







一开始想用C写,结果字符串处理太麻烦放弃了。听了老师的话说可以用一门新语言写写,那就顺便试试。
实验一:程序语言的重复率检查
实验目的: 通过编写一个重复率检查程序,掌握编译器的预处理方法。
实验要求:
(1)打开两个C或C++或其它程序语言文件,并显示两个文件内容;
(2)对比两个程序语言源文件,进行重复率检查,给出重复率;注:重复率:连续有n个词相同则计一次重复,n可以通过界面设置进行调整,给出程序设计过程中重复率的设定及计数公式。
(3)两个文件中重复之处用红色标出或者摘录出来。
实验代码:
# encoding: utf-8
list1 = []
list2 = []
n = 0 # 控制重复
k = 0 # 控制循环
m = input("重复字数:") # 要求的长度
p = 0 # 控制输出
r = 0 # 控制输出次数
flag = 0 # 标志位
counts = 0 # 出现的最大公共序列
i = 0
sum = 0
# 打开文件写入
fo = open("C:\Users\Launcher-Z\Desktop\words 1.txt", "r")
str1 = fo.read()
print str1
fo = open("C:\Users\Launcher-Z\Desktop\words 2.txt", "r")
str2 = fo.read()
print str2
# str1 = "Engraved a the signs so He can feel just right When I'm losing yourself, I'l come to found We can finally "
# str2 = "Engraved all the signs so I can feel just right When I'm losing myself, I'll come to find We can finally"
list1 = str1.split()
list2 = str2.split()
while i < len(list1):
k = i
for j in range(len(list2)):
if list1[k] == list2[j]:
if k == (len(list1) - 1):
continue
else:
k = k + 1
n = n + 1
continue
else: # 如果长度大于等于要求则输出i到n的字符,否则不干事;并重置k=i,n=0
if n >= m:
# 改进:如果在集合中,跳过不管;不在集合中,加入集合,执行标志置1,目前不想写了
flag = 1 # 标志位置1
counts = n
sum = sum + n
print '有', n, '个重复单词'
p = i
while r < n:
print list1[p]
p = p + 1
r = r + 1
r = 0
k = i
n = 0
if flag == 1:
i = i + counts - 1
counts = 0
flag = 0 # 重置标志
i = i + 1
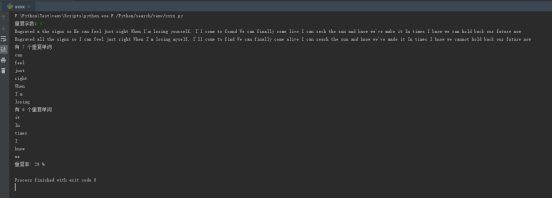
print '重复率:', sum*100/len(list1), '%'

问题及讨论:
这个代码适用的条件应该是当n值比较大的时候,如果n值过小,那么就会造成输出第一段中后方存在与第二段中前方相同的字段,即第一段中的与自己重复的部分会被计算进去,造成结果错误——改进方法:可以设置一个集合,如代码中的注释所说,但如果集合中存放单独的单词不行,重复的会被抛弃,只能以短语为单位存放。
第一段文字从头到尾之遍历了一遍,而的第二段遍历了许多许多次性能上是否还可以优化有待商榷。
单纯地先把实验报告上的东西搬上来了,第一次接触python,肯定还有很多要去学习的。














 2653
2653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









