






Prometheus+grafana监控系统-学习笔记
0.环境准备
| 环境 | 机器 | 内网地址 | 外网地址 | |
|---|---|---|---|---|
| 虚拟机 | Prometheus(docker服务提前安装好) | 10.0.1.132 | ||
| Linux(常规物理机器) | 10.0.1.133 | |||
| Linux--docker(主要运行各种容器服务) | 10.0.1.134 | |||
1.Prometheus介绍
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
官网:https://prometheus.io
项目代码:https://github.com/prometheus2.Prometheus组件与架构
2.1 Prometheus组件与架构示意图

2.2 Prometheus Server端

Prometheus Server端是Prometheus的核心。Prometheus本身是一个以进程方式启动,之后以多进程和多线程实现监控数据收集、计算、查询、更新、存储的一个C/S模型运行模式。
TSDB
Prometheus采用的是时间序列(time-series)的方式,以一种自定义的格式存储在本地硬盘上。Prometheus的本地时间序列数据库以每两小时为间隔来分块(block)存储,每一个块中又分为多个chunk文件,chunk文件是用来存放采集过来的数据的时间序列数据,元数据(metadata)和索引文件(index),索引文件是对指标(metrics)和标签(labels)进行索引后存储在chunk中,chunk是作为存储的基本单位,索引和元数据作为子集。
Prometheus平时是将采集过来的数据先都存放在内存之中以类似缓存的方式用于加快搜索和访问。当出现宕机时,Prometheus有一种保护机制叫做WAL(类似Oracle归档日志),可以将数据定期存入硬盘中,以Chunk来表示,并在重新启动时,用以恢复进内存。
Retrieval
用于将抓取(pull)的数据存入到TSDB中。
HTTP server
展示端以HTTP的方式从TSDB中获取监控数据。2.3 服务发现

Prometheus可以与其它开源的注册中心(例如Consul)组件进行集成实现自动服务发现功能,另外它还能通过定义配置文件来给Prometheus本身规定需要被监控的项目和被监控的节点。2.4 采集客户端

客户端主要有两种方式采集监控数据:
1.Pull-主动拉取方式
2.Pull主动拉取方式主要分三种类型:
2.1 Exporters:客户端(被监控机器)先安装各类已有exporters(由社区或企业、开发的监控客户端插件)在系统上,exporters以守护进程的模式运行并开始采集数据,由于exporter本身是一个http_server,Prometheus可以用pull的方式(Http get)主动去访问每个节点上exporter并采集回需要的数据(K-V形式的监控数据);
2.2 Jobs:应用系统通过集成Prometheus的形式,开发符合Prometheus接口规范的监控数据查询接口供Prometheus服务端拉取采集的监控数据;
Push gateway:Prometheus服务端以pull的方式从Push gateway中采集需要的监控数据;
2.3 Push-被动推送方式
此种方式适用于临时性的监控任务,应用系统运行自己开发的各种脚本,把监控数据组织成k-v的形式发送给push gateway之后,Prometheus服务端再通过pull方式从push gateway中获取推送的监控数据。这种采集方式相对于Prometheus服务端是一种被动的数据采集模式。2.5 报警端

报警端(Alertmanager)是用于监控数据的报警模块,支持通过多种方式去发送预警,比如短信、邮件、企业微信、钉钉等。Prometheus的警报数据是在 Prometheus服务端中依据配置的警报规则(Alert Rule)计算并产生,当产生报警信息时会将报警信息推送给altermanager,由altermanager通过配置的渠道将报警信息发送给相关人员。
Alertmanager的目标不是简单地“发出警报”,而是“发出高质量的警报”。它提供的高级功能包括但不限于:
1.可以通过模板渲染警报内容;
2.通过配置参数管理警报的重复提醒时机与消除后消除通知的发送;
3.根据标签定义警报路由,实现警报的优先级、接收人划分,并针对不同的优先级和接收人定制不同的发送策略;
4.将同类型警报打包成一条通知发送出去,降低警报通知的频率;
5.支持静默规则: 用户可以定义一条静默规则,在一段时间内停止发送部分特定的警报;
6.支持“抑制”规则(Inhibition Rule): 用户可以定义一条“抑制”规则,规定在某种警报发生时,不发送另一种警报;2.6 可视化端

