行训练。形式上,我们将训练样本的亲和矩阵构建为W:

其中D(xi,xj)是数据的距离度量。Ni是第I个数据点的邻域。在我们的方法中,W可以表示为
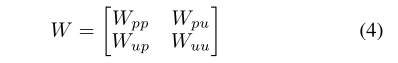
其中Wpp和Wuu分别表示阳性数据和未标记数据之间的亲和力矩阵,Wpu和Wup都表示阳性数据和未标记数据之间的亲和力矩阵。对于未标记数据,我们将Wuu设置为零矩阵,以避免子空间结构被未标记数据的不确定结构破坏。换句话说,由于不确定性的存在,我们不考虑未标记数据之间的流形结构。
流形正则化可以定义为

其中E(Xi)表示样本Xi的编码器特征。该正则化项可以迫使编码器将类似的例子映射到邻域中。请注意,可能会出现混淆:正数据和未标记数据的大小不同,我们如何才能将W形式化到(4)公式中,这是一个与优化算法相关的问题,下一小节将对此进行说明。
Optimization
竞争重构自动编码器经过优化,最大限度地减少了以下损失函数:
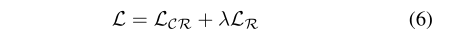
其中λ> 0是控制正则项相对重要性的超参数。我们针对不同的任务对λ进行了调整,并观察到λ= 0.1可以为我们的所有实验带来可喜的结果。为了优化该损失函数,采用了随机梯度下降(SGD)方法来训练我们的模型。当我们使用小批量SGD时,对于每次迭代,我们都采样相同数量的正数据,以便可以像等式(4)中那样计算W。详细的优化算法在Alg1中进行了描述。

Discussions


学习过程。为了了解CoRA的学习过程,我们针对不同的学习迭代探索了Inlier解码器和Outlier解码器的重建结果。如图3所示,在训练的一开始,两个解码器针对不同的样本进行了类似的重构。但是,在几个时期之后,与离群值解码器相比,正解码器开始在目标类上生成更好的重构。最终,随着学习过程的收敛,正解码器为离群值产生了错误的重建,像失真的正样本。尽管异常值解码器可以输出正样本的可理解的重建,但它们都有一定的失真。因此,正样本被分配给正解码器,而离群样本被分配给离群解码器。此外,我们研究了在训练过程中正数据和离群值上,离群解码器和离群解码器之间的重构残差分布。残差定义为


结果如图4所示。我们可以看到,两个解码器在初始化阶段对于内联和外联都有相似的重构误差。然而,随着训练的进行,内联和外联的残差是不同的。大约50次训练后,学习过程开始收敛,内联者和外联者的区分越来越清晰。但是,由于总存在一些难以与inliers区分的异常值,因此有一个小的重叠区域。
**CoRA的优点。**如前所述,我们的模型不需要预先定义的阈值来区分异常值。这对于许多现实世界的应用程序来说非常重要。我们的算法的另一个优点是,它不会像大多数基于重构的模型那样受到过拟合问题的困扰。当学习过程收敛时,每个未标记样本的分配很少改变,这意味着CoRA是鲁棒的。此外,我们对自动编码器的设计没有任何限制。通过利用深度自动编码的表示学习能力,我们的模型对于各种数据是灵活的。同时,小批量梯度下降优化使我们的方法在处理大规模数据集时非常有效,这是大数据时代的基本要求。
Performance Evaluation
在这一部分中,我们对CORA的异常检测任务进行了评估,并将其与现有的方法(包括最新的方法)进行了比较。我们使用了七个数据集,包括低维数据和图像数据。





Conclusion
本文提出了一种用于半监督异常检测任务的竞争性重构自动编码器模型。我们的模型从正数据和未标记测试数据中学习,并在学习后直接预测未标记数据的标签。这两个解码器的设计目的是相互竞争以实现更低的重建误差。在正向数据的引导下,Inlier解码器更有可能构建正向类的配置。与现有的大多数判别方法不同,新的判别准则不需要预先定义阈值。此外,我们还采用SGD对该模型进行了优化,使其在大规模数据集上具有较高的效率和可扩展性。在7个基准数据集上的实验结果表明,该模型可以击败许多最先进的方法。

















 2459
2459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









