







1. 线程 - 进程
进程是资源分配的最小单位,线程是CPU调度的最小单位
让我们来直观地理解一下:
【进程】> 【线程】
当你打开 matlab 或者 pycharm 或者 google 浏览器这些软件,一个进程就开启了,一个进程开启的过程相对复杂,需要调用内存空间、CPU 这些系统的资源,所以说:进程是资源分配的最小单位
那么线程呢?
我们都知道用 python 来实现 “多线程” 编程,这个过程,无非是把本来 主函数(主线程) 要做的事情进行拆分并同时进行计算。在多线程的程序中,CPU 在不同的线程之间进行轮询,并按照自己的方式给每个线程不同的时间来运算。所以说:线程是CPU调度的最小单位
在知乎上还看到一个很恰当的类比,在这里引用一下:
做个简单的比喻:进程=火车
- 线程=车厢线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
作者:知乎用户
链接:https://www.zhihu.com/question/25532384/answer/411179772
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2. 并行 - 并发
并行和并发描述的是 CPU 和任务之间 的关系,由于线程是CPU调度的最小单位,所以当然这个 “任务” 既可以是线程又可以是进程。
- 当 CPU 的核数够多,大于任务的总数,那么这个时候 CPU 不需要在不同的任务之间跑来跑去地处理,可以悠然地做到每个 CPU 核负责一个任务,这种情况叫做 “并行”
- 而当 CPU 的核数小于任务的总数,这个时候 CPU 必须在不同的任务之间进行轮询和处理,这个时候的状态叫做 “并发”
3. 同步 - 异步
结合上面的 并行 - 并发的概念,我们知道,只有在 CPU 并发处理任务的状态下才会产生同步和异步的问题。
【异步】
假设此时,CPU 并发执行 主线程、a线程、b线程;
异步处理的方式如下面代码所示:a、b 线程同时抢占CPU资源来更改全局变量 g_num 的值
import threading
import time
g_num = 0
def work1():
global g_num
for i in range(1000000):
g_num = g_num + 1
print(g_num)
def work2():
global g_num
for i in range(1000000):
g_num = g_num + 1
print(g_num)
if __name__ == '__main__':
a = threading.Thread(target=work1)
b = threading.Thread(target=work2)
a.start()
b.start()
while threading.active_count()!=1:
time.sleep(1)
print(g_num)
这种情况下,a 和 b 都不等待对方线程执行完毕的返回结果,而是同时抢占 CPU 资源对 g_num 进行更改, CPU 轮询到 a,a就更改,轮循到 b,b 就进行更改,最后的结果就是,很多情况下,一个线程还没有完成,另外一个线程就开始了 所以最后得到的结果:
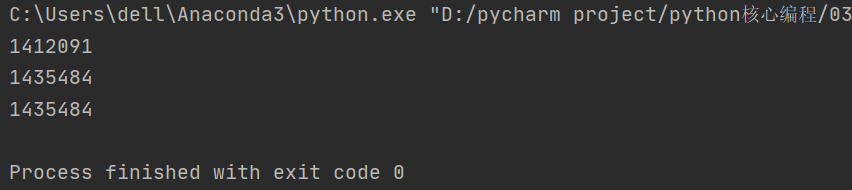
这种异步的弊端,在多个线程改变同一个公共数据的时候尤为明显。
【同步】
同步处理的方式如下面代码所示:a 先占用CPU的资源,得到a线程的运行结果的返回值之后,b 再占用CPU的资源,本质上相当于这两个线程合并成一个线程
import threading
import time
g_num = 0
def work1():
global g_num
for i in range(1000000):
g_num = g_num + 1
print(g_num)
def work2():
global g_num
for i in range(1000000):
g_num = g_num + 1
print(g_num)
if __name__ == '__main__':
a = threading.Thread(target=work1)
b = threading.Thread(target=work2)
a.start()
a.join() # 通过 join 来实现同步
b.start()
while threading.active_count()!=1:
time.sleep(1)
print(g_num)

可以看到结果,由于 a b 线程本质上通过 a.join() 的方式合并成了一个线程,所以不存在 a b 之间的 CPU 资源轮询和抢占,通过这种方式实现了线程之间的同步。
那这个时候有人要提出灵魂拷问了:
那既然,线程同步的操作相当于一个线程执行完再执行另外一个线程,那这和单线程有什么区别??
答:当然有区别,线程同步只有在多个线程都要对一个公共数据进行修改的时候才需要同步,在其他的时候还是异步地进行,比单线程的效率高得多。
















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











