








后端思维篇:手把手教你写一个并行调用模板
前言
手把手教你写一个并行调用模板
业务场景:查询采集详情、处理详情、发送详情
实现方案:
方案1:
- 串行实现查询采集详情、处理详情、发送详情
方案2:
- CompletionService实现并行调用
- 抽取通用的并行调用方法
- 代码思考以及设计模式应用
- 思考总结
1. 一个串行调用的例子
如果让你设计一个App首页查询的接口,它需要查询采集详情、处理详情、发送详情等等。一般情况,小伙伴会实现如下:
/**
* 查询采集详情、处理详情、发送详情
*
* @param businessTypes 业务类型
* @param pageNum 默认1
* @param pageSize 默认10
* @return 结果集
*/
@Override
public Result findDetail(String businessTypes, int pageNum, int pageSize) throws Exception {
long startTime = System.currentTimeMillis();
LOGGER.info("findDetail.start.startTime={}", startTime);
// 查询采集详情
CollectDetailVO fileCollectDetail = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
// 查询处理详情
HandleDetailVO handleDetail = handleService.findHandleDetail(businessTypes, pageNum, pageSize);
// 查询发送详情
SendDetailVO fileSendDetail = sendService.findFileSendDetail(businessTypes, pageNum, pageSize);
// 组装数据,返回结果集
Map<String, Object> map = new HashMap<>();
map.put("collectDetail", fileCollectDetail);
map.put("handleDetail", handleDetail);
map.put("sendDetail", fileSendDetail);
LOGGER.info("串行查询耗时={}", System.currentTimeMillis() - startTime);
return Result.successJson(map);
}
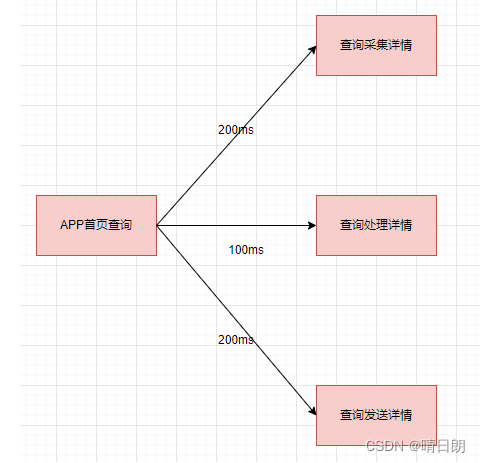
这段代码会有什么问题嘛?(返回结果不要在意了哈)其实这是一段挺正常的代码,但是这个方法实现中,采集详情、处理详情、发送详情,是串行的。如果采集详情耗时200ms,查询处理详情100ms,查询发送详情200ms的话,耗时就是500ms啦。

其实为了优化性能,我们可以修改为并行调用的方式,耗时可以降为200ms,如下图所示:
2. CompletionService实现并行调用
对于上面的例子,如何实现并行调用呢?
