







Scene-Adaptive Remote Sensing Image Super-Resolution Using a Multiscale Attention Network
论文地址
1、论文
摘要:
遥感图像超分辨率一直是主要的研究热点,近年来提出了许多基于深度学习的算法。
然而,由于遥感图像的结构往往比自然图像复杂得多,因此遥感图像的超分辨率仍然存在一些困难。
首先,难以用同一模型描绘不同场景的高分辨率(HR)和低分辨率(LR)图像之间的非线性映射
其次,遥感图像地物内部尺度范围大,单尺度卷积难以有效提取各种尺度的特征。
为了解决上述问题,我们提出了一种多尺度注意力网络(MSAN)来提取遥感图像的多级特征。 MSAN 的基本组件是多尺度激活特征融合块 (MAFB)。
此外,还采用了遥感图像的场景自适应超分辨率策略,以更准确地描述不同场景的结构特征。
在多个数据集上进行的实验证实,所提出的算法在评估指标和视觉结果方面均优于其他最先进的算法。
索引术语——通道注意力、深度学习、多尺度激活、遥感图像、场景自适应。
一、简介
单图像超分辨率(SISR)是一种低级计算机视觉问题,指的是从低分辨率(LR)图像[1]-[3]重建高分辨率(HR)图像以获得更有用的技术。详细信息。由于SISR在卫星成像、医学成像、监控、人脸识别等领域的广泛应用[4],多年来一直是数字图像处理领域的研究热点。SISR是一个天生不适定的问题,因为LR 图像中缺乏冗余信息 [5]-[7]。在过去的几十年中,已经开发了许多不同的框架来解决这个具有挑战性的问题。现有的 SISR 算法大致可以分为三类[8]:1)基于插值的方法; 2)基于重建的方法; 3)基于学习的方法。基于插值的方法,包括双线性插值、双三次插值 [9] 和 Lanczos 重采样 [10],计算效率高,但通常会导致过度平滑和高频信息丢失。基于重建的方法 [11]-[14] 通常利用来自 LR 和 HR 图像对的强大先验知识来限制重建的解空间。这些方法在恢复清晰细节方面具有优势,但是当放大倍数增加时,它们会遇到复杂的计算和性能下降的问题。为了缓解上述问题,从 Freeman 等人提出的马尔可夫随机场 (MRF) 模型开始,基于学习的方法在重建精度方面取得了很大的进步。 [15]。最近,逐渐引入了随机森林 [16] 和稀疏编码方法 [17]-[21]。
最近,由于深度神经网络的非线性表示和强大的特征提取能力,它们在 SISR 中取得了巨大的成功。现在已经提出了许多基于深度学习的算法来实现自然图像的超分辨率。这些方法 [22]-[24] 通常利用卷积神经网络 (CNN) 从大量训练数据中预测 LR 和 HR 块之间的非线性映射关系。因此,可以使用端到端的框架重建 LR 图像,并且这些方法总是优于以前传统的基于学习的方法。上述基于深度学习的方法可以在自然图像上取得出色的重建结果。
与自然影像相比,遥感影像的结构更为复杂。
首先,遥感图像通常具有更大的图像宽度,并且包含范围广泛的不同场景,例如建筑物、农田、森林和机场。一张完整的遥感影像可以由许多不同的场景组成,它们的纹理和结构信息差异很大,导致不同场景的HR和LR图像之间的映射关系不一致。
