







一、数据结构
1. 前缀和
对于数组 nums,定义前缀和 s[0] = 0,s[i+1]=sum(nums[j]), 0 < j <= i。
根据这个定义,有 s[i+1] = s[i] + nums[i]。
例如 nums =[1,2,1,2],对应的前缀和数组为 s =[0,1,3,4,6]。通过前缀和,我们可以把子数组的元素和转换成两个前缀和的差,即:
sum(nums[j])(left < j <= right) = s[right+1] - s[left]
例如
nums的子数组[2,1,2]的和就可以用s[4]-s[1] = 6-1 = 5算出来
注1:为方便计算,常用左闭右开区间 [left,right) 来表示从 nums[left] 到nums[right - 1] 的子数组,此时子数组的和为 s[right] - s[left],子数组的长度为 right - left。
注 2: s[0] = 0 表示一个空数组的元素和。为什么要额外定义它? 想一想,如果要计算的子数组恰好是一个前缀 (从 nums[0] 开始),你要用 s[right] 减去谁呢? 通过定义 s[0]= 0,任意子数组 (包括前缀)都可以表示为两个前缀和的差。
前后缀分解练习题:
难度简单12
给你一个正整数 n ,找出满足下述条件的 中枢整数 x :
1和x之间的所有元素之和等于x和n之间所有元素之和。
返回中枢整数 x 。如果不存在中枢整数,则返回 -1 。题目保证对于给定的输入,至多存在一个中枢整数。
示例 1:
输入:n = 8
输出:6
解释:6 是中枢整数,因为 1 + 2 + 3 + 4 + 5 + 6 = 6 + 7 + 8 = 21 。
示例 2:
输入:n = 1
输出:1
解释:1 是中枢整数,因为 1 = 1 。
示例 3:
输入:n = 4
输出:-1
解释:可以证明不存在满足题目要求的整数。
提示:
1 <= n <= 1000
class Solution {
public int pivotInteger(int n) {
int[] pre = new int[n+1];
int[] suf = new int[n+1];
for(int i = 0; i < n; i++)
pre[i+1] = pre[i] + (i+1);
for(int i = n-1; i > 0; i--)
suf[i-1] = suf[i] + (i+1);
for(int i = 0; i <= n; i++){
if(pre[i] == suf[i]) return i+1;
}
return -1;
}
}
给你一个大小为 n 下标从 0 开始的整数数组 nums 和一个正整数 k 。
对于 k <= i < n - k 之间的一个下标 i ,如果它满足以下条件,我们就称它为一个 好 下标:
- 下标
i之前 的k个元素是 非递增的 。 - 下标
i之后 的k个元素是 非递减的 。
按 升序 返回所有好下标。
class Solution {
public List<Integer> goodIndices(int[] nums, int k) {
int n = nums.length;
int[] suf = new int[n+1]; // suf[i]记录i位置后缀有多少非递减的
int[] pre = new int[n+1]; // pre[i]记录i位置前缀有多少非递增的
pre[0] = 1;
for(int i = 1; i < n; i++)
pre[i] = nums[i] <= nums[i-1] ? pre[i-1] + 1 : 1;
suf[n-1] = 1;
for(int i = n-2; i >= 0; i--)
suf[i] = nums[i] <= nums[i+1] ? suf[i+1] + 1 : 1;
List<Integer> res = new ArrayList<>();
for(int i = k; i < n-k; i++){
// 枚举i位置,注意不包括i
if(pre[i-1] >= k && suf[i+1] >= k) res.add(i);
}
return res;
}
}
2. 差分数组
前缀和主要适用的场景是原始数组不会被修改的情况下,频繁查询某个区间的累加和
差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减
差分数组使用场景:对于一个数组
nums[]要求一:对
num[2...4]全部+ 1要求二:对
num[1...3]全部- 3要求三:对
num[0...4]全部+ 9
差分算法是前缀和算法的逆运算,可以快速的对数组的某一区间进行计算操作。
例如,有一数列 a[1],a[2],.…a[n],且令 b[i] = a[i]-a[i-1],b[1]=a[1],
那么就有a[i] = b[1]+b[2]+.…+b[i] = a[1]+a[2]-a[1]+a[3]-a[2]+.…+a[i]-a[i-1],
此时b数组称作a数组的差分数组,换句话来说a数组就是b数组的前缀和数组
例:
原始数组a:9 3 6 2 6 8
差分数组b:9 -6 3 -4 4 2可以看到a数组是b数组的前缀和数组。
那么现在有一个任务:对数组a区间[left,right]每个元素加一个常数c。这时可以利用原数组就是差分数组的前缀和这个特性,来解决这个问题。对于b数组,只需要执行b[left] += c, b[right+1] −= c
如何得到更新后的数组元素值? 只需要累加即可。第i位值:sum :sum += b[i]
差分数组练习题:
3. 二维前缀和、二维差分
1、二维前缀和
作者:AC_OIer
链接:https://leetcode.cn/problems/range-sum-query-2d-immutable/solution/xia-ci-ru-he-zai-30-miao-nei-zuo-chu-lai-ptlo/
「二维前缀和」解决的是二维矩阵中的矩形区域求和问题。
① 初始化前缀和数组 sum
-
前缀和数组下标从 1 开始,因此设定矩阵大小为
s[n + 1][m + 1] -
s[i+1][j+1] = matrix[i][j] + s[i+1][j] + s[i][j+1] - s[i][j];
二维前缀和数组中的每一个格子记录的是「以当前位置为区域的右下角(开区间),左上角恒定为原数组的左上角 的区域和」
f[i][j]理解成是以(i-1, j-1)为右下角,(0, 0)为左上角的区域和。
② 求 (x1, y1) 作为左上角,(x2, y2) 作为右下角的区域和。
- 当我们要求
(x1, y1)作为左上角,(x2, y2)作为右下角 的区域和的时候,可以直接利用前缀和数组快速求解:s[x2+1][y2+1] - s[x1][y2+1] - s[x2+1][y1] + s[x1][y1];
难度中等490
给定一个二维矩阵 matrix,以下类型的多个请求:
- 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为
(row1, col1),右下角 为(row2, col2)。
实现 NumMatrix 类:
NumMatrix(int[][] matrix)给定整数矩阵matrix进行初始化int sumRegion(int row1, int col1, int row2, int col2)返回 左上角(row1, col1)、右下角(row2, col2)所描述的子矩阵的元素 总和 。
做这种初始化一次、检索多次的题目的秘诀:在初始化的时候做预处理。
class NumMatrix {
int[][] s; // 二维前缀和sum
public NumMatrix(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
// 与「一维前缀和」一样,前缀和数组下标从 1 开始,因此设定矩阵形状为 [n + 1][m + 1](模板部分)
s = new int[m+1][n+1];
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
s[i+1][j+1] = matrix[i][j] + s[i+1][j] + s[i][j+1] - s[i][j];
}
}
}
// 前缀和是从 1 开始,原数组是从 0 开始,上来先将原数组坐标全部 +1,转换为前缀和坐标
public int sumRegion(int x1, int y1, int x2, int y2) {
// 求某一段区域和 [i, j] 的模板是 sum[x2][y2] - sum[x1 - 1][y2] - sum[x2][y1 - 1] + sum[x1 - 1][y1 - 1];(模板部分)
// 但由于我们源数组下标从 0 开始,因此要在模板的基础上进行 + 1
return s[x2+1][y2+1] - s[x1][y2+1] - s[x2+1][y1] + s[x1][y1];
}
}
二维前缀和的模板部分:
// 预处理前缀和数组
{
sum = new int[n + 1][m + 1];
// 当前格子(和) = 上方的格子(和) + 左边的格子(和)
// - 左上角的格子(和) + 当前格子(值)【和是指对应的前缀和,值是指原数组中的值】
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
sum[i+1][j+1] = sum[i][j+1] + sum[i+1][j] - sum[i][j] + matrix[i][j];
}
}
}
// 首先我们要令左上角为 (x1, y1) 右下角为 (x2, y2)
// 计算 (x1, y1, x2, y2) 的结果
{
// 前缀和是从 1 开始,原数组是从 0 开始,上来先将原数组坐标全部 +1,转换为前缀和坐标
x1++; y1++; x2++; y2++;
// 记作 22 - 12 - 21 + 11,然后 不减,减第一位,减第二位,减两位
// 也可以记作 22 - 12(x - 1) - 21(y - 1) + 11(x y 都 - 1)
ans = sum[x2][y2] - sum[x1 - 1][y2] - sum[x2][y1 - 1] + sum[x1 - 1][y1 - 1];
}
2、二维差分
https://tom0727.gitee.io/post/068-%E4%BA%8C%E7%BB%B4%E5%B7%AE%E5%88%86/
一维差分可以用于解决以下问题:
- 给定一系列的区间加/减操作,最后询问整个数组的元素。
那么二维差分就可以解决:
- 给定一系列的矩阵加/减操作,最后询问整个矩阵中的元素。
二维前缀和的计算方式是:sum[x2][y2] - sum[x1 - 1][y2] - sum[x2][y1 - 1] + sum[x1 - 1][y1 - 1]
所以我们思考,对于差分数组 d[x][y],如果我们要给一个矩阵[x1,y1][x2,y2]全部加
1
1
1,即左上角为
(
x
1
,
y
1
)
(x_1,y_1)
(x1,y1),右下角为
(
x
2
,
y
2
)
(x_2,y_2)
(x2,y2) 的矩阵全部加
1
1
1,应该怎么处理?
