







文章目录
- Formal
- Agile
- Estimation 总结
- 扩展重点内容(Function Points)

Formal
- 决定 cost 的因素:
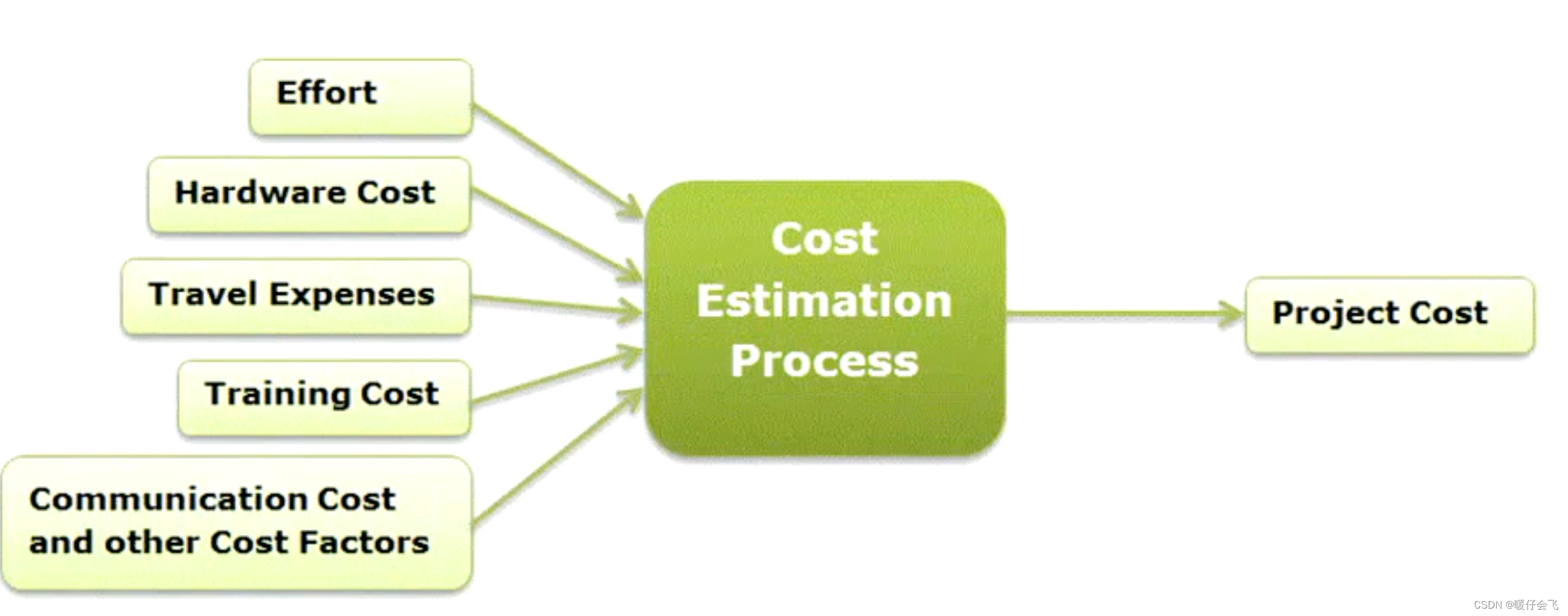
软件成本评估

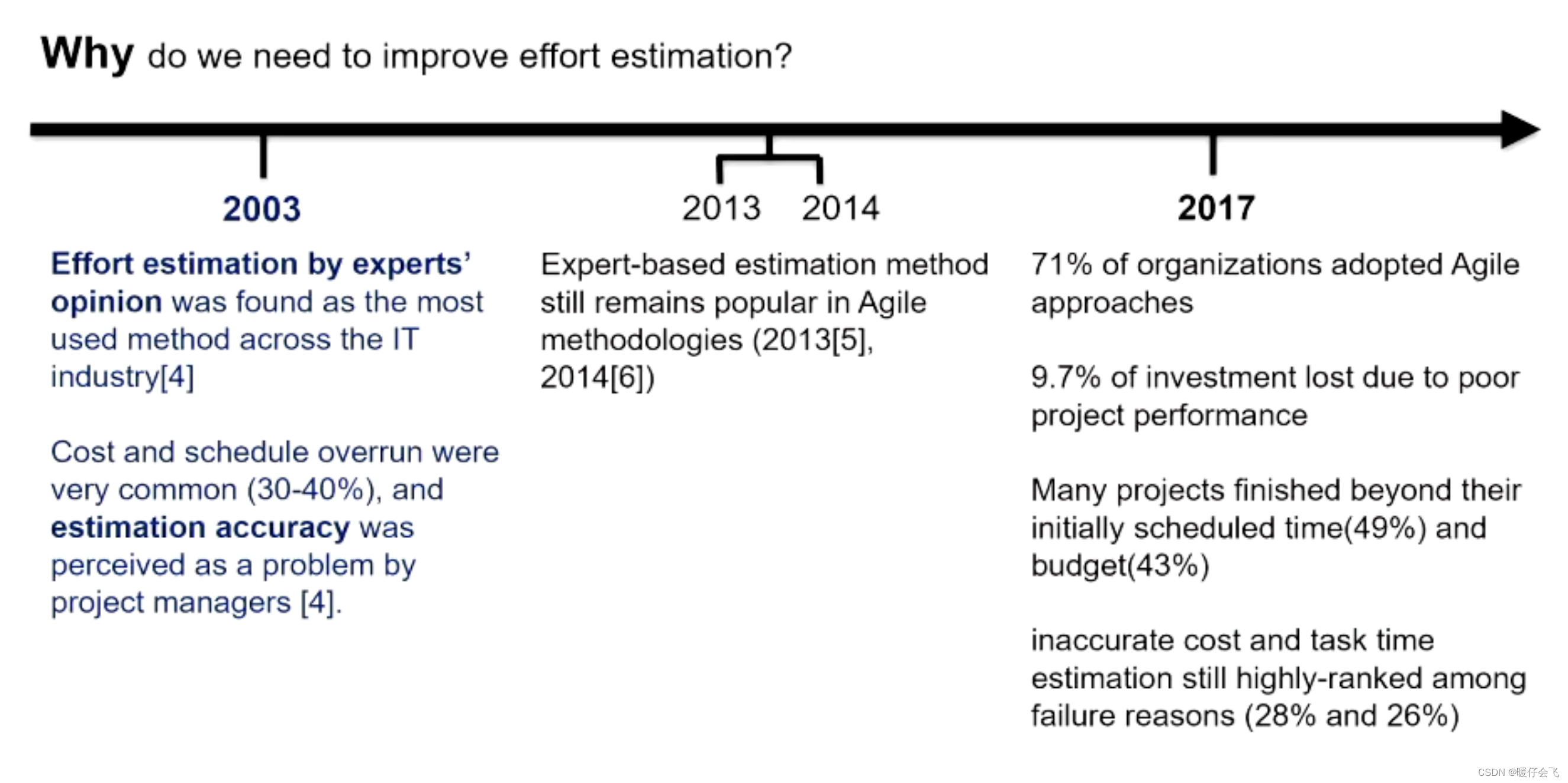
成本评估过程中的挑战(challenges)