二是遥感影像中地物比例尺差异较大。例如,飞机、车辆等物体在遥感图像中只占几个像素,这与自然图像有很大不同。
因此,同一个超分辨率模型难以准确重建不同场景的图像,单尺度卷积不能很好地有效提取不同尺度的特征。
现在已经开发了许多基于深度学习的遥感图像超分辨率框架 [25]-[27]。
尽管这些方法可以取得令人满意的结果,但在某种程度上,它们往往忽略了遥感图像的结构信息[28],并且没有考虑不同场景下的潜在视觉信息量。因此,为了从海量遥感影像中提取更多有用的知识,需要开发一种更适用于遥感影像并且能够利用遥感影像中不同场景之间的结构信息的方法。
在本文中,我们提出一种新的框架,它使用来自不同类别场景的遥感图像训练深度神经网络,以获得适用于各种场景的遥感图像的不同超分辨率模型。还提出了多尺度注意网络 (MSAN) 来表征遥感图像在多个层次上的结构特征。
在本文中,我们首次提出了多尺度激活模块,然后在后面添加了通道注意力模块。我们工作的贡献可以总结为三个方面。
1) 多尺度激活特征融合块 (MAFB):我们开发了一种新的 MAFB 作为 MSAN 的基本组件。受[29]中广泛激活策略的启发,在本文中,我们首先提出了一个多尺度激活模块来扩展整流线性单元(ReLU)激活层之前的特征图的数量,并在每个MAFB中同时提取多级特征。融合各种尺度的特征图后,在后面加入通道注意力模块,进一步自适应地利用多个尺度特征之间的有效信息。
2)场景自适应策略:我们建立了一个自适应的超分辨率模型数据库通过迁移学习对遥感图像的不同场景;航空影像数据集(AID)30] 数据集中包含的 30 个不同场景的遥感影像总共训练了 30 个网络模型,该数据集通常用于航空场景分类任务。相应地,基于该模型数据库,经过场景匹配后,可以实现场景自适应的遥感图像重建。
3)通过对比实验,分析了遥感图像中不同场景的差异性。此外,在AID数据集和其他遥感影像数据集上得到的实验结果,包括吉林一号卫星影像和马萨诸塞州道路和建筑物检测数据集都证实了所提方法的性能令人满意。
本文的其余部分组织如下。
第二节介绍了现有的SISR方法。
拟议的MSAN的框架和模型的细节在第三节中描述。
第四节提供了利用AID数据集、吉林一号卫星图像和马萨诸塞州道路和建筑物探测数据集获得的模拟实验结果以及讨论。
最后,我们在第五节中提出这项工作的结论。
二 相关工作
本节简要概述了与我们的工作相关的基于深度学习的 SISR 算法,并介绍了一些现有的遥感图像超分辨率方法。基于深度学习的SISR 为了解决SISR问题,早期基于深度学习的框架通常使用插值技术,如双三次插值,将LR图像超分辨率到HR空间。
董等。 [22] 首先通过提出包含三层的浅层超分辨率 CNN (SRCNN) 将深度学习引入 SISR 领域。随后,受深度 Res-Net 网络 [31] 的启发,Kim 等人。 [23] 将残差学习的概念应用于超分辨率以加速网络的收敛,并提出了两个 20 层网络,称为非常深的超分辨率(VDSR)和深度递归卷积网络(DRCN)[24],这比 SRCNN 产生了更好的结果。赖等。 [32] 提出了深度拉普拉斯金字塔超分辨率网络(LapSRN)来从粗到细逐步预测残差图像。为了避免在输入网络之前对 LR 图像进行上采样操作,Shi 等人。 [33]提出了一种高效的亚像素卷积网络(ESPCN),通过在网络的尾部添加一个像素洗牌层,使得所有的计算都在LR空间中进行,从而减轻了网络的计算负担。后来,Lim 等人提出了一种增强的非常深和宽的网络,称为增强型深度超分辨率网络(EDSR)。 [34],结合残差学习和亚像素卷积的优点,取得了优异的性能。 EDSR 基于 SRResNet [35] 模型,通过移除批归一化层来优化原始残差块 (RB),以提高计算效率并简化网络,这已被证明是超分辨率任务的有效方法.余等。 [29] 改进了 EDSR 的 RB,并提出了 WDSR 模型,该模型通过在 ReLU 激活之前扩展特征来使用广泛激活的策略。张等。 [36] 提出了一个名为非常深的剩余通道注意网络(RCAN)的网络。他们率先将通道注意力机制引入图像超分辨率,这是一种更常用于高级计算机视觉问题的机制,包括图像分类和对象识别。渠道关注机制通过为不同通道的特征图设置不同的缩放因子来自适应地利用特征图中的有效信息。从那时起,已经提出了更多基于通道注意力的方法[37]-[39]。此外,为了充分利用提取的特征,Li 等人。 [40]首次将多尺度模块合并到残差结构中,实现了不同尺度的特征融合。
SISR for Remote Sensing Images 由于遥感图像超分辨率对于后续的物体识别[41]、分类[42]-[44]和检测任务[45]具有重要意义,因此一直是主要的研究重点。对于遥感图像,空间分辨率的提高始终依赖于数据融合方法[46],这是一种有效的方法,但缺乏同步 HR 观测存在瓶颈。为了解决这一局限性,遥感图像的 SISR 算法引起了越来越多的关注。早期的方法 [25]-[27] 通常用遥感图像重新训练为自然图像设计的网络,例如 SRCNN 和 VDSR。这些方法在遥感图像上的重建结果在一定程度上令人赏心悦目,但这些方法的效果不如应用于自然图像。随后,考虑到遥感图像的结构特征,Ma 等人。 [47] 使用单级二维离散小波变换 (WT) 将 LR 图像分解为四个子带,然后将四个子带馈送到递归 Res-Net 中以提取多分辨率特征。王等。 [48]利用 2-D-WT 通过四个 SRCNN 网络描述不同频率级别的特征图的特征,可以大大提高表示能力。此外,为了逐步提高遥感图像的分辨率,Jiang 等人。 [28] 提出了一个名为 PECNN 的网络,它由两个分别提取低级特征和结构信息的子网络组成。雷等。 [49] 通过利用深度学习对遥感图像的多级数据表示能力,提出了局部-全局联合网络(LGCNet)。
三、方法
在第一节介绍,由于遥感影像结构复杂,遥感影像超分辨率存在两大难点。
首先,对于遥感影像中场景目标的多样性,高频信息的联合分布格局差异较大,不同场景之间的高低映射关系趋于不一致,难以用同一模型重建不同场景的遥感图像。
其次,由于遥感影像中的目标往往具有较宽的尺度,因此应考虑影像的局部纹理信息和全局特征分布。
因此,与自然图像相比,学习多级特征和强制特征表达具有重要意义。
为了解决上述问题,基于WDSR架构,我们首先优化它通过提出一种新的多尺度激活特征融合 RB,称为 MAFB。