有小伙伴说,可以使用Future+Callable实现多个任务的并行调用。但是线程池执行批量任务时,返回值用Future的get()获取是阻塞的,如果前一个任务执行比较耗时的话,get()方法会阻塞,形成排队等待的情况。
而CompletionService是对定义ExecutorService进行了包装,可以一边生成任务,一边获取任务的返回值。让这两件事分开执行,任务之间不会互相阻塞,可以获取最先完成的任务结果。
CompletionService的实现原理比较简单,底层通过FutureTask+阻塞队列,实现了任务先完成的话,可优先获取到。也就是说任务执行结果按照完成的先后顺序来排序,先完成可以优先获取到。内部有一个先进先出的阻塞队列,用于保存已经执行完成的Future,你调用CompletionService的poll或take方法即可获取到一个已经执行完成的Future,进而通过调用Future接口实现类的get方法获取最终的结果。
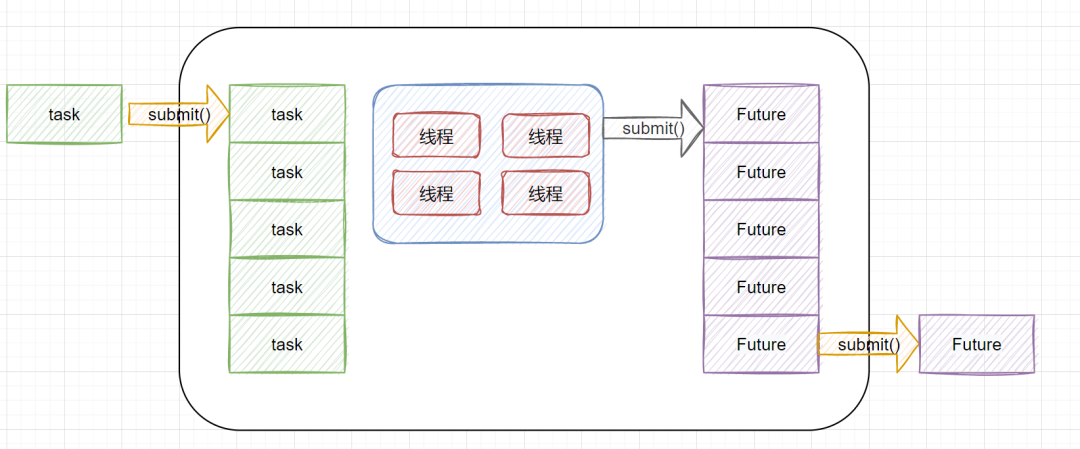
接下来,我们来看下,如何用CompletionService,实现并行查询APP首页信息哈。思考步骤如下:
-
我们先把查询用户信息的任务,放到线程池,如下:
ExecutorService executor = Executors.newFixedThreadPool(10); ExecutorCompletionService<CollectDetailVO> resultExecutorCompletionService = new ExecutorCompletionService<CollectDetailVO>(executor); Callable<CollectDetailVO> collectServiceResult = () -> { CollectDetailVO fileCollectDetail = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize); return fileCollectDetail; }; resultExecutorCompletionService.submit(collectServiceResult); -
如果想把查询处理详情的任务,也放到这个线程池的话,发现不好放了,因为返回类型不一样,一个是CollectDetailVO,另外一个是HandleDetailVO。那这时候,我们把泛型声明为Object即可,因为所有对象都是继承于Object的。如下:
ExecutorService executor = Executors.newFixedThreadPool(10);
CompletionService<Object> baseDTOCompletionService = new ExecutorCompletionService<Object>(executor);
// 查询采集详情
Callable<Object> collectServiceResult = () -> {
return collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
};
// 查询处理详情
Callable<Object> handleServiceResult = () -> {
return handleService.findHandleDetail(businessTypes, pageNum, pageSize);
};
//提交查询采集详情任务
baseDTOCompletionService.submit(collectServiceResult);
//提交查询处理详情任务
baseDTOCompletionService.submit(handleServiceResult);
- 这里会有个问题,就是获取返回值的时候,我们不知道哪个
Object是查询详情的CollectDetailVO,哪个是HandleDetailVO?怎么办呢?这时候,我们可以在参数里面做个扩展嘛,即参数声明为一个基础对象BaseRspDTO,再搞个泛型放Object数据的,然后基础对象BaseRspDTO有个区分是CollectDetailVO还是HandleDetailVO的唯一标记属性key。代码如下:
public class BaseRspDTO<T extends Object> {
//区分是DTO返回的唯一标记,比如是CollectDetailVO还是HandleDetailVO
private String key;
//返回的data
private T data;
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
//并行查询App首页信息
/**
* 并行查询改造:并行查询采集详情、处理详情、发送详情
*
* @param businessTypes 业务类型
* @param pageNum 默认1
* @param pageSize 默认10
* @return 结果集
*/
@Override
public Result findDetailByParallel(String businessTypes, int pageNum, int pageSize) throws Exception {
long startTime = System.currentTimeMillis();
LOGGER.info("findDetail.start.startTime={}", startTime);
ExecutorService executor = Executors.newFixedThreadPool(10);
ExecutorCompletionService<BaseRspDto<Object>> resultExecutorCompletionService = new ExecutorCompletionService<BaseRspDto<Object>>(executor);
Callable<BaseRspDto<Object>> collectServiceResult = () -> {
Result fileCollectDetail = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey("collectDetail");
