







目录
循环优化
循环分块
循环分块是利用cache的数据局部性进行优化的一种方法。现代CPU通常具有多级cache,在存储体系中,cache是除CPU寄存器外最接近CPU的存储层次,相比主存速度更快,但是容量更小。cache中复制有CPU频繁使用的数据以进行快速访问。由于cache的容量有限,数据会在cache中进行换入换出。当访问的数据在cache中没有时,产生cache miss,会向低一级存储层次发出访问请求,然后该数据存储进cache,这时访问数据的时间就大大提高。当访问数据就在cache中时,会直接使用该数据以进行复用。
循环分块主要针对大型数据集进行优化,大数据集无法一次全部存入cache中。当遍历该数据集时,循环按照顺序进行访问,会替换掉之前加载进cache的数据,导致后面的指令对之前的数据无法复用,要重新加载数据,产生大量的cache miss,数据的复用性很差。程序执行时间变长,大量时间花费在载入数据上。
循环分块将大数据集分成多个小块以充分进行数据复用。数据块的内存访问是一个具有高内存局部性的小邻域。该数据块可以一次加载进cache,执行完所有或者尽可能多的计算任务后才被替换出。原始的矩阵乘法存储访问模式和分块后的存储访问模式见下图1。

图1 循环分块数据访问模式示意图
设置原始矩阵乘法与利用循环分块优化的矩阵乘法的性能对比,如图2。矩阵乘法的大小设置为(1024,1024)和(1024,1024)。原始矩阵乘法的一次遍历需要访问1024*1024*sizeof(float)大小的数据,即4096KB,超出了L1 data cache的容量。设置不同的分块大小即tile_size进行性能对比。由图可得,分块大小在256时相对性能最好,占用存储大小为128KB,也是L1 data cache的容量。分块大小小于256无法充分利用数据的复用,大于256会导致数据在cache的换入换出。
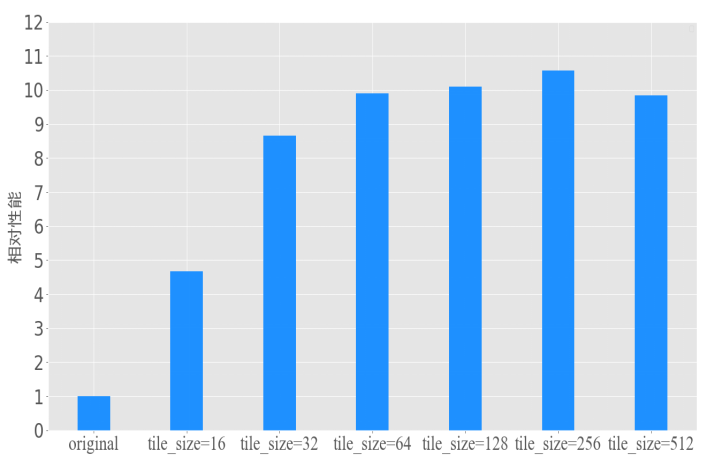
图2 循环分块性能对比图
循环重排序
循环重排序(reorder)是矩阵乘法常见的优化方式,特别是在CNN中卷积层的应用。如图3循环重排序示意图,在矩阵乘法计算中,B是逐列访问的,在行优先的存储模式下访问模式很不友好。切换内层的循环顺序可以使得所有元素按顺序读取和写入。一次计算输出的一行,得到的是中间结果,全部累加即可得到结果矩阵的一行最终结果,这种方式利用的是内存的空间局部性。

图3 循环重排序示意图
循环展开
循环展开是用于降低循环开销的编译器优化技术。循环展开将程序中的循环部分或全部展开,产生大量程序指令如图3.4,减少循环次数从而降低指令分支预测的开销。当程序中存在大量循环结构时,每一次循环迭代都要判断是否满足循环的条件,造成额外开销。
如果循环的次数已知,且数据前后没有依赖关系,则可以产生大量指令针对每个数据进行运算,为具有多个功能单元的处理器提供指令级并行,也有利指令流水线的调度。

图4 一个向量相加运算的循环展开前后对比
存储优化
存储布局转换
科学计算中的数据通常是多维数组,多维数组在内存中是一维展平的方式存放,一般是以行优先的方式存放。在矩阵乘法的第二个源矩阵中,数据的访问模式是从上至下,在行优先的存储布局中是不连续的。期望获得一个连续的存储访问模式,这样获取数据的速度更快。对第二个源矩阵进行存储布局转换,使得当我们在获得对应值时,访问模式是连续的。
优化缓存写入
在对计算进行加速时,容易想到对读取数据进行高效访问而忽略了写数据。对写数据过程不带任何优化时,计算结果会逐块写入结果矩阵,并且访问模式不是连续的。考虑写数据时的连续写入问题,在对矩阵进行循环分块后,对源数据的每个子矩阵都读了一次,而对结果矩阵需要写多次。因此,可以将每个子矩阵的计算结果写入本地缓冲区,然后再一起写回结果矩阵。
其他优化
多线程并行
现代CPU通常是多核结构,其架构一般如图5多核CPU架构示意图,可以进行线程级并行。在单核CPU上运行多任务时,通常是模拟进行的并行,通过进程调度算法如时间片轮转算法来同时进行多任务,实际上CPU在一个时刻只进行了一个任务。在多核CPU上,每一个核都可以进行计算,搭配超线程技术时,一个核可以执行两个线程。通过将多个计算线程分配到多个核,可以同时执行多线程计算实现并行加速,这是CPU上最有效的优化方式。