在每个 MAFB 中,我们将多尺度激活模块和通道注意模块组合在一起。然后,开发了一种用于遥感图像超分辨率的场景自适应框架。
在这一部分,详细描述了所提出的MSAN模型和场景自适应策略。
A. MSAN for Remote Sensing Image Super-Resolution
用于遥感图像超分辨率的 MSAN
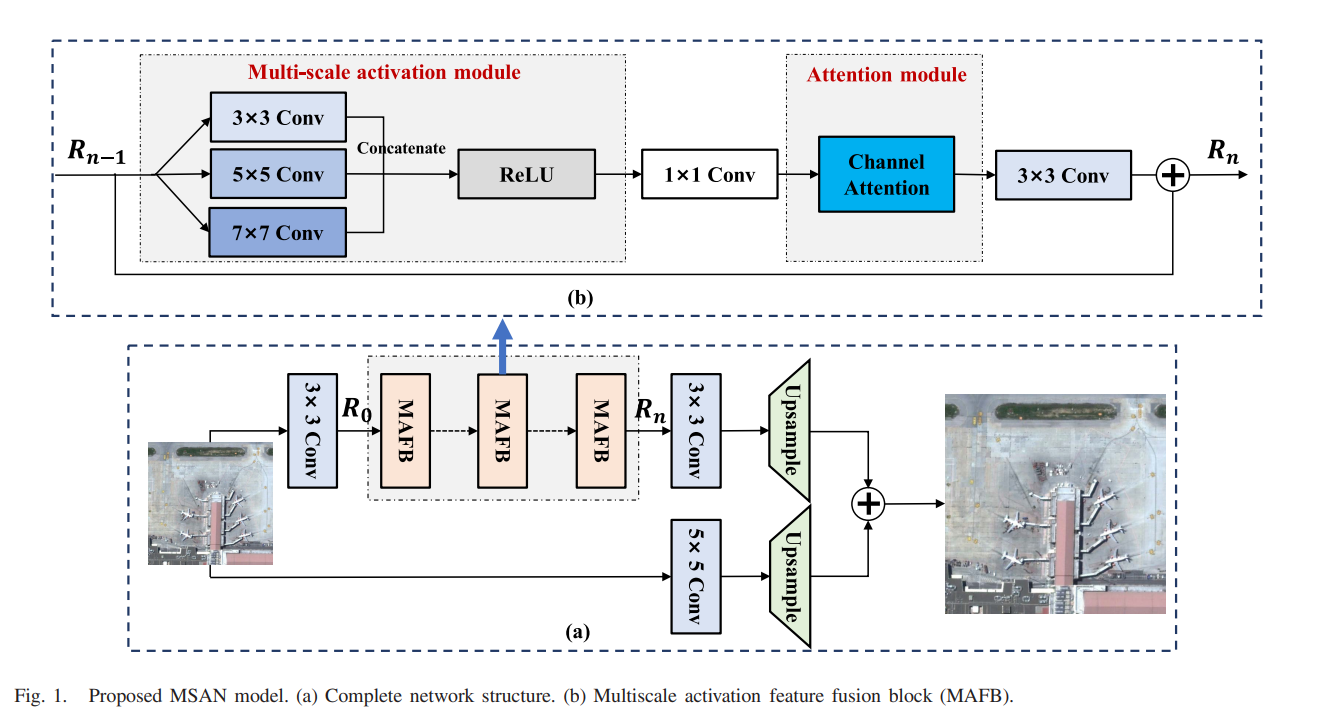
所提出的 MSAN 模型的体系结构如图 1 所示,包括完整的网络结构和新的 RB MAFB,分别如图 1(a)和(b)所示。
MSAN 的整体结构由两部分组成:
- 身份映射和 2) 残差体。
对于恒等映射分支,我们利用原来的 5×5 卷积层提取 LR 特征,并保留上采样层与 WDSR 的亚像素卷积。在本文中,我们的目标是从 LR 输入中恢复超分辨率遥感图像,如下所示: ISR = F(ILR) (1) 其中 F 是端到端网络学习到的映射,ILR ∈ RH ×W×c代表LR输入,ISR∈RsH×sW×c代表SR输出,s为比例因子。假设在残差分支中有N个MAFB,第一个和第i个(i ∈ [1, N))块的输入可以定义为R0 =ω3×3∗ILR+b0 (2) Ri = δi(Ri− 1) = δi(δi−1(…δ1(R0)…)) (3) 其中ω和b分别代表filter和bias,下标代表kernel size,δ代表各自的函数MAFB。 ω3×3的大小为c×3×3×n,其中c=3代表输入LR图像的RGB通道,n为输出特征图的个数。
B.多尺度激活特征融合块(MAFB)
MAFB是在多尺度激活模块、特征融合瓶颈层和通道注意模块的基础上开发的,如图1(b)所示。
1)多尺度激活模块:由于它WDSR 已经证明,在 ReLU 激活之前扩展特征图有助于网络的性能,因此,在本文中,我们首先提出多尺度激活模块。我们通过在每个 MAFB 中的 ReLU 激活之前添加一个多尺度卷积模块来将宽激活策略扩展到多尺度激活,以扩展各种尺度的特征图的数量并同时提取多个尺度的不同场景的类间多样性,如图所示在图 1(b)中。多尺度卷积滤波器的内核大小分别为 3×3、5×5 和 7×7。多尺度卷积模块能够在不同层次上描述输入 LR 图像的上下文和纹理信息,可以增强网络的表示能力。由于多尺度卷积操作具有不同大小的感受野,长期依赖
经过几个RB后才能处理。此外,通过三种核大小的组合,可以获得多级特征和更大的感受野,从而可以同时捕获遥感图像中不同场景的局部和全局分布的联合信息。我们的 MAFB 中的多尺度卷积模块可以表示为
C1 =ω3×3∗Rn−1+b1 (4)
C2 =ω5×5∗Rn−1+b2 (5)
C3 =ω7×7∗Rn−1+b3 (6)
我们将三个卷积的输出特征图连接在一起,然后应用 ReLU 函数
M = σ[concat(C1,C2,C3)] (7)
其中 σ(·) 表示非线性激活函数,M ∈ R H×W ×3n。
如果我们假设三个卷积操作中的每一个都输出 n 个特征图,那么在 ReLU 激活后我们可以获得 3×n 个特征图。随后,进行 1×1 卷积以融合之前提取的多尺度特征。此外,它仍然作为瓶颈层将通道数减少到 n
M’ = ω1×1 × M + b’ (8)
其中 M’ ∈RH×W×n.

