







SparkSQL使用窗口函数
开窗函数
●介绍
开窗函数的引入是为了既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。
开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进
行分组,能够在同一行中同时返回基础行的列和聚合列。
●聚合函数和开窗函数
聚合函数是将多行变成一行,count,avg….
开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中
开窗函数可以不使用group by,直接将所有信息显示出来
●开窗函数分类
1.聚合开窗函数
聚合函数(列)OVER(选项),这里的选项可以是PARTITION BY子句,但不可以是ORDER BY子句。
2.排序开窗函数
排序函数(列)OVER(选项),这里的选项可以是ORDER BY子句,也可以是OVER(PARTITION BY子句ORDER BY子句),但不可以
是PARTITION BY子句。
3.分区类型NTILE的窗口函数
下面我们来看具体的案例:
聚合开窗函数
if __name__ == '__main__':
#O.构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("Local[*]").\
config("spark.sql.shuffle.partitions",2).\
getorCreate()
sc = spark.sparkContext
rdd = sc.parallelize([
('张三', 'class_1',99),
('王五', 'class_2',35),
('王三', 'class_3',57),
('王久', 'class_4',12),
('王丽', 'class_5',99),
('王娟', 'class_1',90),
('王军', 'class_2',91),
('王俊', 'class_3',33),
('王君', 'class_4',55),
('王珺', 'class_5',66),
('郑颗', 'class_1',11),
('郑辉', 'class_2',33),
('张丽', 'class_3',36),
('张张', 'class_4',79),
('黄凯', 'class_5',90),
('黄开', 'class_1',90),
('黄恺', 'class_2',90),
('王凯', 'class_3',11),
('王凯杰', 'class_1',11),
('王开杰', 'class_2',3),
('王承亮', 'class_3',99)
])
schema = StructType().add("name",StringType)).\
add("class",).\
add("score",IntegerType())
df = rdd.toDF(schema)
df.createTempview("stu")
#T0D0聚合窗口函数的演示,这里用"""来用于定义多行字符串字面量。方便在一个字符串中嵌入多行SQL代码或包含特殊字符(如换行符)
# 对score列求平均后,给每行赋予相同值
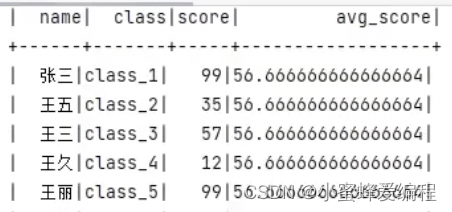
spark.sql("""
SELECT * AVG(score) OVER() AS avg_score FROM stu
""").show)
结果如下图:
排序开窗函数
# TODO排序相关的窗口函数计算
# RAKN over,DENSE_RANK over ROW_NUMBER over
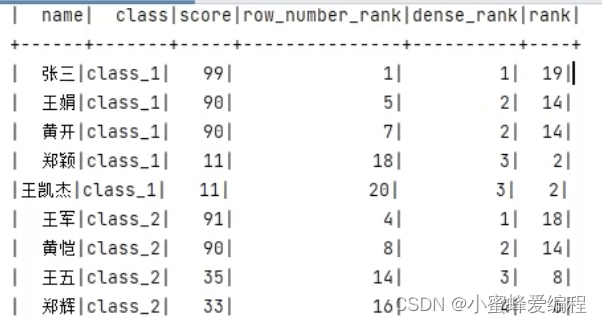
spark.sql("""
SELECT * ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,
DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank,
RANK() OVER(ORDER BY score) AS rank FROM stu
).show()
上面分别会给出3列信息,一列row_number_rank按score降序排序的序号,一列按class分区,分区内按score排序的序号,另外一列整体按score排序的序号
NTILE函数
NTILE会为结果集分配指定大小的分区,将结果集尽可能平均分配到结果集上,并对每一行的结果标明分区编号,总行数不能整除指定分区大小时分区内数据数量可能有点差异,如下按score降序之后,进行分区
spark.sql("""
SELECT * NTILE(6) OVER(ORDER BY score DESC) FROM stu
""").show()
 可以看到,前4名被分到第一个分区,编号为1
可以看到,前4名被分到第一个分区,编号为1
















 3973
3973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









