







是否遇到过这样的问题,很多的原文链接,想要识别里面文字,一个个打开进去截取,过于费劲

可以用python的newspaper库来实现
这个库分为 Python2 和 Python3 两个版本,Python2 下的版本叫做 newspaper,Python3 下的版本叫做 newspaper3k,这里使用 Python3 版本来进行测试。
pip3 install newspaper3k
import urllib
import re
import os
import string
from bs4 import BeautifulSoup
import logging
from newspaper import Article
counts1=0
counts2=0
counts3=0
urlLinks = []
save_urls = '3.txt'
# file = open(save_urls, 'r')
file= open("3.txt",encoding='utf-8')
# 读取之前保存的url
for line in file:
urlLinks.append(line)
file.close()
print(len(urlLinks))
print(urlLinks)
for link in urlLinks:
try:
news = Article(link.strip(), language='zh')
news.download() # 加载网页
news.parse() # 解析网页
print(news.text)
if len(news.text)>256:
counts1=counts1+1
elif len(news.text)<256:
counts2=counts2+1
print('-------------------------------------------------------------------------------------------------------')
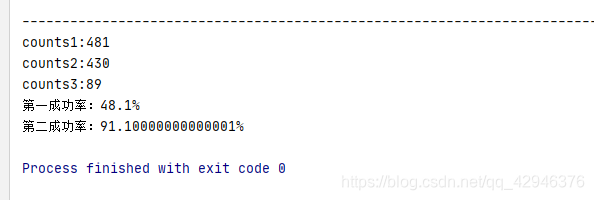
print('counts1:'+str(counts1))
print('counts2:' +str(counts2))
print('counts3:' + str(counts3))
except Exception as e:
counts3 = counts3 + 1
pass
continue
print('第一成功率:'+str(counts1/len(urlLinks)*100)+'%')
print('第二成功率:'+str((counts2+counts1)/len(urlLinks)*100)+'%')
其中第一成功率是在链接网址下识别出来大于256个字除于总链接数(可以测试newspaper库)
第二成功率是在链接网址下识别出来小于256个字除于总链接数
counts1是 识别出来大于256字的网址个数
counts2是 识别出来小于256字的网址个数
counts3是 报错无法识别的网址个数
newspaper常用方法
print(news.title) # 题目
print(news.text) # 正文内容
print(news.authors) # 作者
print(news.keywords) # 关键词
print(news.summary) # 摘要
print(news.top_image) # 配图地址
print(news.movies) # 视频地址
print(news.publish_date) # 发布日期
print(news.html) # 网页源代码

















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









