









一、ContainerCreating
这种报错其实不算报错,容器正在创建中,通常是我们配置问题导致的,
1、docker服务问题
有一天起来有个应用说容器创建不出来,卡在ContainerCreateing状态
按照习惯,我们去describe去看事件,但并没发现有什么报错信息,容器本身还创建出来了
并且通过exec 是可以登陆的,当然logs日志看不了,尝试重启node节点上的kube-proxy、kubelet后
依然是不可用的,重启docker服务后创建成功就绪, 原因未查明( ̄﹃ ̄)
2、 K8挂载远程存储问题
这种情况通常是远程nfs、gfs等存储问题导致的,这个我们可以还原一下
举个栗子
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
volumeMounts:
- mountPath: /tmp/
name: www
volumes:
- name: www
nfs:
path: /nfs/web/date
readOnly: true
server: 192.168.1.21
这里的nfs主机并不存在,我们直接去部署这个yaml,他会一直卡在创建中
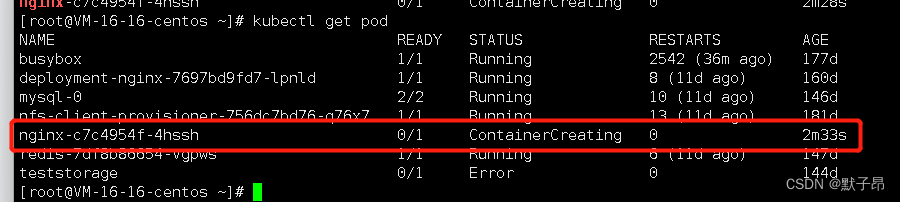
查看报错事件

类似 mount failed: exit status 32的报错很多,比如
1、nfs 挂载报错mount failed: exit status 32 是存储nfs不存在
2、 nfs 挂载报错mount failed: exit status 1 记不清了,反正在nfs的问题,试试挂载目录或者权限吧
3、 gfs 挂载报错mount failed: exit status 32 是指 node节点上没有安装 gfs的客户端
4、 gfs 挂载报错mount failed: exit status 1 可能是我们没有在gfs服务端创建要挂载的卷上面的不一定全对,提供一个思路,存储之类的报错通常都可以从pod的事件信息中得到的
3、configmap 问题
这个不是很常见,不过也出现过,在搞paas平台的时候,我们写应用通常要传入一些paas的变量,这个通过挂载configmap来获取,但因为奇奇怪怪的原因没挂上,就会出现了,或者简单点就是cm的名称写错了之类的
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
volumeMounts:
- mountPath: /tmp/
name: www
volumes:
- name: www
configMap:
name: nginx-config
返回
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m21s default-scheduler Successfully assigned default/nginx-59d6d76f78-2kh7n to vm-16-16-centos
Warning FailedMount 18s kubelet Unable to attach or mount volumes: unmounted volumes=[www], unattached volumes=[www kube-api-access-hvk9s]: timed out waiting for the condition
Warning FailedMount 13s (x9 over 2m21s) kubelet MountVolume.SetUp failed for volume "www" : configmap "nginx-config" not found
解决方法
每个人的环境不同解决方法也不一样,如果是自己写错了名称,改一下就OK
如果是别人开发的环境,那就只能找开发来看了这部分能想到的就这些,其他有的再补充
二、ErrImagePull 或者 ImagePullBackOff
1、仓库镜像问题
这种情况一般是镜像推送的流程有问题,我们做了ci/cd,但是在推送镜像的时候刚好赶上镜像仓库在清理镜像,那么就会有部分的仓库同步不到镜像,这样可能导致我们拉取镜像失败
,简单来说就是仓库没镜像
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1111111111 #不存在的镜像
imagePullPolicy: Always
name: nginx
volumeMounts:
- mountPath: /tmp/