图5 多核CPU架构示意图
向量化
向量化是一种数据级并行优化。向量化即“批量操作”,在计算机中常见执行模型是单指令多数据(SIMD,Single Instruction Multiple Data)。通过对批量数据同时进行相同计算以提高效率。向量体系结构获取在存储器中散布的数据集,将多个数据元素放在大型的顺序寄存器堆即向量寄存器中,对整个寄存器进行操作从而同时计算了多个数据元素。向量本身可以容纳不同大小数据,因此如果一个向量寄存器可以容纳64个64 bit元素,那么也可以容纳128个32 bit元素或者512个8 bit元素。凭借这种硬件上的多样性,向量化特别适合用于多媒体应用和科学计算。
传统的执行方式为单指令单数据(SISD,Single Instruction Single Data),硬件不支持并行计算。现代CPU几乎都支持SIMD指令集,如Intel的SSE和AVX系列指令集。图6 为SISD与SIMD执行示意。

图6 SIMD示意图
实验
实验环境
为探索各种优化方式的原理和优化效果,使用TVM的TE语言编写矩阵乘法,并使用调度原语实现上述优化,对比优化效果。实验平台如表1。线程数是硬件平台可以调度使用的线程数量,TVM使用线程池将任务与线程绑定。指令集包括AVX指令集,这是SIMD向量化专用指令集。
表1 实验平台CPU数据
| CPU型号 | CPU主频 | 动态加速频率 | 线程数 | 支持指令集 |
|---|---|---|---|---|
| Intel Core i5 9300 | 2.4GHz | 4.1GHz | 8(超线程技术) | SSE4.1/4.2,AVX2(支持SIMD) |
由于优化方式很多利用了Cache,如循环分块利用了Cache的空间局部性。因此将详细CPU缓存数据列出,如下表2。
表2 CPU缓存数据
| L1 数据缓存 | L1指令缓存 | L2缓存 | L3缓存 | |
|---|---|---|---|---|
| 总容量 | 128KBytes | 128KBytes | 1.0MBytes | 8.0MBytes |
| 缓存行大小 | 64 Byte/line | 64 Byte/line | 64 Byte/line | 64 Byte/line |
| 映射方式 | 8路组相连 | 8路组相连 | 4路组相连 | 16路组相连 |
实验步骤
实验设置(1024,1024)与(1024,1024)的矩阵乘法,产生(1024,1024)的结果矩阵,数据类型为float32。设置实验信息如表3。由于个别优化方式会依赖其他优化,如多线程并行需要循环在外层展开,然后外层循环并行方式执行,因此优化方式为主要优化方式,尽量独立,有依赖的会说明。
表3 实验设置信息
| CPU对照组 | CPU优化1 | CPU优化2 | CPU优化3 | CPU优化4 | CPU优化5 | CPU优化6 | CPU优化7 | |
|---|---|---|---|---|---|---|---|---|
| 主要优化方式 | 不采用任何优化 | 循环分块 | 循环重排序 | 循环展开 | 存储布局转换 | 优化缓存写入 | 多线程并行 | 向量化 |
CPU对照组为默认实现方式,不采用任何优化,生成三层嵌套循环的方式执行。CPU优化1采用循环分块因子大小为32,生成一个4层嵌套循环执行方式,最内层循环大小就是循环分块因子大小。CPU优化2首先进行循环分块,因子大小为32,然后进行循环重排序,使得每一次内层循环加载进的数据利用率更高。CPU优化3在循环分块后,将最内层循环进行展开,生成大量指令以有利流水线调度。CPU优化4对第二个源数组进行包装,将其进行数据存储布局转换使得存储访问模式连续。CPU优化5在CPU优化4的基础上,在每一个子块计算后结果先写入cache,当整个结果计算完毕后再写回主存。CPU优化6在CPU优化4的基础上,对最外层循环进行多线程并行化处理,充分发挥CPU的多核计算能力。CPU优化7设置向量化接口,当内存访问模式一致时,编译器可以检测到这种模式并将连续内存传递给向量处理器,进行SIMD操作。
实验结果
| CPU对照组 | CPU优化1 | CPU优化2 | CPU优化3 | CPU优化4 | CPU优化5 | CPU优化6 | CPU优化7 | |
|---|---|---|---|---|---|---|---|---|
| 耗时(ms,保留4位小数) | 2.0075 | 0.2874 | 0.1130 | 0.1165 | 0.1192 | 0.1039 | 0.0661 | 0.2923 |
8组实验结果如表3.4所示。在8组实验中,加速比最高的是CPU优化6多线程并行方式,充分发挥了CPU的多核计算能力,这也是CPU厂商将发展方向由大核转变为多核的体现。加速比最低的是CPU优化7向量化,一部分原因是由于向量化需要数据之间没有依赖,因此需要向量启动时间来检查数据依赖性,只有向量化加速能掩盖这种额外开销时,SIMD操作才能优于普通标量计算。另一部分原因是没有选择适合的向量化循环轴。在几种优化方式中,大多数优化并未达到该种优化的理论最优,这与超参数选择有关。例如在循环分块中,3.2.1节表明选择不同循环分块因子,对性能有不同影响。在循环展开中,也涉及不同展开层级,例如对外层循环还是内层循环展开。
在实际优化中,一般会选择多种优化方式组合以充分发挥硬件平台特性。此外,由于不同超参数选择会极大影响性能,因此需要设置尽可能合适的超参数。而所有优化方式的超参数组合是一个非常庞大的硬件配置空间,使用手动探索的方式无疑是非常耗时且工程量巨大。因此TVM提供了AutoTVM自动调优器,自动进行硬件配置空间检索以达到调优目的。
相关阅读
基于HLS(High-level synthesis)的开源CNN加速库调研 - 知乎














 1411
1411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