- 没有具体的科学
- 中途的变化太多
- 大多数评估方法都假设事情会按照预期进行,只是简单地增加一些余量来应对可能出现的问题
可能的策略(possible solutions)

- 等到项目后期再评估(几乎没啥用)
- 通过过去的项目作为标准,大致评估
- 将系统工作切分成小的部分,单独评估,容易些
- 通过经验
可用的技术(Techniques)
Expert judgement

- Delphi technique:首先让专家们单独评分,算出平均分之后,让每个专家按照这个分数调整自己给出的分数,再求平均,直到所有专家都停止 revise
Analogy
Parkinson’s Law
Pricing to win

- analogy:根据之前的经验估算一个数值
- parkinson‘s law:工作总是会占满所有可用时间,因此 cost 取决于当前的所有可用资源,例如你有 3 个人, 12 个月的时间,那么 cost = 36个person months
- pricing to win:取决于客户出多少钱,出多少就是多少
Algorithmic cost modelling (算法成本模型)

Size 的衡量方式

- 通过代码的行数来评估一个项目的大小
- 通过 function 的数量来评估一个项目的大小
代码行数
- 逻辑上的代码行数:度量可执行“语句”的数量,但它们的特定定义与特定的计算机语言相关
- 实际的代码行数:实际执行的代码行数


*功能数量 (Funtion points)


- function points 的计算可以在项目的早期进行评估,因为他只依赖于requirements

Agile
Agile 中进行 estimation 的重要依据

- agile 的 effort 和 cost estimation 依靠于 story points 和 velocity
- velocity 的定义就是:在一段时间之内,能够交付的产品数量(用story points衡量),代表了团队的生产力
Agile estimation 流程

- 构建 user story
- 为每个 user story 分配 story point;使用选定的技术(稍后讨论),根据来自以前故事的故事点的数量估算每个故事的故事点数量。
- 使用团队从以前的经验中获得的速度来估计项目的交付时间——在固定范围发布计划的情况下,开发一个burndown chart。
- 在开发中,评估实际的 velocity
- 使用这个真实的 velocity 去重新评估项目交付的时间
Agile estimation guidelines (评估指导)

- 通过类比来确定这次的 user story 的分数分配情况
- 将 story 划分成多个 task,对每个 task 评分,最终作为一个 story 的 评分
- 使用正确的单位,不要讲 story point 划分太细。要使用几个固定的数值,例如只使用 1,2,4,8,12 或者斐波那契数列
- 通过整个团队来给 user story 分配分数
Agile 的 estimation techniques

Planning Poker
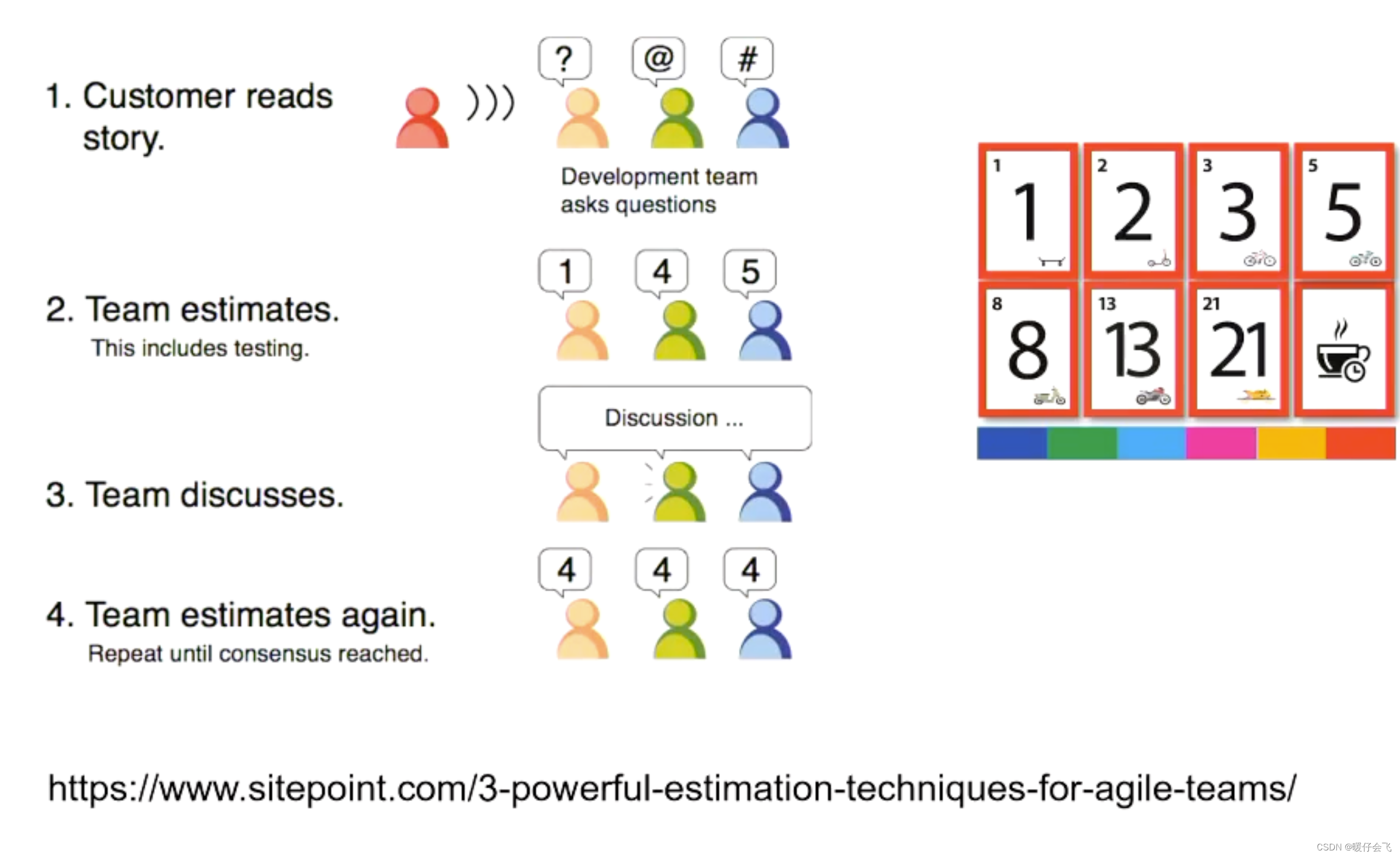
- customer 来读需求
- 针对成员的自己的理解,团队成员首先进行提问,并最终通过一组预先固定的数值中的值给出自己的评价分数
- 然后根据这些分数进行讨论
- 最终重新评估,直到 获得一致的分数
Bucket System