name: www
volumes:
- name: www
configMap:
name: nginx-config


2、error syncing pod skipping failed to "StartContainer" for "POD" with RunContainerError: "runContainer" operation timeout: context deadline exceeded
情况1 初次安装后报错
这个报错好久没看到了,我隐约记得是在更新二进制的docker更新崩了后出现的
把docker和container 的文件清理掉重新安装即可
rm -rf /var/run/containerd/*
rm -rf /var/lib/docker/*情况2 运行中的pod出现这个
基本上和文件系统挂钩,我的docker数据目录是独立挂载的,停kubelet、kube-proxy、docker服务,将该文件系统内杀掉fuser -ck /docker文件系统 ,然后umount卸载目录 后清空docker内数据/var/lib/docker/* 重新初始化文件系统 mkfs.xxx docker挂载设备 重启所有服务恢复
情况3 公有云下的主机因位置原因IO极慢
等待IO恢复正常
三、Pending
pending状态其实涉及的方向有很多的这里先简单列举一下
1、 K8调度组件 scheduler 组件异常, 集群组件挂了
2、 sa 没有权限或者不存在
3、 用户指定的匹配节点策略有问题 (nodeselector 容忍、污点等等调度策略)
通常是应用用户标签写错了
4、 节点没有足够的资源满足调度 //测试环境通常资源较小,用户软限制太大无法调度
5、pv 卷问题
隐约记得还有几项的,但是想不起来了,想起来在加
四、CrashLoopBackOff 或者 ERROR
这种涉及到的方向也不少,这种情况我们大多数的时候都可以通过容器日志、容器服务日志得到答案
1、 容器服务配置有问题,导致容器服务的守护进程启动直接挂掉了,检查配置
2、容器健康检查探针检查端口不正常会杀死容器重启,
3、容器有什么启动后的操作,操作到一般发现跑不下去了,比如容器服务启动脚本里面有
//ftp 链接
//域名无法解析
//远程主机端口无法通讯等等
4、容器资源限制太小,内存软硬限制一般是1:1的 然后内存超出我们的硬限制后oom 导致容器重启报错五、Terminating或Unknown
这种资源一般情况下都是 大批量node节点掉线导致的,比如之前我们集群网络波动,(k8s在node失联后不会删除pod,而是标记为Terminating或Unknown)
1、等待node主机恢复,当宿主机恢复通讯后,kubelet会重新去找apiserver 确定pod状态
2、用户强制删除 #通过kubectl delete pod xxx --grace-period=0 --force 删除
#除非明确知道pod处于停止状态(比如node所在的虚拟机或物理机已经关机)
#否则不建议使用该方法,特别是sts类型的控制器,强制删除容易导致脑裂或数据丢失六、UnexpectedAdmissionError
说白了,就是node节点上磁盘满了,我们node写不进去日志了
你可以发现大量这种的pod都是来自于同一台node主机,你登陆node主机去把文件系统清理一下,然后批量删除掉这些pod
kubectl get pods -A | grep UnexpectedAdmissionError | awk '{print("kubectl delete pod ", $2, " -n ", $1)}' | /bin/bash七,一个误以为是K8问题的linux问题
我们K8集群环境有一天发现有个节点掉了(notready)登陆主机发现df -h命令阻塞无法使用
猜测为远程挂载存储异常,但主机数量非常多,不清楚是那里的存储导致的下面是解决方法
还原场景
//部署nfs服务
echo "/home/nfs *(rw,async,no_root_squash)" >> /etc/exports
//启动nfs
systemctl start nfs
//登陆客户端创建目录
mkdir -p /tmp/test1/
//挂载nfs
mount -t nfs 10.0.16.16:/home/nfs /tmp/test1/
//查看
df -h | grep /tmp/test1
这个前提是我们df -h 能用的情况下,下面我们演示df -h 不可用的情况怎么查询
//停止nfs服务
