






if __name__ == '__main__':的作用
一个python文件通常有两种使用方法,第一是作为脚本直接执行,第二是 import 到其他的 python 脚本中被调用(模块重用)执行。因此 if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程,在 if __name__ == 'main': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的。举例说明如下:
- 直接执行
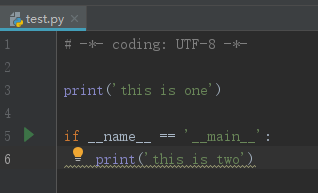
直接执行 test.py,结果如下图,可以成功 print 两行字符串。即,if __name__=="__main__": 语句之前和之后的代码都被执行。

- import 执行
然后在同一文件夹新建名称为 import_test.py 的脚本,输入如下代码:
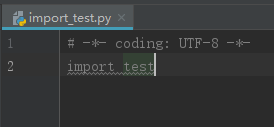
执行 import_test.py 脚本,输出结果如下:

只输出了第一行字符串。即,if __name__=="__main__": 之前的语句被执行,之后的没有被执行。
if __name__ == '__main__':的运行原理
每个python模块(python文件,也就是此处的 test.py 和 import_test.py)都包含内置的变量 __name__,当该模块被直接执行的时候,__name__ 等于文件名(包含后缀 .py );如果该模块 import 到其他模块中,则该模块的 __name__ 等于模块名称(不包含后缀.py)。
而 “__main__” 始终指当前执行模块的名称(包含后缀.py)。进而当模块被直接执行时,__name__ == 'main' 结果为真。
为了进一步说明,我们在 test.py 脚本的 if __name__=="__main__": 之前加入 print(__name__),即将 __name__ 打印出来。文件内容和结果如下:


可以看出,此时变量__name__的值为"__main__"。
再执行 import_test.py,执行结果如下:
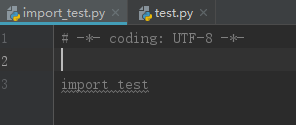

此时,test.py中的__name__变量值为 test,不满足 __name__=="__main__" 的条件,因此,无法执行其后的代码。
Python在Dataframe中新添加一列
先创建一个Dataframe。指明列名,然后赋值
import pandas as pd
data = pd.DataFrame(columns=['a','b'], data=[[1,2],[3,4]])
print(data)
'''
运行结果
a b
0 1 2
1 3 4
'''添加一列空列在最后
data['c'] = ''
print(data)
'''
运行结果
a b c
0 1 2
1 3 4
'''添加一列在最后
data['d'] = [5,6]
print(data)
'''
运行结果
a b c d
0 1 2 5
1 3 4 6
'''如果需要在指定位置添加新的一列,使用insert方法
data.insert(2,'c','')
# 2 :插入的列的位置
# ‘c':待插入列的列名
# ‘ ’:插入的值,这里插入的是空值
data
Out[56]:
a b c
0 1 2
1 3 4 














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