baseRspDto.setData(fileCollectDetail);
return baseRspDto;
};
Callable<BaseRspDto<Object>> handleServiceResult = () -> {
Result handleDetail = handleService.findHandleDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey("handleDetail");
baseRspDto.setData(handleDetail);
return baseRspDto;
};
Callable<BaseRspDto<Object>> sendServiceResult = () -> {
Result fileSendDetail = sendService.findFileSendDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey("sendDetail");
baseRspDto.setData(fileSendDetail);
return baseRspDto;
};
resultExecutorCompletionService.submit(collectServiceResult);
resultExecutorCompletionService.submit(handleServiceResult);
resultExecutorCompletionService.submit(sendServiceResult);
Map<String, Object> map = new HashMap<>();
for (int i = 0; i < 3; i++) {
Future<BaseRspDto<Object>> resultFuture = resultExecutorCompletionService.poll(3, TimeUnit.SECONDS);
BaseRspDto<Object> baseRspDto = resultFuture.get();
if ("collectDetail".equals(baseRspDto.getKey())) {
map.put("collectDetail", baseRspDto.getData());
} else if ("handleDetail".equals(baseRspDto.getKey())) {
map.put("handleDetail", baseRspDto.getData());
} else if ("sendDetail".equals(baseRspDto.getKey())) {
map.put("sendDetail", baseRspDto.getData());
}
}
// 组装数据,返回结果集
LOGGER.info("并行查询耗时={}", System.currentTimeMillis() - startTime);
return Result.successJson(map);
}
到这里为止,一个基于CompletionService实现并行调用的例子已经实现啦。是不是很开心,哈哈。
3. 抽取通用的并行调用方法
我们回过来观察下第2小节,查询app首页信息的demo:CompletionService实现了并行调用。不过大家有没有什么其他优化想法呢?比如,假设别的业务场景,也想通过并行调用优化,那是不是也得搞一套类似第2小节的代码。所以,我们是不是可以抽取一个通用的并行方法,让别的场景也可以用,对吧?这就是后端思维啦!
基于第2小节的代码,我们如何抽取通用的并行调用方法呢。
首先,这个通用的并行调用方法,不能跟业务相关的属性挂钩,所以方法的入参应该有哪些呢?
方法的入参,可以有
Callable。因为并行,肯定是多个Callable任务的。所以,入参应该是一个Callable的数组。再然后,基于上面的APP首页查询的例子,Callable里面得带BaseRspDTO泛型,对吧?因此入参就是List<Callable<BaseRspDTO<Object>>> list。
那并行调用的出参呢?你有多个Callable的任务,是不是得有多个对应的返回,因此,你的出参可以是List<BaseRspDTO<Object>>。我们抽取的通用并行调用模板,就可以写成酱紫:
public List<BaseRspDTO<Object>> executeTask(List<Callable<BaseRspDTO<Object>>> taskList) {
List<BaseRspDTO<Object>> resultList = new ArrayList<>();
//校验参数
if (taskList == null || taskList.size() == 0) {
return resultList;
}
ExecutorService executor = Executors.newFixedThreadPool(10);
CompletionService<BaseRspDTO<Object>> baseDTOCompletionService = new ExecutorCompletionService<BaseRspDTO<Object>>(executor);
//提交任务
for (Callable<BaseRspDTO<Object>> task : taskList) {
baseDTOCompletionService.submit(task);
}
try {
//遍历获取结果
for (int i = 0; i < taskList.size(); i++) {
Future<BaseRspDTO<Object>> baseRspDTOFuture = baseDTOCompletionService.poll(2, TimeUnit.SECONDS);
resultList.add(baseRspDTOFuture.get());
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return resultList;
}
既然我们是抽取通用的并行调用方法,那以上的方法是否还有哪些地方需要改进的呢?