- 将所有的用户故事按照事先划分好的 bucket 进行分组
- bucket 的分数指定也可以按照上面的标准(斐波那契数列)

- 先将桌面上的 story card 任意选一张放在分数标记为 8 的 bucket 中
- 接下来的几张卡片每次随机抽取一张,讨论并达成一致意见,并相对于之前的卡片放置在一个桶中
- 然后分配给每个人一些卡片,并根据个人判断将它们放在适当的桶中(分治法)。
- 最后,团队审查了这些位置并达成共识
Relative Mass Valuation

- 放一张大桌子,这样故事就可以很容易地相对移动。
- 选择一个故事开始,团队估计他们是否认为它是相对的:大,中,小。
- 大故事放在桌子的一端。中间是中型故事,另一端是小型故事
- 继续执行步骤2和步骤3
- 下一步是根据故事在桌子上的位置分配分数值。从最简单的值得分值的故事开始,称它为1 然后向上移动卡片列表,为每个故事分配1的值,直到你到达一个看起来至少比第一个故事难两倍的故事。这个故事得2分。
Computing Velocity

- story points / day
Estimated Delivery Time
- 通过总的 story points 以及项目的速度,可以预估出项目完成的时间。

Estimation 总结

扩展重点内容(Function Points)
SRS (Software Requirements Specification)
- 一种指定对软件系统的期望的 文档;简称系统的要求

