






这里写一篇帮助小白学习如何使用工具使自己的生产效率事半功倍的文章,今天学习的网站是mooc网。
随便打开一门课程。
假设我们想抓取这里的课程评价,我们如何把浏览器里的包抓出来生成python代码自己使用以便于节省时间呢? 按F12打开浏览器工具。
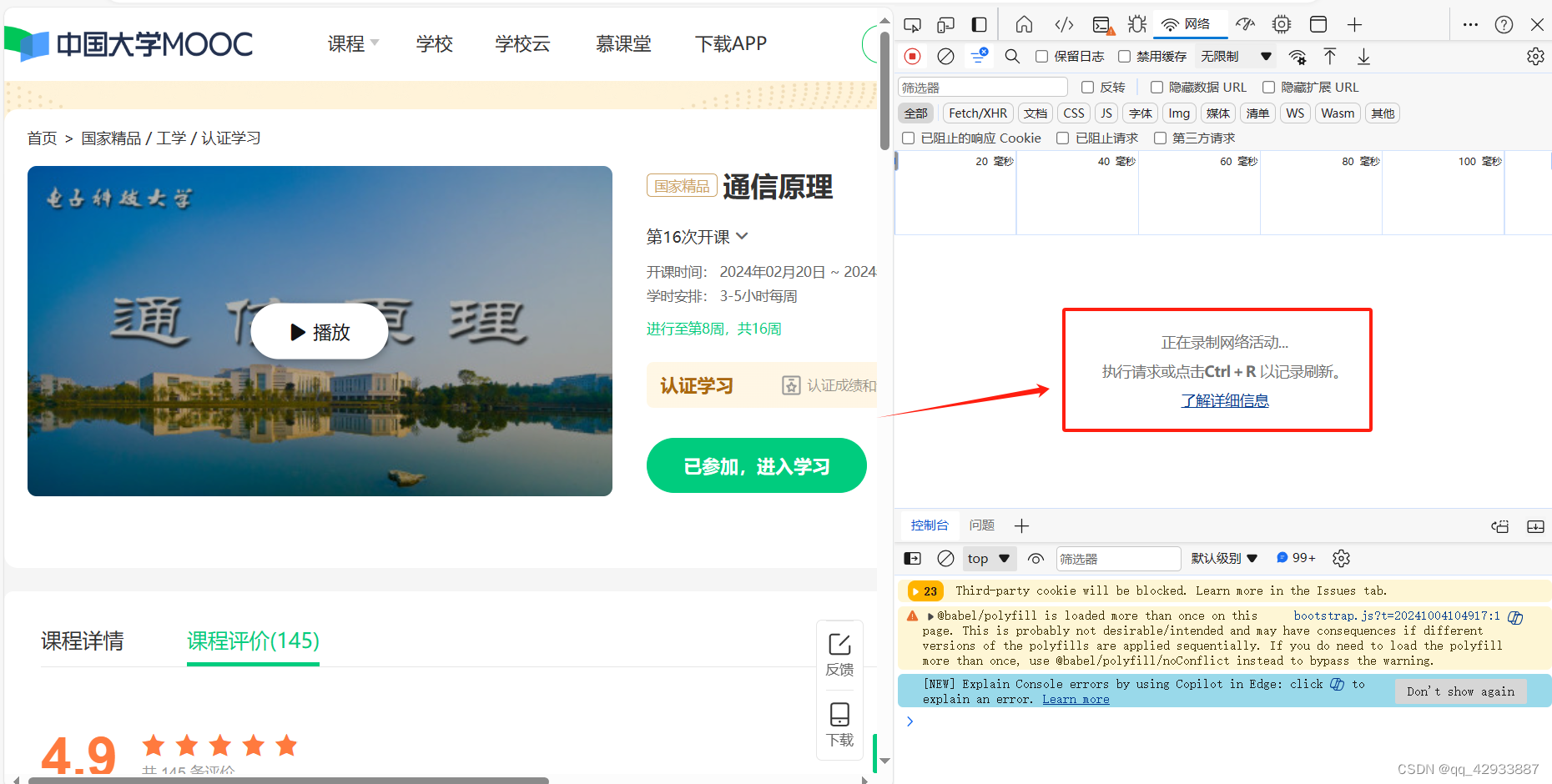
重新按F5 或者ctrl+R刷新 点进网络,其他浏览器可能是英文,为(Network),然后刷新等待,
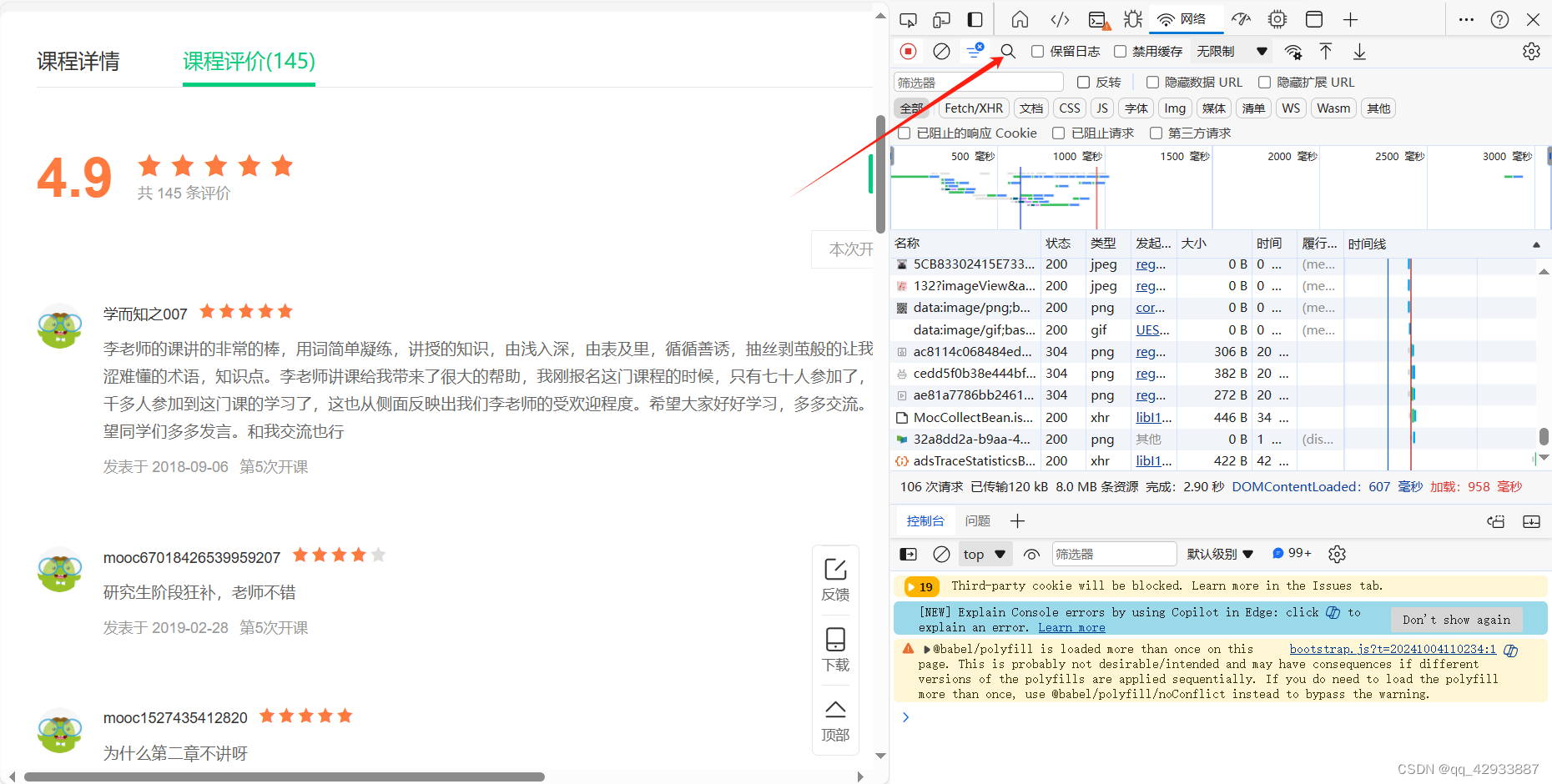