- 第一个可以优化的地方,就是
executor线程池,比如有些业务场景想用A线程池,有些业务想用B线程池,那么,这个方法,就不通用啦,对吧。我们可以把线程池以参数的形式提供出来,给调用方自己控制。 - 第二个可以优化的地方,就是
CompletionService的poll方法获取时,超时时间是写死的。因为不同业务场景,超时时间要求可能不一样。所以,超时时间也是可以以参数形式放出来,给调用方自己控制。
我们再次优化一下这个通用的并行调用模板,代码如下:
/**
* @Descrition: 并行处理任务框架封装
* @ClassName: ParallelCommonService
* @Author: 晴日朗
* @Date 2022年10月26日14:11
* @Version: V1.0
*/
@Service
public class ParallelCommonService {
/**
* 并行执行任务
*
* @param taskList 多个任务
* @param timeOut 获取任务执行完之后的结果过期时间
* @param executor 自定义线程池
* @return List<BaseRspDto < Object>> 任务结果
*/
public List<BaseRspDto<Object>> executeTaskByParallel(List<Callable<BaseRspDto<Object>>> taskList, long timeOut, ExecutorService executor) throws InterruptedException, ExecutionException {
// 任务结果集
List<BaseRspDto<Object>> resultList = new ArrayList<>();
//校验参数
if (CollectionUtils.isEmpty(taskList)) {
return resultList;
}
if (executor == null) {
return resultList;
}
if (timeOut <= 0) {
return resultList;
}
//提交任务
CompletionService<BaseRspDto<Object>> baseDTOCompletionService = new ExecutorCompletionService<BaseRspDto<Object>>(executor);
for (Callable<BaseRspDto<Object>> task : taskList) {
baseDTOCompletionService.submit(task);
}
//遍历获取结果
for (int i = 0; i < taskList.size(); i++) {
Future<BaseRspDto<Object>> baseRspDTOFuture = baseDTOCompletionService.poll(timeOut, TimeUnit.SECONDS);
resultList.add(baseRspDTOFuture.get());
}
// 返回任务结果集
return resultList;
}
}
以后别的场景也需要用到并行调用的话,直接调用你的这个方法即可,是不是有点小小的成就感啦,哈哈。
4. 代码思考以及设计模式应用
我们把抽取的那个公用的并行调用方法,应用到App首页信息查询的例子,代码如下:
/**
* 并行查询改造:并行查询采集详情、处理详情、发送详情
*
* @param businessTypes 业务类型
* @param pageNum 默认1
* @param pageSize 默认10
* @return 结果集
*/
@Override
public Result findDetailByParallel(String businessTypes, int pageNum, int pageSize) throws Exception {
long startTime = System.currentTimeMillis();
LOGGER.info("findDetail.start.startTime={}", startTime);
ExecutorService executor = Executors.newFixedThreadPool(10);
Callable<BaseRspDto<Object>> collectServiceResult = () -> {
Result fileCollectDetail = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey("collectDetail");
baseRspDto.setData(fileCollectDetail);
return baseRspDto;
};
Callable<BaseRspDto<Object>> handleServiceResult = () -> {
Result handleDetail = handleService.findHandleDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey("handleDetail");
baseRspDto.setData(handleDetail);
return baseRspDto;
};
Callable<BaseRspDto<Object>> sendServiceResult = () -> {
Result fileSendDetail = sendService.findFileSendDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey("sendDetail");
baseRspDto.setData(fileSendDetail);
return baseRspDto;
};
List<Callable<BaseRspDto<Object>>> taskList = new ArrayList<>();
taskList.add(collectServiceResult);
taskList.add(handleServiceResult);
taskList.add(sendServiceResult);
List<BaseRspDto<Object>> resultList = parallelCommonService.executeTaskByParallel(taskList, 10, executor);
if (CollectionUtils.isEmpty(resultList)) return Result.successJson(null);
