







 文章详细介绍了如何在Pycharm专业版中创建和激活名为MISA的虚拟环境,以及安装Pytorch和CUDA。关键步骤包括使用conda创建环境,安装CMU-MultimodalSDK,处理Windows环境下的路径问题,并下载数据集和glove文件。此外,文章还提到了在训练过程中遇到的兼容性和路径问题的解决方案。
文章详细介绍了如何在Pycharm专业版中创建和激活名为MISA的虚拟环境,以及安装Pytorch和CUDA。关键步骤包括使用conda创建环境,安装CMU-MultimodalSDK,处理Windows环境下的路径问题,并下载数据集和glove文件。此外,文章还提到了在训练过程中遇到的兼容性和路径问题的解决方案。
MISA源码github链接:click here
IDE: Pycharm专业版2022.2.2 python3.8
一、创建虚拟环境:
- 尝试
源码中给了environment.yml,可以用以下命令创建,但可能是由于某些库的版本问题,尝试失败。
conda env create -f environment.yml
- 执行
最终选择新建一个虚拟环境,命名为MISA ,再依次导入相关包。
##创建虚拟环境MISA,指定Python版本为3.8
conda create -n MISA python=3.8
##激活虚拟环境
conda activate MISA
在创建的虚拟环境下安装Pytorch及对应的CUDA:见另一篇博客
pip list 查看虚拟环境下的安装的库的版本:
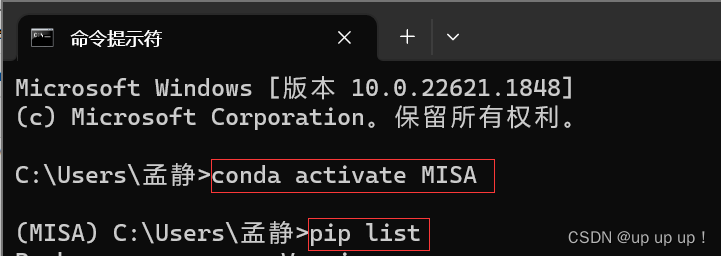
Pytorch、cuda版本:

将源码在Pycharm中打开:
二、下载数据集:
github的源码解读中给出:
Data Download
Install CMU Multimodal SDK. Ensure, you can perform from mmsdk import mmdatasdk.
Option 1: Download pre-computed splits and place the contents inside datasets folder.
Option 2: Re-create splits by downloading data from MMSDK. For this, simply run the code as detailed next.
安装CMU多模态SDK。确保您可以执行from mmsdk import mmdatasdk。
选项1:下载预先计算的数据集拆分,并将内容放置在数据集文件夹中。
选项2:通过从MMSDK下载数据重新创建数据集拆分。为此,请按照下面详细说明的代码运行。
1.下载安装CMU Multimodal SDK 并在Windows环境下进行配置:
1.1.下载
原链接已经失效,找到了新的:click here
下载并解压缩,记住存放的路径!
 1.2.anaconda环境配置(Windows系统下)
1.2.anaconda环境配置(Windows系统下)
官方github的readme中写了需要配置环境,但该命令是基于linux系统,windows系统需要按照以下步骤设置。
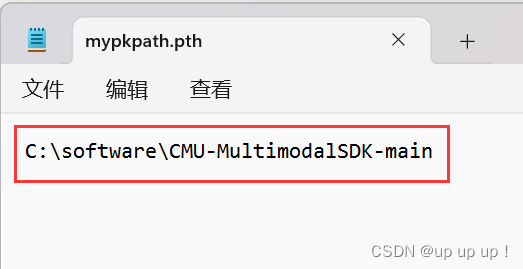
- 步骤1:在anaconda的虚拟环境
路径下的Lib\site-packages,创建一个文本文档,命名为’mypkpath‘,在该文档中添加上一步的SDK路径,保存之后将文件后缀改为“pth”。

- 步骤2:用下面的命令安装mmsdk的依赖包:
pip install h5py validators tqdm numpy argparse requests
- 步骤3:因为win10和Linux的文件路径分隔符不同,所以这里要修改mmsdk里的文件:
修改文件1:路径如下
..\CMU-MultimodalSDK-main\mmsdk\mmdatasdk\computational_sequence\download_ops.py
在文档最后修改为:(read和URL中间加一个’_')

修改文件2:和上一个文件同级的不同文件:computational_sequence.py
..\CMU-MultimodalSDK-main\mmsdk\mmdatasdk\computational_sequence\computational_sequence.py
文档第68行左右,把分隔符从’os.sep’改为’/':
 步骤4:启动conda的虚拟环境,导入mmsdk包验证是否安装成功,没报错就安装成功
步骤4:启动conda的虚拟环境,导入mmsdk包验证是否安装成功,没报错就安装成功
from mmsdk import mmdatasdk as md
create_dataset.py文件 导入mmsdk语句没有报错!
