






 本文全面介绍了eBPF技术,包括其定义、与内核模块对比、架构、限制、使用方法、实现原理和特性等。eBPF允许程序在不修改内核源代码或添加额外内核模块的情况下运行,在安全性和入门门槛上有优势。还介绍了使用BCC工具编写eBPF程序的步骤。
本文全面介绍了eBPF技术,包括其定义、与内核模块对比、架构、限制、使用方法、实现原理和特性等。eBPF允许程序在不修改内核源代码或添加额外内核模块的情况下运行,在安全性和入门门槛上有优势。还介绍了使用BCC工具编写eBPF程序的步骤。
1 什么是 eBPF
eBPF 全称 extended Berkeley Packet Filter,中文意思是 扩展的伯克利包过滤器。一般来说,要向内核添加新功能,需要修改内核源代码或者编写 内核模块 来实现。而 eBPF 允许程序在不修改内核源代码,或添加额外的内核模块情况下运行。
从 eBPF 的名字看,好像是专门为过滤网络包而创造的。其实,eBPF 是从 BPF(也称为 cBPF:classic Berkeley Packet Filter)发展而来的,BPF 是专门为过滤网络数据包而创造的。
但随着 eBPF 不断完善和加强,现在的 eBPF 已经不再限于过滤网络数据包了。
2 eBPF 与内核模块对比
在 Linux 观测方面,eBPF 总是会拿来与 kernel 模块方式进行对比,eBPF 在安全性、入门门槛上比内核模块都有优势,这两点在观测场景下对于用户来讲尤其重要。
| 维度 | Linux 内核模块 | eBPF |
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
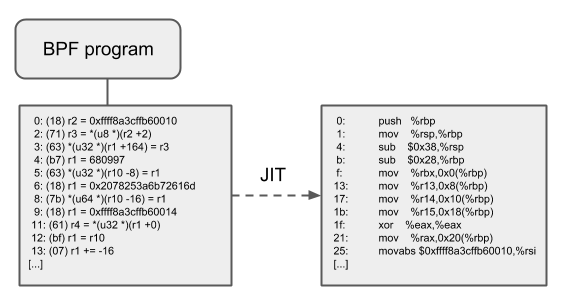
3 eBPF 架构
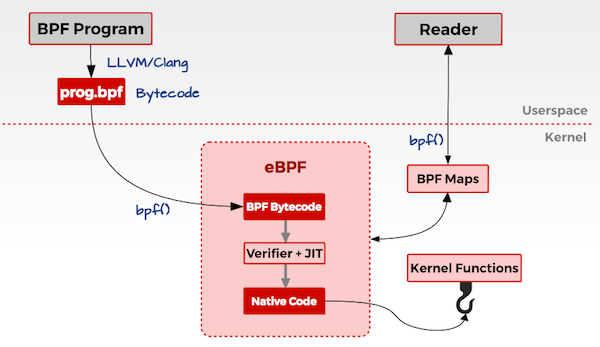
用户态
- 用户编写 eBPF 程序,可以使用 eBPF 汇编或者 eBPF 特有的 C 语言来编写。
- 使用 LLVM/CLang 编译器,将 eBPF 程序编译成 eBPF 字节码。
- 调用
bpf() 系统调用把 eBPF 字节码加载到内核。
内核态
- 当用户调用
bpf() 系统调用把 eBPF 字节码加载到内核时,内核先会对 eBPF 字节码进行安全验证。 - 使用
JIT(Just In Time)技术将 eBPF 字节编译成本地机器码(Native Code)。 - 然后根据 eBPF 程序的功能,将 eBPF 机器码挂载到内核的不同运行路径上(如用于跟踪内核运行状态的 eBPF 程序将会挂载在
kprobes 的运行路径上)。当内核运行到这些路径时,就会触发执行相应路径上的 eBPF 机器码。
4 eBPF 限制
eBPF 技术虽然强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也给予了诸多限制,当然随着技术的发展和演进,限制也在逐步放宽或者提供了对应的解决方案。
- eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,函数支持列表也随着内核的演进在不断增加。
- eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。
- eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
- eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;参见 include/linux/filter.h,这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半。目前没有计划增加这个限制,解决方法是改用 bpf 映射存储,它实际上是无限的。
