







 MInD是一种多模态情感分析方法,通过信息解纠缠来改善不同模态之间的差异,提高表示的纯度和信息利用率。它将输入分解为模态不变、模态特定和噪声组件,通过多种约束优化学习表示,增强多模态融合。实验证明,MInD在多模态情感识别和幽默检测任务上优于现有最先进的模型。
MInD是一种多模态情感分析方法,通过信息解纠缠来改善不同模态之间的差异,提高表示的纯度和信息利用率。它将输入分解为模态不变、模态特定和噪声组件,通过多种约束优化学习表示,增强多模态融合。实验证明,MInD在多模态情感识别和幽默检测任务上优于现有最先进的模型。
题目:通过多模态信息解纠缠改进多模态情感分析
Abstract
学习有效的联合表征一直是多模态情感分析的核心任务。以前的方法侧重于利用不同模态之间的相关性,并通过复杂的融合技术提高性能。然而,由于不同模态固有的异质性,可能导致分布差距,阻碍了对多模态信息的充分利用,并导致从特征中提取的信息冗余和不纯。为了解决这个问题,我们引入了多模态信息解纠缠(MInD)方法。MInD通过共享编码器和多个私有编码器将多模态输入分解为模态不变分量、模态特定分量和每个模态的残余噪声分量。共享编码器的目的是探索模态之间的共享信息和共性,而私有编码器的目的是捕获独特的信息和特征。因此,这些表示提供了多模态数据的综合视角,促进了后续预测任务的融合过程。此外,MInD通过以对抗的方式明确建模与任务无关的噪声来改进学习表征。在基准数据集(包括CMU-MOSI、CMU-MOSEI和UR-Funny)上进行的实验评估表明,MInD在多模态情感识别和多模态幽默检测任务上的表现优于现有的最先进方法。代码链接:click here
1 Introduction
近年来,人们对多模态情感分析(MSA)越来越感兴趣。对情感的理解通常通过视觉、音频和文本信息等跨模态输入来增强。因此,研究人员专注于开发有效的联合表示,以整合收集到的数据中的所有相关信息,而大多数模型依赖于设计复杂的融合技术来探索模态内和模态间的动态。虽然多模态学习在理论上表现优于单模态学习,但在实践中,不同模态的内在异质性导致的模态差距阻碍了对多模态信息的充分利用,从而实现有效的多模态表征。这种现象在广泛的多模态模型中持续存在,包括文本、自然图像、视频、医学图像和氨基酸序列。因此,先前的方法通过一个全面的学习框架来处理每种模态表征可能会导致多模态表征的不够精细和潜在冗余。
最近的研究已经开始探索不同的多模态表征的学习。Pham等人使用循环重构将源模态转换为联合表示的目标模态。Mai等人提供了一个对抗性的编码器-解码器分类器框架,通过翻译分布来学习模态不变的嵌入空间。但这些方法并没有明确地学习到从不同角度揭示情感独特特征的模态特定表示。通过采用共享-私有学习框架,Hazarika等人和Yang等人试图通过学习每个模态的不同分解子空间来合并不同的信息集,以获得更好的融合表示。然而,他们的方法要么使用简单的约束不能保证一个完美的分解,要么依赖于一个复杂的融合模块,这表明提取的信息可能是未经提炼的。而且,两者都忽略了对信息流的控制,这可能导致实际信息的损失。
受上述观察的启发,我们提出了多模态信息解纠缠(Multimodal Information Disentanglement, MInD)方法来解决异构模态信息开发不足的问题。主要策略是通过信息优化将每种模态的特征分解为三个不同的组件。具体来说,第一个组件是模态不变组件,它可以有效地捕获潜在的共性并探索跨模态的共享信息。其次,对模态特定组件进行训练,获取区分性信息和独有特征;此外,由于每个信号中的未知噪声可能被归类为互补信息,因此我们显示地对噪声成分进行建模,以增强学习信息的精细化并减轻噪声对表征质量的影响。因此,这三个组件的组合提供了给定输入的全面视图。
本文的贡献可以概括为:
- 我们提出了一种基于解纠缠的多模态情感分析方法MInD,该方法由信息优化驱动。MInD通过学习模态不变性、模态特异性和噪声表征来克服模态异质性带来的挑战,从而有助于预测任务的融合。