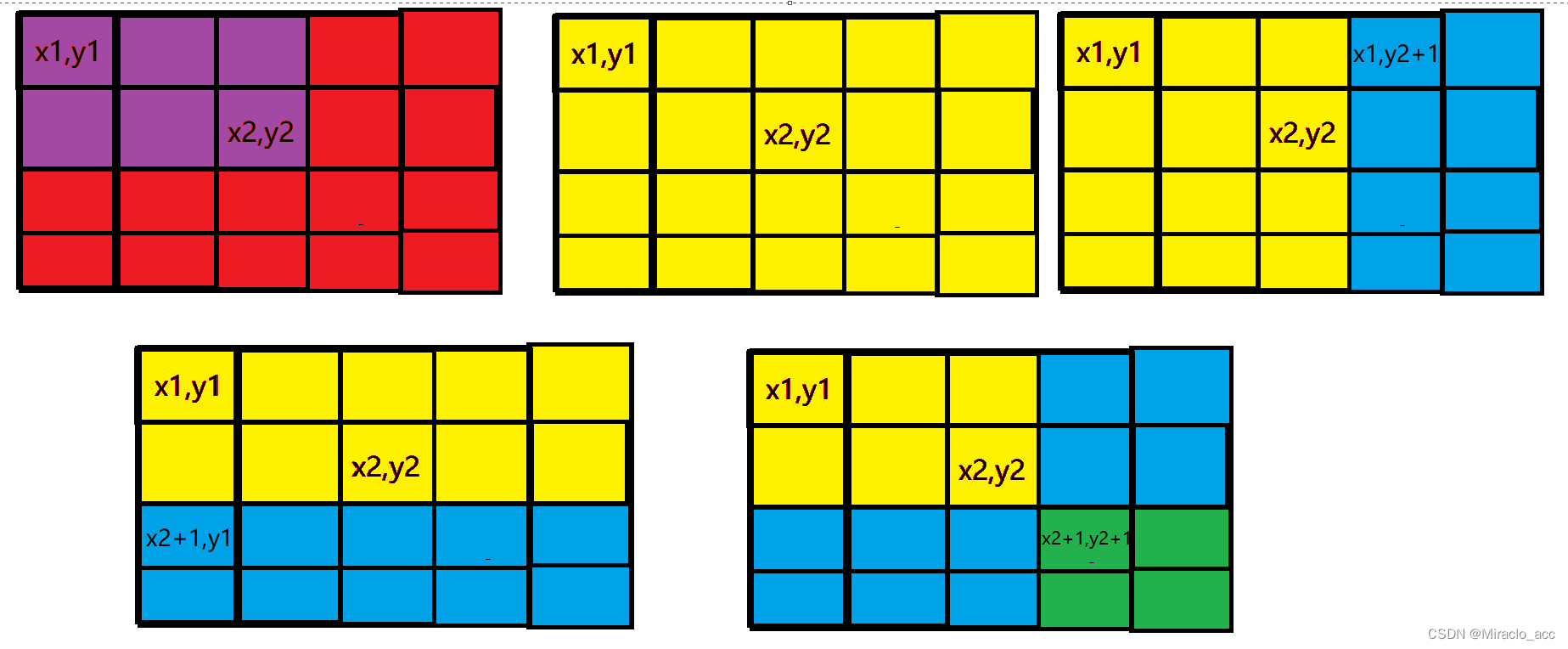
注意到如果我们进行二维前缀和的方法的话,修改一个差分数组 d [ x ] [ y ] d[x][y] d[x][y] 影响到的是 ( x , y ) (x,y) (x,y) 右下方的所有元素的值。
我们想要的是 紫色部分 全部加 1 1 1。
那么如果我们让 d [ x 1 ] [ y 1 ] d[x_1][y_1] d[x1][y1] 加 1 1 1,那么影响到的是所有的 紫色加红色 部分。
于是,我们可以通过让 d [ x 1 ] [ y 2 + 1 ] d[x_1][y_2+1] d[x1][y2+1] 和 d [ x 2 + 1 ] [ y 1 ] d[x_2+1][y_1] d[x2+1][y1] 全部减去 1 1 1 来消除红色部分。
然而 绿色部分 被减去了两次,所以我们再给 d [ x 2 + 1 ] [ y 2 + 1 ] d[x_2+1][y_2+1] d[x2+1][y2+1] 加上 1 1 1。
在所有的操作结束后,使用 二维前缀和 的方式来获得矩阵值即可。(注意要直接在diff上复原)
diff[i][j] += diff[i][j - 1] + diff[i - 1][j] - diff[i - 1][j - 1]
# 注:下面求二维差分方式在diff数组中位置都+1(偏移量),这样做是为了方便后面恢复
# 1. 二维差分:快速地把一个矩形范围内的数都 +1
diff = [[0] * (m+2) for _ in range(n+2)]
for i, j, side in forceField:
# 下面输入四个顶点
r1 = bisect_left(xs, 2*i-side) # 离散化后的左横坐标
r2 = bisect_left(xs, 2*i+side) # 离散化后的右横坐标
c1 = bisect_left(ys, 2*j-side) # 离散化后的下纵坐标
c2 = bisect_left(ys, 2*j+side) # 离散化后的上纵坐标
# 将区域 r1<=r<=r2 && c1<=c<=c2 上的数都加上 x
# 多 +1 是为了方便求后面用二维前缀和复原,不加1的话需要在后面复原时i,j+1(同二维数组方式)
diff[r1 + 1][c1 + 1] += 1
diff[r1 + 1][c2 + 2] -= 1
diff[r2 + 2][c1 + 1] -= 1
diff[r2 + 2][c2 + 2] += 1
# 2. 直接在 diff 上复原(二维前缀和),计算最大值
ans = 0
for i in range(1, n+1):
for j in range(1, m+1):
diff[i][j] += diff[i][j - 1] + diff[i - 1][j] - diff[i - 1][j - 1]
ans = max(ans, diff[i][j])
return ans
困难
给你一个 m x n 的二进制矩阵 grid ,每个格子要么为 0 (空)要么为 1 (被占据)。
给你邮票的尺寸为 stampHeight x stampWidth 。我们想将邮票贴进二进制矩阵中,且满足以下 限制 和 要求 :
- 覆盖所有 空 格子。
- 不覆盖任何 被占据 的格子。
- 我们可以放入任意数目的邮票。
- 邮票可以相互有 重叠 部分。
- 邮票不允许 旋转 。
- 邮票必须完全在矩阵 内 。
如果在满足上述要求的前提下,可以放入邮票,请返回 true ,否则返回 false 。
示例 1:

输入:grid = [[1,0,0,0],[1,0,0,0],[1,0,0,0],[1,0,0,0],[1,0,0,0]], stampHeight = 4, stampWidth = 3
输出:true
解释:我们放入两个有重叠部分的邮票(图中标号为 1 和 2),它们能覆盖所有与空格子。
示例 2:
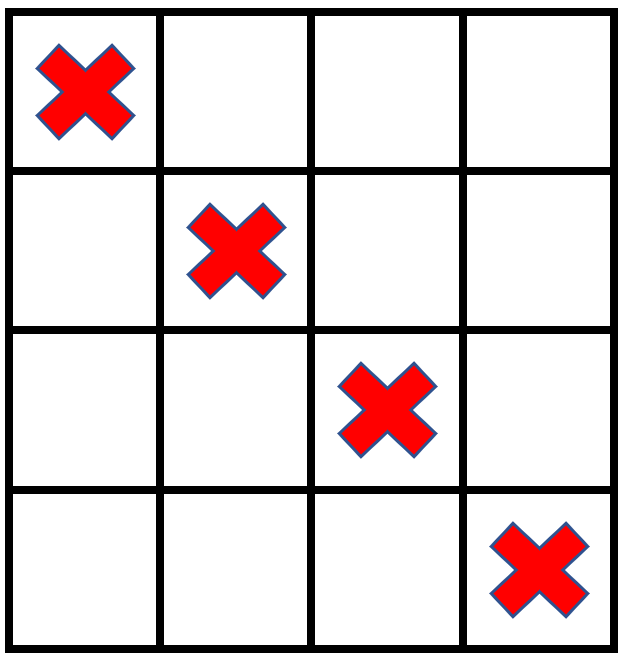
输入:grid = [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]], stampHeight = 2, stampWidth = 2
输出:false
解释:没办法放入邮票覆盖所有的空格子,且邮票不超出网格图以外。
提示:
m == grid.lengthn == grid[r].length1 <= m, n <= 1051 <= m * n <= 2 * 105grid[r][c]要么是0,要么是1。1 <= stampHeight, stampWidth <= 105
二维差分
https://leetcode.cn/problems/stamping-the-grid/solutions/1199642/wu-nao-zuo-fa-er-wei-qian-zhui-he-er-wei-zwiu/?envType=daily-question&envId=2023-12-14
由于邮票可以相互重叠,因此贪心地想,能放邮票就放邮票
遍历所有能放邮票的位置去放邮票,
同时记录每个空格子有多少张邮票被覆盖,如果存在一个空格子没被邮票覆盖,则return false
细节:
1.怎么快速判断一个矩形区域能放邮票?「怎么O(1)得求出任意矩形区域的元素和」
利用二维前缀和,如果一个矩形区域元素和=0,那么该矩形区域所有格子都是0
2.假设用一个二维计数矩阵 cnt 记录每个空格子被多少张邮票覆盖,
那么放邮票时,就需要把 cnt 的一个矩形区域都加一。怎么快速实现?