暂时无法在飞书文档外展示此内容
- eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令( BPF_COMPLEXITY_LIMIT_INSNS),参见:include/linux/bpf.h,对于无权限的BPF程序,仍然保留4096条限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。
暂时无法在飞书文档外展示此内容
5 eBPF 使用
编写 eBPF 程序有多种方式,比如使用原生 eBPF 汇编来编写,但使用原生 eBPF 汇编编写程序的难度较大,所以一般不建议。
也可以使用 eBPF 受限的 C 语言来编写,难度比使用原生 eBPF 汇编简单些,但对初学者来说也不是十分友好。
最简单是使用 BCC 工具来编写,BCC 工具帮我们简化了很多繁琐的工作,比如不用编写加载器。
下面我们将使用 BCC 工具来介绍怎么编写一个 eBPF 程序。
注意:由于 eBPF 对内核的版本有较高的要求,不同版本的内核对 eBPF 的支持可能有所不相同。所以使用 eBPF 时,最好使用最新版本的内核。
本文使用 Ubuntu 20.04(内核版本为5.15.0)
5.1 BCC安装
使用下面的命令安装
暂时无法在飞书文档外展示此内容
BCC 工具可以让你使用 Python 和 C 语言组合来编写 eBPF 程序。
5.2 编写 eBPF 版的 hello world
使用 BCC 编写 eBPF 程序的步骤如下:
- 使用 C 语言编写 eBPF 程序的内核态功能(也就是运行在内核态的 eBPF 程序)。
- 使用 Python 编写加载代码和用户态功能。
为什么不能全部使用 Python 编写呢?这是因为 LLVM/Clang 只支持将 C 语言编译成 eBPF 字节码,而不支持将 Python 代码编译成 eBPF 字节码。
所以,eBPF 内核态程序只能使用 C 语言编写。而 eBPF 的用户态程序可以使用 Python 进行编写,这样就能简化编写难度。
所以,第一步就是编写 eBPF 内核态程序。
使用 C 编写 eBPF 程序
新建一个 hello.c 文件,并输入下面的内容:
暂时无法在飞书文档外展示此内容
使用 Python 和 BCC 工具开发一个用户态程序
新建一个 hello.py 文件,并输入下面的内容:
暂时无法在飞书文档外展示此内容
下面我们来看看每一行代码的具体含义:
- 导入了 BCC 库的 BPF 模块,以便接下来调用。
- 调用 BPF() 函数加载 eBPF 内核态程序(也就是我们编写的hello.c)。
- 将 eBPF 程序挂载到内核探针(简称 kprobe),其中
do_sys_openat2() 是系统调用 openat() 在内核中的实现。 - 读取内核调试文件
/sys/kernel/debug/tracing/trace_pipe 的内容(bpf_trace_printk() 函数会将信息写入到此文件),并打印到标准输出中。
运行 eBPF 程序
用户态程序开发完成之后,最后一步就是执行它了。需要注意的是,eBPF 程序需要以 root 用户来运行:
暂时无法在飞书文档外展示此内容
运行后,可以看到如下输出:

6 eBPF实现原理
6.1 eBPF虚拟机
eBPF汇编
eBPF 本质上是一个虚拟机(Virtual Machine),可以执行 eBPF 字节码。
用户可以使用 eBPF 汇编或者 C 语言来编写程序,然后编译成 eBPF 字节码,再由 eBPF 虚拟机执行。
什么是虚拟机?
