







在做分布式系统集成的时候,当一个功能涉及到多个平台的时候,通常面对的问题都是如果失败了怎么办?今天就给大家分享一个新思路-基于事件溯源实现分布式协调
我们的挑战
在进行正式开始之前我们需要先介绍下我们的场景是什么,要解决的问题是什么。
场景
在应用管理平台建设中需要整合内部的多个平台,比如容器、虚机、监控、发布、cmdb、负载等多个平台,每个平台都只负责某一部分功能,但是比如我们要做一个虚机扩容、灰度发布等通常就需要操作多个平台;如果是全部都是基于k8s的可能还好一点,但是对于一些公司这种平台建设早于容器平台,这时候就得由应用管理平台来进行协调了 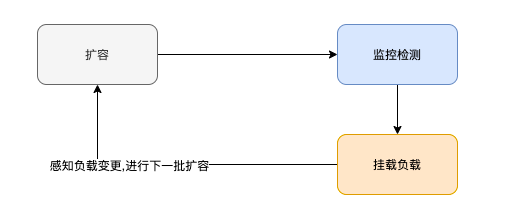
问题
在做一些业务开发时,比如订单支付通常会为了完成这个功能,多个服务会针对业务进行改造,比如使用tcc、saga等分布式事务模型来进行业务的一致性保障,其核心参考ACID的事务模型。而在应用平台建设中,首先对应的业务方不太会配合你进行改造,其次很多业务场景也不可能实现事务。比如你扩容创建了一台虚机,如果后续流程失败了,你总不能把机器给干掉吧?
思考
既然不能像业务一样通过传统的事务模型进行业务完整性保障,那我们何不换一种思路呢?于是基于稳定性的思考,笔者将设计思路转换成提高系统的容错能力,并尽可能的减小爆炸半径,同时尽可能的提升系统的可扩展性,保障高可用。
扩展
提到容错能力比较典型的场景就是数据处理场景了,这里先给大家介绍一下在分布式数据场景中是如何进行容错的。在分布式数据中,通常由source、process、sink三部分组成,而在很多场景中又要实现准确的exactly once,我们看看再flink里面是如何进行设计的, 这里先给大家介绍相关概念
checkpoint
checkpoint通常用于保存某些记录的位置信息用于方便系统故障后快速恢复,在flink中也利用了checkpoint机制来实现exactly once语义,其会按照配置周期性的计算状态生成检查点快照,然后将checkpoint持久化存储下来,这样后续如果崩溃则就可以通过checkpoint来进行恢复 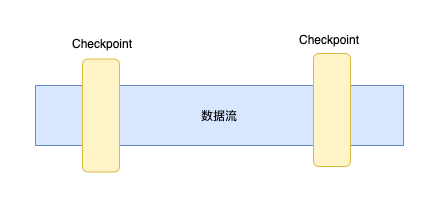
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