2、Attention Module: The channel attention module in the RCAN
体系结构如图2所示。通道注意力机制首先由RCAN引入到超分辨率领域,并被证明具有自适应地利用不同通道之间有效信息的能力。就遥感图像而言,LR图像中的高频分量是有价值的,尤其是对于充满边缘、纹理和纹理的场景和其他详情。
为了加强特征表达并使网络关注更多信息特征,我们将图 2 所示的注意力模块添加到 RB 中,以在 1×1 卷积后重新缩放通道特征,其执行如下:
’ S= f(Wf2 ∗σ(Wf1 ∗Pave(M))) (9)
其中 Pave(M′) ∈ R1×1×n 表示全局平均池化操作,
W f 1 ∈ R1×1×(n/r )和W f 2 ∈ R1×1×n表示两个全连接层,f(·)表示sigmoid函数。
在重新校准操作之后,我们在 RB 的尾部使用 3×3 卷积进行空间特征提取。考虑到网络的参数预算和计算负担,特征图的数量 n 设置为 64。为了实验方便效率,我们使用八个 RB 作为建议的 MSAN 和两种比较方法(即 EDSR 和 WDSR)的基线。此外,权重归一化(WN)被用来提高训练的效率和准确性。还计算了真实图像和超分辨率图像之间的 l1 损失函数,以训练最终的 MSAN。
C.场景自适应框架描述
考虑到遥感图像中不同场景之间的巨大差异,很难训练出适用于所有不同场景的模型。因此,在这篇文章中,我们提出了一个场景自适应的超分辨率框架。所提出框架的流程图如图 3 所示。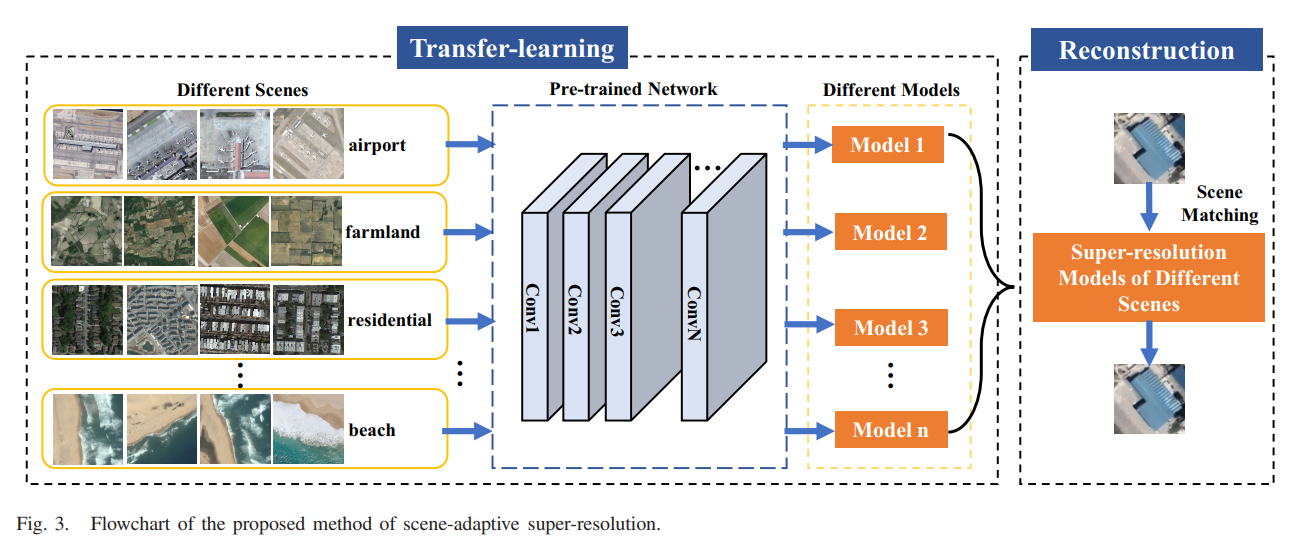
如图 3 所示,场景自适应超分辨率流程图可分为两部分:
1)迁移学习和 2)重建。
1)迁移学习:首先,我们用包含各种场景的遥感图像预训练一个基本网络来初始化参数。然而,由于不同场景之间纹理信息的显着差异以及遥感图像之间的尺度范围较大,初始化模型往往是不同场景训练数据之间博弈的折衷结果。因此,这种预训练模型不会对每个场景都获得最佳重建结果。为此,允许将初始化的参数传递到遥感对应场景的域中图像,我们使用不同场景的遥感图像对预训练的基础网络进行微调[50]。在获得预训练的基础网络后,使用不同场景的遥感图像对预训练网络进行微调以获得最终模型.因此,我们可以建立一个包含适应遥感图像不同场景的超分辨率模型的数据库。同时,我们可以利用不同场景的结构信息来探索 LR 和 HR 图像之间更准确的非线性映射,以改善重建结果。
2)重建:在重建部分,在获得所有针对不同场景微调的模型后,我们可以应用场景自适应超分辨率框架。首先,我们可以通过场景分类将遥感图像匹配到相应的类别。场景匹配后,将每幅遥感影像输入对应的在第一个过程中自适应获得的超分辨率模型,以获得最终的HR输出。
四、实验和讨论。
A. 数据集和实验设置