官方的解释是:虚拟机(VM)是一种创建于物理硬件系统(位于外部或内部)、充当虚拟计算机系统的虚拟环境,它模拟出了自己的整套硬件,包括 CPU、内存、网络接口和存储器。通过名为虚拟机监控程序的软件,用户可以将机器的资源与硬件分开并进行适当设置,以供虚拟机使用。
通俗的解释:虚拟机就是模拟计算机的运行环境,你可以把它当成是一台虚拟出来的计算机。
计算机的最本质功能就是执行代码,所以 eBPF 虚拟机也一样,可以运行 eBPF 字节码。
用户编写的 eBPF 程序最终会被编译成 eBPF 字节码,eBPF 字节码使用 bpf_insn
暂时无法在飞书文档外展示此内容
下面介绍一下 bpf_insn
-
code:指令操作码,如 mov、add 等。 -
dst_reg:目标寄存器,用于指定要操作哪个寄存器。 -
src_reg:源寄存器,用于指定数据来源于哪个寄存器。 -
off:偏移量,用于指定某个结构体的成员。 -
imm:立即操作数,当数据是一个常数时,直接在这里指定。
eBPF 程序会被 LLVM/Clang 编译成 bpf_insn 结构数组,当内核要执行 eBPF 字节码时,会调用 __bpf_prog_run()
如果开启了 JIT(即时编译技术),内核会将 eBPF 字节码编译成本地机器码(Native Code)。这样就可以直接执行,而不需要虚拟机来执行。
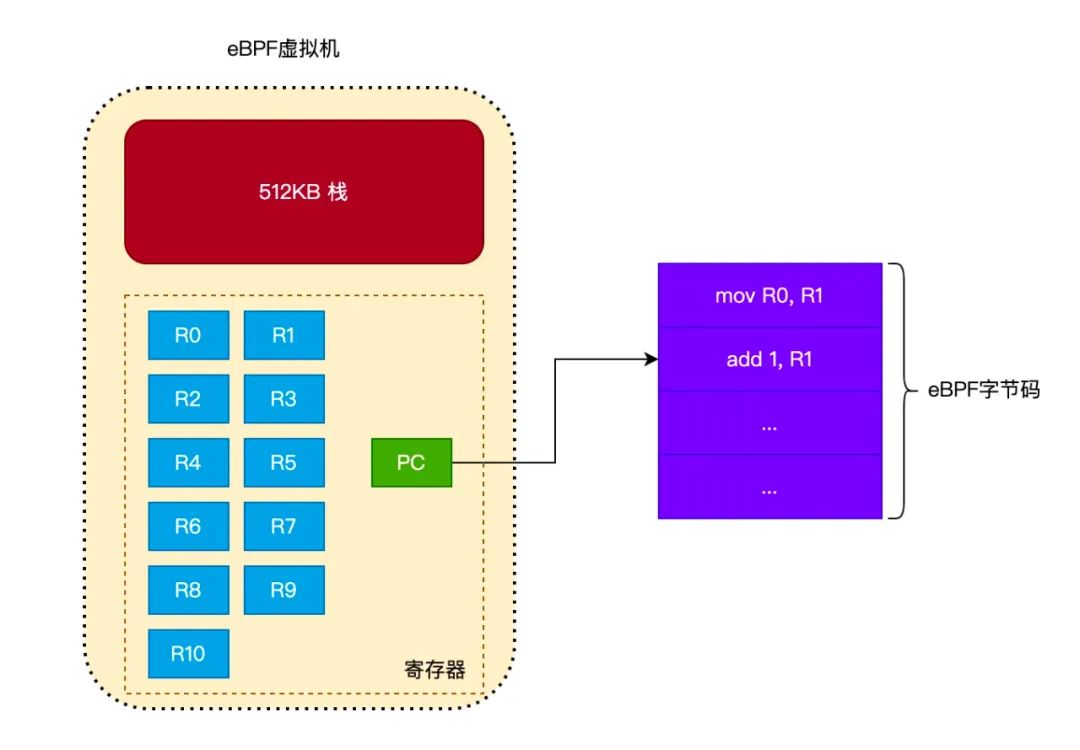
eBPF虚拟机
eBPF 虚拟机的作用就是执行 eBPF 字节码,eBPF 虚拟机比较简单(只有300行代码左右),由 __bpf_prog_run()
通用虚拟机因为要模拟真实的计算机,所以通常来说实现比较复杂(如Qemu、Virtual Box等)。
但像 eBPF 虚拟机这种用于特定功能的虚拟机,由于只需要模拟计算机的小部分功能,所以实现通常比较简单。
eBPF 虚拟机的运行环境只有 1 个 512KB 的栈和 11 个寄存器(还有一个 PC 寄存器,用于指向当前正在执行的 eBPF 字节码)。如下图所示:
如果内核支持 JIT(Just In Time)运行模式,那么内核将会把 eBPF 字节码编译成本地机器码,这时可以直接运行这些机器码,而不需要使用虚拟机来运行。
可以通过以下命令打开 JIT 运行模式:
暂时无法在飞书文档外展示此内容
6.2 将 C 程序编译成 eBPF 字节码
由于使用 eBPF 汇编编写程序比较麻烦,所以 eBPF 提供了功能受限的 C 语言来编写 eBPF 程序,并且可以使用 Clang/LLVM 将 C 程序编译成 eBPF 字节码。
使用 Clang 编译 eBPF 程序时,需要加上 -target bpf 参数才能编译成功。
下面我们用一个简单的例子来介绍怎么使用 Clang 编译 eBPF 程序,我们新建一个文件 hello.c 并且输入以下代码:
暂时无法在飞书文档外展示此内容
然后我们使用以下命令编译程序:
暂时无法在飞书文档外展示此内容
编译后会得到一个名为 hello.o 的文件,我们可以通过下面命令来看到编译后的字节码:
暂时无法在飞书文档外展示此内容
由于编译出来的字节码是二进制的,不利于人类查阅。所以,可以通过以下命令将 eBPF 程序编译成 eBPF 汇编代码:
暂时无法在飞书文档外展示此内容
编译后会得到一个名为 hello.s 的文件,我们可以使用文本编辑器来查看其汇编代码:
暂时无法在飞书文档外展示此内容
eBPF 虚拟机的规范:
- 寄存器
r1-r5:作为函数调用参数使用。在 eBPF 程序启动时,寄存器 r1 包含 "上下文" 参数指针。- 寄存器
r0:存储函数的返回值,包括函数调用和当前程序退出。- 寄存器
r10:eBPF程序的栈指针。
6.3 eBPF 加载器
eBPF 程序是由用户编写的,编译成 eBPF 字节码后,需要加载到内核才能被内核使用。
用户态可以通过调用 sys_bpf() 系统调用把 eBPF 程序加载到内核,而 sys_bpf() 系统调用会通过调用 bpf_prog_load() 内核函数加载 eBPF 程序。
我们来看看 bpf_prog_load() 函数的实现(经过精简后):
暂时无法在飞书文档外展示此内容
bpf_prog_load() 函数主要完成以下几个工作:
- 创建一个
bpf_prog 对象,用于保存 eBPF 字节码和 eBPF 程序的相关信息。 - 把 eBPF 字节码从用户态复制到
bpf_prog 对象的 insns 成员中,insns 成员是一个类型为 bpf_insn 结构的数组。 - 根据 eBPF 程序所属的类型(如
socket、kprobes 或 xdp 等),找到其相关处理函数(如 helper 函数对应的修正函数)。 - 检查 eBPF 字节码是否合法。由于 eBPF 程序运行在内核态,所以要保证其安全性,否则将会导致内核崩溃。
- 修正
helper 函数的偏移量。 - 尝试将 eBPF 字节码编译成本地机器码,主要为了提高 eBPF 程序的执行效率。
- 申请一个文件句柄用于与
bpf_prog 对象关联,这个文件句柄将会返回给用户态,用户态可以通过这个文件句柄来读取内核中的 eBPF 程序。
6.4 修正 helper 函数
helper 函数是 eBPF 提供给用户使用的一些辅助函数。
由于 eBPF 程序运行在内核态,所以为了安全,eBPF 程序中不能随意调用内核函数,只能调用 eBPF 提供的辅助函数(helper functions)。
调用 eBPF 的 helper 函数与调用普通的函数并不一样,调用 helper 函数时并不是直接调用的,而是通过 helper 函数的编号来进行调用。
每个 eBPF 的 helper 函数都有一个编号(通过枚举类型 bpf_func_id 来定义),定义在 include/uapi/linux/bpf.h 文件中,定义如下(只列出一部分):
暂时无法在飞书文档外展示此内容
下面我们来看看在 eBPF 程序中怎么调用 helper 函数:
暂时无法在飞书文档外展示此内容
从上面的代码可以知道,当要调用 helper 函数时,需要先定义一个函数指针,并且将函数指针赋值为 helper 函数的编号,然后才能调用这个 helper 函数。
定义函数指针的原因是:指定调用函数时的参数。
所以,调用的 helper 函数其实并不是真实的函数地址。那么内核是怎么找到真实的 helper 函数地址呢?