可以用二维差分矩阵 d 来代替 cnt。矩形区域都加一的操作转变成 O(1)地对 d 中四个位置的更新操作。
3.最后从二维差分矩阵 d 还原出二维计数阵 cnt。类似对一维差分数组求前缀和得到原数组,
我们需要对二维差分矩阵求二维前缀和。
遍历 cnt,如果存在一个空格子的计数值为 0,就表明该空格子没有被邮票覆盖,返回 false,否则返回 true。
代码实现时,可以直接在 d 数组上原地计算出 cnt
class Solution {
public boolean possibleToStamp(int[][] grid, int stampHeight, int stampWidth) {
int m = grid.length, n = grid[0].length;
// 1. 计算 grid 的二维前缀和
int[][] s = new int[m+1][n+1];
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
s[i+1][j+1] = s[i+1][j] + s[i][j+1] - s[i][j] + grid[i][j];
}
}
// 2. 计算二维差分
// 为方便第 3 步的计算,在 d 数组的最上面和最左边各加了一行(列),所以下标要 +1
int[][] d = new int[m+2][n+2];
for(int i2 = stampHeight; i2 <= m; i2++){
for(int j2 = stampWidth; j2 <= n; j2++){
int i1 = i2 - stampHeight + 1;
int j1 = j2 - stampWidth + 1;
if(s[i2][j2] - s[i2][j1 - 1] - s[i1 - 1][j2] + s[i1 - 1][j1 - 1] == 0){
d[i1][j1]++;
d[i1][j2 + 1]--;
d[i2 + 1][j1]--;
d[i2 + 1][j2 + 1]++;
}
}
}
// 3. 还原二维差分矩阵对应的计数矩阵(原地计算)
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
d[i+1][j+1] += d[i+1][j] + d[i][j+1] - d[i][j];
if(grid[i][j] == 0 && d[i+1][j+1] == 0)
return false;
}
}
return true;
}
}
难度中等5
4. 并查集
并查集结构简单,但要灵活应用并查集解决问题却不简单
简单来说,并查集是一种以树形结构来表示不同种类数据的集合。一般当我们需要用到数据的连通性时会用到它。
并查集维护一个数组parent,parent数组中维护的不是元素本身,而是元素的下标索引,当然,这个下标索引是指向该元素的父元素的。
并查集的应用场景:
并查集的主要作用不是“存储数据”,而是“快速查询数据的状态或者关系”。
具体来讲,并查集的作用是,快速响应对元素所处的集合进行合并操作,以及快速查询两个元素是否属于同一个集合。(如判断节点联通性问题)
并查集模板:
①parent数组版本
路径压缩:主要针对find函数,当在寻找一个节点A的根节点root时,直接将节点A的父节点B、祖父节点C…等节点全部指向根节点root。
优点:这样在下次寻找A的根节点、B的根节点、C的根节点时可以节省很长一段搜索路径。
private class UnionFind {
//par数组用来存储根节点,par[x]=y表示x的根节点为y
private int[] parent;
public UnionFind(int n) {
parent = new int[n];
//初始化, 每个节点都是一个联通分量
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
//查找x所在集合的根(带路径压缩)
private int find(int x) {
if (x != parent[x]) {
//递归返回的同时压缩路径
parent[x] = find(parent[x]);
}
return parent[x];
}
//合并x与y所在集合
public void union(int x, int y) {
int xRoot = find(x);
int yRoot = find(y);
if (xRoot != yRoot) { //不是同一个根,即不在同一个集合,就合并
parent[xRoot] = yRoot;
}
}
}
②HashMap版本
https://blog.csdn.net/weixin_45545090/article/details/124343565
“并”表示合并,“查”表示查找,“集”表示集合。其基本思想是用 father[i] 表示元素 i 的父节点。例如 father[1] = 2 表示元素 1 的父节点是 2。如果 father[i] = i,那么说明 i 是根节点,根节点作为一个集合的标识。当然,如果不使用数组来记录,而使用 map 来记录,那么可以使用 father.get(i) = null 来表示根节点。
class UnionFind {
// 用 Map 在存储并查集,表达的含义是 key 的父节点是 value
private Map<Integer,Integer> father;
// 0.构造函数初始化,初始时各自为一个集合,用null来表示
public UnionFind(int n) {
father = new HashMap<Integer,Integer>();
for (int i = 0; i < n; i++) {
father.put(i, null);//或者father.put(i,i);
}
}
// 1.添加:初始加入时,每个元素都是一个独立的集合,因此
public void add(int x) { // 根节点的父节点为null
if (!father.containsKey(x)) {
father.put(x, null);//或者father.put(x,x); 根节点的父节点为自己
}
}
// 2.查找:反复查找父亲节点。
public int find(int x) {
int root = x; // 寻找x祖先节点保存到root中
while(father.get(root) != null){//或者father.get(root) != root
root = father.get(root);
}
while(x != root){ // 路径压缩,把x到root上所有节点都挂到root下面
int original_father = father.get(x); // 保存原来的父节点
father.put(x,root); // 当前节点挂到根节点下面
x = original_father; // x赋值为原来的父节点继续执行刚刚的操作
}
return root;
}
// 3.合并:把两个集合合并为一个,只需要把其中一个集合的根节点挂到另一个集合的根节点下方
//也可以记录两个集合的大小,根据大小将小集合父节点挂载到大集合父节点上
public void union(int x, int y) { // x的集合和y的集合合并
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY){ // 节点联通只需要一个共同祖先,无所谓谁是根节点
father.put(rootX,rootY);
}
}
// 4.判断:判断两个元素是否同属一个集合
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
}
【并查集的三个常用数组】https://www.acwing.com/blog/content/7106/
并查集中有三个常用的数组,分别是:fa[N]、sz[N]、d[N]
f[i]代表了节点i的祖宗节点、是所有并查集必备的核心数组(一定要记得初始化)sz[i]代表了节点i所在的并查集块中所有的元素数量(该并查集的大小)、常用于求并查集(连通块)的大小d[i]代表了节点i与其祖宗节点直接的距离(权值)、常用于带权并查集之间
一般并查集的简单题目都是基于这三种数组进行操作的,简单并查集的分类例题:
- 普通并查集:一般只会用到一个
fa[N]数组。一般支持的的操作也很简单:合并两个集合、判断两个元素是否在一个集合当中 - 需要询问并查集(连通块)的大小:需要询问并查集(连通块)的大小时,就需要用到
sz[N]数组了。这种问题一般都是又增加一个询问:求出该并查集(连通块)的大小(其中元素的个数) - 带权并查集(当然,一般也可用扩展域并查集)带权并查集:一般用带权并查集来维护边权两边的两个点之间的相对关系(两个点即:一个点与其根节点之间的关系)。 因为
d[i]数组主要维护的是一个点与其根节点之间的距离 (用不同的距离取模,来表示关系(一般%的值的大小就表示关系的种类的多少))通过知道每个点与根节点之间的关系,就可以(通过加减)知道集合之间任意两点的相对关系了(信息具有相互性、传递性;类似于无向边)
5. 树状数组
IndexTree所能解决的典型问题就是存在一个长度为n的数组, 如何高效的某一个范围内的前缀和 ,智能的解决 【单点更新】完怎么维护一个结构【快速查询累加和】的问题。
其基本操作主要有:
- int query(int index):求1到index位置的累加和
- void add(int index, int d): 将index位置的数加一个d(单点更新)
- int RangeSum(int index1, int index2): 求index1到index2上面的累加和
BIT可以解决的问题有:
- 单点修改,区间查询。
- 如果维护数组的差分,那么就可以完成:区间修改,单点查询。
- 如果两个树状数组相互维护,可以做到:区间修改,区间查询。
BIT可以解决的问题,Index Tree都可以解决;Index Tree可以解决的问题,线段树都可以解决。
线段树的思想是,把区间表示成若干区间的并集
树状数组的思想是,把区间表示成两个前缀区间的差集(前缀区间又可以表示成若千个区间的并集)
问题1:如何获取一个二进制序列中最右侧的1?
公式:n&(~n+1) == n&(-n)
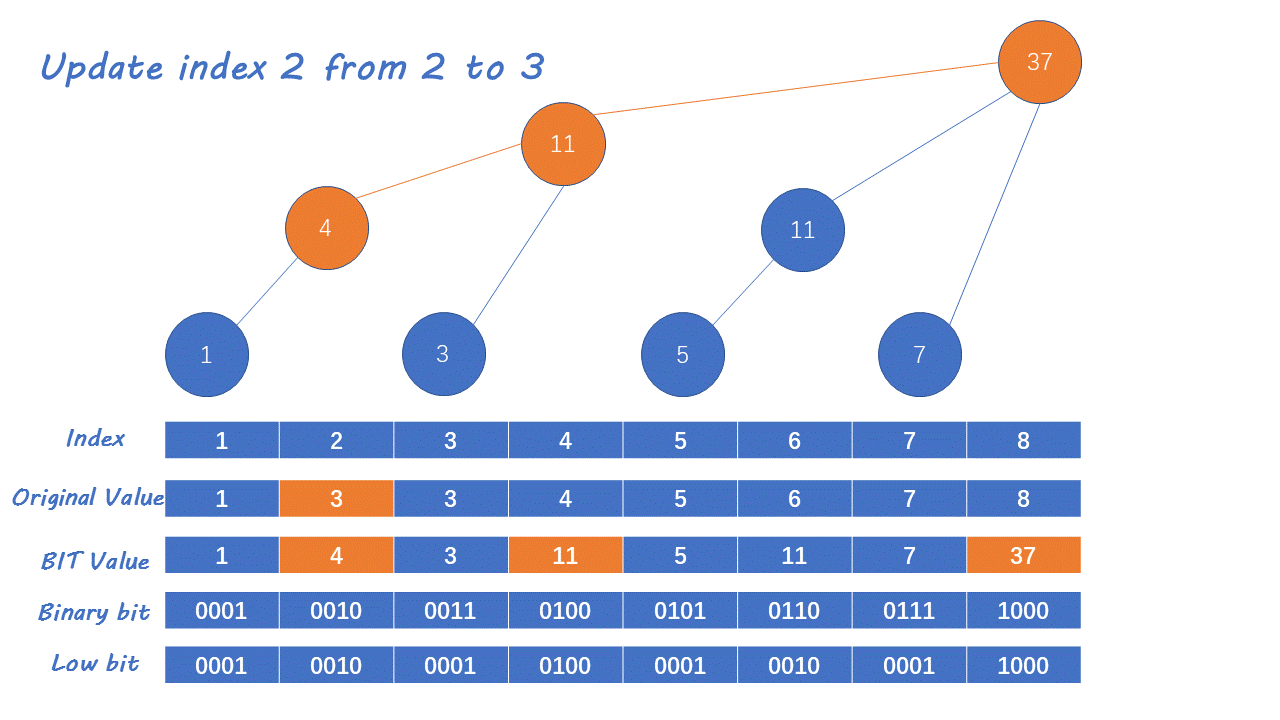
在IndexTree中一般有一个helper数组对应i为位置管理了一段区间的累加和:举个例子
那么,假设有序列A = {1, 2, 3, 4, 5, 6, 7, 8},注意在help数组中0位置不用,从1位置开始。1位置管理1位置的元素,2位置往前一看1位置有一个和我长度一模一样的累加和于是2位置就管理
1~2位置的累加和。3位置一看前面只有没有和他一样长度的累加和,所以3就只能管理3位置的数字了,4位置一看前面有一个3是和我长度一样的,于是他们两就结成伴了长度就变成2了往前一看还有一个长度为1~2的,于是他们两就结合在一起了,所以4位置管理的是1~8位置的累加和,同理5 6 7 8 位置也可以按照相同的方法求出,这样我们就得到了help数组。对应树形结构:
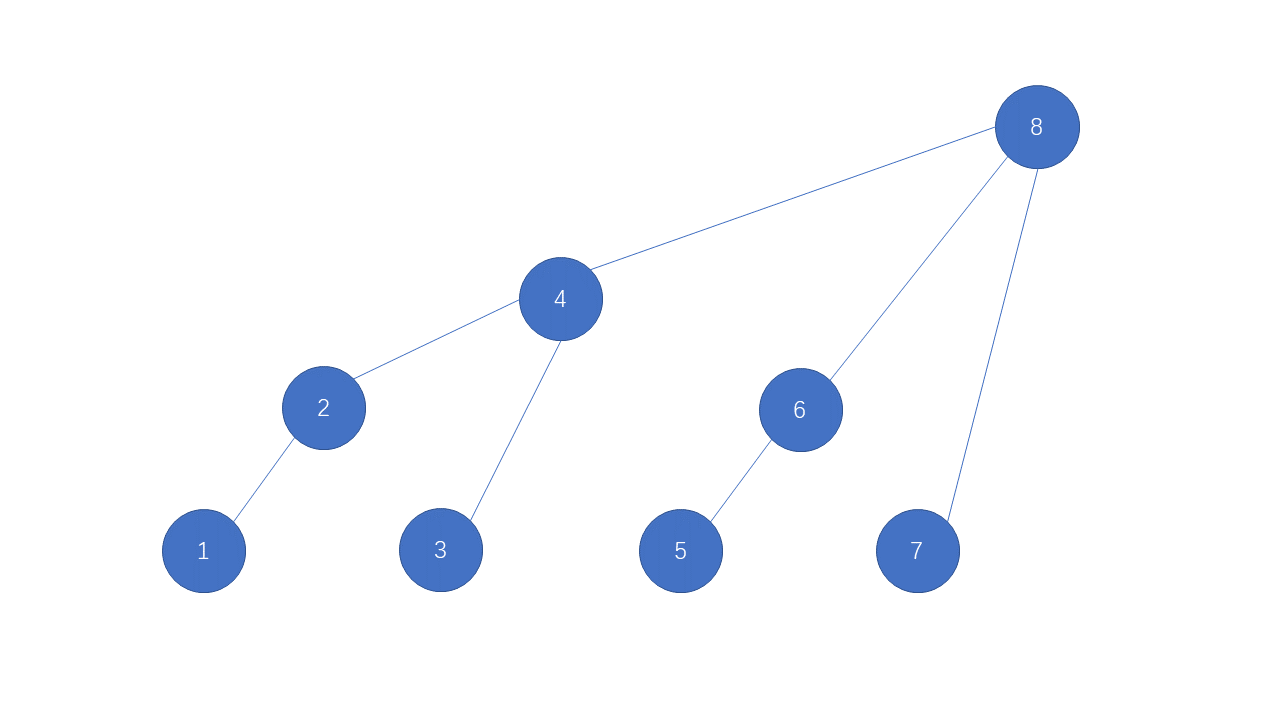