AID数据集是遥感影像场景分类任务中普遍采用的大规模基准数据集。该数据集包含30类不同场景类别,如图4所示。具体来说,这30类分别是机场、裸地、棒球场、海滩、桥梁、中心、教堂、商业、密集住宅、沙漠、农田、森林、工业、草地、中型住宅、山地、公园、停车场、游乐场、池塘、港口、火车站、度假村、河流、学校、稀疏住宅、广场、体育场、储罐和高架桥。样本图像的数量随着不同的航拍场景类型而变化很大,从 220 到 420 不等。AID 数据集包含 10000 多幅图像,分辨率范围从 8 到 0.5 m。每张航拍图的大小固定为600×600像素,可以覆盖各种尺度的场景。首先,我们从AID数据集中选取了900张图片,每类30张图片作为预训练数据集进行pretrain一个带有 ADAM 优化器的基本 MSAN,用于 300 个 epochs。另外,随机选取30张图片作为测试数据集,每类一张图片,我们设置β1=0.9,β2=0.999,ε=10−8。
所有 LR 图像都被裁剪为 48×48 作为输入,预训练时批量大小设置为 16。 WN 的初始学习率设置为 1 × 10−3,每 100 个 epoch 减半。得到预训练网络后,我们从不同场景的 30 个类别中随机抽取 150 张图像作为训练数据集,另外 10 张用于测试以微调预训练网络,学习率固定为 1 × 10−4在微调 30 个模型时。此外,从每个类别中选择另外 30 张图像进行验证。需要注意的是,所有训练都是在 RGB 通道上进行的。在预训练和微调期间,我们通过随机水平翻转图像并将它们旋转 90° 来扩充训练数据,然后从每个 LR 图像中减去相应训练数据集的平均 RGB 值。预训练和微调操作是在 PyTorch 框架下进行。所有 30 个模型都经过 15 个 epoch 的微调。预训练 MSAN 大约需要 12 小时,不同场景的每个模型使用 NVIDIA GTX2080 GPU 进行微调大约需要一个小时。最终,我们分别得到了基于MSAN的AID数据集中所有场景类别的30个模型。
B. Comparison With Other CNN-Based Methods
1、Experiments on RBs:为了比较不同模型深度下的重建精度,在AID数据集上对2×和4×SR进行了一组实验。为了公平起见,我们使用在相同预训练数据集上训练的不同数量的 RB 测试了建议的 MSAN 模型和基线 EDSR 和 WDSR。对来自 30 类场景的测试图像计算的平均量化评估结果如表 1 所示。可以看出,所提出的 MSAN 模型实现了最高的峰值信噪比(PSNR)和结构相似性(SSIM)
2、消融研究:此外,我们进行了一项消融实验,以测试所提出的 MFAB 中多尺度激活和通道注意模块的性能。消融研究是在包含八个 RB 的最终模型上进行的。表 II 中给出的结果证实,多尺度激活模块比通道注意力模型对改进的贡献更大。对于2×和4×SR的结果,多尺度激活模块可以分别将网络性能提高0.182和0.176 dB,而通道注意力模块可以提高0.072和0.062 dB。显然,同时具有多尺度激活和通道注意力模块的模型可以获得最佳性能。