Prometheus本身自带了图形成型界面Prometheus UI,Prometheus UI提供了基本的数据可视化能力,可以帮助用户直接使用PromQL查询数据,并将数据通过可视化图表的方式进行展示,如下图所示:

此图表展现方式单一,满足不了人们对可视化的要求,Prometheus通过与 Grafana集成,解决了Prometheus可视化的需求,Grafana展示效果如下图所示:

Grafana除了提供灵活的可视化定制能力以外,还提供了面向企业的组织级管理能力。在Grafana中Dashboard是属于一个组织,通过组织,可以在更大规模上使用Grafana,例如对于一个企业而言,我们可以创建多个组织,其中一个用户可以属于一个或多个不同的组织。 并且在不同的组织下,可以为用户赋予不同的权限。 从而可以有效的根据企业的组织架构定义整个管理模型。2.7 Prometheus Server集群

Prometheus Server集群方案通过部署多套Prometheus Server,采集相同的Targets即可实现。
基于此模式只能确保Prometheus服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Prometheus Server也不会频繁发生迁移的情况,并且只需要确保短周期监控数据的场景。2.8 远程存储

Prometheus的本地存储设计可以减少其自身运维和管理的复杂度,同时能够满足大部分用户监控规模的需求。但是本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展和迁移。
为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口将数据保存到任意第三方的存储服务中,这种方式在Prometheus中称为远程存储。2.9 Alertmanager集群
Prometheus Server高可用的情况下,单个alertmanager容易引发单点故障,解决该问题的直接方式就是部署多套Alertmanager,但是由于Alertmanager之间存在并不了解彼此的情况,因此会引发报警通知被不同的Alertmanager重复发送多次的问题。为了解决这一问题,Alertmanager引入了Gossip机制,保证多个Alertmanager之间的信息传递,确保多个Alertmanager分别接收到相同报警信息的情况下,也只有一个报警通知被发送给接收方。
Gossip协议是分布式系统中被广泛使用的协议,用于实现分布式节点之间的信息交换和状态同步。当报警信息发送完成后,Gossip会通知其他Alertmanager实例当前报警已经发送,其它实例收到Gossip信息后,则会在自己的数据库中保存该通知已发送的记录而不再对外发送相同的信息。
Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP,即可用性和分区容错性,同时对于Prometheus Server而言保持了配置简单,Prometheus Server之间不需要任何的状态同步。2.10 联邦集群
由于Prometheus基于Pull模型,当有大量的Target需要采集样本时,单一Prometheus实例在抓取数据时会出现性能问题,联邦集群的特性可以让Prometheus将样本采集任务划分到不同的Prometheus实例中,并且通过一个统一的中心节点进行聚合,从而可以使Prometheus根据规模进行扩展。
如上图所示,将监控目标分成不同的区域,每个区域部署单独的Prometheus Server,用于采集当前区域的监控数据。并由一个中心的Prometheus Server负责聚合多个区域的监控数据。这一特性在Prometheus中称为联邦集群。3.部署Prometheus监控系统
3.1本次实战所需文件链接:
本次实战所需文件链接: https://pan.baidu.com/s/1KNDVUluas6O1Ya092liIEQ?pwd=4356
适用于监控docker容器仪表盘插件:
链接:https://pan.baidu.com/s/1PmbGkCvsxflw04Y-RsaHOw?pwd=4356
本次实战所需文件链接:https://pan.baidu.com/s/1KNDVUluas6O1Ya092liIEQ?pwd=43563.2 如何监控?
如何来监控?
如果要想监控,前提是能获取被监控端指标数据,并且这个
数据格式必须遵循Prometheus数据模型,这样才能识别和
采集,一般使用exporter提供监控指标数据。
exporter列表:
https://prometheus.io/docs/instrumenting/exporters
部署文档:https://prometheus.io/docs/prometheus/latest/installation/
node_exporter:用于监控Linux系统的指标采集器。
使用文档:https://prometheus.io/docs/guides/node-exporter/
项目代码:https://github.com/prometheus/node_exporter
部署Grafana可视化系统:
部署文档:https://grafana.com/grafana/download
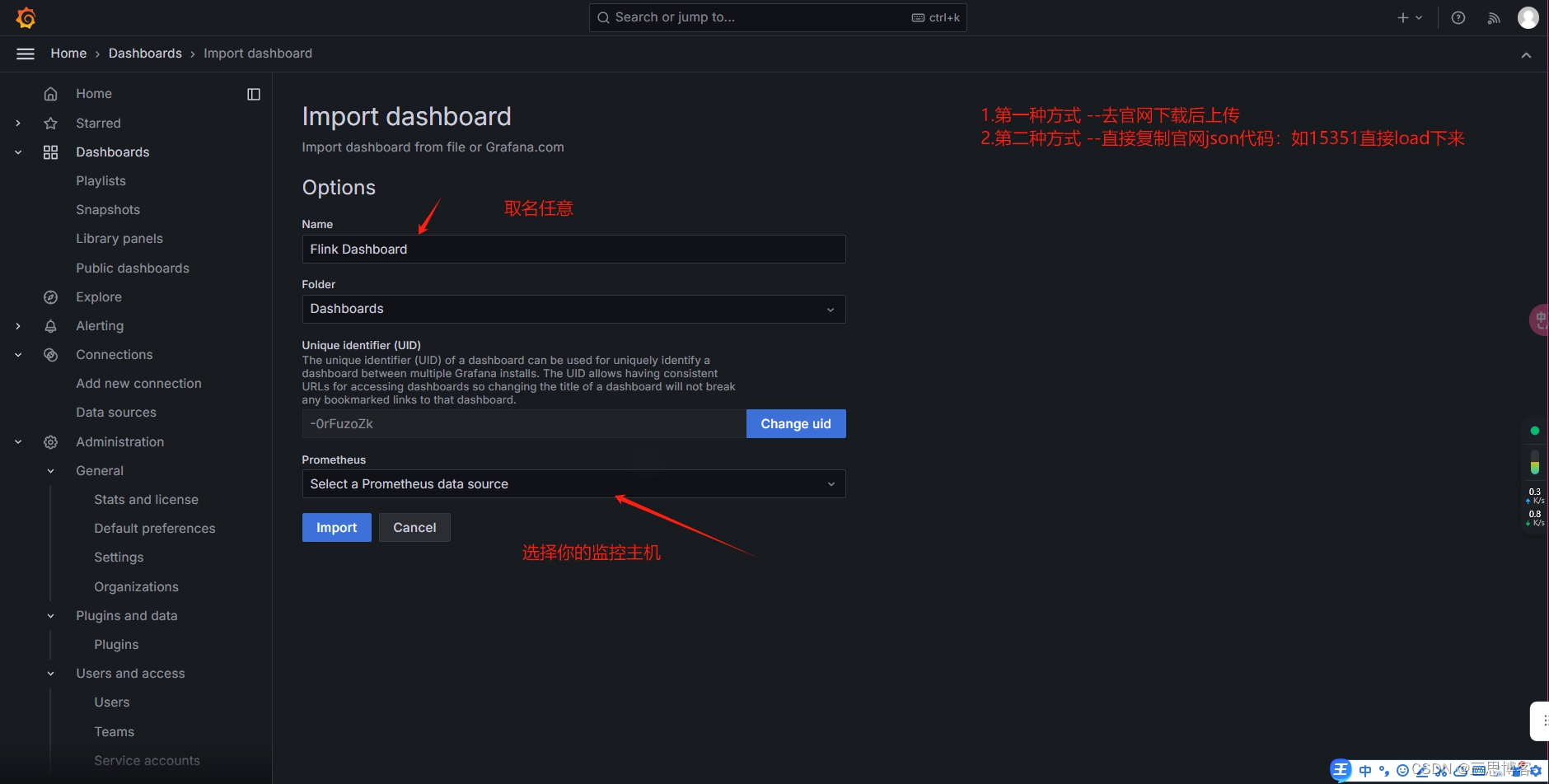
使用Grafana展示node_exporter数据指标,先导入仪表盘文件
仪表盘模板下载:https://grafana.com/grafana/dashboards/?spm=5176.28103460.0.0.f8aa3da2Xt1Lut