这里就是通过上面说的修正 helper 函数来实现的。
在介绍加载 eBPF 程序时说过,加载器会通过调用 fixup_bpf_calls() 函数来修正 helper 函数的地址。我们来看看 fixup_bpf_calls() 函数的实现:
暂时无法在飞书文档外展示此内容
fixup_bpf_calls() 函数主要完成修正 helper 函数的地址,其工作原理如下:
- 遍历 eBPF 程序的所有字节码。
- 如果字节码指令是一个函数调用,那么将进行函数地址修正,修正过程如下:
- 根据
helper 函数的编号获取其真实的函数地址。 - 将
helper 函数的真实地址减去 __bpf_call_base 函数的地址,并且保存到字节码的 imm 字段中。
从上面修正 helper 函数地址的过程可知,当调用 helper 函数时需要加上 __bpf_call_base 函数的地址。
6.5 eBPF 程序运行时机
上面介绍了 eBPF 程序的运行机制,现在来说说内核什么时候执行 eBPF 程序。
eBPF 程序需要挂载到某个内核路径(挂载点)才能被执行。
根据挂载点功能的不同,大概可以分为以下几个模块:
- 性能跟踪(kprobes/uprobes/tracepoints)
- 网络(socket/xdp)
- 容器(cgroup)
- 安全(seccomp)
比如要将 eBPF 程序挂载在 socket(套接字) 上,可以使用 setsockopt() 函数来实现,代码如下:
暂时无法在飞书文档外展示此内容
下面说说 setsockopt() 函数各个参数的意义:
- sock:要挂载 eBPF 程序的 socket 句柄。
- SOL_SOCKET:设置的选项的级别,如果想要在套接字级别上设置选项,就必须设置为
SOL_SOCKET。 - SO_ATTACH_BPF:表示挂载 eBPF 程序到 socket 上。
- prog_fd:通过调用
bpf() 系统调用加载 eBPF 程序到内核后返回的文件句柄。
通过上面的代码,就能将 eBPF 程序挂载到 socket 上,当 socket 接收到数据包时,将会执行这个 eBPF 程序对数据包进行过滤。
我们看看当 socket 接收到数据包时的操作:
暂时无法在飞书文档外展示此内容
当 socket 接收到数据包时,会调用 run_filter() 函数执行 eBPF 程序。
7 eBPF特性
7.1 Hook
Hook(钩子):在 epbf 的世界里看 Linux 内核所有核心调用都可以 Hook,可以理解成为万物皆可挂钩子做 Callback。
eBPF 程序都是事件驱动的,它们会在内核或者应用程序经过某个确定的 Hook 点的时候运行,这些 Hook 点都是提前定义的,包括系统调用、函数进入/退出、内核 tracepoints、网络事件等。
如果针对某个特定需求的 Hook 点不存在,可以通过 kprobe 或者 uprobe 来在内核或者用户程序的几乎所有地方挂载 eBPF 程序。
7.2 Verification(验证器)
生成应用内核层的 bytescode 要想进入到内核中去运行,必然要有个“安全检查员”对这个 bytescode 的安全和合法性进行检测。