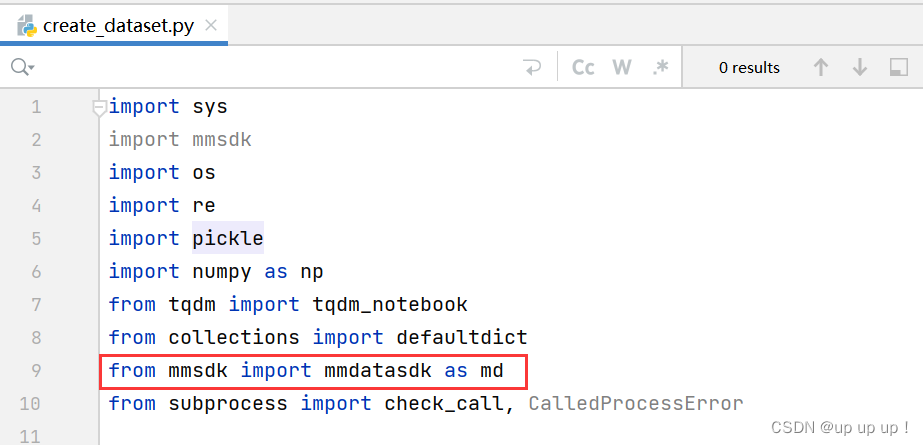
2.下载预先计算的数据集拆分
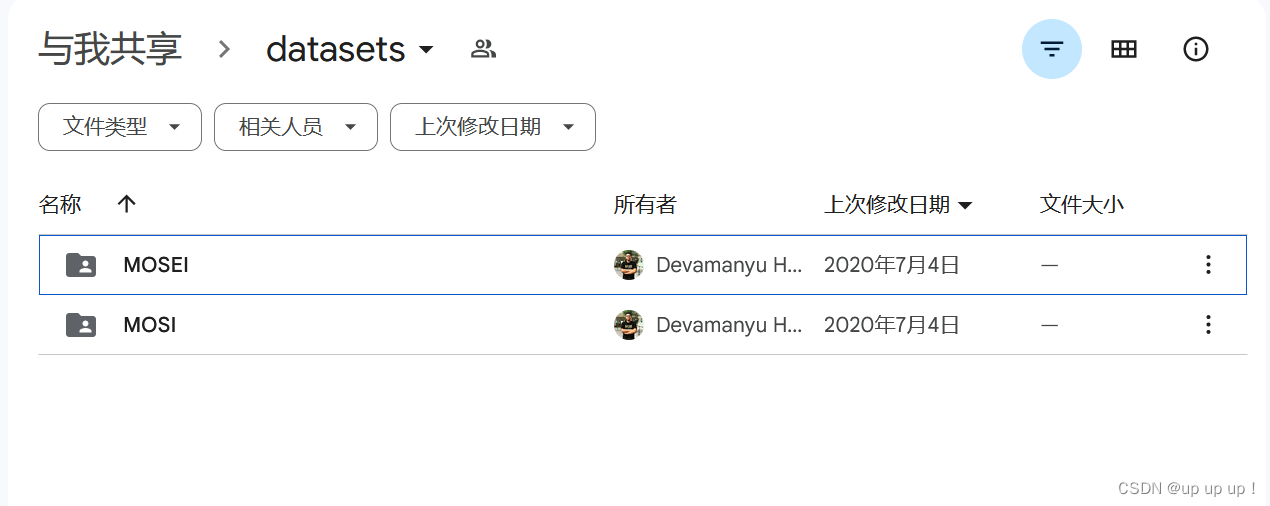
接下来有两种选择:选项1和选项2。这里使用选项1——直接下载预先计算的数据集拆分,并将内容放置在数据集文件夹中。
下载链接:click here
有两个数据集:MOSEI和MOSI
 选项2:直接运行代码,会下载csd文件到数据集文件夹下,再进行计算,生成选项1中的数据集拆分,因此选项1比较容易。
选项2:直接运行代码,会下载csd文件到数据集文件夹下,再进行计算,生成选项1中的数据集拆分,因此选项1比较容易。
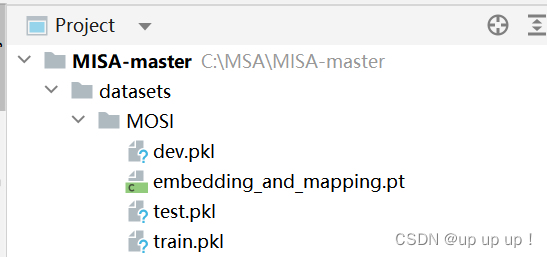