cAdvisor(Container Advisor):用于收集正在运行的容器资源使用和性能信息。
项目代码:https://github.com/google/cadvisor··
4. prometheus+grafana监控主机和docker-流程梳理
#docker部署Prometheus
docker run -d \
--name=prometheus \
-v $PWD/prometheus.yml:/etc/prometheus/prometheus.yml \
-v prometheus-data:/prometheus \
-p 9090:9090 \
prom/prometheus
#docker部署grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana
#Prometheus(web)页面查看
流程在下面
#grafana web页面配置
默认账号:admin
默认密码:admin
#部署Prometheus+grafana可视化
流程图在下面
#上传node_porter文件到需要被监控的机器上
node_exporter:用于监控Linux系统的指标采集器。
使用文档:https://prometheus.io/docs/guides/node-exporter/
项目代码:https://github.com/prometheus/node_exporter
#配置node采集器守护进程自启动
cd /usr/local/
rz
tar zxvf node_exporter-1.5.0.linux-amd64.tar.gz
mv node_exporter-1.5.0.linux-amd64 node_exporter
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
[Service]
ExecStart=/usr/local/node_exporter/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start node_exporter
systemctl restart node_exporter
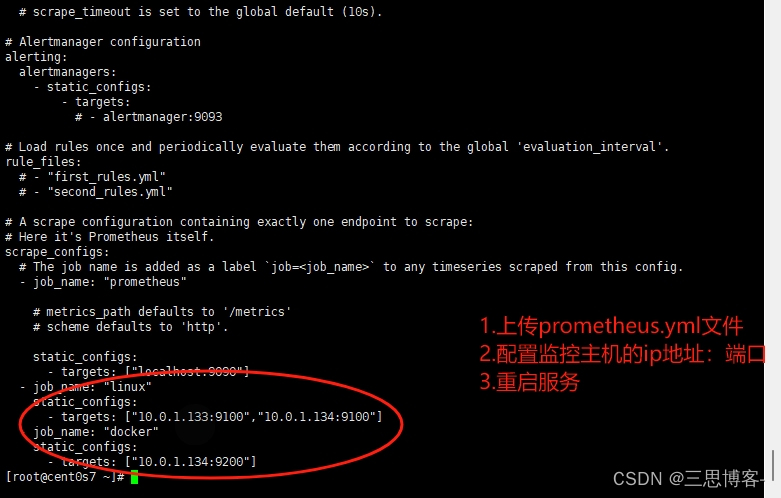
#Prometheus服务器上添加要健康的主机ip和端口
rz
[root@cent0s7 ~]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
#在最后这边添加你需要监控的主机ip和端口,注意格式
static_configs:
- targets: ["localhost:9090"]