Map<String, Object> map = new HashMap<>();
for (int i = 0; i < resultList.size(); i++) {
BaseRspDto<Object> baseRspDto = resultList.get(i);
if ("collectDetail".equals(baseRspDto.getKey())) {
map.put("collectDetail", baseRspDto.getData());
} else if ("handleDetail".equals(baseRspDto.getKey())) {
map.put("handleDetail", baseRspDto.getData());
} else if ("sendDetail".equals(baseRspDto.getKey())) {
map.put("sendDetail", baseRspDto.getData());
}
}
// 组装数据,返回结果集
LOGGER.info("并行查询耗时={}", System.currentTimeMillis() - startTime);
return Result.successJson(map);
}
基于以上代码,小伙伴们,是否还有其他方面的优化想法呢?比如这几个Callable查询任务,我们是不是也可以抽取一下?让代码更加简洁。
二话不说,现在我们直接建一个
BaseTaskCommand类,实现Callable接口,把查询采集详情、查询处理详情、查询发送详情的任务放进去。
代码如下:
public class BaseTaskCommand implements Callable<BaseRspDTO<Object>> {
// 任务入参
private String params;
// 策略类型
private String key;
private FileCollectDetailService collectService;
private FileHandleService handleService;
private FileSendDetailService sendService;
public BaseTaskCommand(String params, String key) {
this.params = params;
this.key = key;
}
@Override
public BaseRspDTO<Object> call() throws Exception {
if ("collectDetail".equals(key)) {
// 查询采集详情
Result fileCollectDetail = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
BaseRspDTO<Object> userBaseRspDTO = new BaseRspDTO<Object>();
userBaseRspDTO.setKey("collectDetail");
userBaseRspDTO.setData(fileCollectDetail);
return userBaseRspDTO;
} else if ("handleDetail".equals(key)) {
// 处理详情
Result handleDetail = handleService.findHandleDetail(businessTypes, pageNum, pageSize);
BaseRspDTO<Object> bannerBaseRspDTO = new BaseRspDTO<Object>();
bannerBaseRspDTO.setKey("handleDetail");
bannerBaseRspDTO.setData(handleDetail);
return bannerBaseRspDTO;
} else if ("sendDetail".equals(key)) {
// 发送详情
Result fileSendDetail = sendService.findFileSendDetail(businessTypes, pageNum, pageSize);
BaseRspDTO<Object> labelBaseRspDTO = new BaseRspDTO<Object>();
labelBaseRspDTO.setKey("sendDetail");
labelBaseRspDTO.setData(fileSendDetail);
return labelBaseRspDTO;
}
return null;
}
}
以上这块代码,构造函数还是有比较多的参数,并且call()方法中,有多个if...else...,如果新增一个条件分支(比如查询浮层信息),那又得在call方法里修改了,并且BaseTaskCommand的构造器也要修改了。
大家是否有印象,当程序中出现多个if…else…时,我们就可以考虑使用策略模式+工厂模式优化。
我们声明多个策略实现类,把条件分支里的实现,搬到策略类,如下:
/**
* @Descrition: 并行执行策略类-具体实现在各个策略实现类
* @ClassName: IBaseTask
* @Author: 晴日朗
* @Date 2022年10月26日14:52
* @Version: V1.0
*/
public interface IBaseTaskStrategy {
//返回每个策略类的key,如是useInfoDTO还是bannerDTO,还是labelDTO
String getTaskKey();
// 执行任务策略
BaseRspDto<Object> executeTask(String params) throws Exception;
}
/**
* @Descrition: 并行执行策略实现类逻辑层-采集详情查询
* @ClassName: collectService
* @Author: 晴日朗
* @Date 2022年10月26日15:52
* @Version: V1.0
*/
@Service
public class collectService implements IBaseTaskStrategy {
@Autowired
private FileCollectDetailService collectService;
@Override
public String getTaskKey() {
return DetailSearchEnum.COLLECT.getKey();
}
@Override
public BaseRspDto<Object> executeTask(String params) throws Exception {
// 获取入参、校验入参 省略...