每一个 eBPF 程序加载到内核都要经过 Verification,用来保证 eBPF 程序的安全性,主要包括:
- 要保证 加载 eBPF 程序的进程有必要的特权级,除非节点开启了
unpriviledged 特性,只有特权级的程序才能够加载 eBPF 程序
- 内核提供了一个配置项
/proc/sys/kernel/unprivileged_bpf_disabled 来禁止非特权用户使用 bpf(2) 系统调用,可以通过 sysctl 命令修改 - 比较特殊的一点是,这个配置项特意设计为一次性开关(one-time kill switch), 这意味着一旦将它设为
1,就没有办法再改为 0 了,除非重启内核 - 一旦设置为
1 之后,只有初始命名空间中有 CAP_SYS_ADMIN 特权的进程才可以调用 bpf(2) 系统调用 。Cilium 启动后也会将这个配置项设为 1:
暂时无法在飞书文档外展示此内容
- 要保证 eBPF 程序不会崩溃或者使得系统出故障
- 要保证 eBPF 程序不能陷入死循环,能够
runs to completion - 要保证 eBPF 程序必须满足系统要求的大小,过大的 eBPF 程序不允许被加载进内核
- 要保证 eBPF 程序的复杂度有限,
Verifier 将会评估 eBPF 程序所有可能的执行路径,必须能够在有限时间内完成 eBPF 程序复杂度分析
7.3 JIT Compilation(JIT 编译器)
跟 java 的 JVM 有点类似,就是把 bytescode 编译成本机能够运行的二进制代码。
Just-In-Time(JIT) 编译用来将通用的 eBPF 字节码翻译成与机器相关的指令集,从而极大加速 BPF 程序的执行:
- 与解释器相比,它们可以降低每个指令的开销。通常,指令可以 1:1 映射到底层架构的原生指令
- 这也会减少生成的可执行镜像的大小,因此对 CPU 的指令缓存更友好
- 特别地,对于 CISC 指令集(例如
x86),JIT 做了很多特殊优化,目的是为给定的指令产生可能的最短操作码,以降低程序翻译过程所需的空间
64 位的 x86_64、arm64、ppc64、s390x、mips64、sparc64 和 32 位的 arm 、x86_32 架构都内置了 in-kernel eBPF JIT 编译器,它们的功能都是一样的,可以用如下方式打开:
暂时无法在飞书文档外展示此内容
32 位的 mips、ppc 和 sparc 架构目前内置的是一个 cBPF JIT 编译器。这些只有 cBPF JIT 编译器的架构,以及那些甚至完全没有 BPF JIT 编译器的架构,需要通过内核中的解释器(in-kernel interpreter)执行 eBPF 程序。
要判断哪些平台支持 eBPF JIT,可以在内核源文件中 grep HAVE_EBPF_JIT:
暂时无法在飞书文档外展示此内容
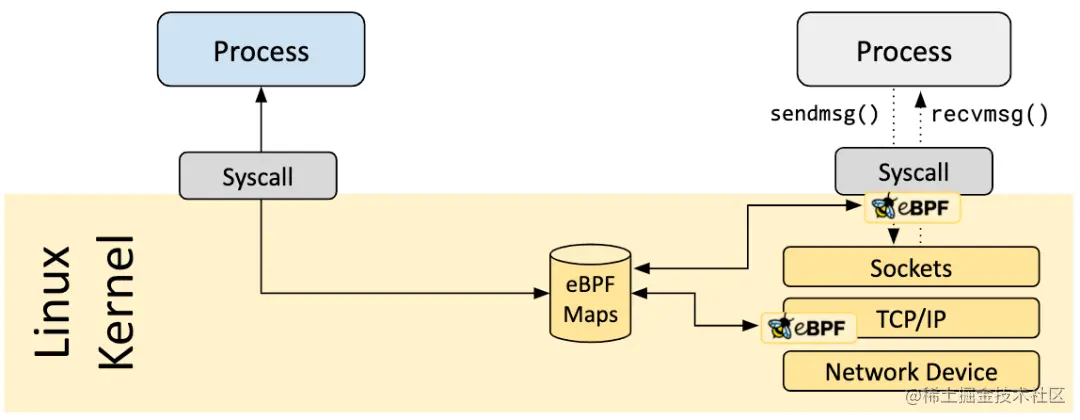
7.4 Maps(映射存储)
ebpf Map 是驻留在内核空间中的高效 Key/Value store,包含多种类型的 Map,由内核实现其功能。用来作为用户层和内核层之间数据交换的媒介,同时可以在不同程序之间共享数据。
