







术语
前驱元素 :若 A 元素在 B 元素的前面,则称 A 为 B 的前驱元素后继元素 :若 B 元素在 A 元素的后面,则称 B 为 A 的后继元素
顺序表 API设计:
1. 设计顺序表类:
1.1 以数组存储元素,使用顺序表时初始化顺序表长度,N表示实际存储全部元素长度(一旦N超过数组容量,抛异常)。
N的值会随着添加和删除操作改变,而数组(顺序表)实际长度不变
1.2 如果N>数组长度,就需要对数组容量可变:(自定义容量条件)
扩容条件:满数组
缩容条件:实际占用少于总容量的1/4
1.3 遍历顺序表
想让顺序表也能实现foreach相同的功能,需要做如下操作:
1.让顺序表类实现Iterable接口,重写iterator方法;
2. 在顺序表类内部提供一个内部类 SIterator, 实现 Iterator 接口,重写 hasNext 方法和 next 方法;

package cn.itcast.algorithm.linear;
import java.util.Iterator;
public class SequenceList<T> implements Iterable<T>{
//存储元素的数组
private T[] eles;
//记录当前顺序表中的元素个数
private int N;
//构造方法
public SequenceList(int capacity){
//初始化数组
this.eles=(T[])new Object[capacity];
//初始化长度
this.N=0;
}
//将一个线性表置为空表
public void clear(){
this.N=0;
}
//判断当前线性表是否为空表
public boolean isEmpty(){
return N==0;
}
//获取线性表的长度
public int length(){
return N;
}
//获取指定位置的元素
public T get(int i){
return eles[i];
}
//向线型表中添加元素t
public void insert(T t){
//扩容条件:满数组
if (N==eles.length){
resize(2*eles.length);
}
eles[N++]=t;
}
//在i元素处插入元素t
public void insert(int i,T t){
//扩容条件:满数组
if (N==eles.length){
resize(2*eles.length);
}
//先把i索引处的元素及其后面的元素依次向后移动一位
for(int index=N;index>i;index--){
eles[index]=eles[index-1];
}
//再把t元素放到i索引处即可
eles[i]=t;
//元素个数+1
N++;
}
//删除指定位置i处的元素,并返回该元素
public T remove(int i){
//记录索引i处的值
T current = eles[i];
//索引i后面元素依次向前移动一位即可
for(int index=i;index<N-1;index++){
eles[index]=eles[index+1];
}
//元素个数-1
N--;
//缩容条件:实际占用少于总容量的1/4
if (N<eles.length/4){
resize(eles.length/2);
}
return current;
}
//查找t元素第一次出现的位置
public int indexOf(T t){
for(int i=0;i<N;i++){
if (eles[i].equals(t)){
return i;
}
}
return -1;
}
//根据参数newSize,重置eles的大小
public void resize(int newSize){
//定义一个临时数组,指向原数组
T[] temp=eles;
//创建新数组
eles=(T[])new Object[newSize];
//把原数组的数据拷贝到新数组即可
for(int i=0;i<N;i++){
eles[i]=temp[i];
}
}
@Override
public Iterator<T> iterator() {
return new SIterator();
}
private class SIterator implements Iterator{
private int cusor;
public SIterator(){
this.cusor=0;
}
@Override
public boolean hasNext() {
return cusor<N;
}
@Override
public Object next() {
return eles[cusor++];
}
}
}
时间复杂度分析:
get(i): 不难看出,不论数据元素量 N 有多大,只需要一次 eles[i] 就可以获取到对应的元素,所以时间复杂度为 O(1);insert(int i,T t): 每一次插入,都需要把 i 位置后面的元素移动一次,随着元素数量 N 的增大,移动的元素也越多,时间复杂为 O(n);remove(int i): 每一次删除,都需要把 i 位置后面的元素移动一次,随着数据量 N 的增大 , 移动的元素也越多,时间复杂度为 O(n);由于顺序表的底层由数组实现,数组的长度是固定的,所以在操作的过程中涉及到了容器扩容操作。这样会导致顺序表在使用过程中的时间复杂度不是线性的,在某些需要扩容的结点处,耗时会突增,尤其是元素越多,这个问题越明显。后面链表的好处就显现了!
顺序表的体现——ArrayList:
java中ArrayList集合的底层也是一种顺序表,使用数组实现,同样提供了增删改查以及扩容等功能。
1.是否用数组实现?
就添加方法来看:
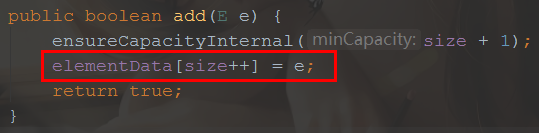

定义的数组:
![]()
2.有没有扩容操作?
就添加方法来看:
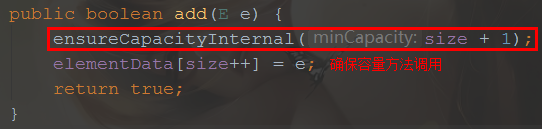



3.有没有提供遍历方式?
ArrayList类有对Iterable接口iterator方法的实现 ,几乎一样!

那么,问题来了!顺序表直接使用ArrayList不就好了吗,为什么还要自己写 ?
因为ArrayList是个庞大的类,具备这种方法,有很多父类和相关联的类,代码比较臃肿,公司在追求代码效率的时候,就体现了数据结构和算法的重要性!















 1234
1234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