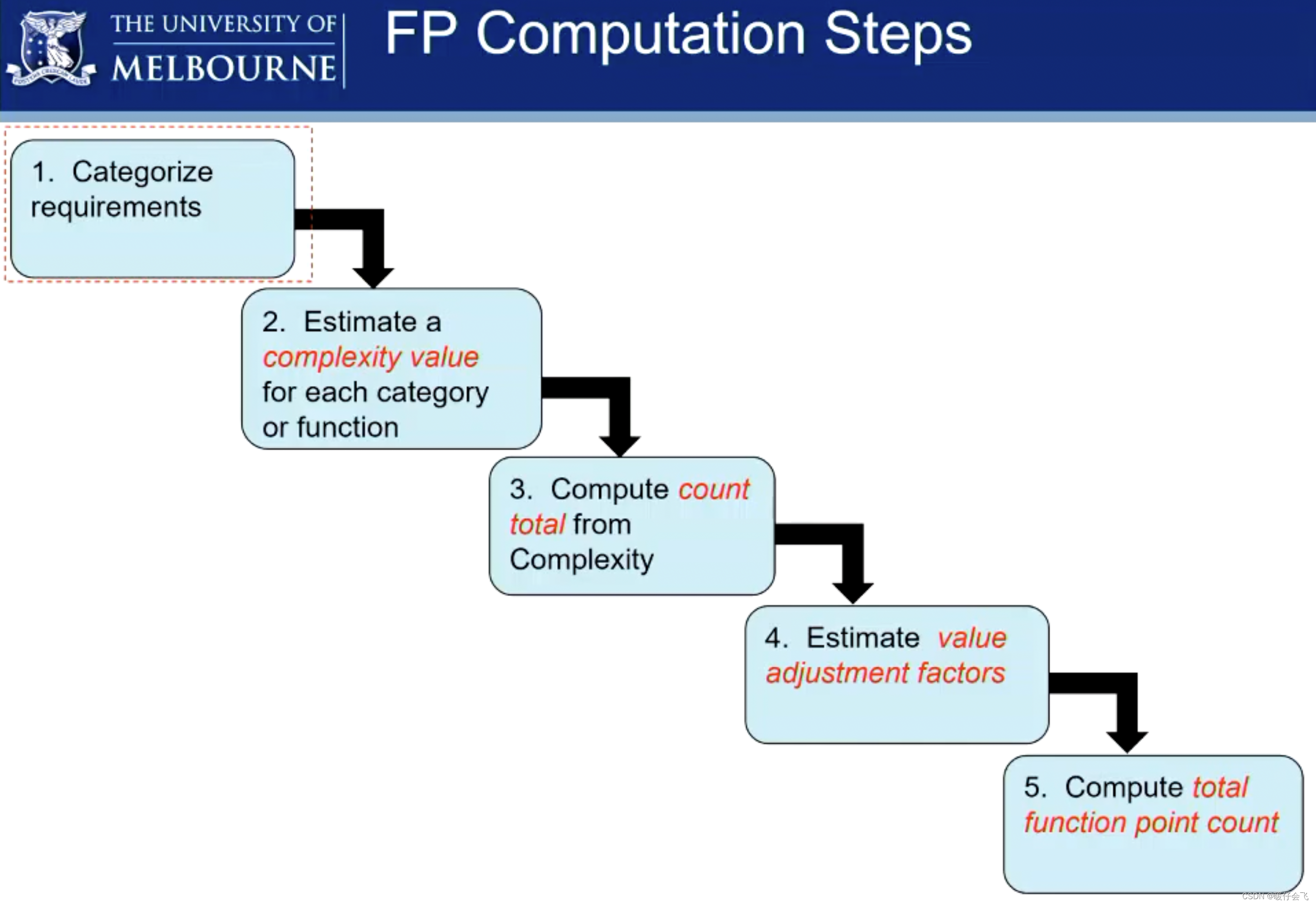
Function points 计算步骤
-
将这些需求进行分类
-
估计每个类别或功能的复杂度值
-
从复杂度计算总数
-
估算价值调整因子
-
计算总功能点计数
-
下面是一个具体的需求文档:包含了 7 个主要功能需求