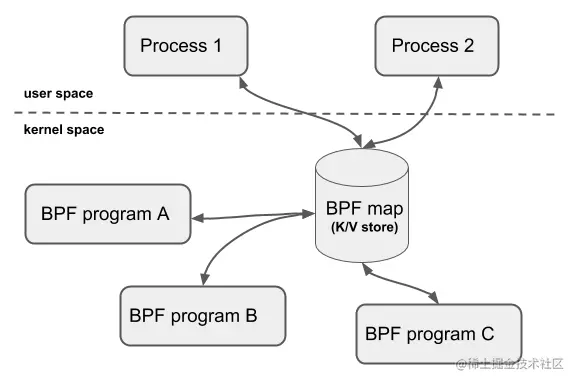
BPF Map 的交互场景有以下几种:
- BPF 程序和用户态程序的交互:BPF 程序运行完,得到的结果存储到 map 中,供用户态程序通过文件描述符访问
- BPF 程序和内核态程序的交互:和 BPF 程序以外的内核程序交互,也可以使用 map 作为中介
- BPF 程序间交互:如果 BPF 程序内部需要用全局变量来交互,但是由于安全原因 BPF 程序不允许访问全局变量,可以使用 map 来充当全局变量
- BPF Tail call:Tail call 是一个 BPF 程序跳转到另一 BPF 程序,BPF 程序首先通过 BPF_MAP_TYPE_PROG_ARRAY 类型的 map 来知道另一个 BPF 程序的指针,然后调用 tail_call() 的 helper function 来执行 Tail call
- 共享 map 的 BPF 程序不要求是相同的程序类型,例如 tracing 程序可以和网络程序共享 map,单个 BPF 程序目前最多可直接访问 64 个不同 map。
内核中的 通用 map 有:
- BPF_MAP_TYPE_HASH
- BPF_MAP_TYPE_ARRAY
- BPF_MAP_TYPE_PERCPU_HASH
- BPF_MAP_TYPE_PERCPU_ARRAY
- BPF_MAP_TYPE_LRU_HASH
- BPF_MAP_TYPE_LRU_PERCPU_HASH
- BPF_MAP_TYPE_LPM_TRIE
内核中的 非通用 map 有:
- BPF_MAP_TYPE_PROG_ARRAY:一个数组 map,用于 hold 其他的 BPF 程序
- BPF_MAP_TYPE_PERF_EVENT_ARRAY
- BPF_MAP_TYPE_CGROUP_ARRAY:用于检查 skb 中的 cgroup2 成员信息
- BPF_MAP_TYPE_STACK_TRACE:用于存储栈跟踪的 MAP
- BPF_MAP_TYPE_ARRAY_OF_MAPS:持有(hold) 其他 map 的指针,这样整个 map 就可以在运行时实现原子替换
- BPF_MAP_TYPE_HASH_OF_MAPS:持有(hold) 其他 map 的指针,这样整个 map 就可以在运行时实现原子替换
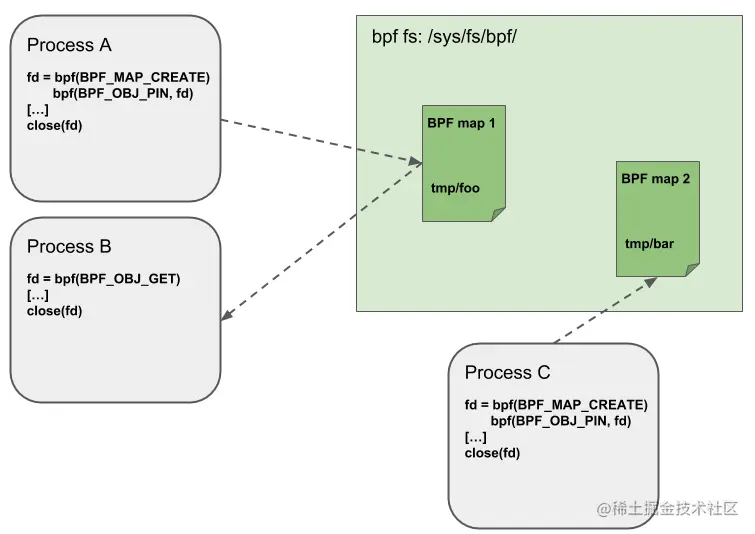
7.5 Object Pinning(钉住对象 )
ebpf map 和程序作为内核资源只能通过文件描述符访问(fd),这个映射实际就是 fd 到内存对象的属性路径的一个映射,这个映射过程叫 pin。
(★)ebpf map 和程序作为内核资源只能通过文件描述符访问,其背后是内核中的匿名 inode。 这个观点很重要,因为 pin 这个行为都是依据这个概念来的。
这样做的优点:
- 用户空间应用程序能够使用大部分文件描述符相关的 API
- 传递给 Unix socket 的文件描述符是透明工作等等
这样做的缺点:
文件描述符受限于进程的生命周期,使得 map 共享之类的操作非常笨重,这给某些特定的场景带来了很多复杂性。
解法
为了解决这个问题,内核实现了一个最小内核空间 BPF 文件系统,BPF map 和 BPF 程序 都可以 pin 到这个文件系统内,这个过程称为 object pinning。BPF 相关的文件系统不是单例模式(singleton),它支持多挂载实例、硬链接、软连接等等。
相应的,BPF 系统调用扩展了两个新命令,如下图所示:
- BPF_OBJ_PIN:钉住一个对象
- BPF_OBJ_GET:获取一个被钉住的对象
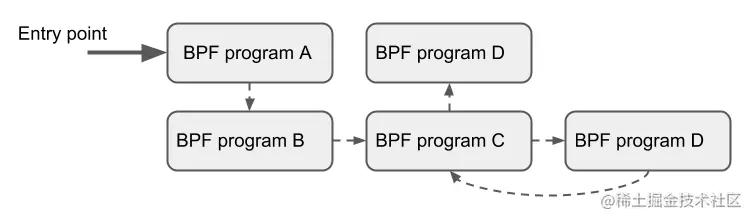
7.6 Tail Calls(尾调用)
一个 BPF 程序可以调用另一个 BPF 程序,并且调用完成后不用返回到原来的程序。
尾调用的机制是指:一个 BPF 程序可以调用另一个 BPF 程序,并且调用完成后不用返回到原来的程序。
- 和普通函数调用相比,这种调用方式开销最小,因为它是用长跳转(long jump)实现的,复用了原来的栈帧 (stack frame)
- BPF 程序都是独立验证的,因此要传递状态,要么使用 per-CPU map 作为 scratch 缓冲区 ,要么如果是 tc 程序的话,还可以使用 skb 的某些字段(例如 cb[])
- 相同类型的程序才可以尾调用,而且它们还要与 JIT 编译器相匹配,因此要么是 JIT 编译执行,要么是解释器执行(invoke interpreted programs),但不能同时使用两种方式
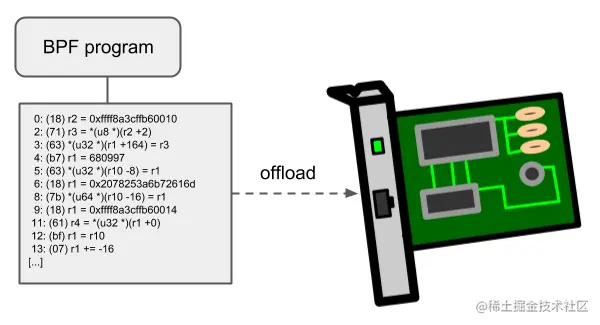
7.7 Offloads(卸载)
就是把 eBPF 的网络程序内核层 bytescode 从 CPU 运行改为由网卡的 MPU 来执行。
eBPF 网络程序,尤其是 tc (Traffic Control,流量控制)和 XDP BPF 程序在内核中都有一个 offload 到硬件的接口,这样就可以直接在网卡上执行 BPF 程序。
资料来源
- 一文看懂eBPF、eBPF的使用(超详细)
- mp.weixin.qq.com
- 【BPF入门系列-1】eBPF 技术简介-阿里云开发者社区
- kerneltravel.net
- ubuntu20.04 安装clang(什么是llvm、什么是clang以及其和clang的关系)_ubuntu安装clang_西京刀客的博客-CSDN博客
- 深入浅出 eBPF|你要了解的 7 个核心问题-阿里云开发者社区
- eBPF 基本架构及使用 - TuringM - 博客园
- 一文详解用eBPF观测HTTP-阿里云开发者社区
- Linux eBPF 技术 入门介绍 - 掘金
- 深入浅出 eBPF: (Linux/Kernel/XDP/BCC/BPFTrace/Cillium)_深入浅出xdp_rtoax的博客-CSDN博客
- ebpf 开发入门之核心概念篇
- cloud.tencent.com

















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