query(int index):假设 我们想知道help数组中8位置对应位置管理的是哪个范围的累加和:首先我们只需要将8的二进制序列写出来 1000,我们将它最右边的1消掉在将这个数加1:也就是0000+1=0001他管理的范围就是消去最右边1的数+1到他本身也就是1~8.不信我们在尝试一个6:它对应的二进制序列为110,将其最右侧的1消去在加1得到101也就是5到6.
add(int index, int d): 如果某一位置的值加上了某个数,必然会引起其他位置的值发生变化那么那些位置的值会发生变化呢? 首先自己这个位置肯定会发生变化,其他位置通过计算得到, 同样的先把其二进制序列写出来,将最右侧的1去出来和原来的数相加得到数就是会发生变化的位置,再重复上面这个过程,直到它大于n就结束。 将对应位置的值加上这个数即可这样我们就更新完成。
代码实现:
// BIT动态维护 arr 的前缀和,注意传进来的 n 和 index 要+1
// 注意这里下标是从1开始的:前缀和思想,lowbit无法处理0
class BinaryIndexedTree{
private int n;
private int[] tree;
public BinaryIndexedTree(int n){
this.n = n;
tree = new int[n];
}
// 将index位置加上val值 arr[i] += val
public void add(int index, int val){
while(index < n){
tree[index] += val;
index += index & -index;
}
}
// 查询[1, index]的前缀和
public int query(int index) {
int s = 0;
while (index > 0) {
s += tree[index]; // 求前缀和
// 如果是求区间最值 s = Math.max(s, tree[index]);
index -= index & -index; // n&(~n+1) == n&(-n)
}
return s;
}
// 返回[left, right]之间的区间和
public int RangeSum(int left, int right){
return query(right) - query(left-1);
}
}
树状数组模板(维护区间和)
class BinaryIndexedTree{
private int n;
private int[] tree;
public BinaryIndexedTree(int n){
this.n = n;
tree = new int[n];
}
// 将index位置加上val值 arr[i] += val
public void add(int index, int val){
while(index < n){
tree[index] += val;
index += index & -index;
}
}
// 查询[1, index]的前缀和
public int query(int index) {
int s = 0;
while (index > 0) {
s += tree[index];
index -= index & -index; // n&(~n+1) == n&(-n)
}
return s;
}
// 返回[left, right]之间的区间和
public int RangeSum(int left, int right){
return query(right) - query(left-1);
}
}
树状数组模板(维护前缀最大值)
// 树状数组模板(维护前缀最大值)
class BIT {
private long[] tree;
public BIT(int n) {
tree = new long[n];
Arrays.fill(tree, Long.MIN_VALUE);
}
public void update(int i, long val) {
while (i < tree.length) {
tree[i] = Math.max(tree[i], val);
i += i & -i;
}
}
public long preMax(int i) {
long res = Long.MIN_VALUE;
while (i > 0) {
res = Math.max(res, tree[i]);
i &= i - 1;
}
return res;
}
}
6. 线段树
线段树(segment tree),顾名思义, 是用来存放给定区间(segment, or interval)内对应信息的一种数据结构。 与树状数组(binary indexed tree)相似, 线段树也用来处理数组相应的 区间查询(range query)和 元素更新(update)操作。
对于一个线段树来说 ,其应该支持的两种操作为:
- Update:更新输入数组中的某一个元素并对线段树做相应的改变。
- Query: 用来查询某一区间对应的信息(如最大值,最小值,区间和等)。
所以线段树主要实现两个方法:「求区间和」&&「修改区间」,且时间复杂度均为 O(logn)。
始终记住一句话:线段树的每个节点代表一个区间
线段树详解:https://leetcode.cn/problems/range-module/solution/by-lfool-eo50/
什么样的问题可以用线段树解决? 区间范围上,统一增加,或者统一更新一个值。大范围信息可以只由左、右两侧信息加工出,而不必遍历左右两个子范围的具体状况。
与树状数组不同的是,线段树不止可以适用于区间求和的查询,也可以进行区间最大值,区间最小值(Range Minimum/Maximum Query problem)或者区间异或值的查询。
根据题目问题,改变表示的含义!!,如:
数字之和「总数字之和 = 左区间数字之和 + 右区间数字之和」
最大公因数 (GCD)「总 GCD = gcd(左区间 GCD, 右区间 GCD)」
最大值「总最大值 = max(左区间最大值,右区间最大值)」
不符合区间加法的例子:
众数「只知道左右区间的众数,没法求总区间的众数」
01 序列的最长连续零「只知道左右区间的最长连续零,没法知道总的最长连续零」
使用模板注意点:
- 看清楚对区间的操作「加减操作」还是「覆盖操作」,如果是覆盖操作(如求最值),val和add直接更新,不需要累加
- 如果是区间「加减操作」,则看清pushdown时是否需要 ✖ 区间节点个数
线段树完整模板
注意:下面模版基于求「区间和」以及对区间进行「加减」的更新操作,且为「动态开点」
public class SegmentTreeDynamic {
class Node {
Node left, right;
int val, add;
}
private int N = (int) 1e9;
private Node root = new Node();
//初始值start和end是固定的0-N,l和r是要更新的区间,更新值为val
public void update(Node node, int start, int end, int l, int r, int val) {
if (l <= start && end <= r) {
node.val += (end - start + 1) * val;
node.add += val;
return ;
}
int mid = (start + end) >> 1;
pushDown(node, mid - start + 1, end - mid);
if (l <= mid) update(node.left, start, mid, l, r, val);
if (r > mid) update(node.right, mid + 1, end, l, r, val);
pushUp(node);
}
public int query(Node node, int start, int end, int l, int r) {
if (l <= start && end <= r) return node.val;
int mid = (start + end) >> 1, ans = 0;
pushDown(node, mid - start + 1, end - mid);
if (l <= mid) ans += query(node.left, start, mid, l, r);
if (r > mid) ans += query(node.right, mid + 1, end, l, r);
return ans;
}
private void pushUp(Node node) {
node.val = node.left.val + node.right.val;
}
private void pushDown(Node node, int leftNum, int rightNum) {
if (node.left == null) node.left = new Node();
if (node.right == null) node.right = new Node();
if (node.add == 0) return ;
node.left.val += node.add * leftNum;
node.right.val += node.add * rightNum;
// 对区间进行「加减」的更新操作,下推懒惰标记时需要累加起来,不能直接覆盖
node.left.add += node.add;
node.right.add += node.add;
node.add = 0;
}
}
线段树的建立
public void buildTree(Node node, int start, int end) {
// 到达叶子节点
if (start == end) {
node.val = arr[start];
return ;
}
int mid = (start + end) >> 1;
node.left = new Node();node.right = new Node();
buildTree(node.left, start, mid);
buildTree(node.right, mid + 1, end);
// 向上更新
pushUp(node);
}
// 向上更新
private void pushUp(Node node) {
node.val = node.left.val + node.right.val;
}
带注释版:
注意:下面模版基于求「区间和」以及对区间进行「加减」的更新操作,且为「动态开点」
public class SegmentTreeDynamic {
class Node {
Node left, right; // 左右孩子节点
int val; // 当前节点值
int add; // 懒惰标记
}
private int N = (int) 1e9;
private Node root = new Node();
//初始值start和end是固定的0-N,l和r是要更新的区间,更新值为val
public void update(Node node, int start, int end, int l, int r, int val) {
// 找到满足要求的区间
if (l <= start && end <= r) {
// 区间节点加上更新值
// 注意:需要✖️该子树所有叶子节点
node.val += (end - start + 1) * val;
// 添加懒惰标记