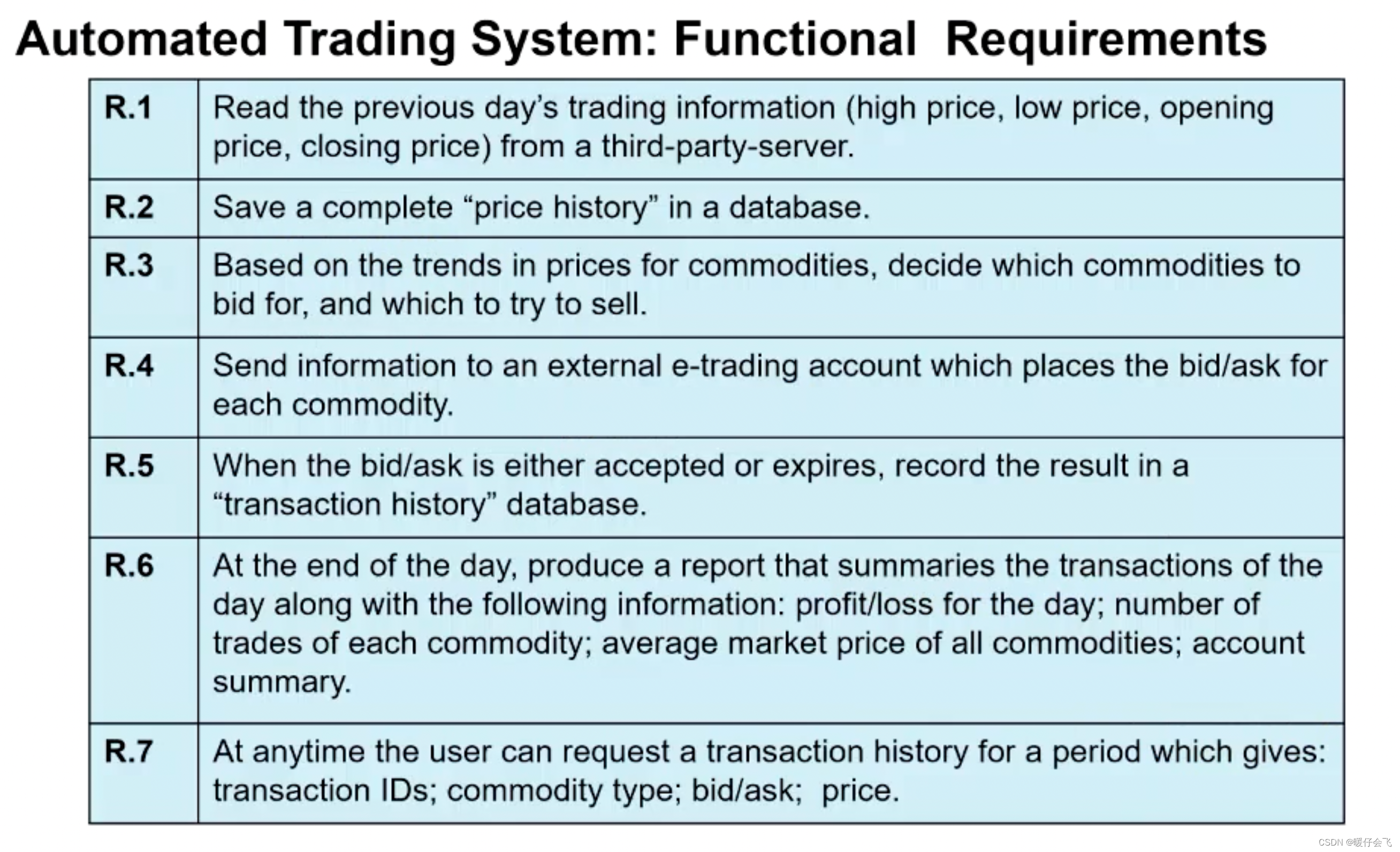
需求分类 (Categorize requirements)
- 分成 数据功能 和 事务功能
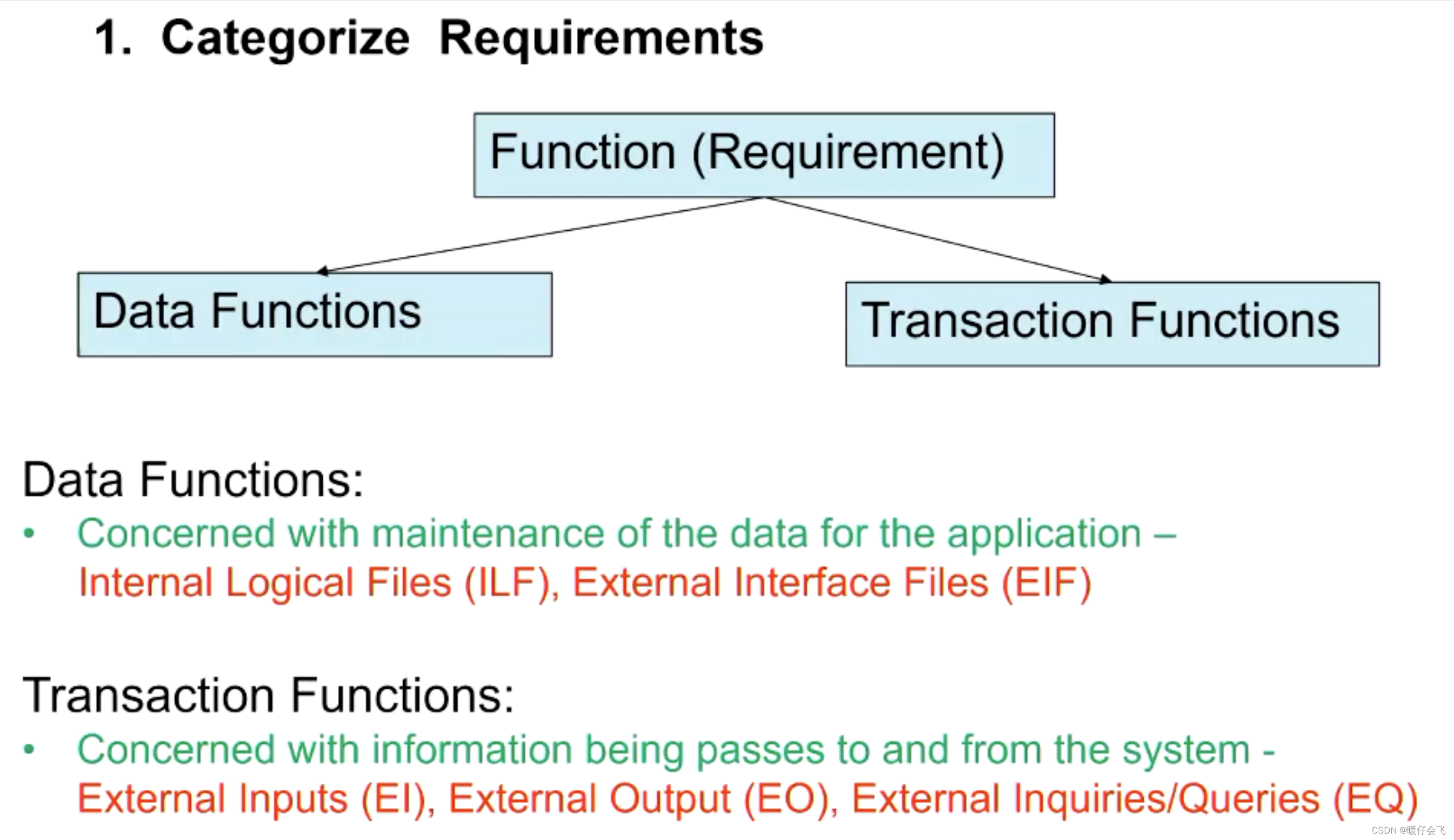
Data functions