这里教一下如何定位自己想要的 数据包, 先用全局搜索文本试一下,中国mooc网的这个精品评论直接用中文搜索是可以搜索到的,后面有很多种数据类型,需要自己长期积累的经验。
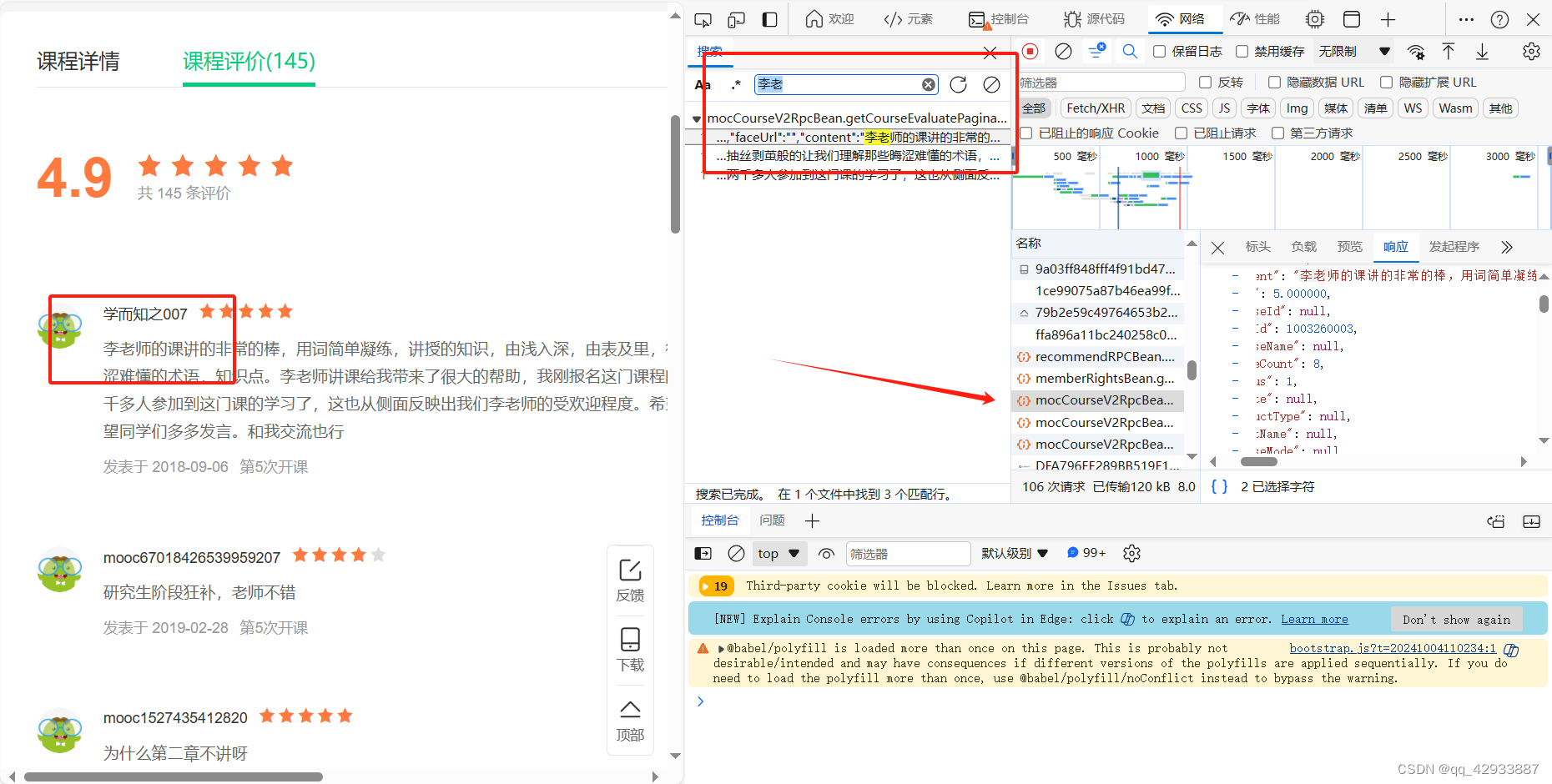
