







1. data.loc[index,column]
使用.loc[ ]第一个参数是行索引,第二个参数是列索引
import pandas as pd
data = pd.DataFrame([range(1,5),range(6,10),range(11,15)])
print(data)
dt = data.loc[0,1] //[index,column]
print(dt)
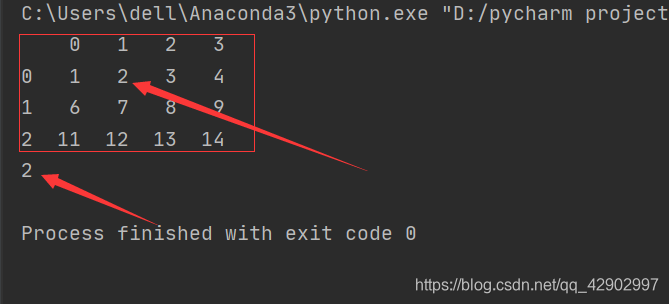
相当于第0行第1列
当然,还可以有如下操作,全部使用标签来作为行索引和列索引:
import pandas as pd
data = pd.DataFrame([range(1,5),range(6,10),range(11,15)],['第一行','第二行','第三行'],['第一列','第二列','第三列','第四列'])
print(data)
dt = data.loc['第一行','第三列']
print(dt)
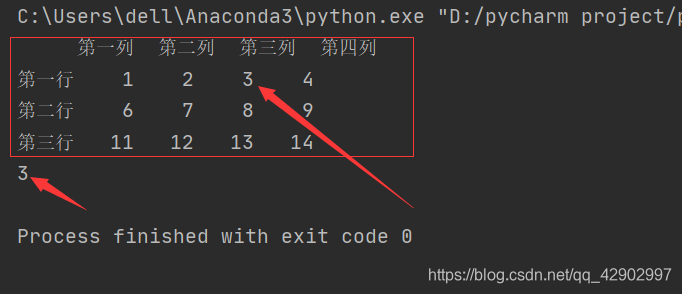
也可以有如下情况,使用数字作为行索引,标签作为列索引:
import pandas as pd
data = pd.DataFrame([range(1,5),range(6,10),range(11,15)],[0,1,2],['第一列','第二列','第三列','第四列'])
print(data)
dt = data.loc[0,'第三列']
print(dt)
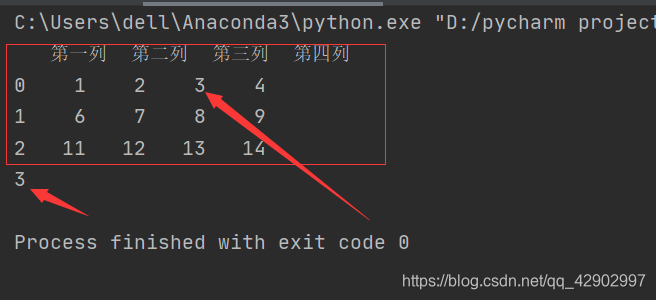
2. data[column][index]
这里与上面不同,使用两个方括号的索引方式,列标签的优先级更高一些,是列在前行在后。
import pandas as pd
data = pd.DataFrame([range(1,5),range(6,10),range(11,15)])
print(data,'\n')
print(data[2][0])
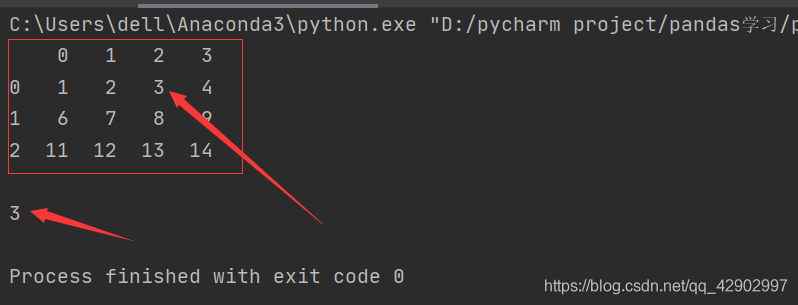
即使是在产生dataframe的时候把行列标签列的毫无歧义,也同样要满足列在前、行在后。
import pandas as pd
data = pd.DataFrame([range(1,5),range(6,10),range(11,15)],[0,1,2],['第一列','第二列','第三列','第四列'])
print(data,'\n')
print(data['第二列'][0])
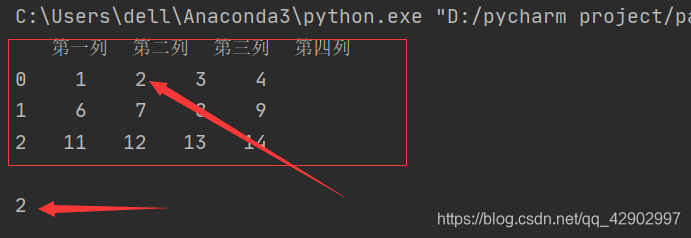
切记!!!!任何情况下如果直接使用data[][]的索引方式,第一个代表的都是列标签,如果行标签放在前面一定会出错。


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