Internal logical file (ILF)
- 数据是从外部输入进来的
- 系统自身对这些数据进行处理和维护:关系型数据库,包含用户设置的文件
External interface file (EIF)
数据在外部维护,但是可能被内部系统进行调用:第三方服务器提供的数据,这些数据维护了当前系统状态
Transactions Functions


External Input (EI)
- 从用户或另一个应用程序到系统的输入,用于控制系统的流程或提供数据。外部输入通常修改内部逻辑文件:由用户填充的数据字段、输入文件(例如编译器的程序源代码)。以及来自外部应用程序的文件提要。
External outputs (EO)
- 向用户提供有关系统状态的信息的输出 :显示给用户的示例屏幕、错误消息和报告。其中的各个数据字段被分组为一个外部输出
External Inqueries / Queries (EQ)
- 输入不用于更新内部逻辑文件,而是用于查询内部逻辑文件并提供输出;直接检索输出,不包括派生数据 :读取用户设置或从数据库表中读取记录的示例
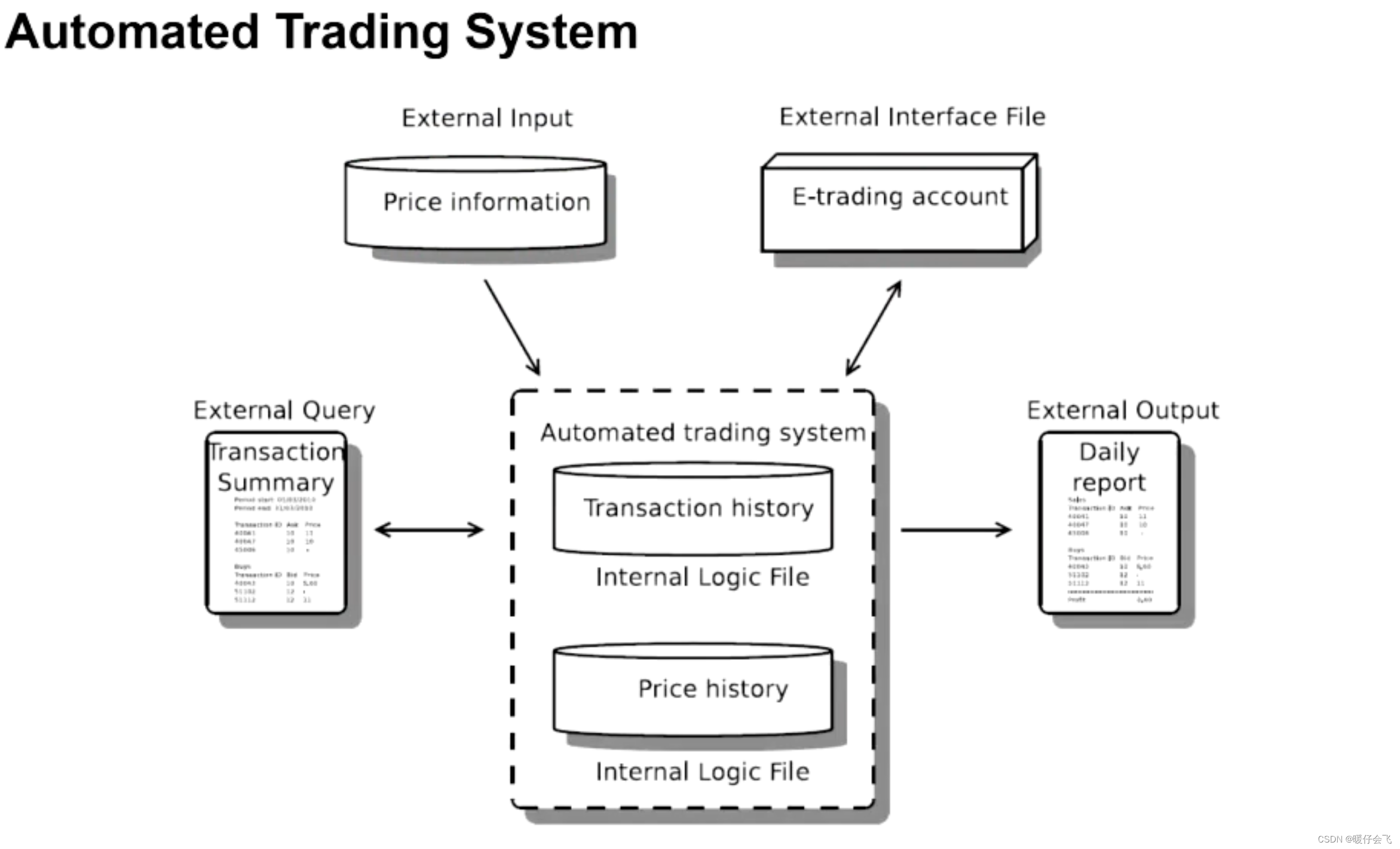