点开这个包,已知数据就在这个包内,接下来我们使用在线curl工具进行偷懒。我使用的工具地址是爬虫工具库-spidertools.cn 右键这个包,选择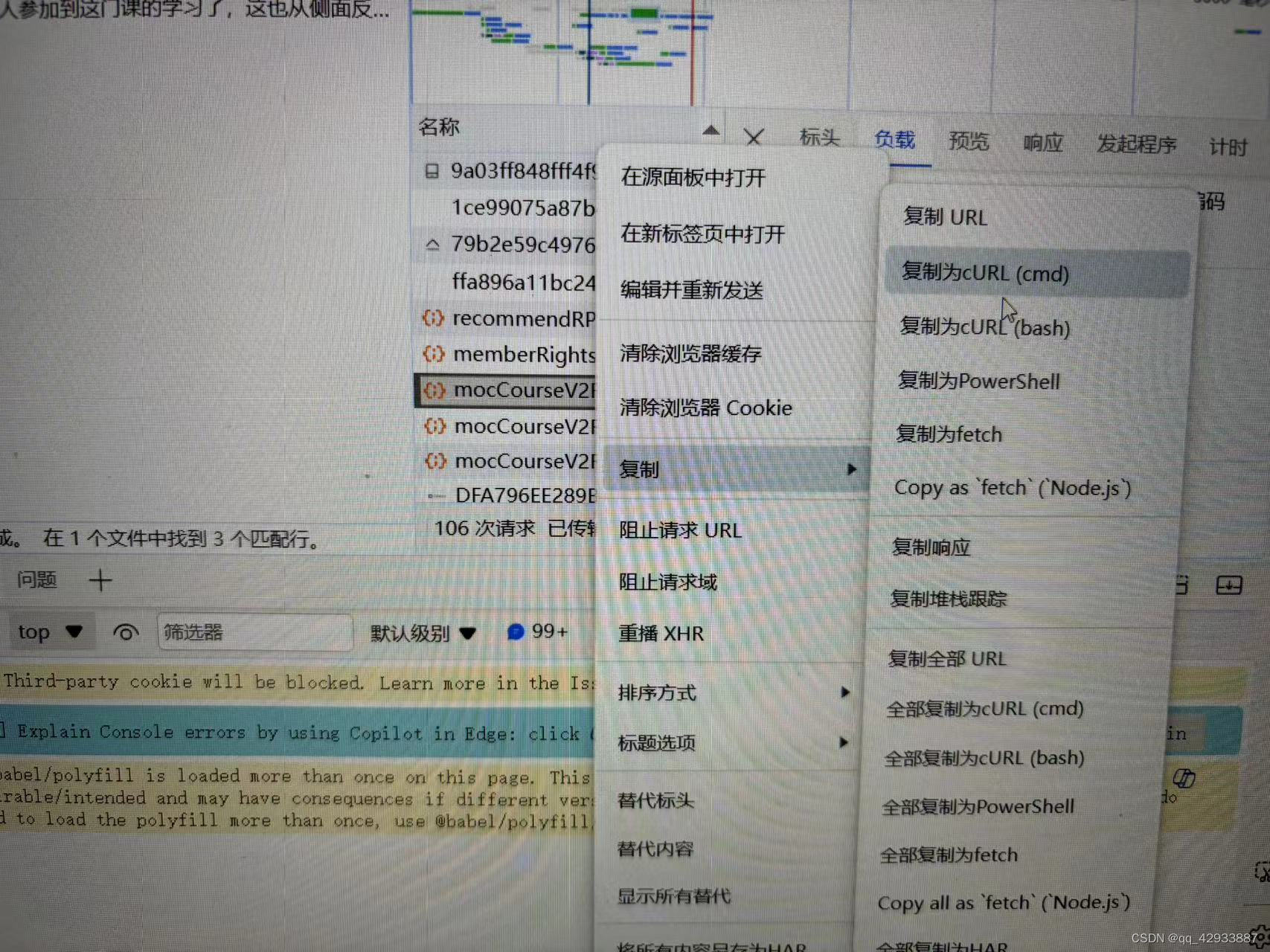