systemctl stop nfs
//查看df命令
df -h 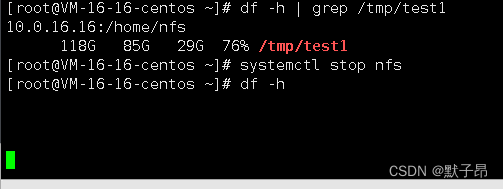
可以看到nfs挂掉后df -h已经阻塞不可用了,下面我们通过mount -l命令去查询挂载信息
mount -l | grep nfs 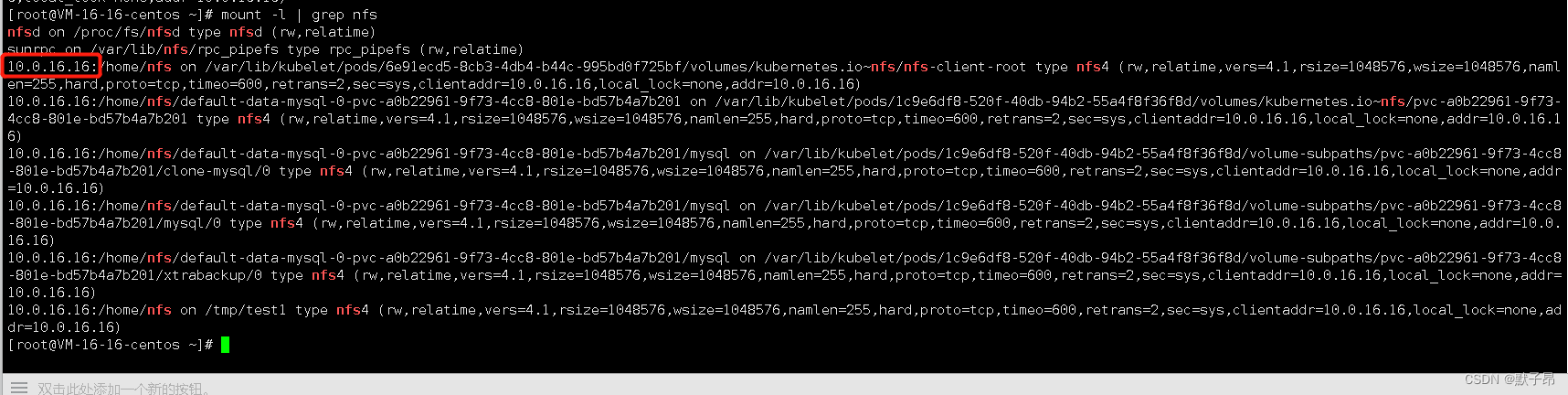
通过mount 命令我们得知nfs地址是10.0.16.16,登陆nfs主机重启服务恢复
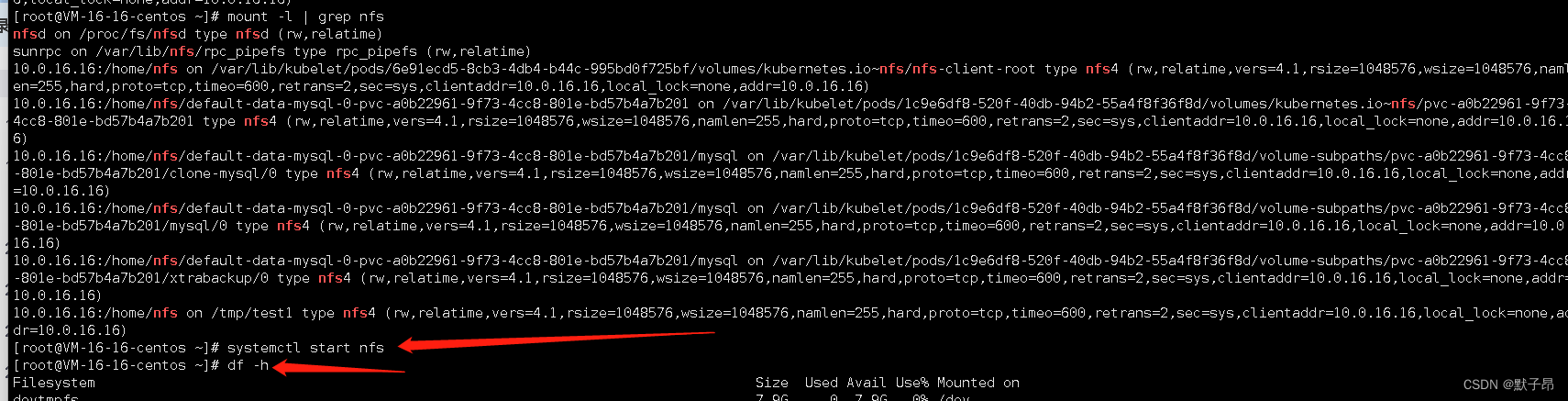
番外
1、docker无法启动
突然有几个环境node掉了,查看node组件,docker也起不来了,日志报错如下
Failed to start containerd: timeout waiting for containerd to start这个是节点的containerd服务卡死了,第一次碰到后重启node节点恢复了,但过几天又开始报这个,排查时发现有个周期脚本会定期重置node节点所有组件,包括挂载设备目录,有一个fuser -ck 挂载目录的操作,通过ps -ef | grep docker 发现有很多fuser -ck 僵死的进程,手动将他们kill -9 掉,发现dockerd服务弹出来了,但依旧无法启动docker服务,将docker-runc进程也kill掉后,重新挂载docker目录设备/var/lib/docker,发现docker可以正常重启了,未查明原因,随后补充
ps aux|grep docker|grep -v grep |awk '{print $2}'|xargs kill -9
systemctl start docker
#主要是杀掉"docker-runc init" 进程2、node节点状态反复横跳
有一天下午,集群突然大量开始进入not ready状态,一下就跳了几十台,但是在几分钟内就恢复了,还没郁闷又开始跳了,通过沟通得知有个应用在部署了一个ds的控制器,在每个node节点都启动了一个pod,但是配置存在问题pod在反复重启,刚开始都没觉得pod会影响到集群状态,之前重启几万次的pod不是没有,各种排查etcd、apiserver、kubelet日志反反复复了出来看,没看出个所以然,node节点的kubelet也没重启,突然想起来去年有个朋友说他们环境用deploy的某种方式替代了ds,说是ds有个什么bug导致集群崩掉,让应用先吧部署的ds删除了,但依旧存在问题,偶然间发现K8S管理的pod依旧被清理了,但是宿主机上docker依然能看到那些ds的容器UP状态,手动杀掉容器卡死,先杀进程在杀容器
ps -ef | grep docker | 容器id
kill pid
docker rm 容器id猜想可能是大量的ds报错导致apiserver压力较大导致的,很早之前在其他环境也碰到过类似的,不过都是单个node反复重启,会报个PLEG的错误,根据提示把对应容器给干掉就能恢复,后续观察补充
后续观测补充
#已知情况如下
1、kubelet无重启现象
2、从node主机ping master地址 网络无波动
3、master组件无重启现象,一切正常登陆node 看 kubelet 日志发现 PLEG is not healthy ,且间歇性报错,很符合node间歇性 notready的现象
kubelet的NodeStatus 机制会定时检查node的节点状态,包括cpu、内存、网络、磁盘、
docker进程等,并吧节点状况同步到apiserver,而PLEG就是检查机制的一部分,
他负责定义检查节点上的pod运行情况,并把pod的运行变化包装成event,发送给kubelet主同步机制syncloop处理,
kubelet在一个syncloop(默认10s)会调用PLEG的healthy()函数,healthy()函数会检查PLEG检查主进程是否在3分钟内完成,就会报PLEG is not healthy
而PLEG Healthy()核心是relist() 该函数负责重新通过容器运行时的rpc调用来获取list node上的所有容器(docker ps )与上一次执行的结果做对比,以此来判断容器的变化
//大致的意思就是说正常情况下relist的时间是1s ,但实际发生时为240s,超过了pleg的3分钟时间导致了超时
//kubelet因为pleg 超时了,所以上报了不健康的信息,最终在master上看着是node not ready,同时因为并不是每次操作都延迟,导致了每一次pleg正常,node就是ready,不正常就是notready的假象日志显示pleg超时原因