// 对区间进行「加减」的更新操作,懒惰标记需要累加,不能直接覆盖
node.add += val;
return ;
}
int mid = (start + end) >> 1;
// 下推标记
// mid - start + 1:表示左孩子区间叶子节点数量
// end - mid:表示右孩子区间叶子节点数量
pushDown(node, mid - start + 1, end - mid);
// [start, mid] 和 [l, r] 可能有交集,遍历左孩子区间
if (l <= mid) update(node.left, start, mid, l, r, val);
// [mid + 1, end] 和 [l, r] 可能有交集,遍历右孩子区间
if (r > mid) update(node.right, mid + 1, end, l, r, val);
// 向上更新
pushUp(node);
}
// 在区间 [start, end] 中查询区间 [l, r] 的结果,即 [l ,r] 保持不变
// 对于上面的例子,应该这样调用该函数:query(root, 0, 4, 2, 4)
public int query(Node node, int start, int end, int l, int r) {
// 区间 [l ,r] 完全包含区间 [start, end]
// 例如:[2, 4] = [2, 2] + [3, 4],当 [start, end] = [2, 2] 或者 [start, end] = [3, 4],直接返回
if (l <= start && end <= r) return node.val;
// 把当前区间 [start, end] 均分得到左右孩子的区间范围
// node 左孩子区间 [start, mid]
// node 左孩子区间 [mid + 1, end]
int mid = (start + end) >> 1, ans = 0;
// 下推标记
pushDown(node, mid - start + 1, end - mid);
// [start, mid] 和 [l, r] 可能有交集,遍历左孩子区间
if (l <= mid) ans += query(node.left, start, mid, l, r);
// [mid + 1, end] 和 [l, r] 可能有交集,遍历右孩子区间
if (r > mid) ans += query(node.right, mid + 1, end, l, r);
// ans 把左右子树的结果都累加起来了,与树的后续遍历同理
return ans;
}
private void pushUp(Node node) {
node.val = node.left.val + node.right.val;
}
// leftNum 和 rightNum 表示左右孩子区间的叶子节点数量
// 因为如果是「加减」更新操作的话,需要用懒惰标记的值✖️叶子节点的数量
private void pushDown(Node node, int leftNum, int rightNum) {
// 动态开点
if (node.left == null) node.left = new Node();
if (node.right == null) node.right = new Node();
// 如果 add 为 0,表示没有标记
if (node.add == 0) return;
// 注意:当前节点加上标记值✖️该子树所有叶子节点的数量
node.left.val += node.add * leftNum;
node.right.val += node.add * rightNum;
// 把标记下推给孩子节点
// 对区间进行「加减」的更新操作,下推懒惰标记时需要累加起来,不能直接覆盖
node.left.add += node.add;
node.right.add += node.add;
// 取消当前节点标记
node.add = 0;
}
}
拓展:
- 对于表示为「区间和」且对区间进行「加减」的更新操作的情况,我们在更新节点值的时候『需要✖️左右孩子区间叶子节点的数量 (注意是叶子节点的数量)』;我们在下推懒惰标记的时候『需要累加』!!(这种情况和模版一致!!) 如题目 最近的请求次数
- 对于表示为「区间和」且对区间进行「覆盖」的更新操作的情况,我们在更新节点值的时候『需要✖️左右孩子区间叶子节点的数量 (注意是叶子节点的数量)』;我们在下推懒惰标记的时候『不需要累加』!!(因为是覆盖操作!!) 如题目 区域和检索 - 数组可修改
- 对于表示为「区间最值」且对区间进行「加减」的更新操作的情况,我们在更新节点值的时候『不需要✖️左右孩子区间叶子节点的数量 (注意是叶子节点的数量)』;我们在下推懒惰标记的时候『需要累加』!! 如题目 我的日程安排表 I、我的日程安排表 III
7. 字典树(前缀树)
Trie树(又叫「前缀树」或「字典树」)是一种用于快速查询「某个字符串/字符前缀」是否存在的数据结构。
其核心是使用「边」来代表有无字符,使用「点」来记录是否为「单词结尾」以及「其后续字符串的字符是什么」。
字典树的主要方法有:
-
insert 插入字符串:从字段树的根节点开始,如果子节点存在,继续处理下一个字符,如果子节点不存在,则创建一个子节点到
child的相应位置,沿着指针继续向后移动,处理下一个字符。 -
startsWith 查找前缀:从根节点开始,子节点存在,则沿着指针继续搜索下一个子节点,直到最后一个,如果搜索到了前缀所有字符,说明字典树包含该前缀。子节点不存在就说明字典树中不包含该前缀,返回
false。 -
search 查找字符串:和查找前缀一样,只不过最后返回的节点的
end是true,也就是说字符串正好是字典树的一个分支。
TrieNode实现:
class Trie {
class TrieNode{//字典树的结点数据结构
boolean end;//是否是单词末尾的标识
int pass; // 经过这个结点的次数(根据需要设置这个变量)
TrieNode[] child; //26个小写字母的拖尾
public TrieNode(){
end = false;
pass = 0;
child = new TrieNode[26];
}
}
TrieNode root;//字典树的根节点。
public Trie() {
root = new TrieNode();
}
public void insert(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
//若当前结点下没有找到要的字母,则新开结点继续插入
if (p.child[u] == null) p.child[u] = new TrieNode();
p = p.child[u];
p.pass++;
}
p.end = true;
}
public boolean search(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
if (p.child[u] == null) return false;//变化点(根据题意)
p = p.child[u];
}
return p.end;
}
public boolean startsWith(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
if (p.child[u] == null) return false;
p = p.child[u];
}
return true;
}
}
二、图论
1. 内向基环树
https://leetcode.cn/problems/maximum-employees-to-be-invited-to-a-meeting/solution/nei-xiang-ji-huan-shu-tuo-bu-pai-xu-fen-c1i1b/
1、基环树定义
从 i i i 向 favorite [ i ] \textit{favorite}[i] favorite[i]连边,我们可以得到一张有向图。由于每个大小为 k k k 的连通块都有 k k k 个点和 k k k 条边,所以每个连通块必定有且仅有一个环,且由于每个点的出度均为1,这样的有向图又叫做内向基环树 (pseudotree),由基环树组成的森林叫基环树森林 (pseudoforest)。
每一个内向基环树(连通块)都由一个基环和其余指向基环的树枝组成。例如示例 [ 3 , 0 , 1 , 4 , 1 ] [3,0,1,4,1] [3,0,1,4,1] 可以得到如下内向基环树,其基环由节点 0、1、3 和 4 组成,节点 2 为其树枝:

特别地,我们得到的基环可能只包含两个节点。例如示例 [ 2 , 2 , 1 , 2 ] [2,2,1,2] [2,2,1,2]可以得到如下内向基环树,其基环只包含节点 1 和 2,而节点 0 和 3 组成其树枝:

2、基环树问题的通用处理方法
下面介绍基环树问题的通用处理方法:
我们可以通过一次拓扑排序「剪掉」所有树枝,因为拓扑排序后,树枝节点的入度均为 0,基环节点的入度均为 1。这样就可以将基环和树枝分开,从而简化后续处理流程:
- 如果要遍历基环,可以从拓扑排序后入度为 1 的节点出发,在图上搜索;
- 如果要遍历树枝,可以以基环与树枝的连接处为起点,顺着反图来搜索树枝(搜索入度为 0 的节点),从而将问题转化成一个树形问题。
难度困难75
一个公司准备组织一场会议,邀请名单上有 n 位员工。公司准备了一张 圆形 的桌子,可以坐下 任意数目 的员工。
员工编号为 0 到 n - 1 。每位员工都有一位 喜欢 的员工,每位员工 当且仅当 他被安排在喜欢员工的旁边,他才会参加会议。每位员工喜欢的员工 不会 是他自己。
给你一个下标从 0 开始的整数数组 favorite ,其中 favorite[i] 表示第 i 位员工喜欢的员工。请你返回参加会议的 最多员工数目 。
示例 1:
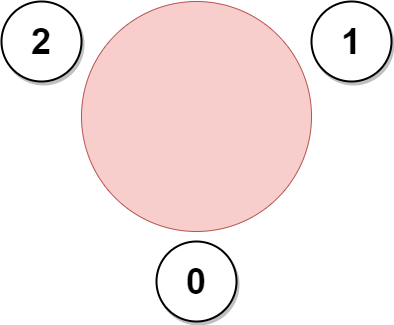
输入:favorite = [2,2,1,2]
输出:3
解释:
上图展示了公司邀请员工 0,1 和 2 参加会议以及他们在圆桌上的座位。
没办法邀请所有员工参与会议,因为员工 2 没办法同时坐在 0,1 和 3 员工的旁边。
注意,公司也可以邀请员工 1,2 和 3 参加会议。
所以最多参加会议的员工数目为 3 。
示例 2:
输入:favorite = [1,2,0]
输出:3
解释:
每个员工都至少是另一个员工喜欢的员工。所以公司邀请他们所有人参加会议的前提是所有人都参加了会议。
座位安排同图 1 所示:
- 员工 0 坐在员工 2 和 1 之间。
- 员工 1 坐在员工 0 和 2 之间。
- 员工 2 坐在员工 1 和 0 之间。
参与会议的最多员工数目为 3 。
示例 3:
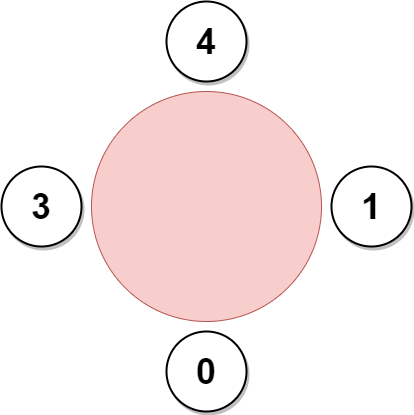
输入:favorite = [3,0,1,4,1]
输出:4
解释:
上图展示了公司可以邀请员工 0,1,3 和 4 参加会议以及他们在圆桌上的座位。
员工 2 无法参加,因为他喜欢的员工 0 旁边的座位已经被占领了。
所以公司只能不邀请员工 2 。
参加会议的最多员工数目为 4 。
提示:
n == favorite.length2 <= n <= 1050 <= favorite[i] <= n - 1favorite[i] != i
