







笔者:YY同学
文章目录
Ext(Extended File System)是属于 Linux 的文件系统,最新发行版是 Ext3。Ext 的特点有两个:1. 块地址长度总是 4 bytes,2. 块大小只可能是 1024,2048 或者 4096 bytes。
Ext3 文件系统大小

Ext3 i-node 结构
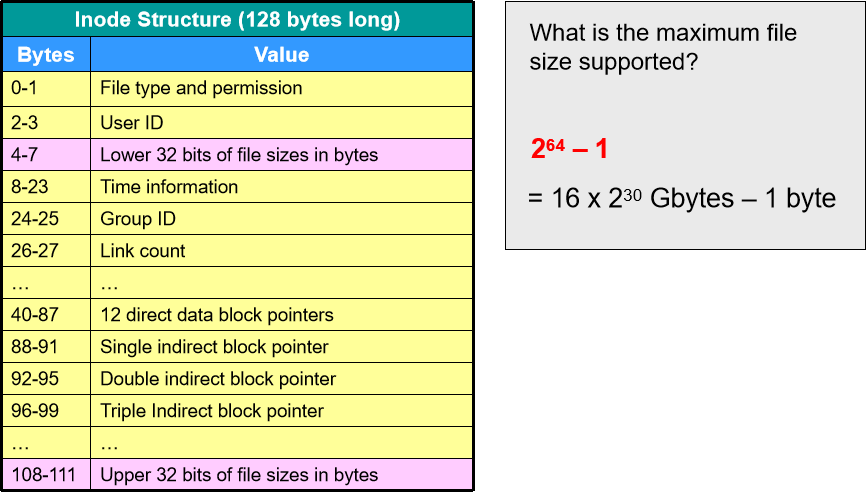
- 4-7 bytes 表示文件大小的 LSB 32位,108-111 bytes 表示文件大小的 MSB 32位,文件大小最大为 2 64 − 1 2^{64}-1 264−1 bytes。
- 40-99 位是 i-node 结构信息。
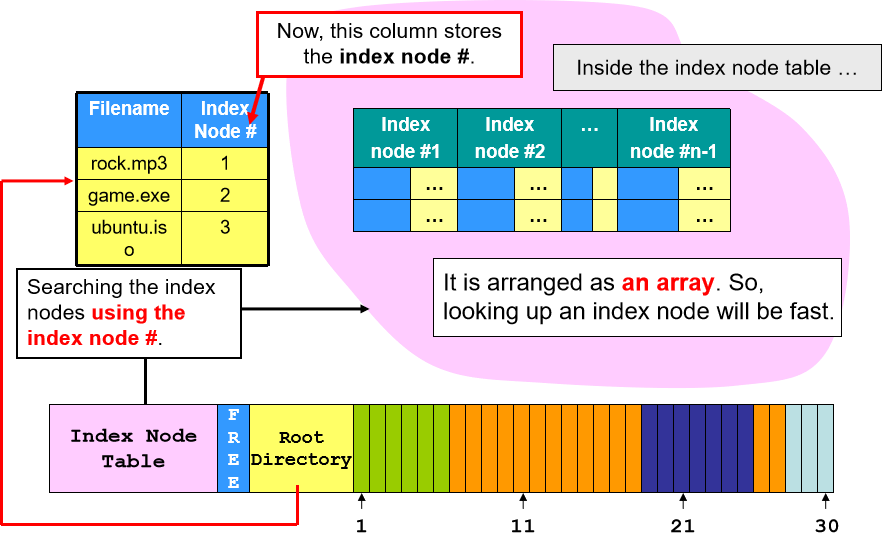
Ext3 分区概念
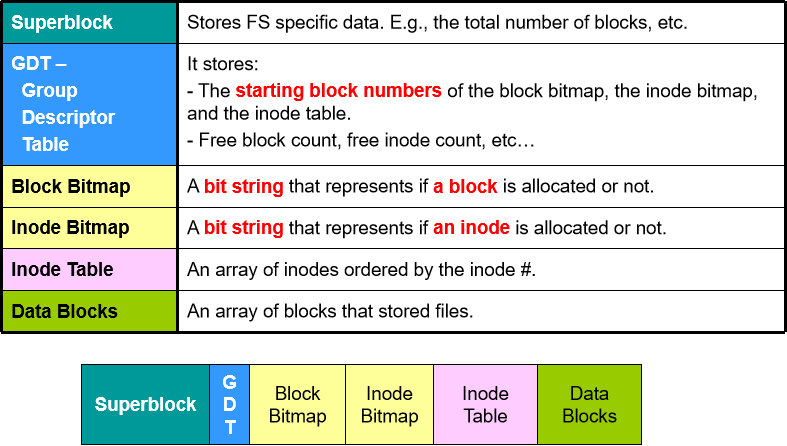
- 超级块(Superblock):用于存放文件系统特定信息。每个组内的超级块信息都是一样的,这是为了使得文件系统更加可靠。通常 Group 0 的超级块为首要超级块,Group 1 的超级块为备用超级块。
- 组描述符表(GDT):存放各块的初始化信息,例如 Bitmap、i-node Table 的数量,空余块的数量,空余 inode 数量等。Ext3 可能存在多个组(Group),每个组都有自己的 GDT。