- 我们显式建模噪声成分,以提供多模态输入的更全面的视图,以及提高学习表征的质量。据我们所知,我们是第一个将噪声成分引入解纠缠的工作。
- MInD在三个标准的多模态基准测试中仅使用简单的融合策略就优于以前最先进的方法,这表明MInD在捕获多模态信息的各个方面的能力。
2 Related Works
2.1 Multimodal Sentiment Analysis
学习有效的联合表征是MSA的一个关键挑战。许多先前的工作已经促成了复杂的融合技术,利用不同模式之间的相关性。Zadeh等人提出了基于张量的融合网络,该网络应用外积对单峰、双峰和三峰相互作用进行建模。Mai等人引入了图融合网络,将每个交互作为一个顶点,对应的相似度作为边的权重。此外,注意机制被广泛用于识别重要信息。例如,Shenoy和Sardana通过重要性注意网络为多种模式之间的重要性差异分配权重。然而,由于多模态输入具有不同的特征和信息属性,不同模态的内在异质性使数据分析变得复杂,从而对信息的挖掘和集成以及多模态联合嵌入的学习带来了重大挑战。
2.2 Disentanglement Learning
解纠缠学习旨在解开复杂的数据结构,隔离关键组件以提取所需信息,以进行更有洞察力和更有效的数据处理。因此,该方法在跨模态的语义相关概念对齐方面发挥了关键作用,有效缓解了因模态差距而产生的问题。此外,解纠缠学习通过提供更结构化和明确的表示,显著有助于多模态融合。数据表示中的这种清晰度和组织性有助于提高多模态集成过程的效率和精度。因此,继Salzmann et al.之后,许多研究将共享-私有学习策略扩展到各种场景,取得了优异的效果,包括检索、社交网络中的用户表示、情感识别等。相比之下,据我们所知,我们首次尝试将共享-私有解纠缠范式扩展为共享-私有-噪声解纠缠方法。
3 Method
3.1 Model Overview
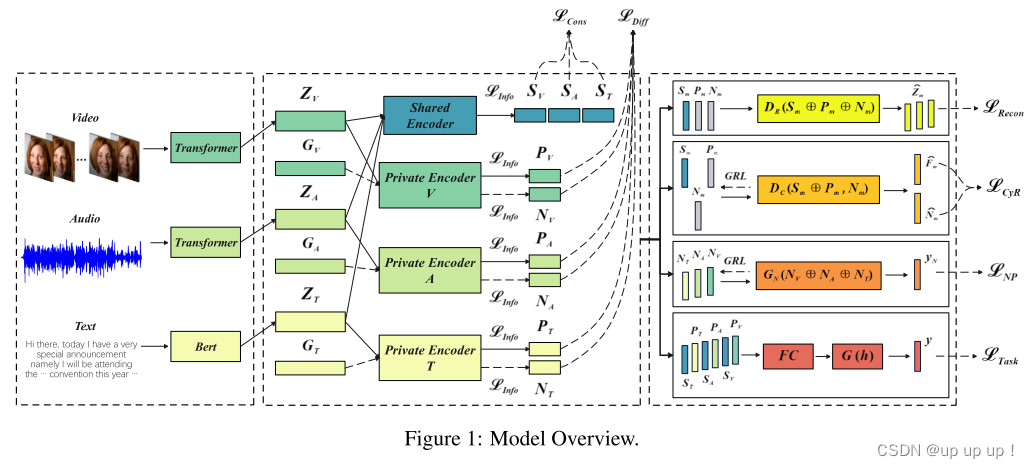
MInD的总体框架如图1所示。我们在一个任务场景中介绍我们的方法,该任务场景包含三种不同的模态,即视觉、音频和文本。每个单独的数据点由来自视觉、声学和文本模式的三个低级特征序列组成。分别记为,其中L(·)为序列长度,d(·)为嵌入维数。
为了应对模态异质性带来的挑战,我们的目标是确定一种有效减轻分布差异并提高信息提取效率的方法,确保对多模态输入进行全面而细致的分析。为此,我们将输入分解为三个部分:模态不变组件,模态特定组件和噪声组件。注意,不同模态的每个噪声分量都是由高斯噪声产生的,并随后发送到相应的专用编码器。然后通过信息约束、一致性约束和差异约束的实现来促进这种分解。这些约束的集成有助于最大限度地利用嵌入在高级特征中的信息,从而能够有效地探索跨模式的共性和独特的特征。然后,通过重构模块评估分解信息的完备性。此外,我们采用循环重构模块进一步减少信息冗余,并采用噪声预测模块有效地最小化噪声分量中的任务相关信息。最后将模态不变分量和模态特定分量融合到预测任务中。
3.2 Feature Extraction
在这里,我们使用基于transformer的模型从各个模态中提取高级语义特征。具体来说,我们对文本模态使用Bert模型,对其余两种模态使用标准transformer模型,
每个模态的精细化特征都在一个固定的维度上,如
3.3 Representation Learning
3.3.1 Modality-Invariant and -Specific Components
虽然基于时间模型的特征提取器可以有效地捕获多模态序列中呈现的长期上下文依赖关系,但由于不同模态的分歧,它们无法有效地处理特征冗余。此外,分而治之处理模式的有效性受到不同处理模态之间固有异质性的影响。
受这些研究结果的启发,我们使用共享和私有编码器来学习模态不变组件和模态特定组件,它们分别用于捕获单个模态的共性和特异性。我们将共享编码器表示为,私有编码器为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