- 特别注意的是 R.4 这个 EIF 具有迷惑性,因为总体来说这个信息是当前系统发给一个 external 的系统,但是这个 external 的系统做的事情却是帮当前系统,因此属于 EIF.
评估每个类别或功能的复杂度值 (Estimate a complexity value for each category or function)

- 复杂度分为简单、平均或复杂。
- 通常是针对一个类别而不是针对每个需求
- 一种常用的技术是基于数据元素类型(DETs)、记录元素类型(RETs)和文件类型引用(FTRs)
- DETs: 系统中唯一的、用户可识别的、非重复的数据字段。比如在维护一个教育系统的时候,要维护学生的信息,这些学生的信息分为 Firstname, lastname, studentID 等,这些就属于数据元素类型
- RETs: ILF或EIF中用户可识别的数据元素子组
- **FTRs:**事务引用的文件(ILF或EIF文件)
DETs, RETs, FTRs
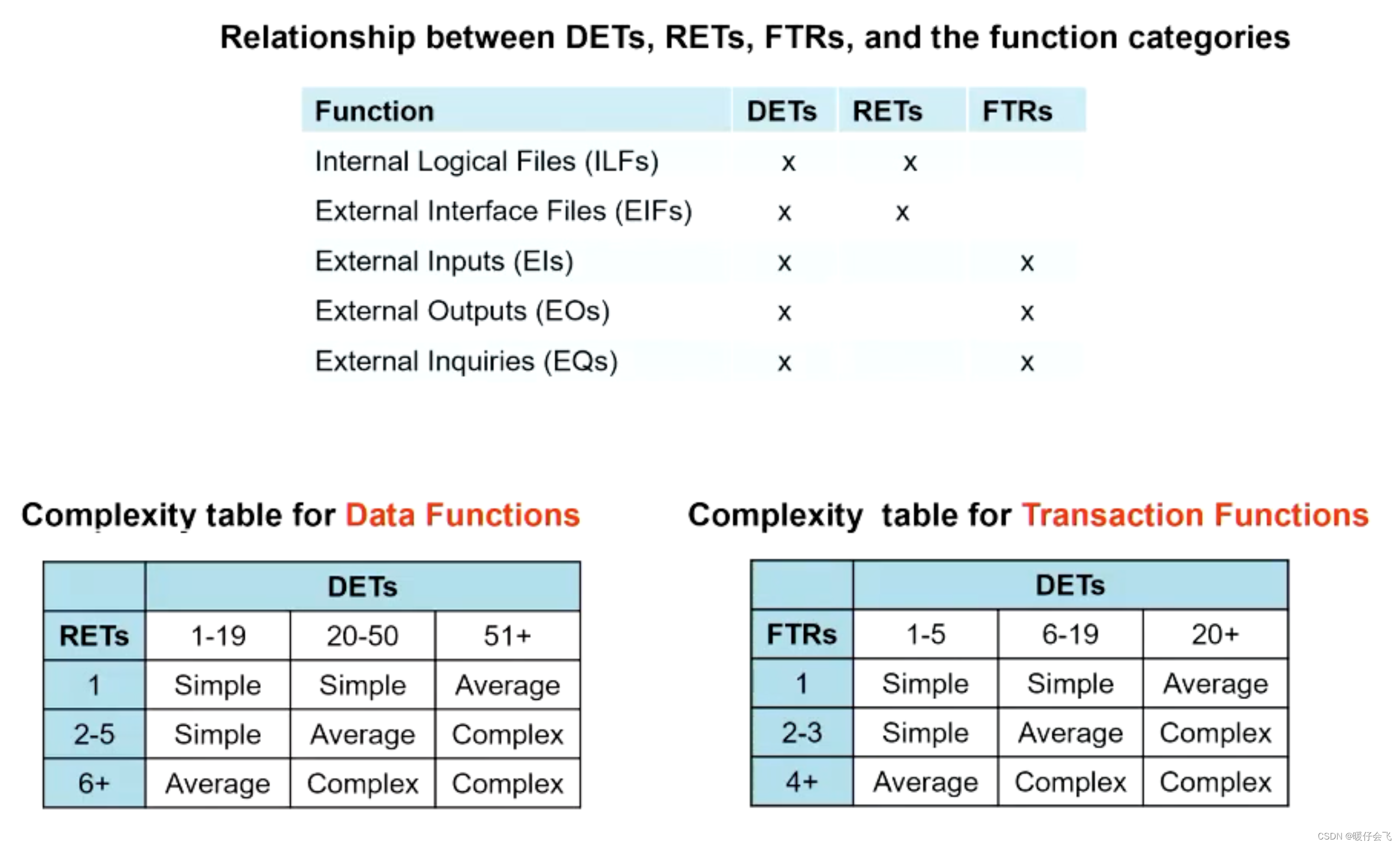
- 在 Data function 的需求类型中,衡量的指标是:DETs 和 RETs
- 在 Transaction function 的需求中,衡量的指标是:DETs 和 FTRs
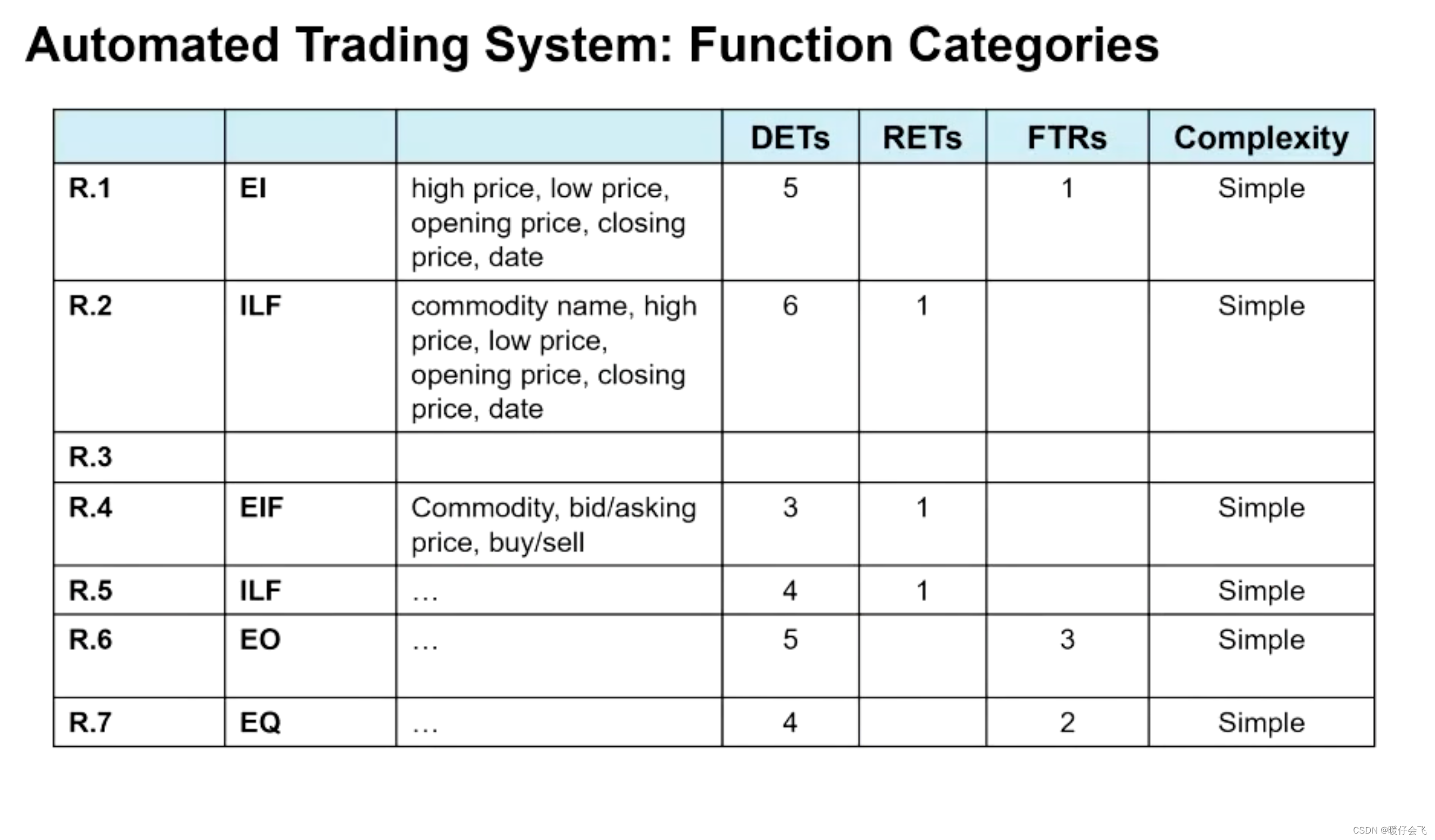