而后粘贴到网站,
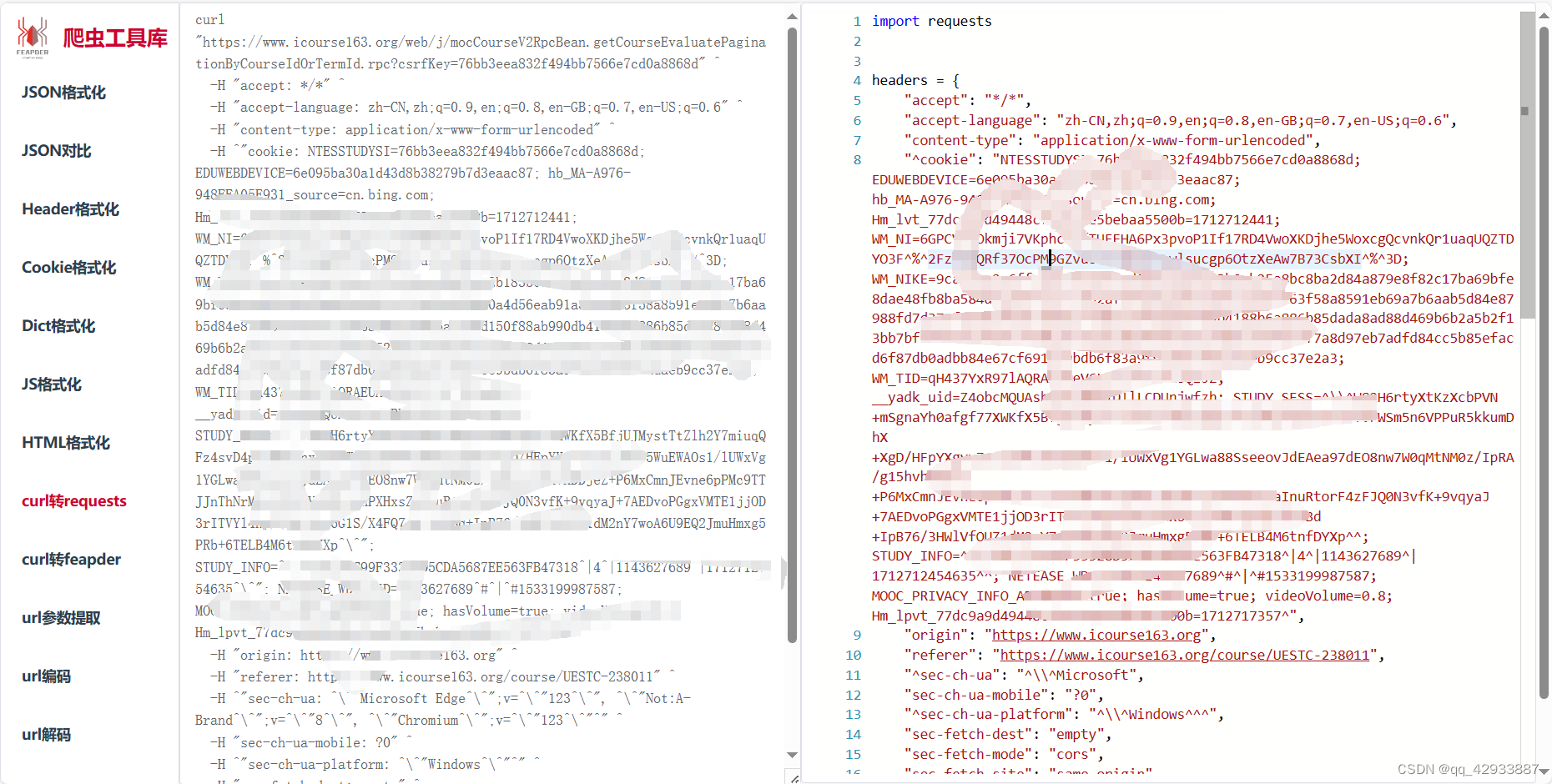
稍加修改,因为有的可能有错误,需要根据报错和经验修改
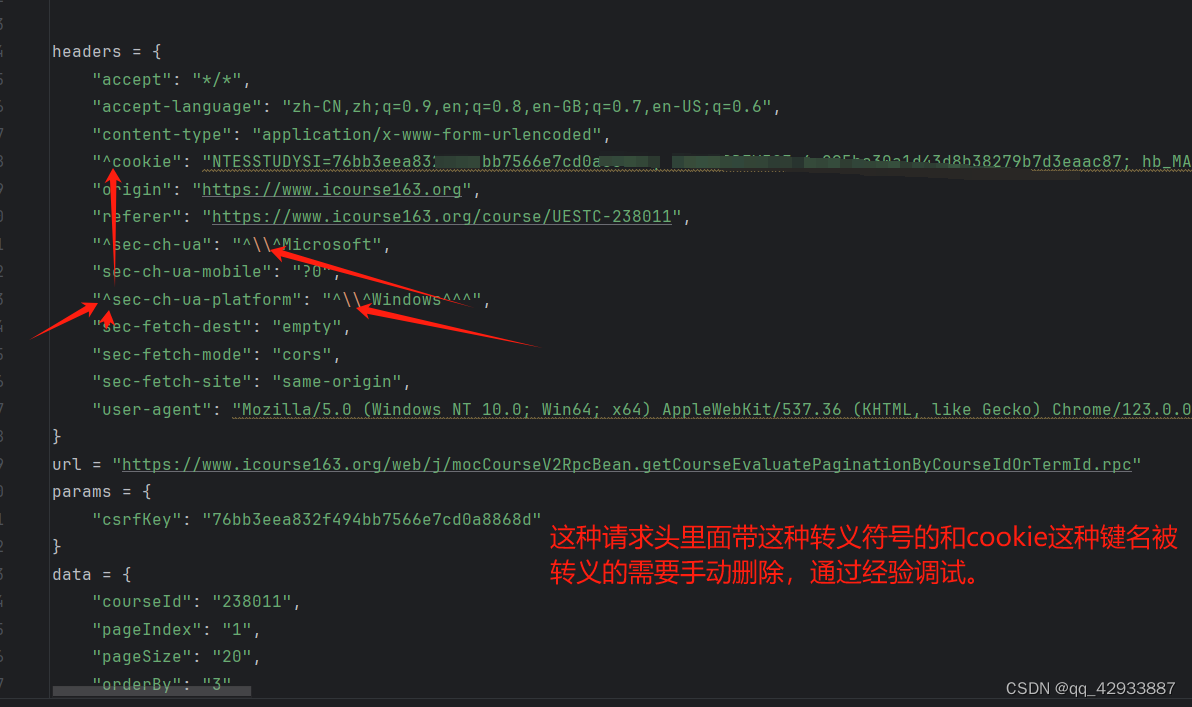