HashMap<String, String> paramsMap = JSON.parseObject(params, new TypeReference<HashMap<String, String>>() {
});
String businessTypes = paramsMap.get("businessTypes");
int pageNum = Integer.parseInt(paramsMap.get("pageNum"));
int pageSize = Integer.parseInt(paramsMap.get("pageSize"));
Result result = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey(getTaskKey());
baseRspDto.setData(result);
return baseRspDto;
}
}
/**
* @Descrition: 并行执行策略实现类逻辑层-处理详情查询
* @ClassName: collectService
* @Author: 晴日朗
* @Date 2022年10月26日15:52
* @Version: V1.0
*/
@Service
public class handleService implements IBaseTaskStrategy {
@Autowired
private FileHandleService handleService;
@Override
public String getTaskKey() {
return DetailSearchEnum.HANDLE.getKey();
}
@Override
public BaseRspDto<Object> executeTask(String params) throws Exception {
// 获取入参、校验入参 省略...
HashMap<String, String> paramsMap = JSON.parseObject(params, new TypeReference<HashMap<String, String>>() {
});
String businessTypes = paramsMap.get("businessTypes");
int pageNum = Integer.parseInt(paramsMap.get("pageNum"));
int pageSize = Integer.parseInt(paramsMap.get("pageSize"));
Result result = handleService.findHandleDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey(getTaskKey());
baseRspDto.setData(result);
return baseRspDto;
}
}
@Service
public class sendService implements IBaseTaskStrategy {
@Autowired
private FileSendDetailService sendDetailService;
@Override
public String getTaskKey() {
return DetailSearchEnum.SEND.getKey();
}
@Override
public BaseRspDto<Object> executeTask(String params) throws Exception {
// 获取入参、校验入参 省略...
HashMap<String, String> paramsMap = JSON.parseObject(params, new TypeReference<HashMap<String, String>>() {
});
String businessTypes = paramsMap.get("businessTypes");
int pageNum = Integer.parseInt(paramsMap.get("pageNum"));
int pageSize = Integer.parseInt(paramsMap.get("pageSize"));
Result result = sendDetailService.findFileSendDetail(businessTypes, pageNum, pageSize);
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
baseRspDto.setKey(getTaskKey());
baseRspDto.setData(result);
return baseRspDto;
}
}
...
