







计算指标/哑变量
另一种常用于统计建模或机器学习的转换方式是:将分类变量转换为“哑变量”或“指标矩阵”。
DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或 DataFrame(其值全为1和0)。pandas有一个get_dummies函数可以实现该功能。使用之前的一个DataFrame例子

=====================================
给指标DataFrame的列加上一个前缀,以便能够跟其他数据进行 合并。get_dummies的prefix参数可以实现该功能

=====================================
对于很大的数据,用这种方式构建多成员指标变量就会变得非常慢。最 好使用更低级的函数,将其写入NumPy数组,然后结果包装在DataFrame中。
字符串操作
Python能够成为流行的数据处理语言,部分原因是其简单易用的字符串和文本处理功能。大部分文本运算都直接做成了字符串对象的内置方法。对于更为复杂的模式匹配和文本操作,则可能需要用到正则表达式。pandas对此进行了加强,它使你能够对整组数据应用字符串表达式和正则表达式,而且能处理缺失数据。
字符串对象方法
对于许多字符串处理和脚本应用,内置的字符串方法已经能够满足要求了。以逗号分隔的字符串可以用split拆分成数段:
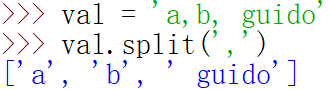
=====================================
split常常与strip一起使用,以去除空白符(包括换行符)
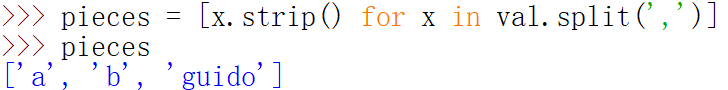
=====================================
利用加法,可以将这些子字符串以双冒号分隔符的形式连接起来

=====================================
但这种方式并不是很实用。一种更快更符合Python风格的方式是,向字符串"::"的 join方法传入一个列表或元组
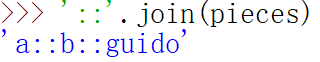
=====================================
其它方法关注的是子串定位。检测子串的最佳方式是利用Python的in关键字,还可 以使用index和find

=====================================
注意find和index的区别:如果找不到字符串,index将会引发一个异常(而不是返回 -1)

=====================================
count可以返回指定子串的出现次数
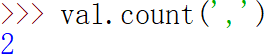
=====================================
replace用于将指定模式替换为另一个模式。通过传入空字符串,它也常常用于删除模式

++++++++++++++++++++++++++++++++++++















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