- 块比特表(Block Bitmap):一串表示数据块是否已分配内存的字符串,0 表示该数据块没有被分配内存,1 表示该数据块已经被分配内存。如果 Ext3 的块大小为 4KB,总磁盘大小为 1GB,那么可以存放的总块数为 1 G B / 4 K B = 2 18 1GB/4KB=2^{18} 1GB/4KB=218,因此比特表的大小为 2 18 2^{18} 218 bits = 32KB。
- i-node 比特表(i-node Bitmap):与块比特表类似,也是一串表示 i-node 是否已被分配的字符串,0 表示没有,1 表示已经被分配。通过 i-node 比特表可以推断出文件的数量(参照操作系统笔记7)。
Ext3 文件链接(Link)
链接是指向文件的指针(Linux 中称为 i-node number)。Index Node(i-node)是一种文件控制结构,文件链接又分为硬链接和软链接。
- 硬链接(Hard Link):
- 是真实存在的物理数据的一个别名。每个硬链接的地位是等价的,可以删除任何多余的硬链接。硬链接是一种很好的备份文件的方式。
- 同一个物理数据可以拥有多个硬链接。
- 硬链接指向的数据必须存在于 FS 中。
- 所有被命名的文件都是硬链接。
- 硬链接不能指向路径。
- 硬链接的 i-node 是一样的,链接数量会显示所有的链接数,所有文件信息也是一样的。