- job_name: "linux"
static_configs:
- targets: ["10.0.1.133:9100","10.0.1.134:9100"]
- job_name: "docker"
static_configs:
- targets: ["10.0.1.134:9200"]
#重启Prometheus服务
docker restart prometheus
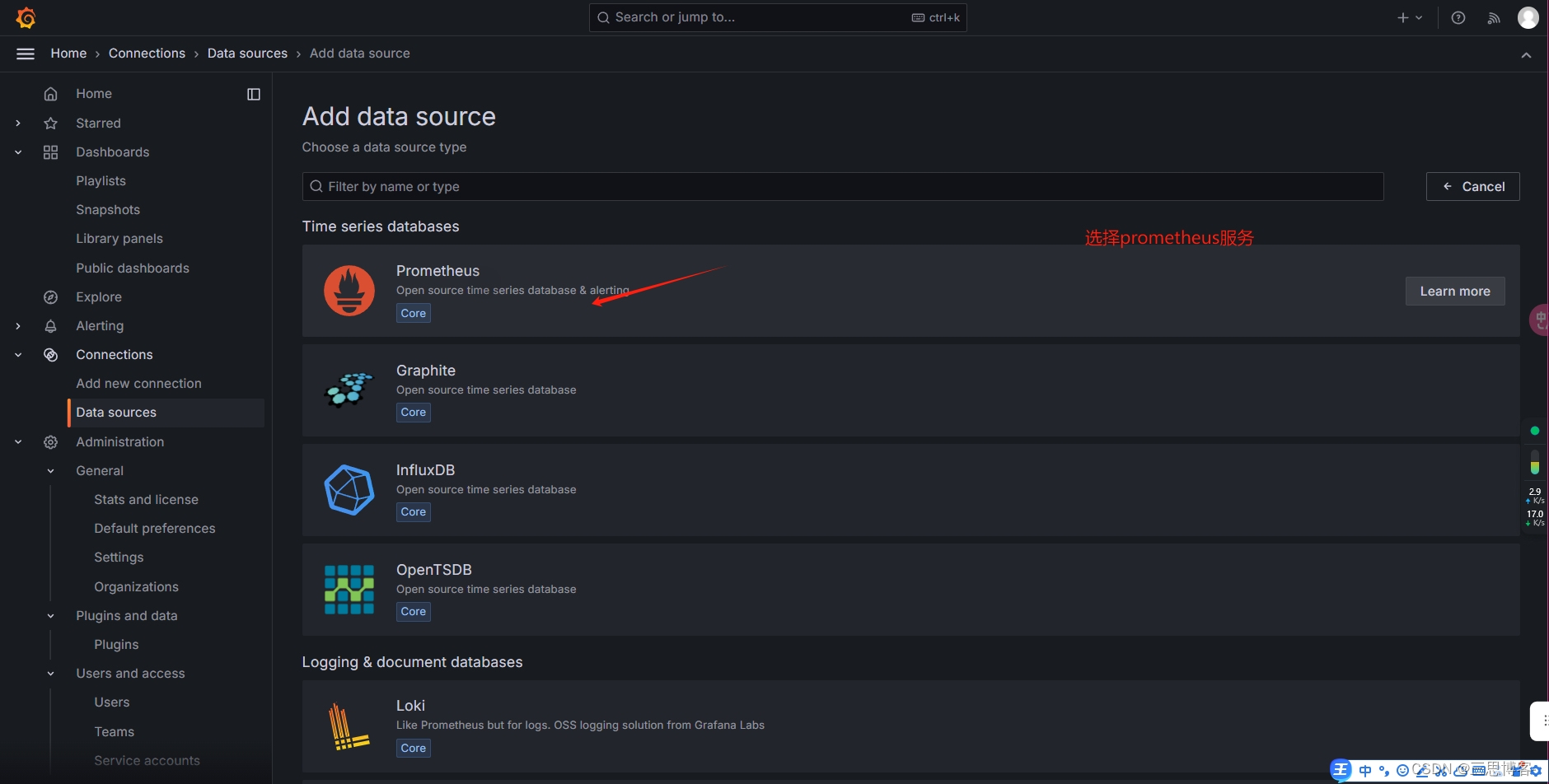
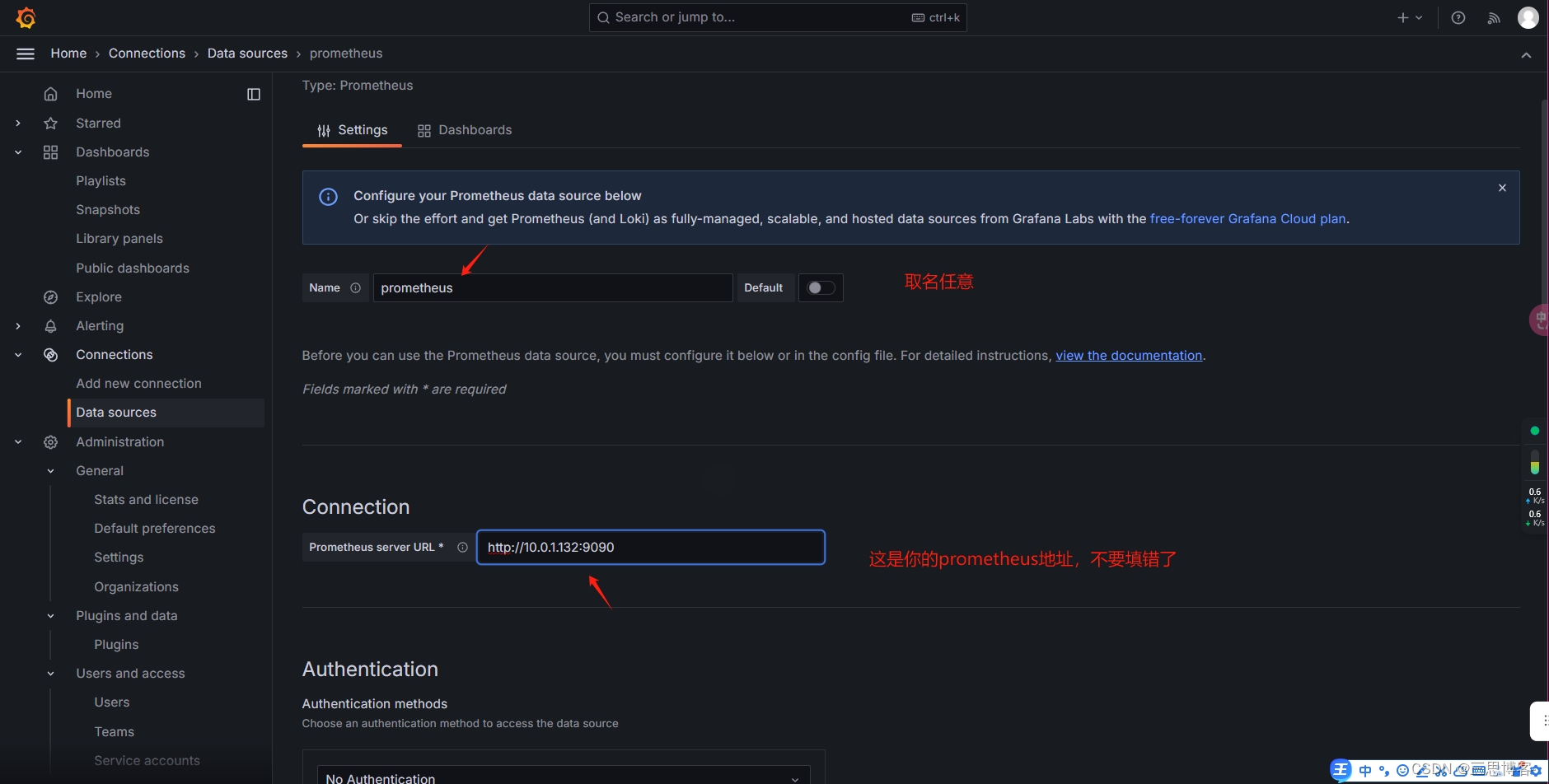
#配置grafana连接Prometheus数据源
Prometheus web页面地址:http://10.0.1.132:9090
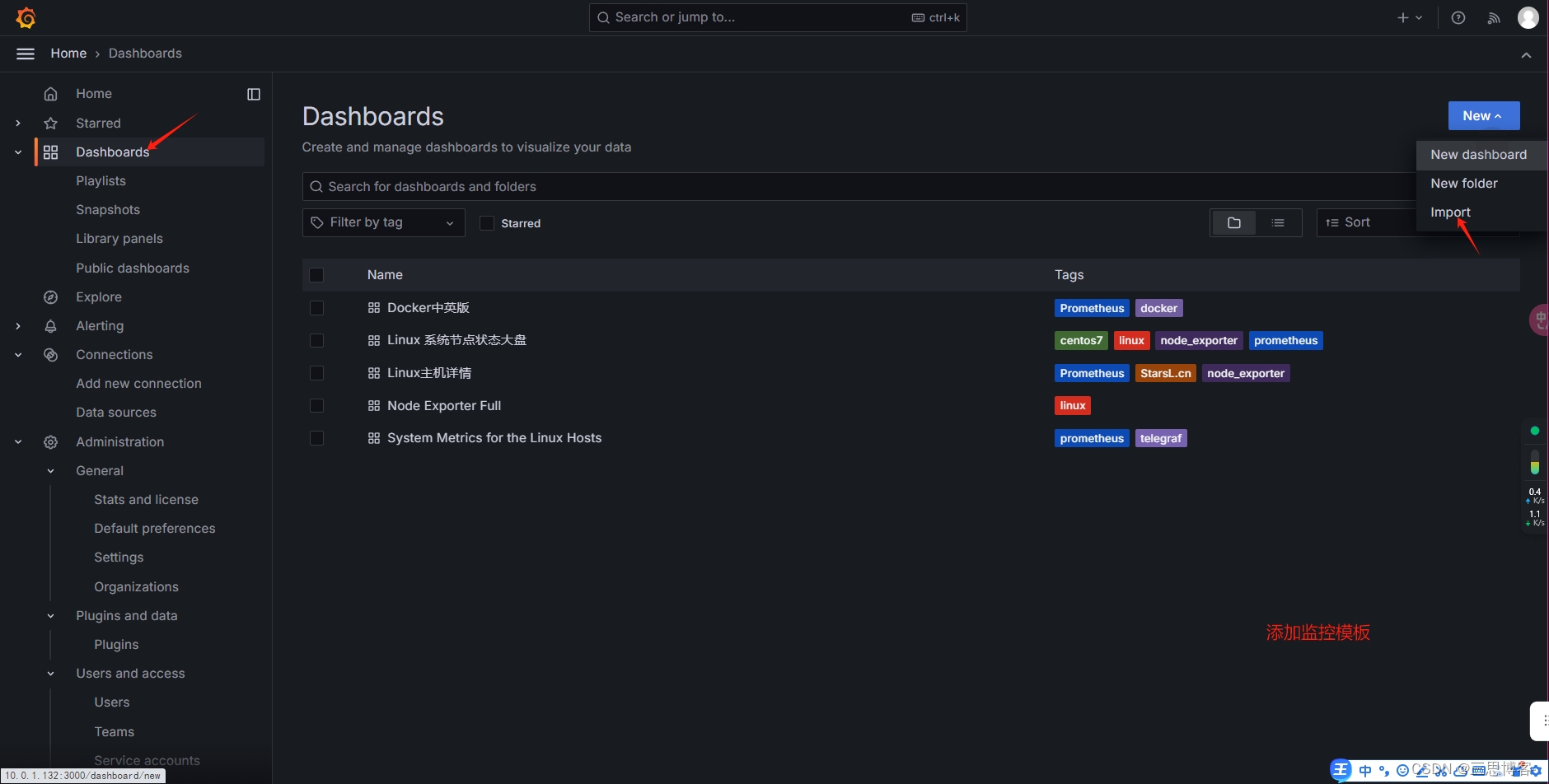
#下载或者上次监控仪表盘模板
流程图在下面
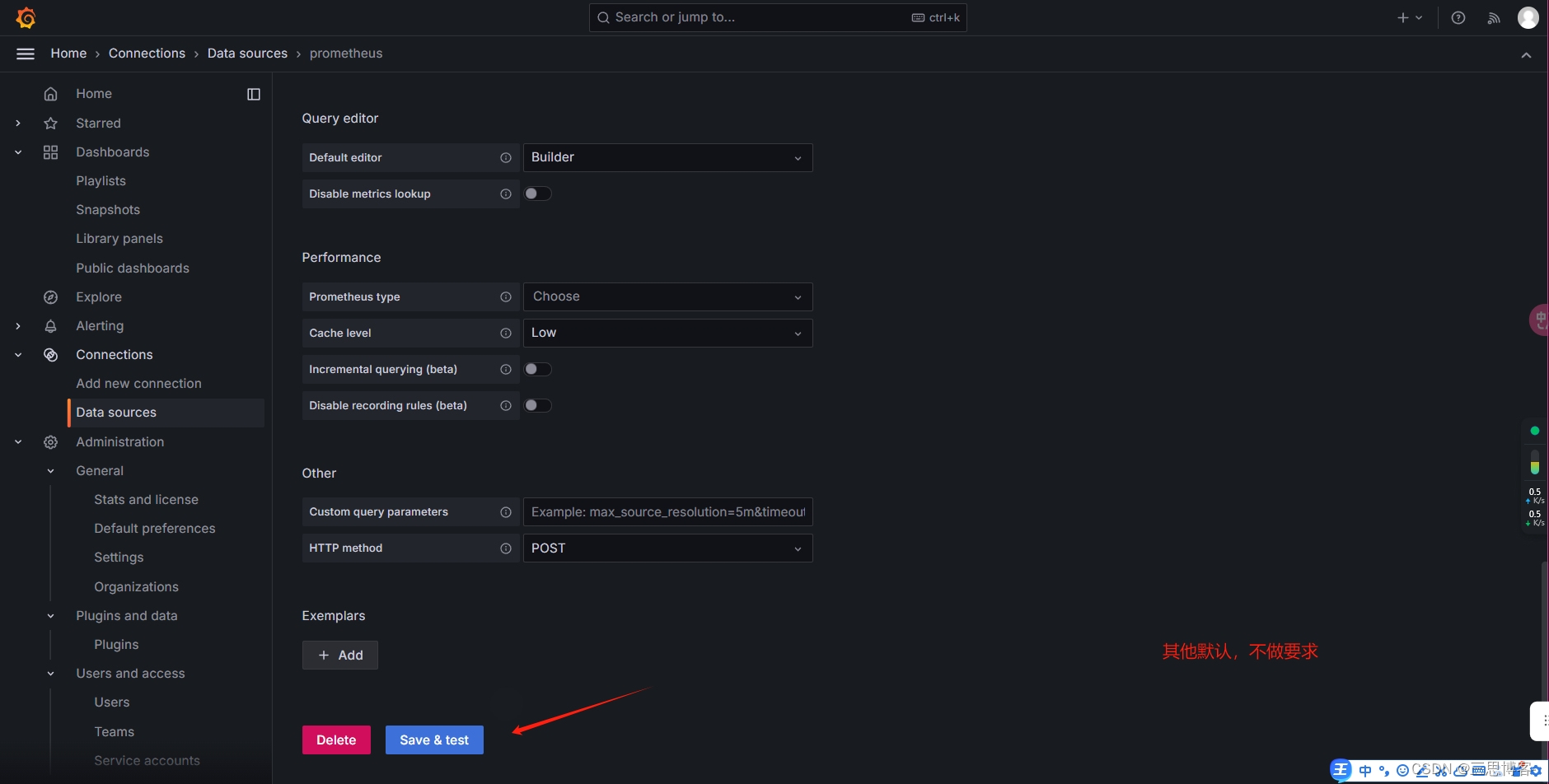
#测试监控各数据是否正常显示
效果图在下面5.Prometheus+grafana监控Linux/docker实战图示
0

1

2

3
4
5
6
7
8

9
10
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