释放pod失败
容器名称(xxxxx) failed: rpc error: code = DeadlineExceeded desc = context deadline exce
PLEG记录pod状态失败
generic.go:397] Pleg: Write status for podmingc (*container,PodStatus)(nil)(err: rpc error code =Deadl孤儿pod 因为volume 还未移除删除不掉
Orphaned pod "pod名称" found, but volumes not yet removed因为pod 有容器信息状态异常,移除不掉
still has one or more containers in the non-exited state, Therefor , it will not be removed from
kubelet 主动记录了node notready的事件
Recording NodeNotReady event message for node xxxip
Node became not ready: {Type:Ready Status:False LastHeartbeatTime: 时间}总结
导致node节点反复不正常的原因是因为pod异常导致,这个pod可能因为服务本身存在问题或者和操作系统不适配导致容器进程起不来,会反复重启,而重启对于K8S来说实际上是新建了一个新的pod,然后删除了就的pod。
在删除过程中,K8S因容器挂载的volumes释放超时,会被认为pod并没有被删除,而到下一轮删除时,实际上容器已经被删除了,而K8S根据pod id去查询时,发现上一次标记的volume还没有释放,而cri 去拿不存在的容器肯定是失败的,于是K8S将pod放入下一轮轮询,最终PLEG检查查询该pod信息超时,导致了主动上报不健康
场景复现
我们可以创建启动后立刻挂掉的的pod,设置400个副本,尽可能多的挂载宿主机上的设备
复现
command:["sleep"] #让容器一创建就推出,反复重启
挂载很多个目录,让删除容器时间变长
解决方法
手动清理node主机上的死亡容器,清理反复重启的容器,升级K8S 版本,重启kubelet清理孤儿pod,强制删除pod等八、ContainerCannotRun
极其罕见的报错,通常和都和存储挂钩
//如下帖子里面写明的是pv相关,我碰到的居然是hostpath目录不存在导致,很奇怪
https://blog.51cto.com/u_7072753/5317617docker相关的一些问题
1、操作系统架构不同导致无法启动容器
操作系统架构不对,比如你之前是centos上部署的模板,突然环到麒麟操作系统上就用不了,或者同操作系统不同架构也用不了arm/amd
standard_init_linux.go:211: exec user process caused “exec format error“
#参考解决文档
https://blog.csdn.net/qq_50573146/article/details/1254981912、docker挂载失败导致的错误
#参考文档
https://huaweicloud.csdn.net/6331123ed3efff3090b5133b.html?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~activity-1-92657302-blog-88555132.pc_relevant_vip_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2~default~BlogCommendFromBaidu~activity-1-92657302-blog-88555132.pc_relevant_vip_default&utm_relevant_index=1
报错
docker: Error response from daemon: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: rootfs_linux.go:76: mounting "/docker/nginx/conf/nginx.conf" to rootfs at "/etc/nginx/nginx.conf" caused: mount through procfd: not a directory: unknown: Are you trying to mount a directory onto a file (or vice-versa)? Check if the specified host path exists and is the expected type.启动的命令