- 从图中可以看出,当评估 EI, EO, EQ 等 transaction function 的时候,只用到了 DETs 和 FTRs 指标,而 ILF 和 EIF 等 data function 评价的时候只用到了 DETs 和 RTEs 指标
从复杂度计算总估计值(Compute count total from Complexity)
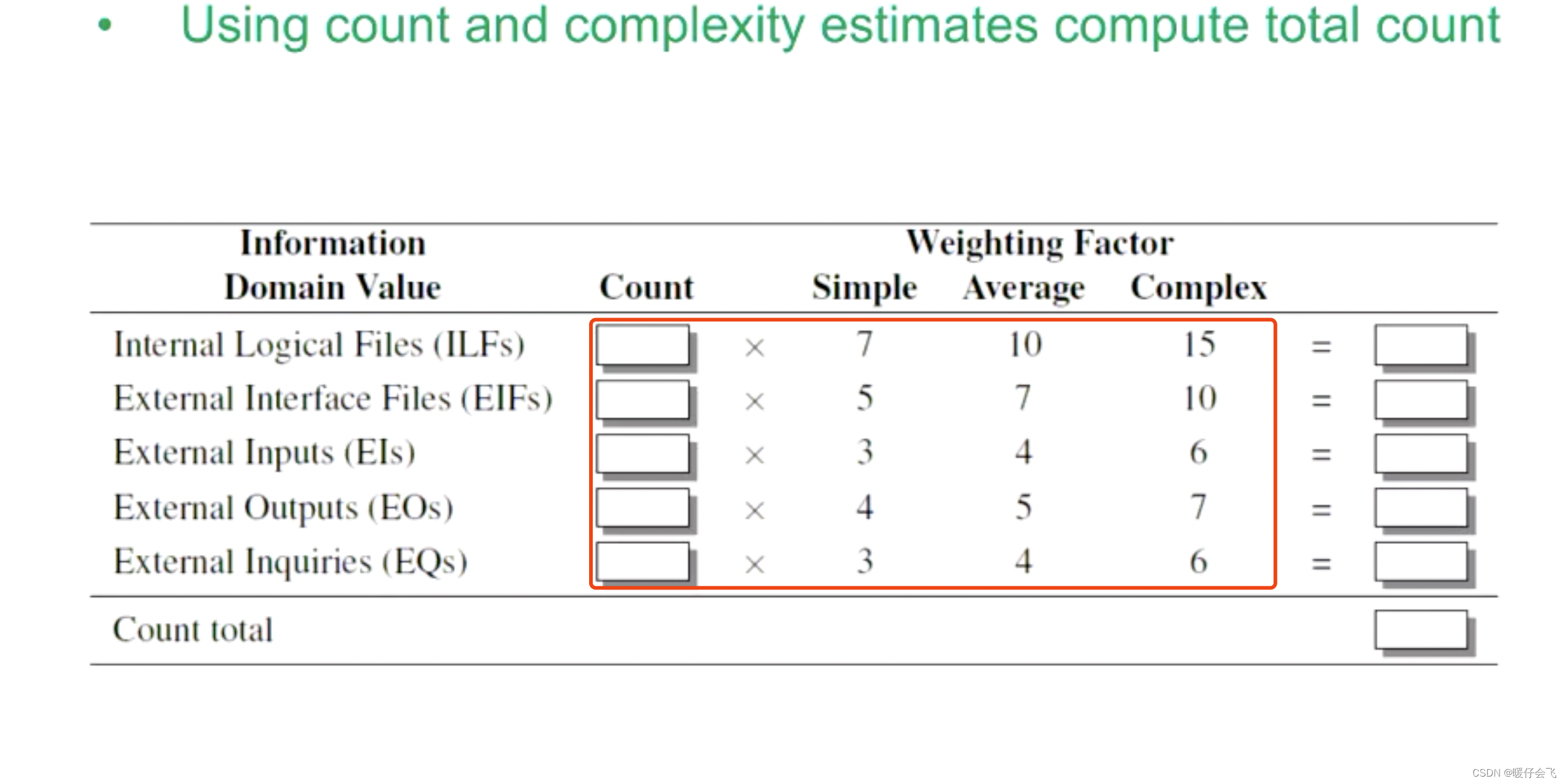
- 方法:使用 simple,average 和 complex 的数量,乘以他们各自占得权重,加权求和得到所有需求的总分数:
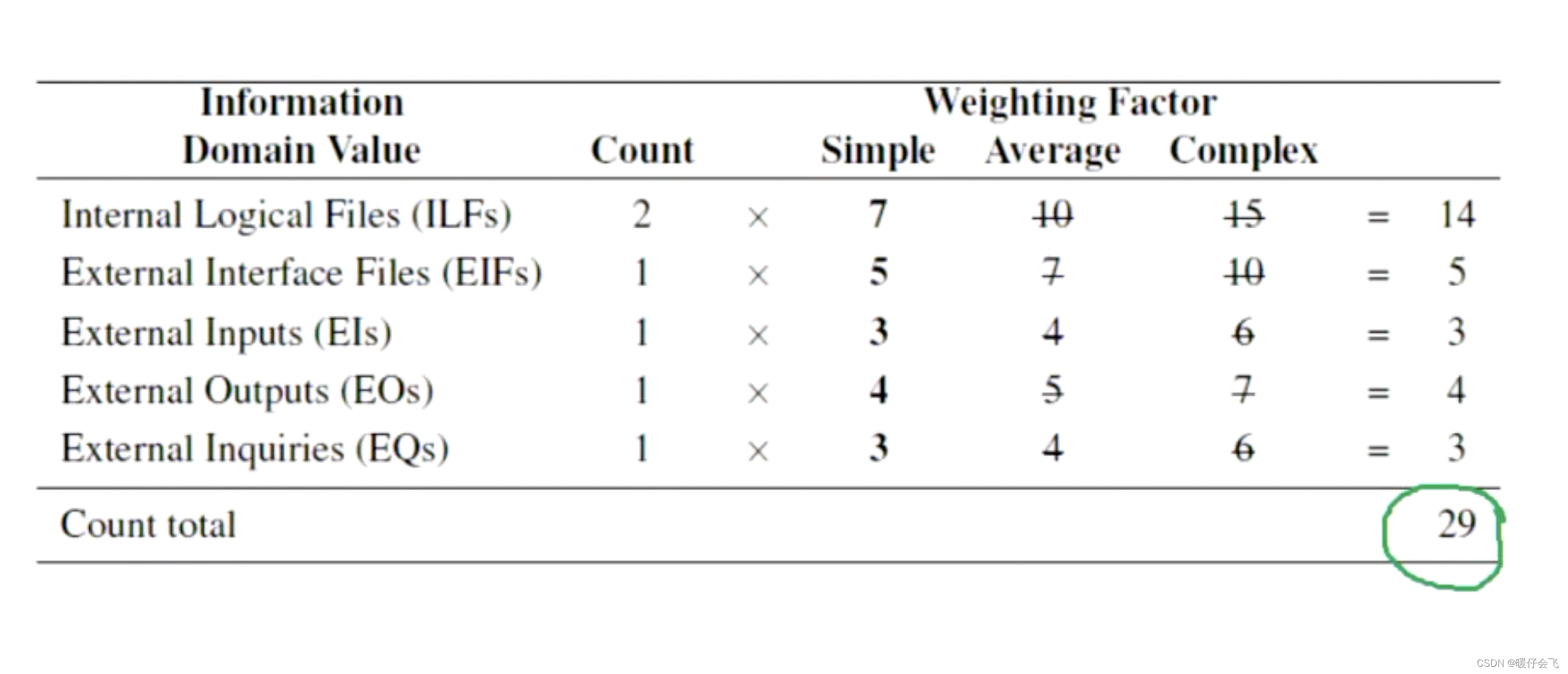
- 因为本文的实例中,无论是数据功能还是事务功能的评价都是简单,所以在上图中的 average 和 complex 选项的值都被划去了。最后计算的分数是 29
计算调整因子(Compute value adjustment factors)

- 是基于14个特征计算的
- 每个特征都有等级或0-5的范围;
- 0不重要,5重要

计算最终的 function point
- 将计数总数和值调整因子代入以下公式,以估计总计数


Function points 优缺点
优点

缺点



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