- 软链接 (Symbolic Link)
- 软链接是一个指向文件的非直接指针,其本质是一个指向硬链接的指针。
- 同一个硬链接可以有多个软链接。
- 软链接指向的文件可以存在于另外的 FS 中。
- 软链接可以指向不存在的文件,这种情况下被称为 “broken link”。
- 软链接可以指向路径。
- 软链接的 i-node 不一样,对于新的软链接而言链接数量为 1,文件信息可能不一样。

Ext3 维持数据一致性(consistency)
创建一个新的文件,一般需要:
- 更新 i-node 信息。
- 更新空余数据比特表信息。
- 更新数据比特表信息。
- 向数据块写入用户数据。
每一个步骤都是原子操作(atom),如果在其中任何一个步骤中断(crash),都可能会造成数据不一致。一般地,解决一致性问题的方法有两种:
- 使用 File System Checker(fsck):
- 描述及作用:Linux 里叫 fsck,Windows 里叫 chkdsk。主要作用是在计算机启动时扫描整个文件系统,纠正不一致信息。必须进行完扫描后计算机才能正常启动,因此不用担心会有其他文件活动在此时进行。
- 过程:
- 超级块纠错,替换备用块。
- 扫描所有 i-node,重建比特表。
- 确认所有 i-node 都能被根节点访问。
- 删除所有已毁坏的 i-node,根据路径树重建链接表。
- 验证路径完整性。
- 其他细节确认。
- 优点:不需要文件系统做任何事情,实现起来更加容易。
- 缺点:实现 fsck 程序非常复杂,需要确认所有可能的不一致情况,以及一些比较难处理的边角细节;运行 fsck 会非常缓慢,因为要扫描整个文件系统。
- 使用 Journaling File System:
-
描述及作用:在把数据写入 FS 前,先通过交易日志(transactional log)来记录这一系列操作。这样就可以保证:如果在写日志的时候出错,只需要再次重写日志;如果日志写完未出错,在写入 FS 时出错,只需要根据日志将数据重新写入 FS 即可。Ext3 和 NTFS 都是用这一种方法。
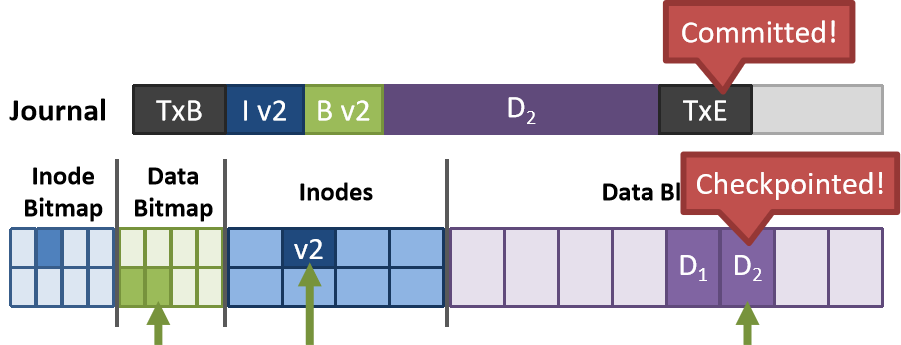
-
过程:
- TxB 表示日志开始,用特殊 ID 记录。
- 将所有操作过程记录到 meta-data block(很小,1 sector)中。
- 写入数据块(注意是写入 log 的 data block,不是 FS 的 data block)。
- 日志的所有交易结束(committed),以 TxE 结尾。
- 向 FS 写入数据。
- 更新检查点(checkpoint)。
- 结束检查点交易,释放空间。
-
时间线:
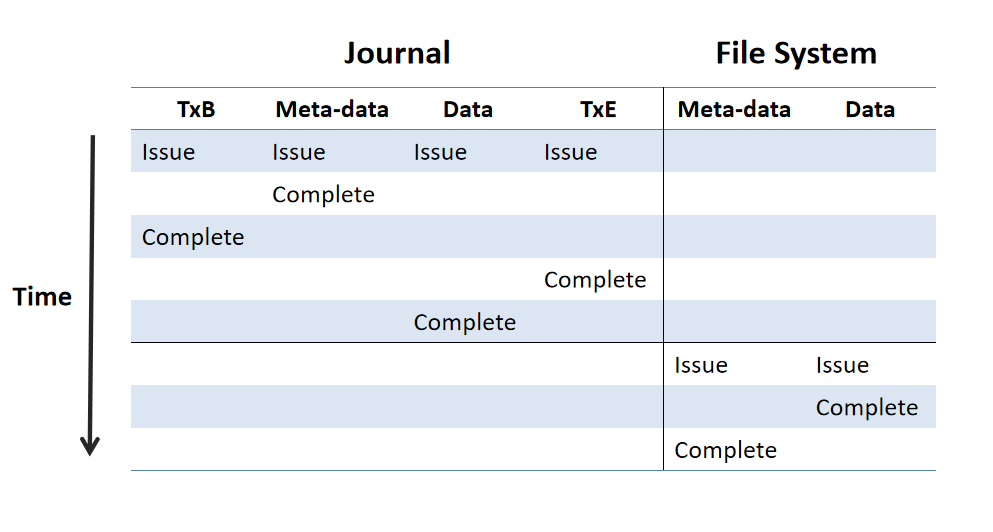
-
优点:
- journal 是附加式的,类似一个环形 buffer,可以周而复始地使用,因此不需要特意删除数据,只要覆盖就可以。
- 鲁棒性很强(robust)。
- 系统恢复快速(无需全部扫读磁盘)。
- 相比 fsck 实现更加直接,更加笼统。
-
缺点:
- 两倍写入花费,尤其对于文件数据很大的情况。
- 用完后删除 log 非常困难(所以一般不删除只覆盖)。
-
其他一些加速措施:
- 加入更多可写入的日志。
- 小文件直接写入 Memory,大文件写入 log。
- 权衡写入速度(Performance)和持续性(Persistence),例如加大批量时间间隔,让数量更少但是大小很大的数据一次性被写入 log。
-
可能的崩溃情形
日志写入时崩溃