mkdir -p /docker/nginx/{www,conf,logs}
docker run -d -p 8081:80 --name nginxx --net host -v /docker/nginx/www:/usr/share/nginx/html -v /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf -v /docker/nginx/logs:/var/log/nginx nginx正确的命令
docker run -d -p 8081:80 --name nginxxx --net host -v /docker/nginx/www:/usr/share/nginx/html -v /docker/nginx/logs:/var/log/nginx nginx
#我们上面将空的配置文件挂载给去掉了,启动不会让配置文件消失prometheus相关的一些问题
1、间歇性监控不显示
prometheus常见的问题,基本上都是跑的好好的突然没数据了,通常情况下清理prometheus数据目录重启才能恢复
我这边解决其实也是清理数据目录,重启prometheus,这里说一下使用的资源比例
比如中小规模集群400台左右,使用率较高的情况
8C16G的prometheus 顶不住,不想3天两头崩的话扩容到8C24 或者8C32
大规模集群2000+以上,看具体使用吧
16C32G反正是不够用,最好扩容到64G内存2、时间不同步导致无法获取指标
遇到一个情况
有一些特殊集群需要模拟不同的时间,会将集群的时间进行修改
同时为了监控数据,prometheus时间也被修改了
这样,当我们想要获取监控指标就比较麻烦你
比如
curl prometheus是无法获取数据了,需要先同步当前主机到对应的时间才可获取9、pod驱逐(Evicted)
1、宿主机文件系统满了
可能有莫名其妙的文件把根宿主机根目录写满了也会报这个
2、临时存储使用过高
查看当前容器状态,Phase: Failed
the node was low on resource: ephemeral-storage. Container 容器名称
was using xxxx , which exceeds its request of 0, container pod名称
was using xxxx which exceeds its request of 0 我们在建容器的时候可能有一部分数据是使用的K8自带的临时存储,一般限制设置为10G,当然默认是没有配置的,具体看集群的配置,如果超出则被驱逐,也就是说pod 使用了emptydir 加上容器不挂载存储卷的配置的总存储了超出10G的数据就可能被驱逐,hostpath不计算在内,
其他
节点资源不足:当一个节点的资源(例如 CPU、内存)不足以满足容器的需求时,Kubernetes 可能会驱逐容器。这可能是由于节点资源过度紧张或者其他高优先级的 Pod 占用了节点的资源。
Pod 超过了调度策略的限制:Kubernetes 可以配置 Pod 的调度策略,例如 PodDisruptionBudget(PDB)或 Pod 的亲和性和反亲和性规则。如果一个 Pod 的调度被限制或被禁止,那么该 Pod 可能会被驱逐。
节点故障:如果节点发生故障或者变得不可达,Kubernetes 可能会将容器驱逐出该节点,以确保应用的高可用性。此时,Kubernetes 会尝试将 Pod 迁移到其他健康的节点上。
节点维护:当节点需要维护或升级时,Kubernetes 可能会将节点上的容器驱逐出去。这包括节点的操作系统更新、硬件维护或者其他需要离线维护节点的操作。
资源配额限制:如果 Pod 的资源请求超过了节点的资源配额限制,Kubernetes 可能会驱逐该 PodUnknown 主机状态异常
我之前碰到的主要情况是 宿主机node上面flanneld 达到上限后,主机重启flanneld服务无法启动,导致docker和kubelet组件异常, master上查是notready,pod状态处于unknown状态 可以理解为主机状态异常

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