3、重建结果比较:同时,我们通过所有类别的场景评估预训练 MSAN 模型在测试图像上的性能并比较结果与那些双三次、VDSR、EDSR 和 WDSR 方法。为了公平和令人信服的比较,我们使用与预训练 MSAN 相同的训练数据集对这些网络进行再训练,以获得它们的最佳效果表现。表 III 列出了这些方法下所有 30 类场景的测试图像的最终平均 PSNR 和 SSIM 值。所提出的 MSAN 模型在所有 30 类场景中都实现了最高的 PSNR 和 SSIM 值。此外,使用 MSAN 的 30 个场景的平均 PSNR 分别比 EDSR 和 WDSR 方法高 0.152 和 0.113 dB。然而,如表 III 所示,预训练 MSAN 模型在重建结果中的改进程度在不同场景之间差异很大。例如,对于停车场和广场等场景,与WDSR的结果相比,PSNR值分别增加了0.315和0.202 dB,而对于沙漠和河流等其他场景,PSNR值仅略有增加。这鼓励我们在下文中进一步探索场景差异对重建结果的影响。图 5 显示了不同方法的一些视觉结果。很明显,MSAN 重建的图像比其他方法的重建图像要好得多。通过比较放大的部分,MSAN 在保留纹理信息和边缘方面表现出更好的 SR 性能。例如,在图 5 中,使用 MSAN 后,飞机的机翼和尾翼等轮廓得到了明显增强。此外,在图5所示的停车场景图像中,对比方法得到的重建红色汽车存在一定程度的模糊和变形,而MSAN得到的汽车是
4)训练和运行时比较:为了进一步比较EDSR、WDSR和MSAN时的收敛性和准确性,图中绘制了三个网络的损耗和PSNR值曲线。6,分别。此外,表四亦记录了三种型号的平均运行时间,以比较工作效率。参考表IV,可以看出MSAN超分辨100张LR图像所花费的时间几乎接近其他两种算法,但MSAN在训练时具有更快的收敛性和更好的精度,如图所示。6.
C. 场景自适应超分辨率策略的结果
…因此,受益于 MAFB 和场景自适应策略,很明显 SAMSAN 可以对遥感图像中各种尺度的物体(无论是大型建筑物还是小型车辆)获得相对较好的重建结果。然而,SRGAN 往往只适用于大型物体。
五、结论
在本文中,提出了一种名为 MSAN 的多尺度通道注意网络用于遥感图像超分辨率。为了表征遥感图像中的多级特征并增强特征表达能力,我们通过在 RB 中结合多尺度激活模块和通道注意模块来开发 MAFB。所提出的 MSAN 模型优于 EDSR 和 WDSR 的最先进的 SR 算法。
此外,为了进一步利用不同场景类别之间的基础信息并表征遥感图像中不同场景之间的特征差异,我们提出了场景自适应超分辨率框架。为此,我们通过迁移学习为不同场景的图像训练了不同的模型,并将它们应用于多个遥感数据集,以验证所提出框架的有效性。使用AID数据集、吉林一号卫星影像和马萨诸塞州道路和建筑物检测数据集获得的实验结果证实了场景自适应策略的有效性。虽然所提出的算法比 EDSR 和 WDSR 取得了更好的结果,但重建结果仍然丢失了一些细节,并且它们依赖于准确的图像分类,这可能不够好。下一阶段,我们计划将深度神经网络与不同场景之间可用的先验信息相结合,充分利用遥感图像的结构信息,进一步提高超分辨率结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