然后这几个策略实现类,怎么交给spring管理呢?我们可以实现ApplicationContextAware接口,把策略的实现类注入到一个map,然后根据请求方不同的策略请求类型(即CollectDetailVO还是HandleDetailVO等),去实现不同的策略类调用。其实这类似于工厂模式的思想。代码如下:
/**
* @Descrition: 自定义策略工厂-管理所有的并发执行策略实现类,根据请求方的策略类型(即key值),去调用特定的策略实现类实现业务逻辑。
* @ClassName: TaskStrategyFactory
* @Author: 晴日朗
* @Date 2022年10月26日15:01
* @Version: V1.0
*/
@Component // 交给spring管理所有的任务策略实现类
public class ParallelTaskStrategyFactory implements ApplicationContextAware {
// ConcurrentHashMap保存策略实现类 key由BaseTaskCommand自定义传入
private Map<String, IBaseTaskStrategy> map = new ConcurrentHashMap<>();
/**
* 策略实现类交给spring管理
*
* @param applicationContext spring上下文
* @throws BeansException bean获取异常
*/
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 获取到任务策略实现类
Map<String, IBaseTaskStrategy> tempMap = applicationContext.getBeansOfType(IBaseTaskStrategy.class);
// 存储任务测类实现类到ConcurrentHashMap
tempMap.values().forEach(iBaseTaskStrategy -> {
map.put(iBaseTaskStrategy.getTaskKey(), iBaseTaskStrategy);
});
}
/**
* 任务分发到具体的策略实现类
*
* @param key 测类类型
* @param params 参数
* @return 任务结果
*/
public BaseRspDto<Object> executeTask(String key, String params) throws Exception {
IBaseTaskStrategy iBaseTaskStrategy = map.get(key);
if (Objects.isNull(iBaseTaskStrategy)) {
throw new Exception(key + "找不到对应的任务策略实现类");
}
// 触发具体的任务策略实现类
return iBaseTaskStrategy.executeTask(params);
}
}
有了策略工厂类ParallelTaskStrategyFactory,我们再回来优化下BaseTaskCommand类的代码。它的构造器已经不需要多个FileCollectDetailService collectService, FileHandleService handleService, FileSendDetailService sendDetailService啦,只需要传入策略工厂类TaskStrategyFactory即可。同时策略也不需要多个if...else...判断了,用策略工厂类TaskStrategyFactory代替即可。优化后的代码如下:
/**
* @Descrition: CompletionService执行需要Callable接口-任务策略请求方配置
* @ClassName: BaseTaskCommand
* @Author: 晴日朗
* @Date 2022年10月26日15:52
* @Version: V1.0
*/
public class BaseTaskCommand implements Callable<BaseRspDto<Object>> {
// 任务入参
private String params;
// 策略类型
private String key;
// 任务并行执行策略工厂类
private ParallelTaskStrategyFactory strategyFactory;
public BaseTaskCommand(String params, String key, ParallelTaskStrategyFactory strategyFactory) {
this.params = params;
this.key = key;
this.strategyFactory = strategyFactory;
}
/**
* 策略工厂分发请求到具体的任务策略实现类实现各自的业务逻辑
*
* @return computed result
*/
@Override
public BaseRspDto<Object> call() throws Exception {
return strategyFactory.executeTask(key, params);
}
}
因此整个app首页信息并行查询,就可以优化成这样啦,如下:
/**
* 并行查询改造:使用策略+工厂抽取代码
* <p>
* 并行查询采集详情、处理详情、发送详情
*
* @param businessTypes 业务类型
* @param pageNum 默认1
* @param pageSize 默认10
* @return 结果集
*/
@Override
public Result findDetailByParallel(String businessTypes, int pageNum, int pageSize) throws Exception {
// 记录开始时间
long startTime = System.currentTimeMillis();
LOGGER.info("findDetail.start.startTime={}", startTime);
// 参数(校验那些就省了)
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("businessTypes", businessTypes);
paramMap.put("pageNum", pageNum);
paramMap.put("pageSize", pageSize);
String params = JsonUtils.toJson(paramMap);
// 自定义线程池
BlockingDeque<Runnable> blockingDeque = new LinkedBlockingDeque<>(10);
ExecutorService executor = new ThreadPoolMonitor(10, 10, 1, TimeUnit.SECONDS, blockingDeque, "findDetailByParallelPool");
// 配置所有任务策略实现类 维护在枚举类
List<Callable<BaseRspDto<Object>>> taskList = new ArrayList<>();
