






RPC调用框架
工作原理
初始化过程细节:第一步,就是将服务装载到容器中,然后准备注册服务。和Spring中启动过程类似,Spring启动时,将bean装载进容器中的时候,首先要解析bean。所以dubbo也是先读配置文件解析服务。
解析服务:1)、基于dubbo.jar内的META-INF/spring.handlers配置,spring在遇到dubbo名称空间时,会回调DubboNamespaceHandler类。
2)、所有的dubbo标签都统一用DubboBeanDefinitionParser进行解析,基于一对一属性映射,将XML标签解析为Bean对象,生产者或者消费者初始化的时候,会将Bean对象转换为URL格式,将所有Bean属性转换成URL的参数。然后将URL传给Protocal扩展点,基于扩展点的Adaptive机制,根据URL的协议头,进行不同协议的服务暴露和引用。
暴露服务:1)、直接暴露服务端口:在没有注册中心的情况下,配置ServiceConfig解析出的URL,基于扩展点Adaptive机制,通过URL的协议头识别,直接调用DubboProtocol的export()方法,打开服务端口
2)、向注册中心暴露服务:将服务的IP和端口一同暴露给注册中心。ServiceConfig解析出的url格式,基于扩展点的Adaptive机制,通过URL的协议头识别,调用RegistryProtocol的export()方法,将export参数中的提供者URL先注册到注册中心,再重新传给Protocol扩展点进行暴露。
引用服务:1)、直接引用服务:在没有注册中心的情况下,直连提供者,ReferenceConfig解析出URL格式,基于扩展点的Adaptive机制,通过URL协议头识别,直接调用DubboProtocol的refer方法,返回提供者引用。
2)、从注册中心发现引用服务:ReferenceConfig解析出的URL的格式,基于扩展点的Adaptive机制,通过URL协议头识别,就会调用RegistryProtocol的refer方法,从refer参数总的条件,查询提供者URL,通过提供者URL协议头识别,就会调用DubboProtocol的refer()方法,得到提供者引用。然后RegistryProtocol将多个提供者引用通过Cluster扩展点,伪装成单个提供者引用返回。
执行流程
1、start:启动Spring容器时,自动启动dubbo的Provider
2、register:dubbo的Provider在启动后自动会去注册内容。注册的内容包括:
1.1 Provider的IP
1.2 Provider的端口
1.3 Provider对外提供的接口、方法
1.4 dubbo版本号
1.5 访问Provider的协议
3、subscribe:订阅,当Consumer启动时,自动去Registry获取到所有已注册的服务信息
4、notify: 通知, 当Provider的信息发生变化时,自动由Registry向Consumer推送通知
5、invoke: 调用, Consumer调用Provider中的方法
4.1同步请求,消耗一定性能,但是必须是同步请求,因为需要接收调用方法后的结果
6、count: 次数, 每隔2分钟,Provider和Consumer自动向Monitor发送访问次数,Monitor进行统计。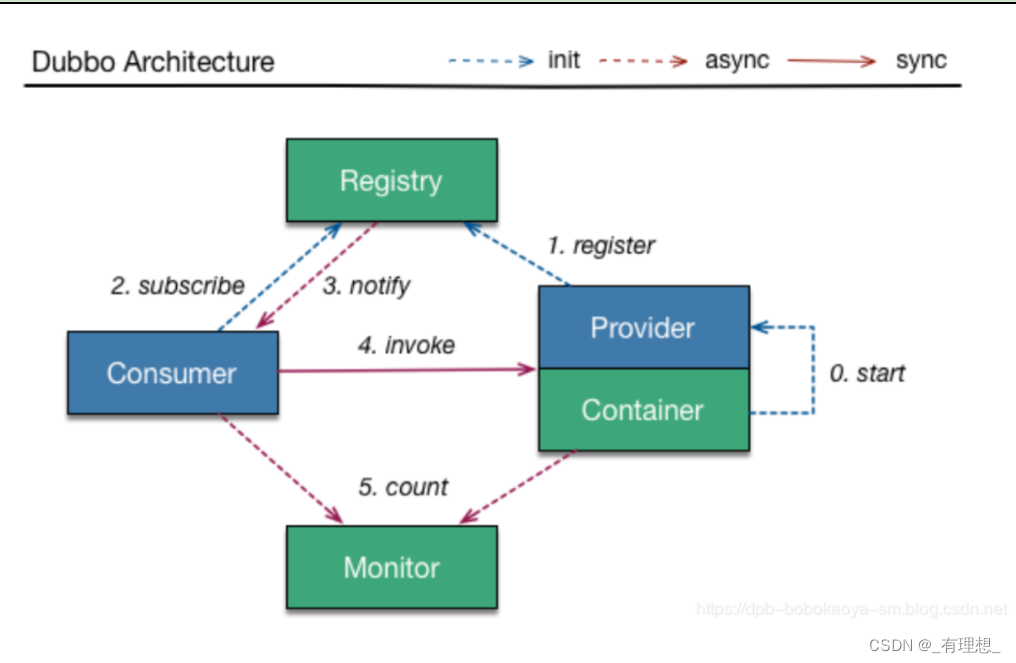
注册中心(registry):生产者在此注册并发布内容,消费者在此订阅并接收发布的内容。
消费者(consumer):客户端,从注册中心获取到方法,可以调用生产者中的方法。
生产者(provider):服务端,生产内容,生产前需要依赖容器(先启动容器)。
容器(container):生产者在启动执行的时候,必须依赖容器才能正常启动(默认依赖的是spring容器)
监控中心(monitor):是dubbo提供的一个jar工程。主要功能是监控服务端和消费端的使用数据。
如:服务端是什么,有多少接口,多少方法,调用次数,压力信息等,客户端有多少,调用过哪些服务端,调用了多少次等。
超时设置的优先级
客户端方法级>服务端方法级>客户端接口级>服务端接口级>客户端全局>服务端全局
超时的实现原理
dubbo默认采用了netty做为网络组件,它属于一种NIO的模式。消费端发起远程请求后,线程不会阻塞等待服务端的返回,而是马上得到一个ResponseFuture,消费端通过不断的轮询机制判断结果是否有返回。因为是通过轮询,轮询有个需要特别注要的就是避免死循环,所以为了解决这个问题就引入了超时机制,只在一定时间范围内做轮询,如果超时时间就返回超时异常。
负载均衡策略:
加权随机:
最小活跃数:
加权轮询:
一致性哈希:
最短响应时间的权重随机















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