对于本题来说,这两类基环树在组成圆桌时会有明显区别,下文会说明这一点。
先来看看基环大小大于 2 的情况:
- 显然基环上的节点组成了一个环,因而可以组成一个圆桌;而树枝上的点,若插入圆桌上 v → w v\rightarrow w v→w这两人中间,会导致节点 v 无法和其喜欢的员工坐在一起,因此树枝上的点是无法插入圆桌的;此外,树枝上的点也不能单独组成圆桌,因为这样会存在一个出度为 0 的节点,其无法和其喜欢的员工坐在一起。对于其余内向基环树(连通块)上的节点,和树枝同理,也无法插入该基环组成的圆桌。
因此,**对于基环大小大于 2 的情况,圆桌的最大员工数目即为最大的基环大小,记作 ** maxRingSize \textit{maxRingSize} maxRingSize
下面来分析基环大小等于 2 的情况:
以如下基环树为例,0 和 1 组成基环,其余节点组成树枝:

我们可以先让 0 和 1 坐在圆桌旁(假设 0 坐在 1 左侧),那么 0 这一侧的树枝只能坐在 0 的左侧,而 1 这一侧的树枝只能坐在 1 的右侧。
2 可以紧靠着坐在 0 的左侧,而 3 和 4 只能选一个坐在 2 的左侧(如果 4 紧靠着坐在 2 的左侧,那么 3 是无法紧靠着坐在 4 的左侧的,反之亦然)。
这意味着从 0 出发倒着找树枝上的点(即沿着反图上的边),每个点只能在其反图上选择其中一个子节点,因此 0 这一侧的节点必须组成一条链,那么我们可以找最长的那条链,即上图加粗的节点。
对于 1 这一侧也同理。将这两条最长链拼起来即为该基环树能组成的圆桌的最大员工数。
对于多个基环大小等于 2 的基环树,每个基环树所对应的链,都可以拼在其余链的末尾,因此我们可以将这些链全部拼成一个圆桌,其大小记作 sumChainSize \textit{sumChainSize} sumChainSize。
答案即为 max ( maxRingSize , sumChainSize ) \max(\textit{maxRingSize},\textit{sumChainSize}) max(maxRingSize,sumChainSize)
对于本题,我们可以遍历所有基环,并按基环大小分类计算:
对于大小大于 2 的基环,我们取基环大小的最大值;
对于大小等于 2 的基环,我们可以从基环上的点出发,在反图上找到最大的树枝节点深度。
class Solution {
List<Integer>[] rg; // g的反图
int[] degree; // g上每个节点的入度
public int maximumInvitations(int[] g) {
int n = g.length;
rg = new ArrayList[n];
Arrays.setAll(rg, e -> new ArrayList<>());
degree = new int[n];
for(int v = 0; v < n; v++){
int w = g[v]; // v->w
rg[w].add(v);
degree[w]++; //rg反图上记录下w->v,并且w入度+1
}
// 拓扑排序,剪掉g上的所有树枝(入度 =0 的节点)
Deque<Integer> dq = new ArrayDeque<>();
for(int i = 0; i < n; i++){
if(degree[i] == 0) dq.addLast(i);
}
while(!dq.isEmpty()){
int v = dq.pollFirst();
int w = g[v]; // v->w,v只有一条出边
if(--degree[w] == 0) dq.addLast(w);
}
// 大小>2的基环:基环大小的最大值maxRingSize
// 大小=2的基环,从基环上的点出发,反向找到树枝的最大深度sumChainSize
int maxRingSize = 0, sumChainSize = 0;
for(int i = 0; i < n; i++){
if(degree[i] <= 0) continue;
//遍历基环上的点(拓扑排序后入度>0的点)
degree[i] = -1;
int ringsize = 1; // tmp环的大小
for(int v = g[i]; v != i; v = g[v]){ //环循环终止条件v!= i,即转一圈
degree[v] = -1; //将基环上的点的入度标记为-1,避免重复访问
ringsize++;
}
//遍历树枝-----------------------------------------------------------------
if(ringsize == 2){ //基环大小为2,累加两条最长链的长度
sumChainSize += rdfs(i) + rdfs(g[i]); // i->g[i],g[i]->i,因此从两个点出发找最长链的长度
}else{// 基环大小 >2, 取所有基环的最大值
//取基环最大值-------------------------------------------------------------
maxRingSize = Math.max(maxRingSize, ringsize);
}
}
return Math.max(maxRingSize, sumChainSize);
}
// 类似树的直径问题,只不过不用求树的直径,而是求当前节点的最大直径(不需要更新全局变量直径长度)
public int rdfs(int v){
int maxdepth = 1;
for(int w : rg[v]){ //w->v,在反图中v包含了所有指向v的树枝,枚举找最大值
if(degree[w] == 0){ //树枝上的点在拓扑排序后,入度均为 0
maxdepth = Math.max(maxdepth, rdfs(w) + 1);
}
}
return maxdepth;
}
}
其他类似问题
三、数学
1. 最大公因数GCD和最小公倍数LCM
// 最大公因数GCD:两个或多个整数共有约数中最大的一个
// 辗转相除法
public int gcd(int x, int y) {
return y == 0 ? x : gcd(y, x % y);
}
// 最小公倍数LCM:两个或多个整数公有的倍数叫做它们的公倍数,
// 其中除0以外最小的一个公倍数就叫做这几个整数的最小公倍数。
public int lcm(int x, int y) {
return (x * y) / gcd(x, y);
}
2. Math.pow(x,n,m)快速幂
/**
两个等式:
(a+b) % mod = ((a%mod) + (b%mod)) % mod
(a*b) %mod = ((a%mod) * (b*mod)) % mod
*/
private long pow(long x, int n, int mod) {
long res = 1;
for (; n > 0; n /= 2) {
if (n % 2 > 0)
res = res * x % mod;
x = x * x % mod;
}
return res;
}
中等
实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,xn )。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
输入:x = 2.10000, n = 3
输出:9.26100
示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
提示:
-100.0 < x < 100.0-231 <= n <= 231-1n是一个整数- 要么
x不为零,要么n > 0。 -104 <= xn <= 104
class Solution {
/** pow(x, n)
1.使用折半计算,每次把n缩小一半,这样n最终会缩小到0,任何数的0次方都为1
2.这时候我们再往回乘,
2.1如果此时n是偶数,直接把上次递归得到的值算个平方返回即可
2.2如果是奇数,则还需要乘上个x的值。
3.还有一点需要引起我们的注意的是n有可能为负数,对于n是负数的情况,
我们可以先用其绝对值计算出一个结果再取其倒数即可。
算法:
1. 我们让i初始化为n,i每次循环缩小一半,直到为0停止
2. 每次循环看i是否是2的倍数,是的话x乘以自己,否则res乘以x。
3. 最后看n的正负,如果为负,返回其倒数。
*/
public double myPow(double x, int n) {
double res = 1.0;
for(int i = n; i != 0; i = i/2){
if(i % 2 != 0) res = res*x;
x *= x;
}
return n < 0 ? 1/res : res;
}
}
2. upper_bound和lower_bound函数
- lower_bound 返回 第一个 >= key 的元素, upper_bound 返回 第一个 > key 的元素
// upper_bound : 返回第一个大于key的元素下标
public int upperBound(List<Integer> list, int target){
int left = 0, right = list.size();
while(left < right){
int mid = (left + right) >> 1;
if(list.get(mid) > target) right = mid;
else left = mid + 1;
}
return left;
}
// lower_bound : 返回第一个大于或等于key的元素下标
public int lowerBound(List<Integer> list, int target){
int left = 0, right = list.size();
while(left < right){
int mid = (left + right) >> 1;
if(list.get(mid) < target) left = mid + 1;
else right = mid;
}
return left;
}
3. 求质数(埃氏筛)
质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
private static void euler() {
int n = (int)1e5;
//判断是否是质数,1-质数 0-合数
int[] isPrime = new int[n];
// 存放质数
int[] primes = new int[n];
int k = 0;//存放质数数组的索引下标
Arrays.fill(isPrime, 1);
isPrime[1] = 0; // 1不是质数
for(int i = 2; i < n; i++) {
if(isPrime[i] == 1){
primes[k++] = i;
}
// 枚举已经筛出来的素数prime[j](j=1~cnt)
for(int j = 0; primes[j] * i < n; j++){
//筛掉i的素数倍,即i的prime[j]倍
isPrime[primes[j] * i] = 0;//每个质数都和i相乘得到合数
//如果i整除prime[j],退出循环,保证线性时间复杂度