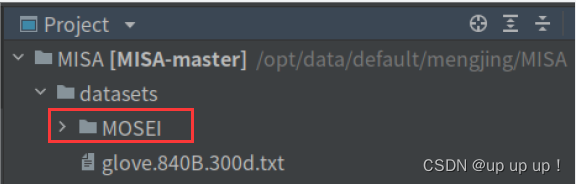
放置到项目中路径如下:
3.下载glove file
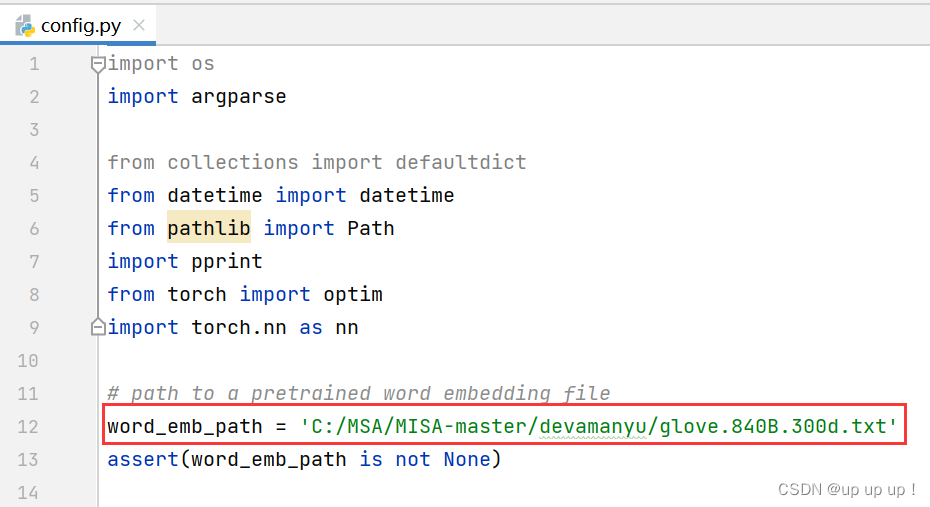
下载链接:click here

并将config.py里的word_emb_path改为上诉路径:
三、运行
做完上述工作后,检查src文件的所有.py文件,看画波浪线标红的模块导入语句,哪里标红,就下载相应的库,在cmd中切换到虚拟环境pip安装,记忆里几个比较重要的库:transformers、h5py、numpy、validators、scipy、scikit-learn、tqdm等。
运行train.py文件!
此项目在windows系统和Linux系统分别进行了配置!