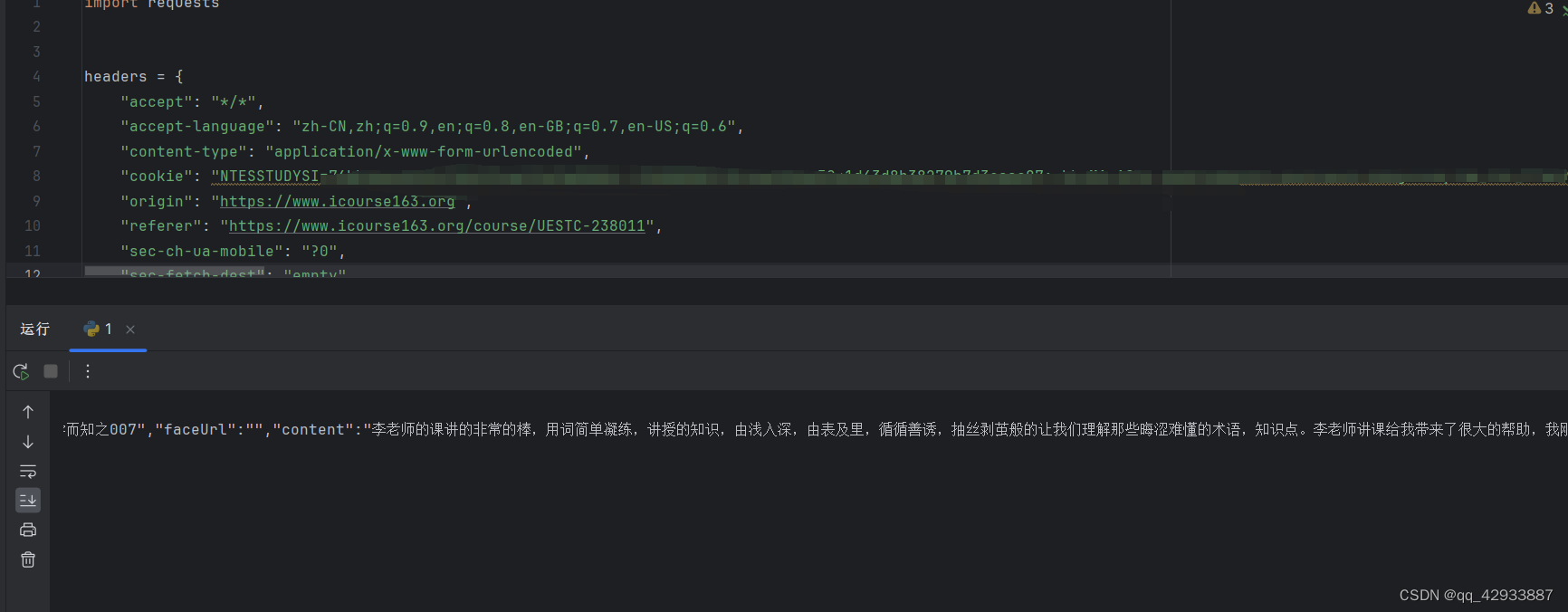
删除后运行,即可。















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