真实数据未被修改,保持一致性。只需要从新写入一遍日志即可,日志中的 meta-data 会被覆盖。
检查点崩溃

此时日志已经写入完毕没有问题,但是在写入 FS 时崩溃,出现数据不一致。但是在重启的时候根据日志将数据重新写入 FS 即可解决这个问题。
删除和阻止再使用时崩溃
- 首先要明确三点:
- 创建路径和文件的时候,i-node 和 data 被重写。
- 删除路径的时候,只有 i-node 被移除。
- 重写 log 的时候,所有 meta-data 被覆盖,之后 FS 写入新的 log 的数据导致原数据丢失。
- 解决方法:
- 在完全删除并释放后(Checkpointed & Freed)再使用块。
- 在 log 中加入重调用记录。

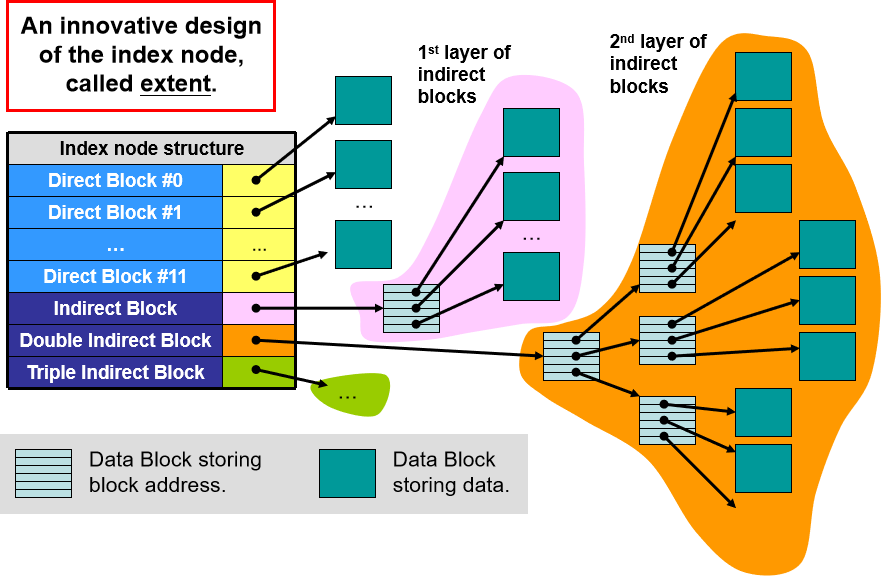
Ext4 扩展和 B-Tree
高效性问题:对于大文件来说,i-node 的遍历较为低效,可能存在层级之间的回溯,搜索时间复杂度 O(n),这个问题是不可避免的。
解决方案:
- 采用扩展(Extend):加入一个长度参数,显示该文件长度,如果搜索的并非该文件,就可以直接跳过这个长度的指针搜索下一个。扩展适用于连续性文件,ext4 (含 4 个扩展)和 NTFS 都使用扩展。

- 参照数据库里的 B-Tree:一般是三个节点的 B-Tree,所以一个节点可以包含 2 个 item,搜索时间复杂度 O(log N)。有时也会采用经过哈希函数变体的 H-Tree(B+Tree)。

Ex4 优缺点:
- 优点:支持所有基础文件系统功能,相比 Ext3 性能有所提升,增加扩展和 B-Tree。
- 缺点:Ext4 是一个渐进式提升,下一代的 FS 会比 Ext4 有更多功能。
基于 Log 框架的 FS(LFS)
- 概况:LFS 适用于 SSD,目前已经在 LFS 的基础上发展出 ZFS 和 btrfs。
- 核心:缓冲写入(包括 meta-data),长片段顺序写入磁盘,采用循环式缓冲,在 Superblock 中含有检查区域(Checkpoint Region),定期垃圾清理。
- 优势:写入量大且按顺序。
- 缺陷:不太好设计框架来管理 meta-data。
- 如何读取文件:
- 在检查区域查找包含 i-node1 的 i-node map(比如在 X 区)。
- 在 X 区读取完整的 i-node map(比如 i-node 1 在 Y 区)。
- 读取 i-node 1,找到该文件的数据。
















 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