过程中遇到了几个问题:
1.在Linux系统的大服务器上配置CMU Multimodal SDK,直接把该文件夹下的mmsdk文件夹放到src文件夹下,就能确保from mmsdk import …语句不出错。
- 报错:RuntimeError: ‘lengths’ argument should be a 1D CPU int64 tensor, but got 1D cuda:0 Long tensor
解决办法:在torch\nn\utils\rnn.py 第244行附近修改:
data, batch_sizes = \
_VF._pack_padded_sequence(input, lengths, batch_first)
改成
data, batch_sizes = \
_VF._pack_padded_sequence(input, lengths.cpu(), batch_first)
- solver.py文件中torch.save 保存模型到checkpoint文件夹,在Linux系统可以正常运行,生成如下文件:
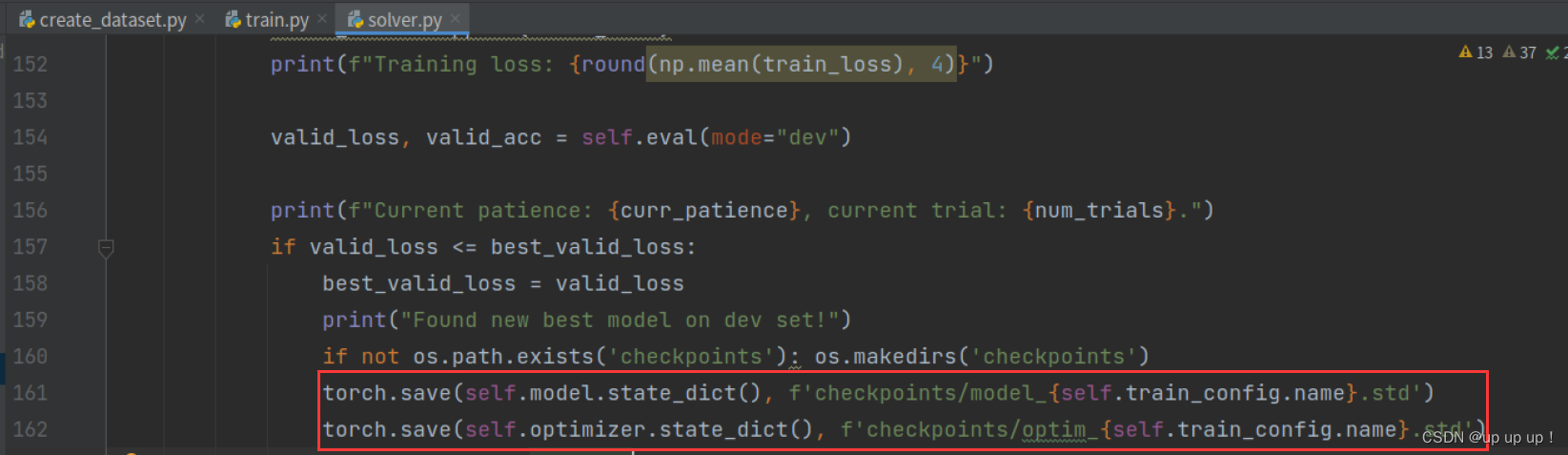
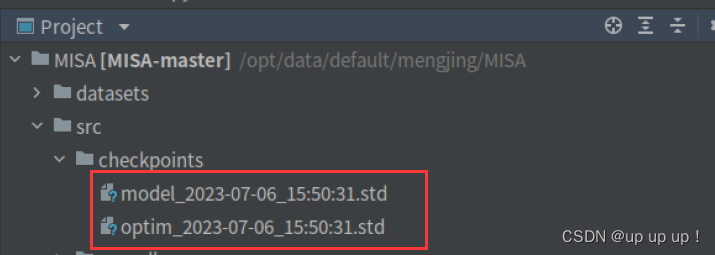
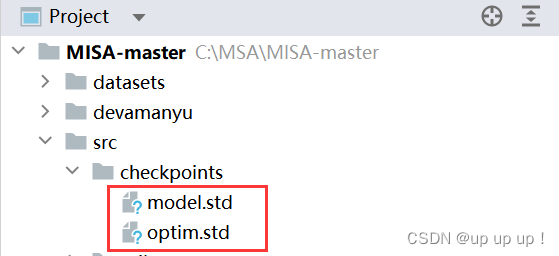
在Windows系统会报错,{self.train_config.name}识别不了,无法生成对应的文件,并保存到checkpoints文件夹下,最后只能把{self.train_config.name}去掉,才能正常运行:

4.更换数据集:从MOSI换成MOSEI
这里修改一下,把glove file放在datasets文件夹下更合适,对应的config.py文件里的路径也要改一下。
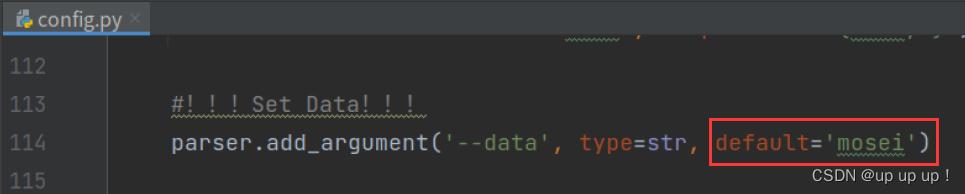
在config.py文件中修改默认数据集为mosei,再run train.py。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