if (i % primes[j] == 0) //primes[j]是i的一个质因数
break;
}
}
}
灵神写法:
private final static int MX = (int) 1e5;
private final static boolean[] np = new boolean[MX + 1]; // 质数=false 非质数=true
static {
np[1] = true;
for (int i = 2; i * i <= MX; i++) {
if (!np[i]) {
for (int j = i * i; j <= MX; j += i) {
np[j] = true;
}
}
}
}
4. 蓄水池采样(Reservoir Sampling)
1、问题描述分析:
采样问题经常会被遇到,比如:
- 从 100000 份调查报告中抽取 1000 份进行统计。
- 从一本很厚的电话簿中抽取 1000 人进行姓氏统计。
- 从 Google 搜索 “Ken Thompson”,从中抽取 100 个结果查看哪些是今年的。
这些都是很基本的采用问题。
既然说到采样问题,最重要的就是做到公平,也就是保证每个元素被采样到的概率是相同的。所以可以想到要想实现这样的算法,就需要掷骰子,也就是随机数算法。(这里就不具体讨论随机数算法了,假定我们有了一套很成熟的随机数算法了)
对于第一个问题,还是比较简单,通过算法生成 [0,100000−1) 间的随机数 1000 个,并且保证不重复即可。再取出对应的元素即可。
但是对于第二和第三个问题,就有些不同了,我们不知道数据的整体规模有多大。可能有人会想到,我可以先对数据进行一次遍历,计算出数据的数量 N,然后再按照上述的方法进行采样即可。这当然可以,但是并不好,毕竟这可能需要花上很多时间。也可以尝试估算数据的规模,但是这样得到的采样数据分布可能并不平均。
2、蓄水池采样算法(Reservoir Sampling)
算法的过程:
假设数据序列的规模为 n,需要采样的数量的为 k。
首先构建一个可容纳 k 个元素的数组,将序列的前 k 个元素放入数组中。
然后从第 k+1 个元素开始,以 k/n 的概率来决定该元素最后是否被留在数组中(每进来一个新的元素,数组
中的每个旧元素被替换的概率是相同的)。 当遍历完所有元素之后,数组中剩下的元素即为所需采取的样本。
- 不证明
难度中等264
给你一个可能含有 重复元素 的整数数组 nums ,请你随机输出给定的目标数字 target 的索引。你可以假设给定的数字一定存在于数组中。
实现 Solution 类:
Solution(int[] nums)用数组nums初始化对象。int pick(int target)从nums中选出一个满足nums[i] == target的随机索引i。如果存在多个有效的索引,则每个索引的返回概率应当相等。
示例:
输入
["Solution", "pick", "pick", "pick"]
[[[1, 2, 3, 3, 3]], [3], [1], [3]]
输出
[null, 4, 0, 2]
解释
Solution solution = new Solution([1, 2, 3, 3, 3]);
solution.pick(3); // 随机返回索引 2, 3 或者 4 之一。每个索引的返回概率应该相等。
solution.pick(1); // 返回 0 。因为只有 nums[0] 等于 1 。
solution.pick(3); // 随机返回索引 2, 3 或者 4 之一。每个索引的返回概率应该相等。
提示:
1 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 1target是nums中的一个整数- 最多调用
pick函数104次
class Solution {
Random random = new Random();
private int[] nums;
public Solution(int[] nums) {
this.nums = nums;
}
public int pick(int target) {
int count = 0;
int ans = -1;
for(int i = 0; i < nums.length; i++){
if(nums[i] == target){
// 1 1/2 1/3 1/4 的概率替换
count++;
if(random.nextInt(count)==0) ans = i;
}
}
return ans;
}
}
二进制相关API
1、获得「数字 num 表示的二进制数」 bit为1的最高非零位的位置 highBit
int highBit = 31 - Integer.numberOfLeadingZeros(num);
// 后续可用来枚举
for (int i = highBit; i >= 0; i--) { // 从最高位开始枚举
}
Integer.numberOfLeadingZeros(num)
- 返回无符号整型i的最高非零位前面的n个0的个数,包括符号位。如果i小于0则返回0,等于0则返回32。
例:10的二进制为:0000 0000 0000 0000 0000 0000 0000 1010
java的int长度为32位,那么这个方法返回的就是28。
Java算法常用API
1、数组拷贝
int[] f = Arrays.copyOf(nums,nums.length)
或者
System.arraycopy(object src , int srcpos , object dest , int destpos ,array.length)
四、其他
1. 离散化
离散化本质上是一种特殊的哈希,把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率。
简单来说,就是在不改变数据的相对大小的情况下,对数据进行一定的缩小。
离散化版本1:二分查找
练习题:LCP 74. 最强祝福力场
离散化前:
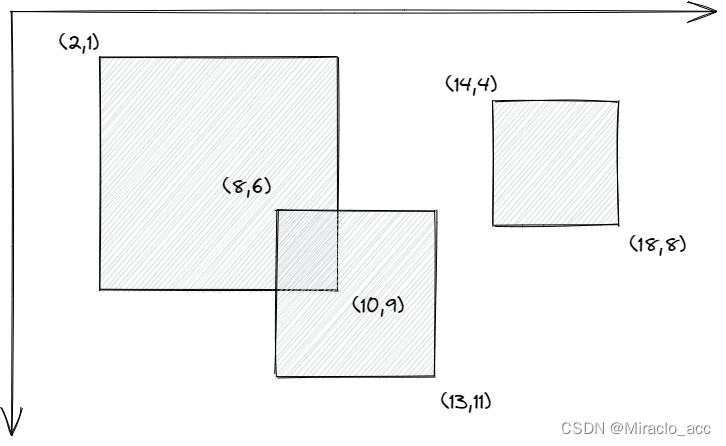
离散化后:
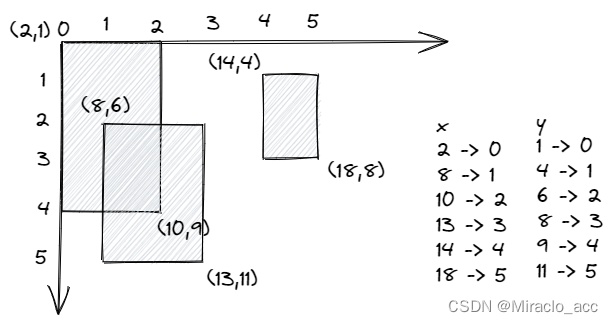
可以发现原来横坐标需要18个空间量,纵坐标需要11个空间单位,通过离散化后压缩到了5个空间单位。
接下来要算的就是映射过去的坐标,而不是其原来的坐标。
那么如何找到映射后的坐标呢?可以通过二分查找。
# 1. 统计所有原下标
x_set = set()
for i in nums:
x_set.add(i) # 将待离散化的元素添加到set中(同时去重)
# 2. 将原数组copy,然后排序
xs = sorted(x_set)
# 3. 找到原数组中映射过去的下标
target = bisect_left(xs, origin_position)
通常分为三步:复制「去重」、排序、二分
// 原数组int[] nums
Set<Integer> set = new HashSet<>(); // 防止重复
for(int x : nums) set.add(x);
List<Integer> copy = new ArrayList<>(set);
Collections.sort(copy); // 排序
// 如何找到原数组中元素映射的下标? 二分
for(int num : nums){
// 二分找到 >= nums 的第一个下标, 查找的元素一定存在
int left = 0, right = copy.size();
while(left < right){
int mid = (left + right) >> 1;
if(copy.get(mid) < num) left = mid + 1;
else right = mid;
}
// left = right 即为元素下标,因为查找的元素一定存在
}
2. 中心扩散法(回文串问题)
回文串问题通常是模拟、动态规划、中心扩展法求解
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
回文字符串 是正着读和倒过来读一样的字符串。
子字符串 是字符串中的由连续字符组成的一个序列。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
题解:
方法一:动态规划
首先这一题可以使用动态规划来进行解决:
- 状态:
dp[i][j]表示字符串s在[i,j]区间的子串是否是一个回文串。 - 状态转移方程:
当 s[i] == s[j] && (j - i < 2 || dp[i + 1][j - 1])时,dp[i][j]=true,否则为false
这个状态转移方程是什么意思呢?
- 当只有一个字符时,比如
a自然是一个回文串。 - 当有两个字符时,如果是相等的,比如
aa,也是一个回文串。 - 当有三个及以上字符时,比如
ababa这个字符记作串 1,把两边的a去掉,也就是bab记作串 2,可以看出只要串2是一个回文串,那么左右各多了一个a的串 1 必定也是回文串。所以当s[i]==s[j]时,自然要看dp[i+1][j-1]是不是一个回文串。
class Solution {
public int countSubstrings(String s) {
boolean[][] dp = new boolean[s.length()][s.length()];
int res = 0;
// 本题中的回文字串是连续的,要求不连续的回文串:516. 最长回文子序列
for(int j = 0; j < s.length(); j++){
for(int i = 0; i <= j; i++){
// 当只有一个字符时,比如 a 自然是一个回文串。
// 当有两个字符时,如果是相等的,比如 aa,也是一个回文串。
// 当有三个及以上字符时,比如 ababa 这个字符记作串 1,把两边的 a 去掉,也就是 bab 记作串 2,
// 可以看出只要串2是一个回文串,那么左右各多了一个 a 的串 1 必定也是回文串。
// 所以当 s[i]==s[j] 时,自然要看 dp[i+1][j-1] 是不是一个回文串。
if(s.charAt(i) == s.charAt(j) && (j - i < 2 || dp[i + 1][j - 1])){
dp[i][j] = true;
res++;
}
}
}
return res;
}
}
方法二:中心拓展法
比如对一个字符串 ababa,选择最中间的 a 作为中心点,往两边扩散,第一次扩散发现 left 指向的是 b,right 指向的也是 b,所以是回文串,继续扩散,同理 ababa 也是回文串。
这个是确定了一个中心点后的寻找的路径,然后我们只要寻找到所有的中心点,问题就解决了。
中心点一共有多少个呢?看起来像是和字符串长度相等,但你会发现,如果是这样,上面的例子永远也搜不到 abab,想象一下单个字符的哪个中心点扩展可以得到这个子串?似乎不可能。所以中心点不能只有单个字符构成,还要包括两个字符,比如上面这个子串 abab,就可以有中心点 ba 扩展一次得到,所以最终的中心点由 2 * len - 1 个,分别是 len 个单字符和 len - 1 个双字符。
如果上面看不太懂的话,还可以看看下面几个问题:
- 为什么有
2 * len - 1个中心点?aba有5个中心点,分别是a、b、c、ab、baabba有7个中心点,分别是a、b、b、a、ab、bb、ba
- 什么是中心点?