Arrays.stream(DetailSearchEnum.values()).forEach(searchEnum -> taskList.add(new BaseTaskCommand(params, searchEnum.getKey(), taskStrategyFactory)));
// taskList.add(new BaseTaskCommand(params, "collectDetail", taskStrategyFactory));
// taskList.add(new BaseTaskCommand(params, "handleDetail", taskStrategyFactory));
// taskList.add(new BaseTaskCommand(params, "sendDetail", taskStrategyFactory));
// 并发执行任务
List<BaseRspDto<Object>> resultList = parallelCommonService.executeTaskByParallel(taskList, 10, executor);
// 结果封装
if (CollectionUtils.isEmpty(resultList)) return Result.successJson(null);
Map<String, Object> map = new HashMap<>();
for (BaseRspDto<Object> baseRspDto : resultList) {
for (DetailSearchEnum value : DetailSearchEnum.values()) {
// baseRspDto.getKey()的值在具体的任务策略实现类赋值,也是在策略枚举维护
if (value.getKey().equals(baseRspDto.getKey())) {
map.put(value.getKey(), baseRspDto.getData());
}
}
}
// 记录结束时间
LOGGER.info("并行查询耗时={}", System.currentTimeMillis() - startTime);
// 返回结果集
return Result.successJson(map);
}
5.并行框架使用方法总结
1.注入并发执行类
@Autowired
private ParallelCommonService parallelCommonService
2.构造任务策略taskList
// 配置所有任务策略实现类 维护在枚举类
List<Callable<BaseRspDto<Object>>> taskList = new ArrayList<>();
// 循环枚举值构造、控制任务策略实现类
Arrays.stream(DetailSearchEnum.values()).forEach(searchEnum -> taskList.add(new BaseTaskCommand(params, searchEnum.getKey(), taskStrategyFactory)));
3.并发执行任务(自定义线程池和超时时间)
List<BaseRspDto<Object>> resultList = parallelCommonService.executeTaskByParallel(taskList, 10, executor);
4.自定义具体的任务策略实现类(n个,最后的返回值是n个实现类的值返回,需要自己手动组装结果集)
/**
* @Descrition: 并行执行策略实现类逻辑层-采集详情查询
* @ClassName: collectService
* @Author: 晴日朗
* @Date 2022年10月26日15:52
* @Version: V1.0
*/
@Service
public class collectService implements IBaseTaskStrategy {
@Autowired
private FileCollectDetailService collectService;
@Override
public String getTaskKey() {
return DetailSearchEnum.COLLECT.getKey();
}
@Override
public BaseRspDto<Object> executeTask(String params) throws Exception {
//=================业务逻辑 start =======================
// 获取入参、校验入参 省略...
HashMap<String, String> paramsMap = JSON.parseObject(params, new TypeReference<HashMap<String, String>>() {
});
String businessTypes = paramsMap.get("businessTypes");
int pageNum = Integer.parseInt(paramsMap.get("pageNum"));
int pageSize = Integer.parseInt(paramsMap.get("pageSize"));
Result result = collectService.findFileCollectDetail(businessTypes, pageNum, pageSize);
//=================业务逻辑 end=======================
// 返回数据组装
BaseRspDto<Object> baseRspDto = new BaseRspDto<Object>();
// 设置策略类型值
baseRspDto.setKey(getTaskKey());
// 设置数据
baseRspDto.setData(result);
return baseRspDto;
}
}
6. 思考总结
以上代码整体优化下来,已经很简洁啦。那还有没有别的优化思路呢。
除了
CompletionService,有些小伙伴喜欢用CompletableFuture实行并行调用,大家可以自己动手操戈写一写。
本文大家学到了哪些知识呢?
- 如何优化接口性能?某些场景下,可以使用并行调用代替串行。
- 如何实现并行调用呢?可以使用
CompletionService。 - 学到的后端思维是?日常开发中,要学会抽取通用的方法、或者工具。
6. 思考总结
以上代码整体优化下来,已经很简洁啦。那还有没有别的优化思路呢。
除了
CompletionService,有些小伙伴喜欢用CompletableFuture、fork/join实行并行调用,大家可以自己试试。
本文大家学到了哪些知识呢?
- 如何优化接口性能?某些场景下,可以使用并行调用代替串行。
- 如何实现并行调用呢?可以使用
CompletionService。 - 学到的后端思维是?日常开发中,要学会抽取通用的方法、或者工具。
- 策略模式和工厂模式的应用
















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