- 中心点即
left指针和right指针初始化指向的地方,可能是一个也可能是两个
- 中心点即
- 为什么不可能是三个或者更多?
- 因为
3个可以由 1 个扩展一次得到,4 个可以由两个扩展一次得到
- 因为
class Solution {
public int countSubstrings(String s) {
int res = 0;
int n = s.length();
for(int center = 0; center < 2 * n - 1; center++){
// left和right指针和中心点的关系是?
// 首先是left,有一个很明显的2倍关系的存在,其次是right,可能和left指向同一个(偶数时),也可能往后移动一个(奇数)
// 大致的关系出来了,可以选择带两个特殊例子进去看看是否满足。
int left = center / 2, right = left + center % 2;
while(left >= 0 && right < n && s.charAt(left) == s.charAt(right)){
// 找到了一个回文串
res++;
// 向两侧拓展
left--;
right++;
}
}
return res;
}
}
3. 预处理回文数「1e9内回文数打表」
https://leetcode.cn/problems/minimum-cost-to-make-array-equalindromic/solutions/2569308/yu-chu-li-hui-wen-shu-zhong-wei-shu-tan-7j0zy/
- 10^9大约有109998个回文数
private static final int[] pal = new int[109999];
static{
// 严格按顺序从小到大生成所有回文数(不用字符串转换)
int palIdx = 0;
for(int base = 1; base <= 10000; base *= 10){ // 枚举回文数的长度
// 生成奇数长度回文数
for(int i = base; i < base * 10; i++){
int x = i; // 123 .. 123*10+2 .. 1232*10+1 ==> 12321
for(int t = i / 10; t > 0; t /= 10){
x = x * 10 + t % 10;
}
pal[palIdx++] = x;
}
// 生成偶数长度回文数
if(base <= 1000){
for(int i = base; i < base * 10; i++){
int x = i;
for(int t = i; t > 0; t /= 10){ // 区别在于t初始是否/10
x = x * 10 + t % 10;
}
pal[palIdx++] = x;
}
}
}
pal[palIdx++] = (int)1e9+1; // 哨兵,防止下面代码中的 i 下标越界
}
可以解决的问题
有序哈希表(平衡树)TreeMap\TreeSet
1、TreeMap
我们先看一看TreeMap类,实现了众多接口,它的这两个方法来自NavigableMap类:
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {...}
先看一看NavigableMap类中常见的API:
| 类型 | 方法 | 描述 |
|---|---|---|
| K | ceilingKey(K key) | 返回大于或等于给定键的最小键,如果没有这样的键,则null |
| K | floorKey(K key) | 返回小于或等于给定键的最大键,如果没有这样的键,则null |
| K | map.lastKey() | 返回此TreeMap中具有最大键值的key ,否则返回null。 |
| K | map.firstKey() | 返回此TreeMap中具有最小键值的key ,否则返回null。 |
| K | map.lastEntry() | 返回此TreeMap中具有最大键值的条目 ,否则返回null。 |
| K | map.firstEntry() | 返回此TreeMap中具有最小键值的条目 ,否则返回null。 |
具体的需要注意的点就是这两个方法来自NavigableMap,在声明的时候最好使用TreeMap map = new TreeMap()。 使用Map map = new TreeMap()是无法调用这两个方法的(这里涉及到向下转型的问题)。且TreeMap不保留存储顺序(内部以key升序)、key唯一等性质。
2、TreeSet
| 方法 | 描述 |
|---|---|
| ceiling(E e) | 返回大于或等于给定元素的最小值,如果没有这样的元素,则null |
| floor(E e) | 返回小于或等于给定键的最大值,如果没有这样的元素,则null |
| last() | 返回最后一个元素,如果TreeSet 为空则抛出异常NoSuchElementException |
| first() | 返回第一个元素,如果TreeSet 为空则抛出异常NoSuchElementException |
注意声明:TreeSet set = new TreeSet()
算法Stream流API
List转int数组:list.stream().mapToInt(Integer::intValue).toArray();
| 方法 | |
|---|---|
| List转int数组 | 写法一:int[] a = list.stream().mapToInt(Integer::intValue).toArray(); 写法二:int[] a = list.stream().mapToInt(i -> i).toArray(); |
| 求数组最大值 | Arrays.stream(cnt).max().getAsInt(); |
| 求数组最小值 | Arrays.stream(cnt).min().getAsInt(); |
可能用不到的技巧
1. 后缀数组 DC3算法
// 生成后缀数组的暴力方法时间复杂度:O(N^2*logN)
// 而DC3算法生成后缀数组的时间复杂度仅O(N)
// 为啥叫DC3?因为是根据下标模3来取得
public class DC3 {
// 下标代表名次,值代表原数组的位置
// 不会有排名相同的后缀串,因为所有的后缀串的长度都不一样
public int[] sa;
// 第0位置的是第几名?第1位置的是第几名?... 第i位置的是第几名?
public int[] rank;
public int[] height;
// 构造方法的约定:
// 数组叫nums,如果你是字符串,请转成整型数组nums
// 数组中,最小值>=1,如果不满足,处理成满足的,也不会影响使用
// max:nums里面最大值是多少
public DC3(int[] nums, int max) {
sa = sa(nums, max);
rank = rank();
height = height(nums);
}
private int[] sa(int[] nums, int max) {
int n = nums.length;
int[] arr = new int[n + 3];
for (int i = 0; i < n; i++) {
arr[i] = nums[i];
}
return skew(arr, n, max);
}
private int[] skew(int[] nums, int n, int K) {
int n0 = (n + 2) / 3, n1 = (n + 1) / 3, n2 = n / 3, n02 = n0 + n2;
int[] s12 = new int[n02 + 3], sa12 = new int[n02 + 3];
for (int i = 0, j = 0; i < n + (n0 - n1); ++i) {
if (0 != i % 3) {
s12[j++] = i;
}
}
radixPass(nums, s12, sa12, 2, n02, K);
radixPass(nums, sa12, s12, 1, n02, K);
radixPass(nums, s12, sa12, 0, n02, K);
int name = 0, c0 = -1, c1 = -1, c2 = -1;
for (int i = 0; i < n02; ++i) {
if (c0 != nums[sa12[i]] || c1 != nums[sa12[i] + 1] || c2 != nums[sa12[i] + 2]) {
name++;
c0 = nums[sa12[i]];
c1 = nums[sa12[i] + 1];
c2 = nums[sa12[i] + 2];
}
if (1 == sa12[i] % 3) {
s12[sa12[i] / 3] = name;
} else {
s12[sa12[i] / 3 + n0] = name;
}
}
if (name < n02) {
sa12 = skew(s12, n02, name);
for (int i = 0; i < n02; i++) {
s12[sa12[i]] = i + 1;
}
} else {
for (int i = 0; i < n02; i++) {
sa12[s12[i] - 1] = i;
}
}
int[] s0 = new int[n0], sa0 = new int[n0];
for (int i = 0, j = 0; i < n02; i++) {
if (sa12[i] < n0) {
s0[j++] = 3 * sa12[i];
}
}
radixPass(nums, s0, sa0, 0, n0, K);
int[] sa = new int[n];
for (int p = 0, t = n0 - n1, k = 0; k < n; k++) {
int i = sa12[t] < n0 ? sa12[t] * 3 + 1 : (sa12[t] - n0) * 3 + 2;
int j = sa0[p];
if (sa12[t] < n0 ? leq(nums[i], s12[sa12[t] + n0], nums[j], s12[j / 3])
: leq(nums[i], nums[i + 1], s12[sa12[t] - n0 + 1], nums[j], nums[j + 1], s12[j / 3 + n0])) {
sa[k] = i;
t++;
if (t == n02) {
for (k++; p < n0; p++, k++) {
sa[k] = sa0[p];
}
}
} else {
sa[k] = j;
p++;
if (p == n0) {
for (k++; t < n02; t++, k++) {
sa[k] = sa12[t] < n0 ? sa12[t] * 3 + 1 : (sa12[t] - n0) * 3 + 2;
}
}
}
}
return sa;
}
private void radixPass(int[] nums, int[] input, int[] output, int offset, int n, int k) {
int[] cnt = new int[k + 1];
for (int i = 0; i < n; ++i) {
cnt[nums[input[i] + offset]]++;
}
for (int i = 0, sum = 0; i < cnt.length; ++i) {
int t = cnt[i];
cnt[i] = sum;
sum += t;
}
for (int i = 0; i < n; ++i) {
output[cnt[nums[input[i] + offset]]++] = input[i];
}
}
private boolean leq(int a1, int a2, int b1, int b2) {
return a1 < b1 || (a1 == b1 && a2 <= b2);
}
private boolean leq(int a1, int a2, int a3, int b1, int b2, int b3) {
return a1 < b1 || (a1 == b1 && leq(a2, a3, b2, b3));
}
private int[] rank() {
int n = sa.length;
int[] ans = new int[n];
for (int i = 0; i < n; i++) {
ans[sa[i]] = i;
}
return ans;
}
private int[] height(int[] s) {
int n = s.length;
int[] ans = new int[n];
for (int i = 0, k = 0; i < n; ++i) {
if (rank[i] != 0) {
if (k > 0) {
--k;
}
int j = sa[rank[i] - 1];
while (i + k < n && j + k < n && s[i + k] == s[j + k]) {
++k;
}
ans[rank[i]] = k;
}
}
return ans;
}
// 为了测试
public static int[] randomArray(int len, int maxValue) {
int[] arr = new int[len];
for (int i = 0; i < len; i++) {
arr[i] = (int) (Math.random() * maxValue) + 1;
}
return arr;
}
// 为了测试
public static void main(String[] args) {
int len = 100000;
int maxValue = 100;
long start = System.currentTimeMillis();
new DC3(randomArray(len, maxValue), maxValue);
long end = System.currentTimeMillis();
System.out.println("数据量 " + len + ", 运行时间 " + (end - start) + " ms");
}
}















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









